Excel で質的データを分析する方法 (簡単な手順)
質的データの分析方法を知る方法を探しています エクセルで ?それなら、これはあなたにぴったりの記事です。 データ 数えることができず、数値で説明するのが難しい場合は、 データ 質的です .この定性を収集できます データ フォーカス グループ ディスカッション、詳細なインタビュー、文の補完、単語の連想、カジュアルな会話などから。
Excel で質的データを分析するための 8 つのステップ
私たちのアプローチを示すために、調査アンケートから 3 つの回答を得ました。こちら XYZ カフェです 町のはずれにあり、学生がたむろすることもあります。 3 つの質問は次のとおりです。
- まず、リッカート尺度 質問「 XYZ に満足しています 」。この質問には 5 つのレベルで回答できます。
- 次に、多肢選択式の質問「 XYZ で食べる頻度 日で」。参加者は 3 のいずれかを選択できます オプション。
- 最後に、自由回答形式の質問:「XYZ に含めるべき食品はどれですか? 」。ここでは、テキストの長さに制限はありません。
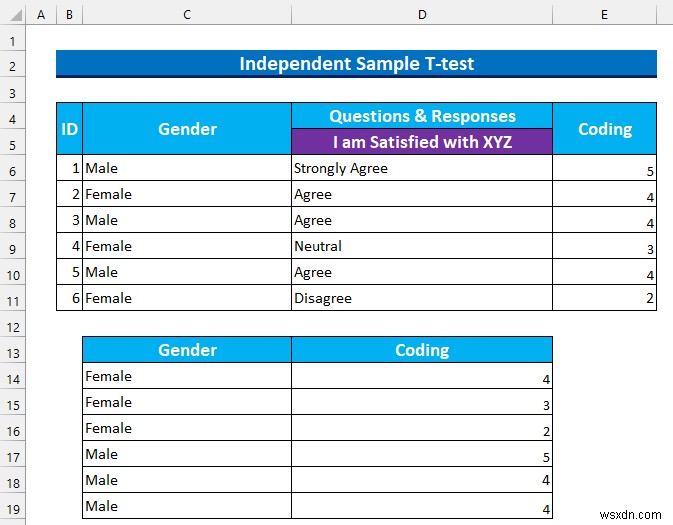
通常、データセットには 3 があります 列:「ID 」、「性別 」、「質問 & 回答 」。さらに、以下のスナップショットでは、3 つの質問がコンパクトな構造で示されています。各タイプから情報を取得する方法について説明します。
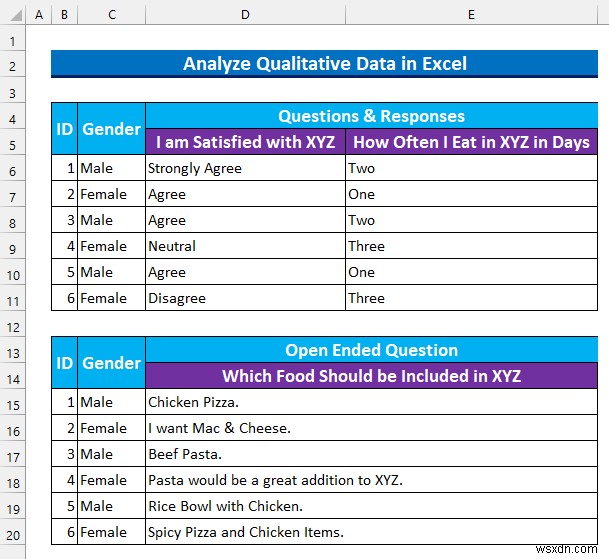
ステップ 1:Excel で分析するための定性的データのコーディングと並べ替え
質的データを変換します コードを使用して数値に変換します。次に、 データ を並べ替えます 次のステップに備えるために。 リッカート尺度 5 あります レベルなので、値は次のようになります:
- 強く同意 -> 5 .
- 同意する -> 4 .
- 中立 -> 3 .
- 同意しない -> 2 .
- まったくそう思わない -> 1 .
- したがって、これを使用してセル範囲 E6:E11 に値を入力します .
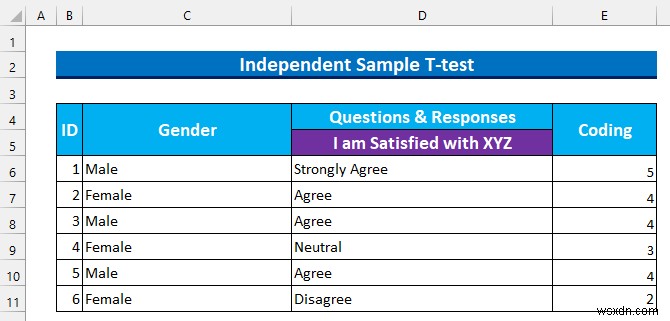
- 次に、「性別」を分けます 」と「コーディング 」列を異なるセル範囲に変換します。
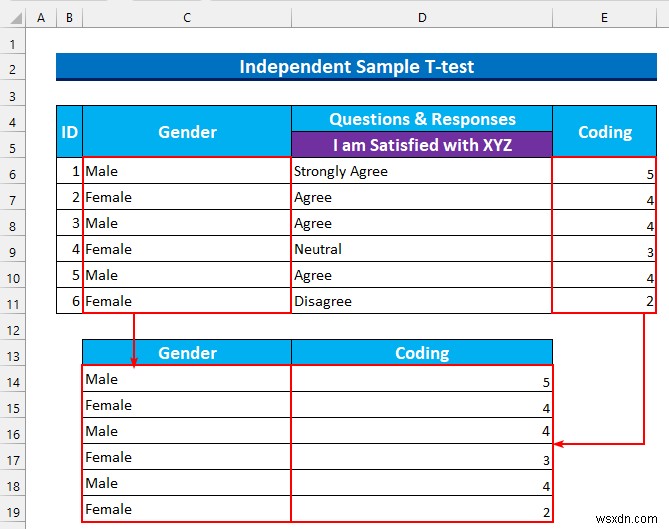
- その後、セル範囲を選択 C14:D19 右クリックしてコンテキスト メニューを表示します .
- 次に、並べ替え から >>>「A から Z に並べ替え」を選択します
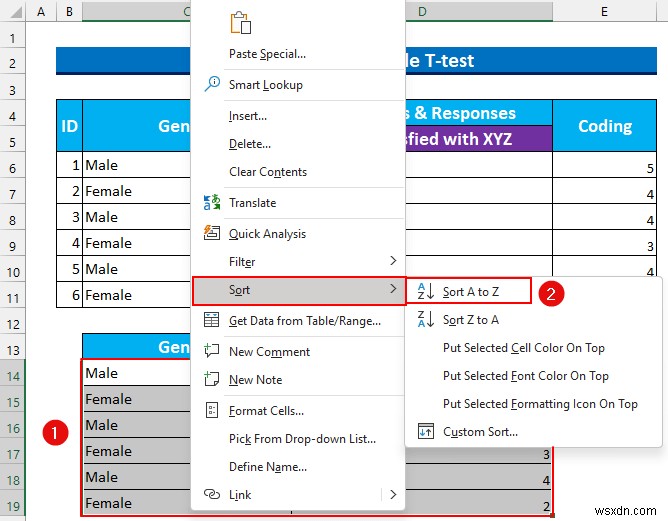
- したがって、同性に対する私たちの価値観は一緒になります。
続きを読む:Excel でデータを分析する方法 (5 つの簡単な方法)
ステップ 2:分析ツールパックを有効にする
データ分析を有効にする必要があります Excel の機能 統計テストを行う前に。
- まず、ALT キーを押します 、F 、次に T Excel のオプションを表示するには ウィンドウ。
- 次に、アドインから >>>「行く…」を選択
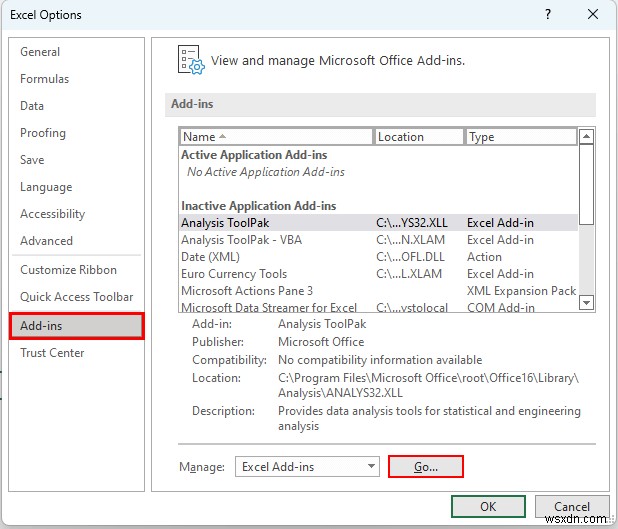
- つまり、[アドイン] ダイアログ ボックス が表示されます。
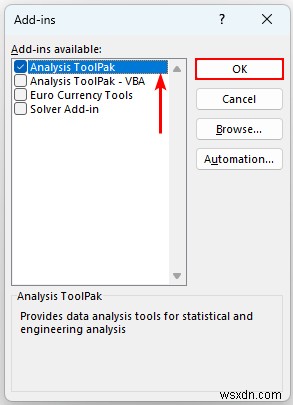
- その後、「分析ツールパック」を選択します 」を押してOKを押します .
- 最後に、データ分析について説明します Data 内のコマンド タブ
続きを読む:[修正:] データ分析が Excel に表示されない (2 つの効果的な解決策)
ステップ 3:平均値を定性的データと比較するための T 検定
「2 サンプル t 検定」を使用します 」、これは「独立サンプル t 検定」とも呼ばれます 」で定性データを分析 . 2 つの仮説または仮定があります:
帰無仮説H 0 : 「2 つのグループが XYZ に等しく満足しています。
対立仮説H a : 「 XYZ に対する 2 つのグループの満足度は同じではありません
p 値が見つかった場合 0.05 未満 帰無仮説の棄却に失敗する .そうでなければ、帰無仮説を棄却します .
- 最後のステップで、分析ツールパックを有効にしました .これは 分析 の下に表示されます
- 次に、[データ分析] をクリックします。
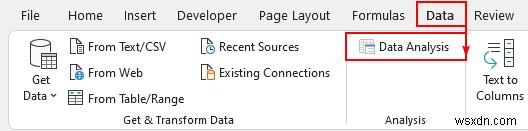
- 次に、「t 検定:不等分散を仮定した 2 サンプル」を選択します 」を押してOKを押します .
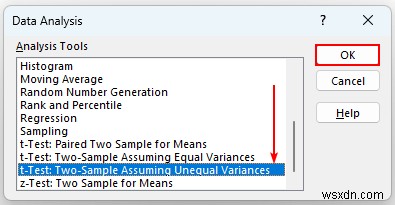
- その後、ダイアログ ボックス 現れる。次のオプションを選択します:
- 変数 1 範囲 – D14:D16 .
- 変数 2 範囲 – D17:D19 .
- これも入れ替えることができますが、結果は同じになります。
- その後、「出力範囲」を選択します 」とセル C21 出力場所として。
- 次に、OK を押します .
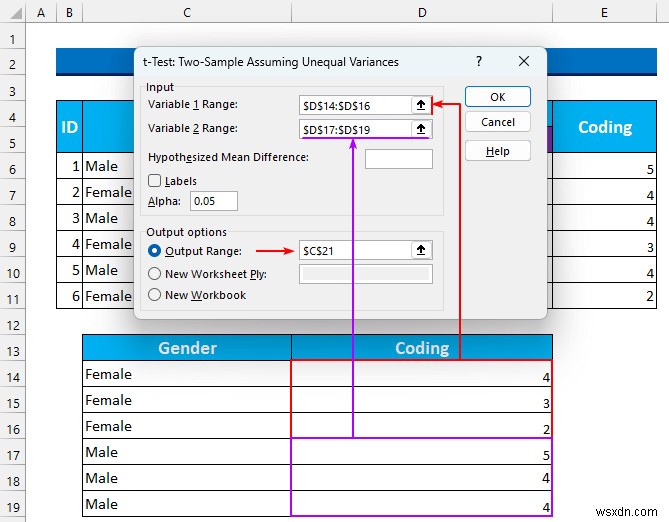
- したがって、出力は次のようになります。
- 次に、平均が であることを確認できます および 4.33 . p値を使用して、この差が有意かどうかを確認します .さらに、分散は 1 です 0.33 であるため、不等分散の仮定は正しかった。この値がほぼ同じである場合は、「t-test:等しい分散を仮定した 2 サンプル」に変更する必要があります。
- したがって、P(T<=t) の両側に集中する必要があります。 値のみ。これは 0.05 未満である必要があります 重要であること。そのまま (0.14 切り上げると) 0.05 以上 、したがって、帰無仮説を棄却 .
- したがって、分析から、男性と女性では満足度が異なると言えます。 カフェ XYZ 、これは統計的に有意です .

ステップ 4:カイ 2 乗検定用のカテゴリ データセットを準備する
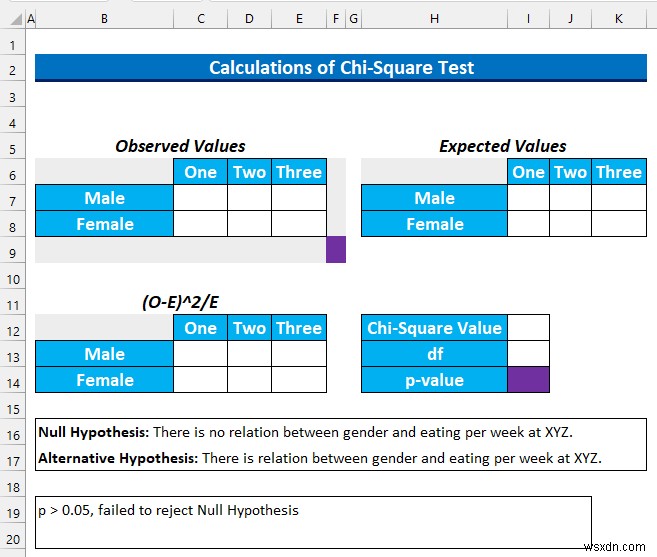
SUM を使用します および COUNTIFS このステップで機能します。ここで、2 番目の質問の分析について説明します。 カイ二乗を使用します テスト 2 つのカテゴリ データ間の関係を調べます。さらに、期待値と観測値の差を返すこともできます。 XYZ cafe で性別と食事回数に関係があるかどうかを調べたい .
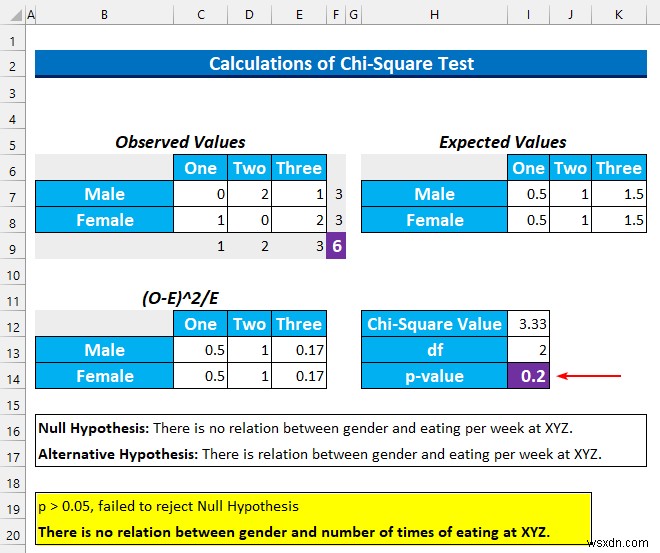
帰無仮説H 0 : 「XYZ では性別と 1 週間の食事に関係はありません。
対立仮説H a : 「XYZ では、性別と 1 週間の食事に関係があります。
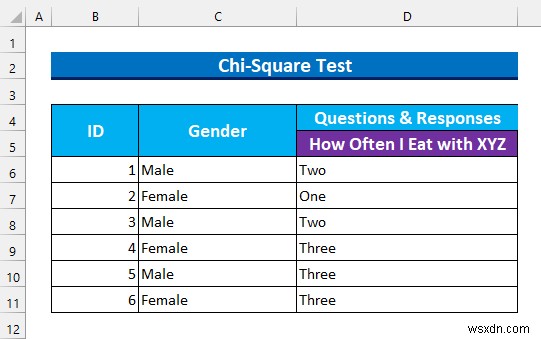
- まず、範囲に C6:C11 という名前を付けます 「性別」として 」とD6:D11 「時間」として
- 次に、カイ 2 乗を計算するためのテンプレートを作成します。 値。
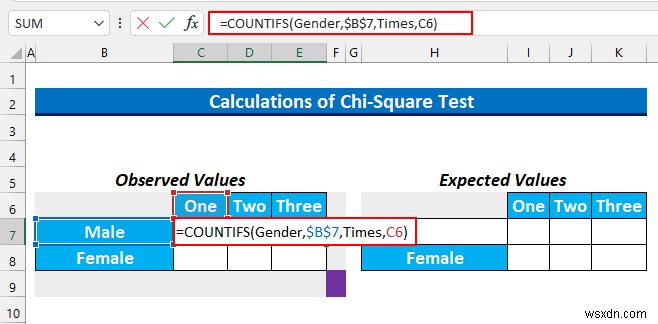
- 次に、セル範囲 C7:E7 を選択します 次の式を入力してください。
=COUNTIFS(Gender,$B$7,Times,C6)
この数式は、男性と 1 を含むセルの数を求めます カフェ XYZ での 1 週間の食事時間 .
- 次に、CTRL+ENTER を押します .これにより、数式が自動入力されます .
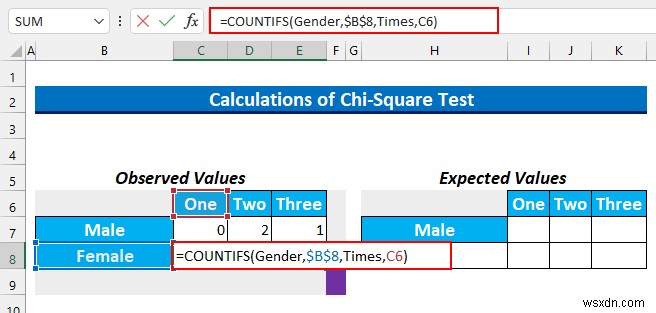
- その後、セル範囲 C8:E8 を選択します 次の式を入力してください。
=COUNTIFS(Gender,$B$8,Times,C6)
この式は、女性と 1 を含むセルの数を求めます カフェ XYZ での 1 週間の食事時間 .
- 次に、CTRL+ENTER を押します .
- その後、行と列を合計します。
- セル範囲を選択 C9:E9 この数式を入力してください。
=SUM(C7:C8)
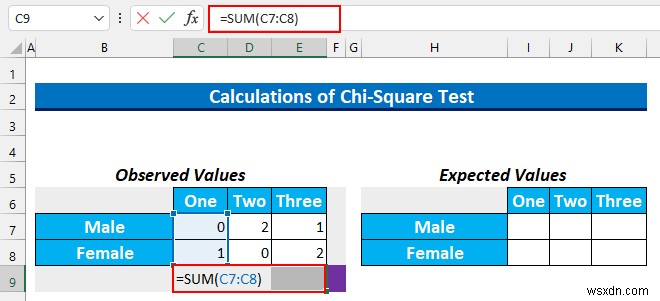
- CTRL+ENTER を押します .
- 次に、セル範囲を選択 F7:F8 この数式を入力してください。
=SUM(C7:E7)
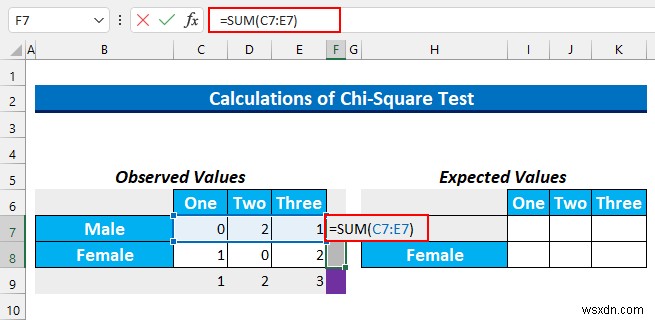
- CTRL+ENTER を押します .
- 次に、6 と入力します セル内 F9 回答者数は6だったので .
- では、期待値を見つけます。それを見つけるための式は 行の合計 * 列の合計/合計 です .
- その後、次の数式をセル範囲 I7:K7 に入力します 事前に選択してください。
=$F$7*C9/$F$9
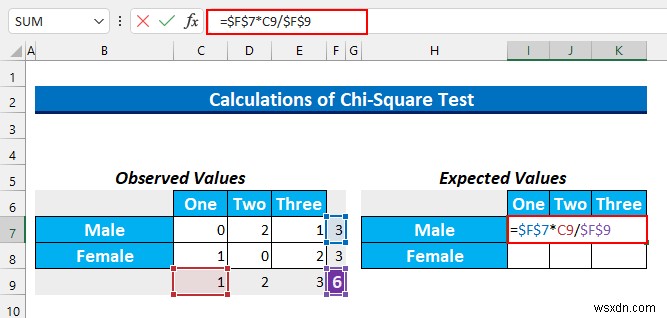
- CTRL+ENTER を押します .
- 次に、セル範囲 I8:K8 を選択します この数式を入力してください。
=$F$8*C9/$F$9
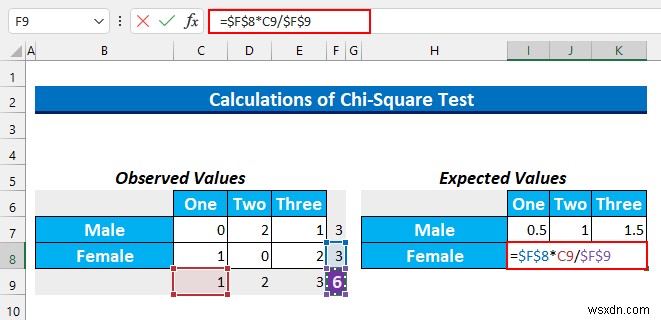
- その後、CTRL+ENTER を押します .
- さて、カイ二乗を見つけます 値。
- では、セル範囲 C13:E14 を選択します 次の式を入力してください。
=(C7-I7)^2/I7
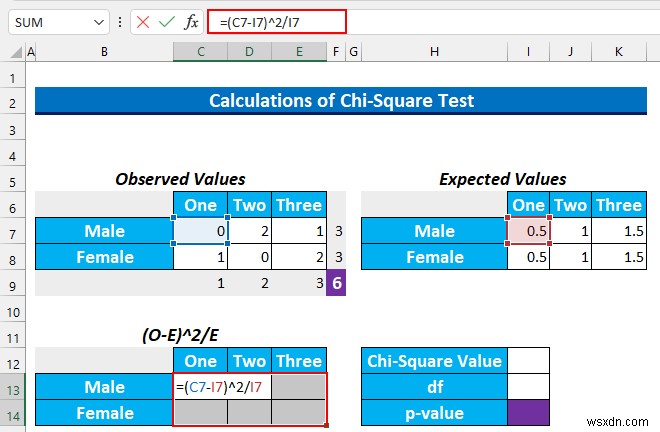
- その後、CTRL+ENTER を押します .
- 次に、これらの値をセル I12 に追加します この数式を入力してください。
=SUM(C13:E14)
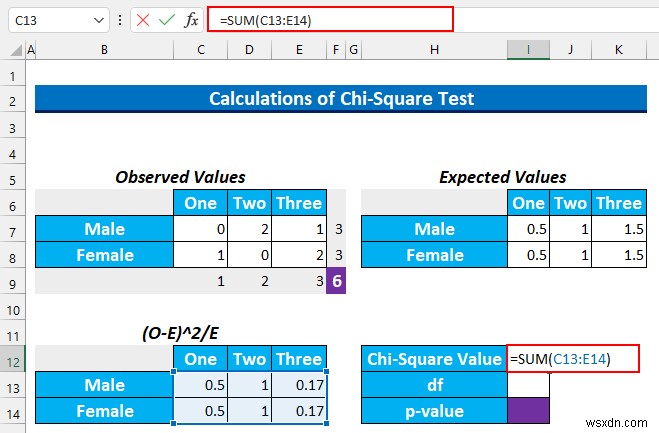
- その後、ENTER を押します .
- さて、df 自由度を意味します .それを見つける式は (列数 -1) * (行数-1) を使用することです . 2 あります 行と 3 列。したがって、私たちの df (3-1)*(2-1) =2 になります .
続きを読む:Excel で大量のデータ セットを分析する方法 (6 つの効果的な方法)
類似の読み物
- Excel で売上データを分析する方法 (10 の簡単な方法)
- ピボット テーブルを使用して Excel でデータを分析する (9 つの適切な例)
- Excel で時系列データを分析する方法 (簡単な手順)
ステップ 5:カイ 2 乗検定を使用して Excel でカテゴリ定性データを分析する
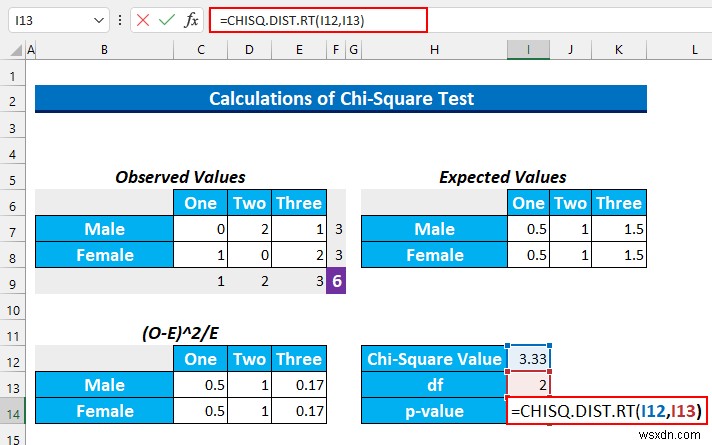
CHISQ.DIST.RT を使用します p値を見つける
- セル I14 に次の式を入力します .
=CHISQ.DIST.RT(I12,I13)
この関数は、「カイ 2 乗分布の右側確率」を返します。
- その後、ENTER を押します . 0.2 の値を取得します 0.05 より大きい .したがって、帰無仮説の棄却に失敗します。 .簡単に言えば、2 つのカテゴリには関係がないと言えます。
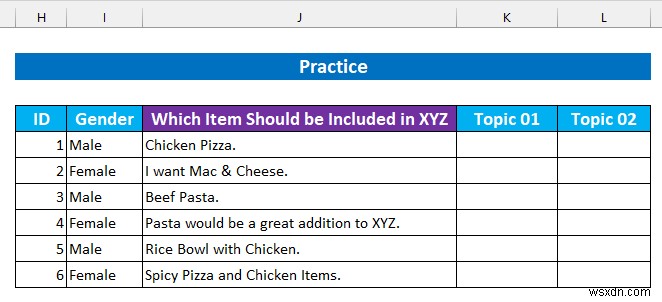
ステップ 6:オープンエンド定性的データのセンチメント分析
では、最後の質問と回答を見ていきます。回答のテーマを見つける手動プロセスを使用します。データセットに「Topic1」という 2 つの列を追加しました。 」および「トピック 2」

- 次に、回答を読み、食べ物のトピックを添付します。たとえば、「チキン」 ピザ 」は 2 あります トピック:「チキン 」と「ピザ 」など
- その後、独自のトピックのみを新しいテーブルに追加しました。
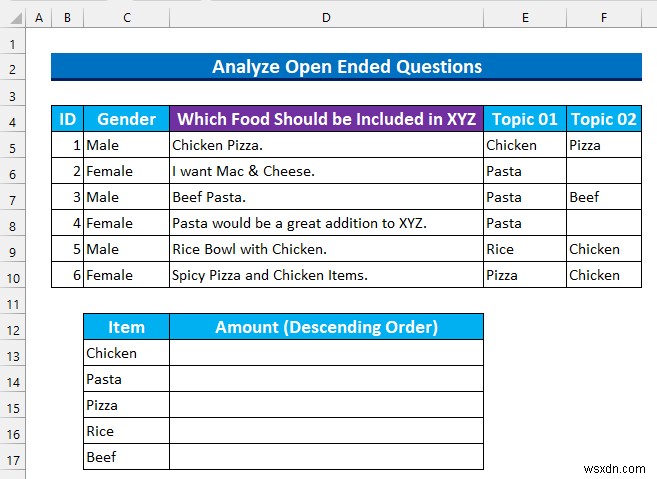
ステップ 7:COUNTIF 関数を使用して制限のない質的データを分析する
COUNTIF 関数を使用します 度数分布への洞察を得るために。
- まず、セル範囲 D13:D17 を選択します 次の式を入力してください。
=COUNTIF($E$5:$F$10,C13)
この数式は、範囲 F5:F10 内の値の数をカウントします セル C13 の値を持つ .
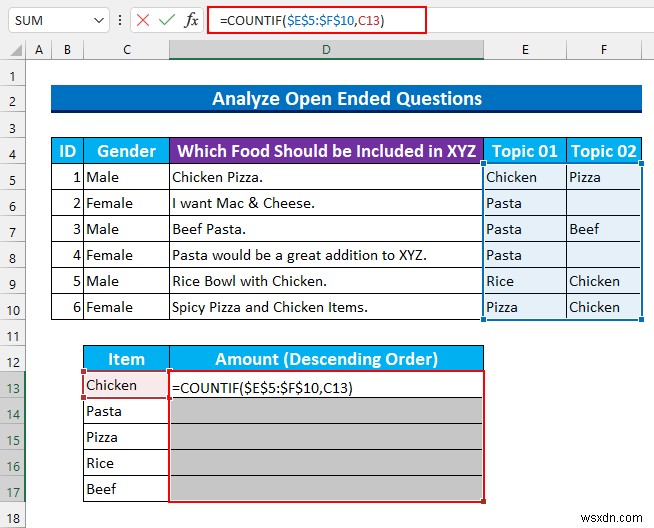
- その後、オートフィル 式、CTRL+ENTER を押します .
- 次に、チャートを挿入します 度数分布を視覚化します。
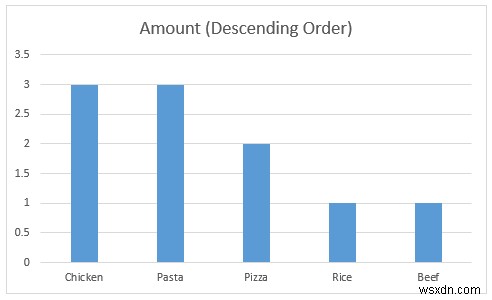
ステップ 8:クラスター化された縦棒グラフを使用して、制限のない質的データを視覚化する
このステップでは、集合縦棒グラフを作成します。 質的データを理解する
- では、セル範囲 C12:D17 を選択します [挿入] タブから、[推奨グラフ] を選択します。 .
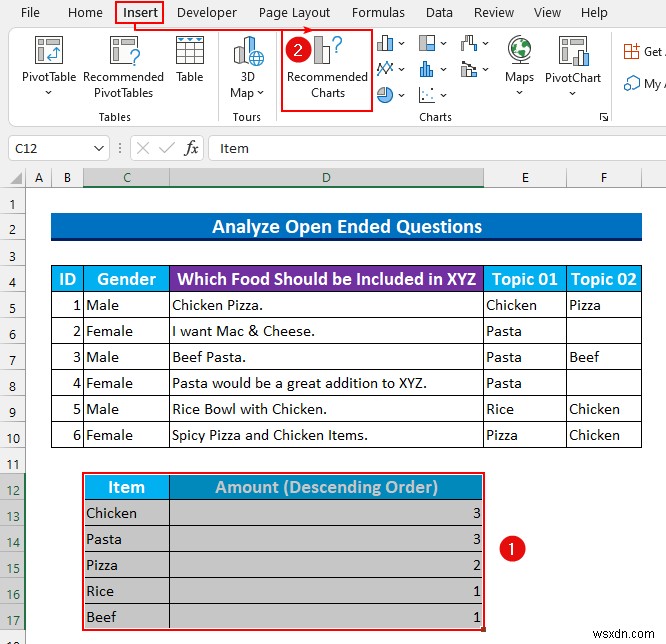
- 次に、グラフの挿入ダイアログ ボックス が表示され、クラスター化された列 がデフォルトで選択されます。そうでない場合は選択してください。
- その後、OK を押します .
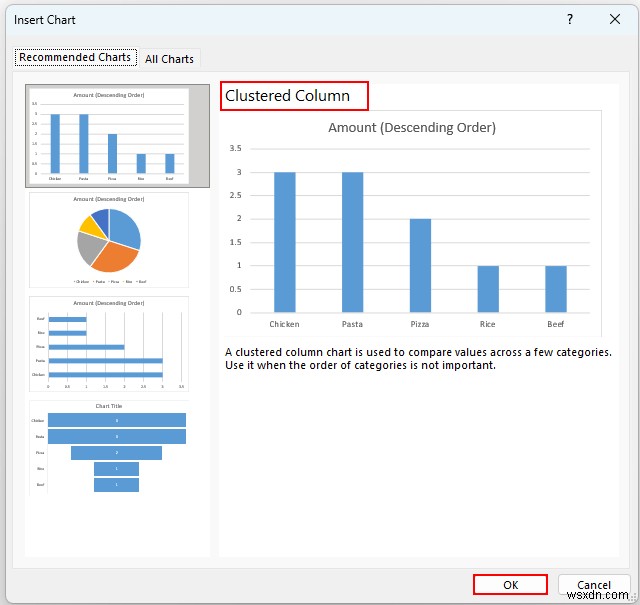
- 次に、顧客がチキンを欲しがっていることがわかります 、パスタ、 と ピザ トップ 3 として XYZ カフェの食品 . XYZ cafe の運営 より多くの収益を生み出すために、これらの製品をより多く提供することを選択できます。
まとめ
- t検定を使用します 平均値を比較するとき 2 つのグループと カイ 2 乗検定 カテゴリ値を扱うとき .
- 私たちのデータセットでは、調査アンケートの 3 つの質問からこれらの結果を取得します-
- カフェ XYZ の満足度は男性と女性で異なります .
- cafe XYZでの性別と食事回数 は関係ありません。
- 学生や顧客がチキンを欲しがっている 、パスタ 、 ピザ Cafe XYZ に含めるアイテムのトップ 3 として .
練習セクション
Excel に各メソッドの実践データセットを追加しました ファイル。したがって、私たちの方法に簡単に従うことができます。
結論
8 を表示しました 質的データを分析する手順 エクセルで .これらの方法に関して問題が発生した場合、または私にフィードバックがある場合は、お気軽に以下にコメントしてください。さらに、私たちのサイト ExcelDemy にアクセスできます その他の Excel 関連 記事。読んでくれてありがとう。これからも頑張ってください!
関連記事
- Excel で qPCR データを分析する方法 (2 つの簡単な方法)
- Excel データ分析を使用してケース スタディを実行する
- Excel でテキスト データを分析する方法 (5 つの適切な方法)
-
Excel でデータ モデルを管理する方法 (簡単な手順)
管理方法を学ぶ必要がある データ モデル エクセルで ?そのようなユニークな種類のトリックを探しているなら、あなたは正しい場所に来ました.この記事では、データ モデルを管理するすべての手順について説明します エクセルで。ここでは、これらすべてを学ぶための完全なガイドラインを紹介します。 次の Excel ワークブックをダウンロードして、理解を深め、練習してください。 Excel のデータ モデルとは Excel データ モデル 2 つ以上のテーブルが 1 つ以上の共有データ セットを介して相互に関連付けられている、特定の形式のデータ テーブルです。 データ モデルのすべてのテーブルのデ
-
Excel ファイルを XML データ マッピングとして保存する方法 (簡単な手順)
Excel に名前を付けて保存する方法を探している場合 XML データ マッピング 、あなたは正しい場所にいます。 XML HTML と同じように機能するマークアップ言語です . XML データを保存および転送するように設計されています。 Excel を使用してデータを XML に保存する場合 形式により、データを Web 上に保存し、他のユーザーがアクセスできるようにすることができます。この記事では、Excel を XML として保存する方法について説明します。 データ マッピング。 Excel ファイルを XML データ マッピングとして保存するための 5 つの手順 Excel