ソルバーと数式を使用して Excel で軽量 ML モデルを構築する

Excel は、基本的な機械学習タスクにとって驚くほど強力なツールです。 これは機械学習プラットフォームではありませんが、組み込み関数とソルバーを使用した線形回帰やロジスティック回帰などの基本的な ML 概念を実証するために効果的に使用できます。
このチュートリアルでは、ソルバーと数式を使用して Excel で軽量の機械学習モデルを構築する方法を示します。
- 線形回帰: 継続的な値(売上収益、住宅価格、テストの得点など)を予測する
- ロジスティック回帰: Yes/No の結果 (顧客の購入、ローン不履行、医療診断、合否など) を予測する
前提条件:
- Microsoft Excel (2016 以降を推奨)。
- ソルバー アドインを有効にします。
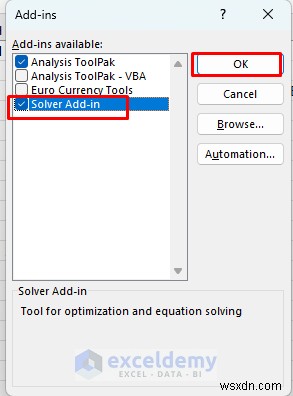
- ファイル に移動します タブ>> オプション を選択します>> アドインを選択します>> Excel アドインを選択します .
- [実行] をクリックします。 .
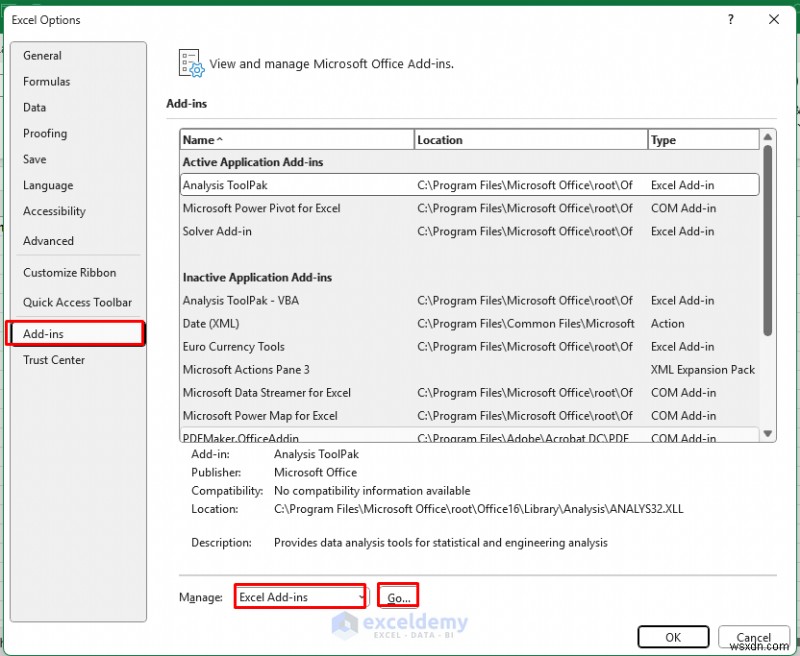
- ソルバー アドインを選択します .
- [OK] をクリックします。 .
- 回帰の概念についての基本的な理解
パート 1:線形回帰モデル
線形回帰は、データ ポイント全体の連続数値を予測するための最適な直線を見つけます。広告費 (X) が売上収益 (Y) を予測するという単純なビジネス シナリオをモデル化します。各データ ポイントは 1 か月分のビジネス データを表します。
ステップ 1:サンプル データのセットアップ
インプット (数千単位の広告支出) とアウトプット (数千単位の売上) の間の明確な線形関係を示す現実的なデータセットを作成します。
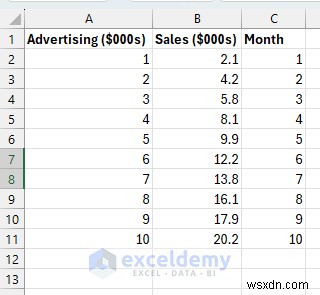
各行は 1 か月分のビジネス データです。広告費が増加すると、売上収益も増加しますが、完全に増加するわけではありません (ある程度のランダム性はありますが、これは現実的です)。
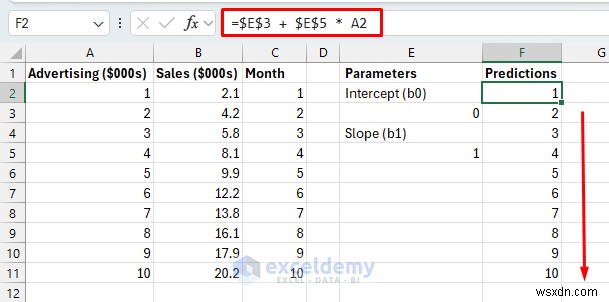
ステップ 2:予測式を作成する
最適なラインを見つけるためにモデルが調整する数学的な「ノブ」を設定します。線形回帰では、2 つのパラメータが必要です。
- インターセプト (b0) :線が Y 軸と交差する場所 (広告料 0 ドルのベースライン売上)。
- 坂道 (b1) :広告が 1,000 ドル増加するごとに売上がどれだけ増加するか
モデル パラメータを別のセルに設定します。
モデルパラメータ:
Predicted Y = b0 + b1 * X
- インターセプト (b0)
- 初期値 0
- スロープ (b1)
- 初期値 1
この線形方程式を使用して、広告費に基づいて売上を予測します。これはモデルの中核であり、広告の量を取得して、売上のあるべき額を推定します。
数学的意味:
- b0 =0.5 および b1 =2 の場合、広告に 3,000 ドルを費やすと、0.5 + 2*3 =6.5,000 ドルの売上が予測されます。
- モデルはデータから b0 と b1 の最適な値を学習します。
予測式:
- セルを選択し、次の数式を挿入します。
- この数式を F11 までドラッグします。
ステップ 4:残差と誤差を計算する
私たちの予測がどれだけ間違っているかを測定してください。モデルはこれらのエラーを最小限に抑えようとして学習するため、これは非常に重要です。
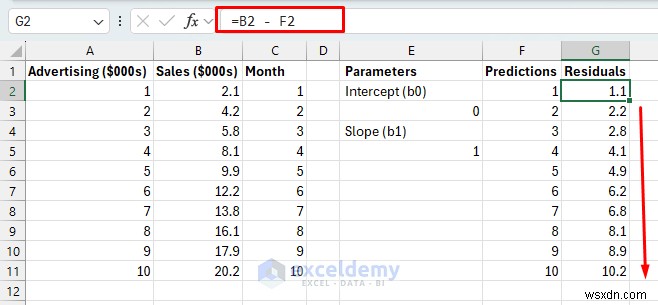
- 残差: 各月の実際の売上と予測売上の差
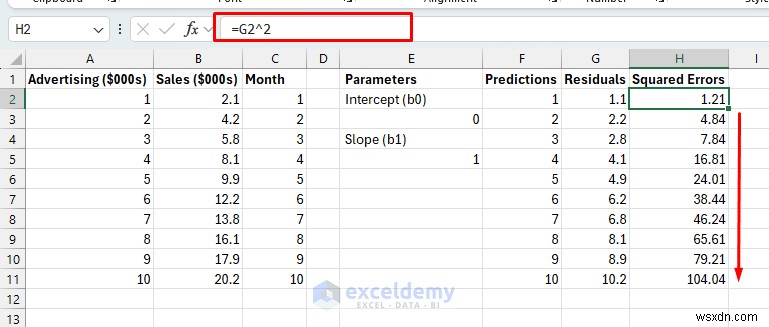
- 二乗誤差: 残差の二乗 (すべてのエラーを正にし、大きなエラーにさらにペナルティを与えるため)。
残差:
- 数式を G11 までドラッグします。
二乗誤差:
- 数式を H11 まで下にドラッグします。
ステップ 5:エラー メトリックを計算する
ビジネスに意味のあるモデルのパフォーマンスの測定値を作成します。これらの指標は、モデルが実際の使用に十分であるかどうかを理解するのに役立ちます。
指定された領域に主要なメトリクスを設定します。
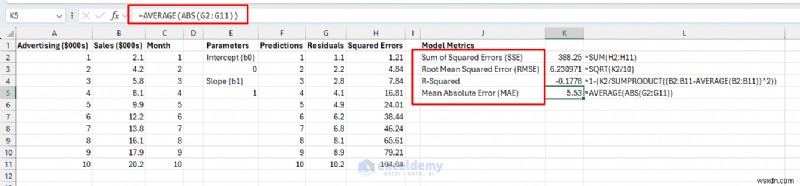
エラー指標:
- 誤差二乗和 (SSE): すべての予測の合計誤差 - 低いほど優れています。
- 二乗平均平方根誤差 (RMSE): 元の単位($000 単位)での平均誤差 – 解釈が容易になります。
- R 二乗: 広告によって説明される売上変動の割合(0 ~ 100%、高いほど良い)
=1-(K2/SUMPRODUCT((B2:B11-AVERAGE(B2:B11))^2))
- 平均絶対誤差 (MAE): 平均絶対誤差 – RMSE よりも外れ値の影響を受けにくい
ステップ 6:ソルバーを使用してパラメータを最適化する
Excel が予測誤差を最小限に抑える最適な切片と傾きの値を自動的に見つけられるようにします。
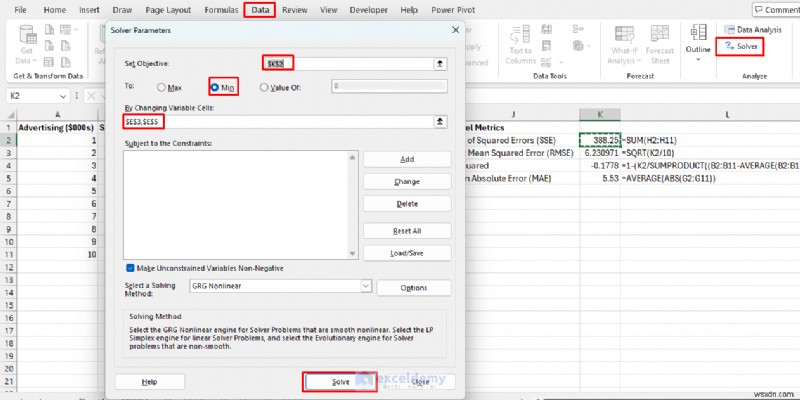
- データ に移動します。 タブ>> ソルバーを選択します .
- 目標の設定:K2 (SSE セル)。
- 宛先:分 .
- 変数セルを変更する:E3、E5 (パラメータ)。
- [解決] をクリックします。 .
- [OK] をクリックします。 .
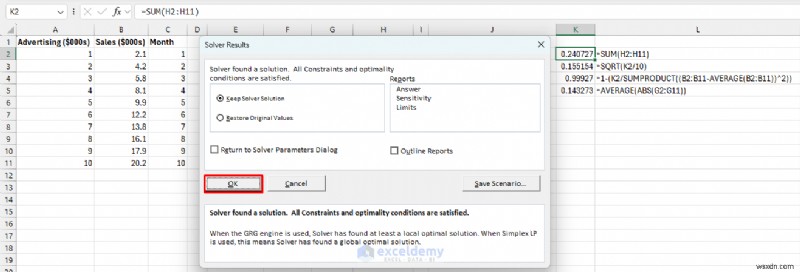
- b0 と b1 の何百万もの異なる組み合わせを試します。
- 各組み合わせの合計誤差を計算します。
- 誤差が最も少ない組み合わせが見つかるまで調整を続けます。
- これは推測するよりもはるかに高速かつ正確です。

ステップ 7:ビジュアライゼーションの作成
モデルを視覚的に検証することは理にかなっています。ほとんどのデータ ポイントの近くを通る予測線を見てみましょう。
- 「広告」列と「売上」列を選択します。
- 挿入 に移動します。 グラフ のタブ>>>> 散布図を選択します .
- グラフを右クリック>> データ を選択します。>> [シリーズの追加] を選択します。 .
- シリーズ名: セル F1 を選択します。
- シリーズ X の値: X 値を選択します (例:B2:B11)
- シリーズ Y の値: 予測値 F2:F11 をクリックして選択します。
- 予測シリーズを線としてフォーマットします。
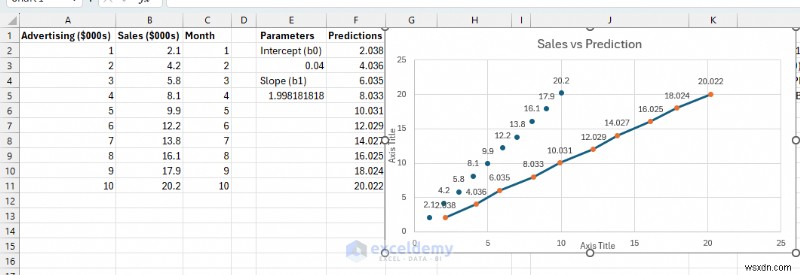
- 予測線はデータ ポイントの一般的な傾向に従います。
- 点はラインの周囲に点在しています (すべてが上または下にあるわけではありません)。
- 残差に明らかなパターンがない。
パート 2:ロジスティック回帰モデル
ロジスティック回帰は、はい/いいえの決定の確率を予測します。正確な数値を予測する線形回帰とは異なり、ロジスティック回帰は何かが起こる可能性 (0 ~ 100%) を予測します。
ステップ 1:バイナリ分類データを準備する
顧客の購入行動をモデル化してみましょう。顧客の収入レベル (X) に基づいて、顧客がプレミアム製品を購入するか (1)、購入しないか (0) を予測したいと考えています。これは、マーケティングのターゲティング、医療診断、またはあらゆる二者択一の決定において一般的です。
ロジスティック回帰用のデータを設定します:
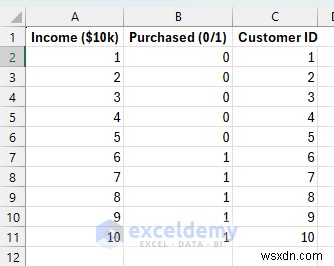
顧客の収入レベル (10,000 ドル単位) と購入の意思決定。低所得の顧客 (1 ~ 5) は (0) を購入しない傾向がある一方、高所得の顧客 (6 ~ 10) は (1) を購入する傾向があることに注目してください。これは現実的な購入パターンを反映しています。
ステップ 2:ロジスティック予測式を作成する
ロジスティック モデル パラメータの初期化:
ロジスティック関数のパラメータを設定します。線形回帰とは異なり、これらのパラメータはより複雑な数学的変換 (シグモイド関数) を通じて機能します。
- インターセプト (b0) :しきい値を左または右にシフトします (50% の確率が発生する場所)。
- 坂道 (b1) :「可能性が低い」から「可能性が高い」への移行の急勾配を制御します。
- 開始値 :まず合理的な推測から始めます。ソルバーがそれらを最適化します。
ロジスティックパラメータ:
Probability = 1 / (1 + e^(-(b0 + b1×X)))
- インターセプト (b0)
- -2 (初期値)
- スロープ (b1)
- 0.5 (初期値)
ロジスティック予測式を作成する:
シグモイド関数を使用して、線形結合を確率に変換します。これは、予測を 0 から 1 の間に保つ数学的な魔法です。
- 線形結合 :b0 + b1*X (線形回帰と同じ)。
- シグモイド変換 :1/(1+e^(-(線形結合))) は、任意の数値を 0 ~ 1 の範囲に変換します。
- 結果 :確率を表す滑らかなS字カーブ。確率が 0.7 の場合、この顧客が購入する確率は 70% です。
確率予測:
- 線形結合:
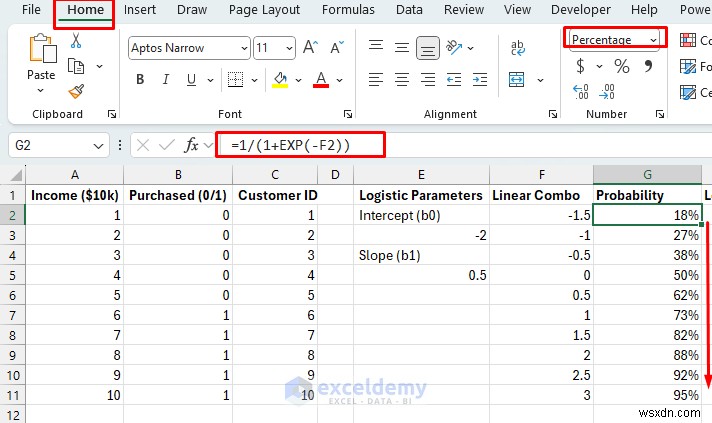
- 確率予測:
- セルをパーセンテージ (%) として書式設定します。 .
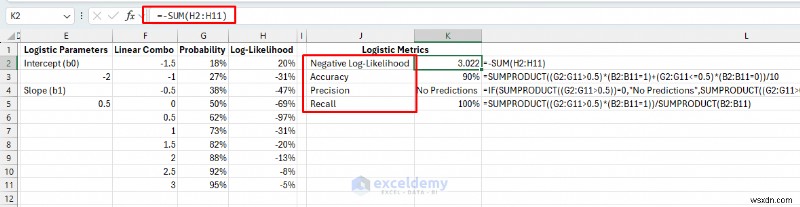
ステップ 4:対数尤度を計算する
確率予測が実際の結果とどの程度一致しているかを測定します。正確な値ではなく確率を扱っているため、これは単純なエラーよりも複雑です。
対数尤度コンポーネント:
=IF(B2=1,LN(MAX(G2,0.0001)),LN(MAX(1-G2,0.0001)))

- バイナリ結果の場合、単純な減算(実際の値と予測値)を使用することはできません。
- 代わりに、予測を踏まえた実際の結果にどれだけ「驚いたか」を測定します。
- 購入の可能性が 90% であると予測し、顧客が購入したとしても、私たちは驚かない(良いモデル)
- 購入の可能性が 10% であると予測し、顧客が購入した場合、私たちは非常に驚きます (悪いモデル)
ステップ 5:ロジスティック モデルの指標を設定する
分類パフォーマンスのビジネス関連の尺度を作成します。これらの指標は、モデルが実際のビジネス上の意思決定を行うのに十分であるかどうかを判断するのに役立ちます。
精度が高いということは、無駄なマーケティング費用が少なくなる (誤検知が少ない) ことを意味します。再現率が高いということは、潜在的な顧客を逃さないことを意味します (偽陰性が低い)。
ロジスティック指標:
- モデルの適合/負の対数尤度: 値が低いほど、確率予測がより適切になることを意味します。
- 精度: 正しく分類された顧客の割合(カットオフとして 50% を使用した場合)
=SUMPRODUCT((G2:G11>0.5)*(B2:B11=1)+(G2:G11<=0.5)*(B2:B11=0))/10
- 精度: 購入すると予測した顧客の何パーセントが購入しましたか?
=IF(SUMPRODUCT((G2:G11>0.5))=0,"No Predictions",SUMPRODUCT((G2:G11>0.5)*(B2:B11=1))/SUMPRODUCT((G2:G11>0.5)))
- 思い出してください: 購入した顧客の何パーセントを特定しましたか?
=SUMPRODUCT((G2:G11>0.5)*(B2:B11=1))/SUMPRODUCT(B2:B11)
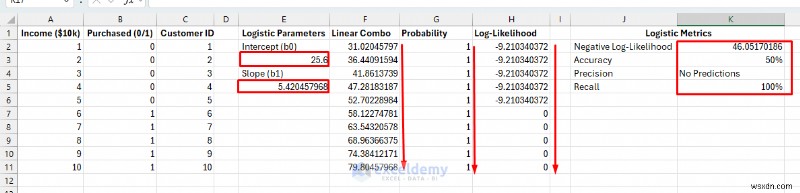
ステップ 6:ソルバーを使用してロジスティック モデルを最適化する
データ内の確率パターンに最もよく適合するパラメーター値を見つけます。ソルバーは負の対数尤度を最小化し、実際のデータを観測する確率を最大化します。
- データ に移動します。 タブ>> ソルバーを選択します .
- 目標の設定:K2 (負の対数尤度)。
- 宛先:分 .
- 変数セルを変更する:E3、E5 .
- [解決] をクリックします。 .
一般的な問題のトラブルシューティング
- ソルバーが収束しない :別の初期値を試すか、反復を増やしてください。
- 負の R 二乗 :データ入力エラーまたはモデル仕様を確認してください。
- 物流における完全な分離 :特徴量を減らすか、正則化を追加します。
結論
このチュートリアルでは、Excel で直接機械学習モデルを構築する手順を段階的に説明します。 Excel には専用の ML ツールと比較すると制限がありますが、モデルの仕組みを理解するための透明性とアクセシビリティが提供されます。 Excel のソルバーと基本的な数式を使用すると、これらの軽量の機械学習モデルを迅速に実装し、予測を視覚化し、シンプルかつ洞察力に富んだ方法でモデルの精度を理解することができます。ここで示した手法は、より複雑なシナリオに拡張でき、回帰の概念を学習するための教育ツールとして役立ちます。
ソリューション付きの高度な Excel 演習を無料で入手しましょう!-
Word、Excel、PowerPointで定規の単位を変更する方法
Microsoft Wordは、水平定規と垂直定規を使用して、段落、表、画像などを配置します。文章のスタイルに合ったレイアウトにするだけでなく、ドキュメントの印刷方法を決定することも重要です。デフォルトでは、これらの定規の単位はインチに設定されていますが、選択した単位に簡単に変更できます。このガイドでは、 Wordで定規の単位を変更する方法を説明します。 、 Excel 、および PowerPoint インチからcm、mm、ポイント、パイカまで。 WordとExcelでルーラーの単位を変更する これは、すべてのOfficeインストールで機能します。コンピューターのOffice365
-
Excel で XML を使用してカスタム リボンを追加する方法
カスタム リボンを追加する方法を探しています XML を使用 エクセルで?次に、これはあなたにぴったりの場所です。ここでは、 カスタム リボン を追加する手順を順を追って説明します。 XML を使用 ワークブックをダウンロードして、自分で練習できます。 Excel で XML を使用してカスタム リボンを追加する手順 一部の学生の学生 ID を含むデータセットがあるとします。 、名前 、マーク .次に、 MsgBox を開く方法を示します。 カスタム リボン を追加して XML を使用して Excel で 自分で行うには、以下の手順に従ってください。 ステップ 1:E