高度な分析のロックを解除:Excel の Python でデータ分析を強化

Excel の Python は、Excel セル内で Python コードを直接記述して実行できる強力な Microsoft 365 機能です。 Python 分析の能力を Excel にもたらします。セルに Python を直接入力すると、Python の計算が Microsoft Cloud で実行され、結果がワークシートに返されます。 Excel の使い慣れたインターフェイスと再計算を Python の豊富なエコシステムと組み合わせて、スプレッドシートから離れたりローカルに何かをインストールしたりすることなく、データ分析、クリーニング、統計、視覚化を行うことができます。
このチュートリアルでは、Excel で Python を使用する方法と、それがいつ、どのように役立つかを示します。 Jupyter や VS Code などの他のツールに切り替える代わりに、Excel で Python を直接使用できます。
要件と可用性
- Microsoft 365 サブスクリプション: 多くの有料プラン (一般消費者向け、ファミリー/個人向け、商用、教育向け、エンタープライズ向け) で利用できます。一部の機能や高度なコンピューティングにはアドオンが必要な場合があります。
- プラットフォーム: 主に Windows デスクトップ Excel で利用できます。サポートは Web、Mac、モバイルごとに異なります。 Excel for iPad、Excel for iPhone、Excel for Android では利用できません。
- ローカル Python は必要ありません: プリインストールされたライブラリを使用して、すべてがクラウドで実行されます。 Excel で Python を使用するために、Python のローカル バージョンは必要ありません。ローカル バージョンの Python がコンピュータにインストールされている場合、そのインストールに対して行ったカスタマイズは、Python in Excel の計算には反映されません。
重要: Excel で Python を使用するには、インターネット アクセスが必要です。これは、Python in Excel の計算が、標準バージョンの Python 言語を使用して Microsoft クラウドで実行されるためです。
Excel で Python の使用を開始する
セル内で Python を有効にする:
- セルを選択
- 数式に移動します タブ>> Python の挿入 を選択します。
- または「=PY」と入力します。 セル内で Tab を押します。
- 数式バーが緑色に変わり、Python モードであることを示します
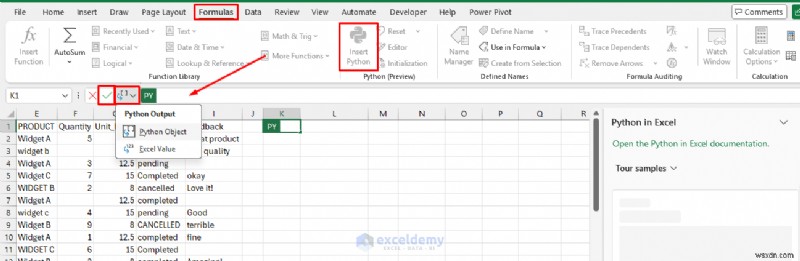
xl() 関数:Excel と Python の橋渡し
Excel で Python を使用するための鍵は、xl() 関数です。この関数を使用すると、Python コードでスプレッドシートからデータを直接読み取ることができます。
- 編集モードで、クリックしてドラッグしてセルまたは範囲(例:A1:D100)を選択します
- Excel は xl(“A1:D100”) などの参照を挿入します
# pandas DataFrame として範囲を参照する
df =xl(“A1:D100”, headers=True)
# 単一のセル値を参照する
ターゲット =xl(“F1”)
これは、Python がスプレッドシート データを「認識」する方法です。これを =PY() セル内に記述し、結果を通常の Python オブジェクトとして操作します。
出力オプション:
- 数式バーのドロップダウンを使用してExcel 値として返します。 (ネイティブ Excel セル/テーブルに変換) またはPython オブジェクトとして保持します。 (他の Python セルでのチェーン用)
- Ctrl + Alt + Shift + M を押します。 出力タイプを切り替える
- 場合によっては、デバッグまたは出力に print() を使用します
再計算: Python のセルは、他の数式と同様、入力が変化すると (自動モードで) 自動的に再計算されます。
ヒント: 小さなことから始めましょう。データを選択し、Python を挿入して DataFrame に変換し、.head()、.describe()、または単純な操作を使用して探索します。
Excel で Python が役立つ場合
1.高度なデータ クリーニングと変換
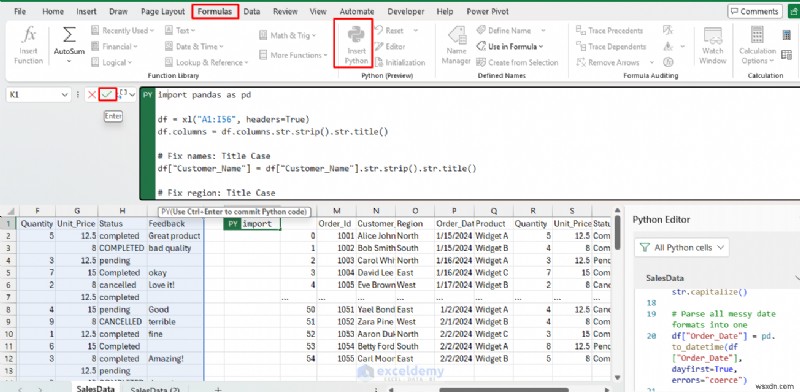
Python では、乱雑な日付を簡単に修正し、テキスト (大文字、スペース) を標準化し、null と重複を処理し、ワイド データを長い形式にアンピボットし、一貫性のない形式や欠損値を管理できます。 Pandas を使用すると、これらのタスクが簡潔になり、再現可能になります。
Python:
import pandas as pd
df = xl("A1:I56", headers=True)
df.columns = df.columns.str.strip().str.title()
# Fix names: Title Case
df["Customer_Name"] = df["Customer_Name"].str.strip().str.title()
# Fix region: Title Case
df["Region"] = df["Region"].str.strip().str.title()
# Standardize product: Title Case
df["Product"] = df["Product"].str.strip().str.title()
# Standardize status and feedback
df["Status"] = df["Status"].str.strip().str.capitalize()
df["Feedback"] = df["Feedback"].str.strip().str.capitalize()
# Parse all messy date formats into one
df["Order_Date"] = pd.to_datetime(df["Order_Date"], dayfirst=True, errors="coerce")
# Fill missing quantity with median
df["Quantity"] = pd.to_numeric(df["Quantity"], errors="coerce")
df["Quantity"] = df["Quantity"].fillna(df["Quantity"].median())
df
- チェックマークをクリックします。 またはCtrl+Enterを押します。 コードを実行する
- 出力セルのカード アイコンをクリック>> arrayPreview を選択します
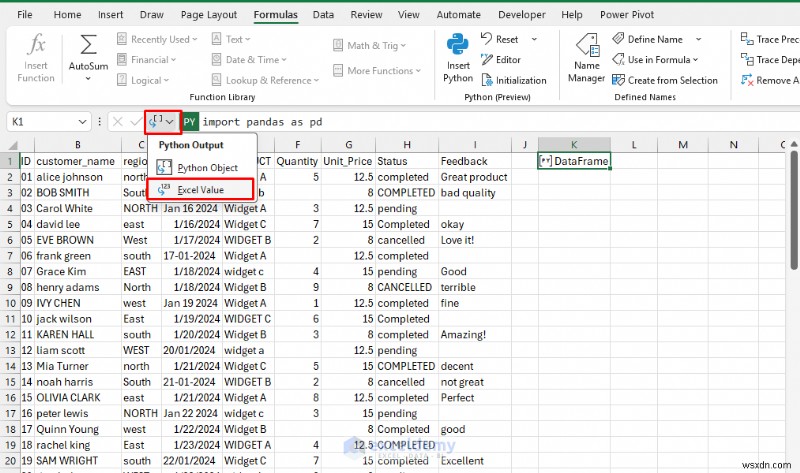
クリーンアップされた DataFrame は自動的にシートに戻ります。結果を Excel 値として返し、クリーンなデータをさらなる分析と計算に使用します。
- 数式バーからドロップダウンを展開します。>> Excel 値を選択します
- 次に、クリーンアップされた新しいデータを他の例で使用します
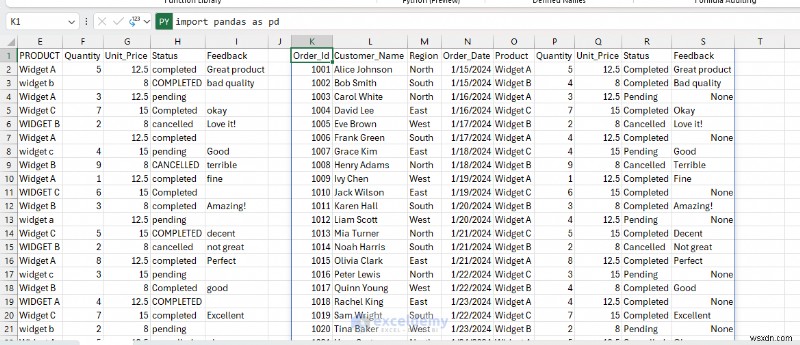
2.複雑なデータ分析と統計
Python を使用すると、複雑なグループ化、複数ステップの変換、統計集計など、Excel の組み込み関数を超える操作が可能になります。また、時系列分析、回帰、クラスタリング、外れ値検出、テキストのセンチメント分析、モンテカルロ シミュレーションもサポートしています。
Python:
import pandas as pd
# Load data from the SalesData sheet
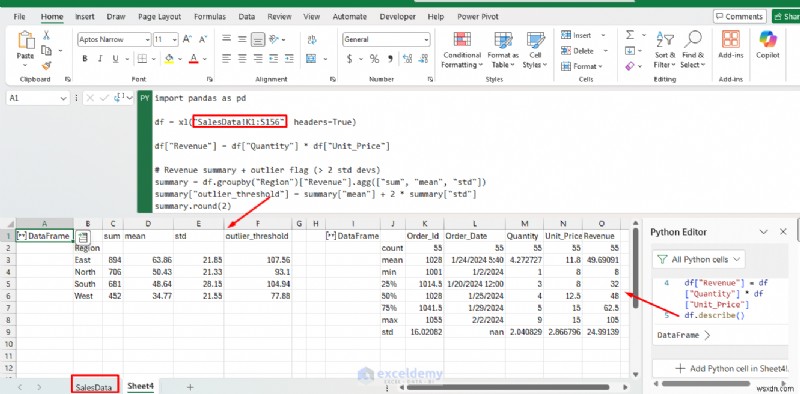
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# Revenue summary + outlier flag (> 2 std devs)
summary = df.groupby("Region")["Revenue"].agg(["sum", "mean", "std"])
summary["outlier_threshold"] = summary["mean"] + 2 * summary["std"]
summary.round(2)
結果は、テーブルとしてシートに直接反映されます。 df.describe() を使用することもできます。 データフレーム全体の概要統計を表示します。
Python:
import pandas as pd
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
df.describe()
3.より良いグラフと視覚化
Matplotlib、Seaborn、plotnine を使用すると、密度プロット、群プロット、ワード クラウド、または小さな倍数などの専門的なプロットを簡単に作成できます。これらは Excel グラフよりもはるかに柔軟です。 matplotlib と seaborn を使用して、Excel のネイティブ チャートを超えてみましょう。
Python:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
fig, ax = plt.subplots(figsize=(8, 4))
sns.boxplot(data=df, x="Region", y="Revenue", palette="Set2", ax=ax)
ax.set_title("Revenue Distribution by Region")
ax.set_xlabel("Region")
ax.set_ylabel("Revenue ($)")
fig
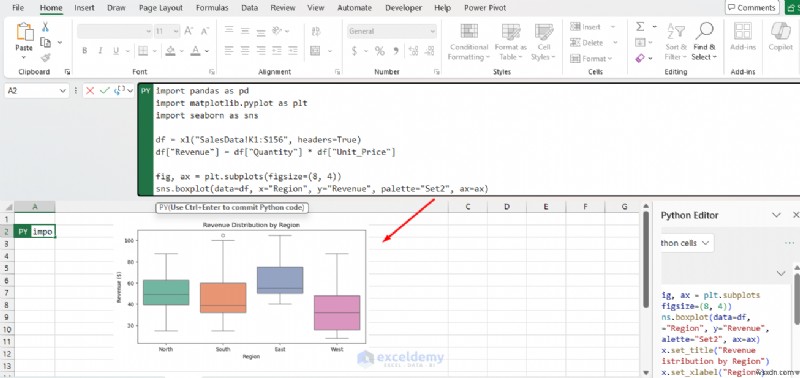
グラフはワークシート内に画像オブジェクトとして直接表示され、他の Excel グラフと同様にサイズ変更や位置変更が可能です。
4.スプレッドシート データの機械学習
Python を使用すると、予測モデリングと予測が可能になります。 Excel データに対して statsmodels または scikit-learn を直接使用して、より正確な予測やシンプルな機械学習モデルを構築できます。
Excel を終了せずに予測モデルを実行します:
Python:
import pandas as pd
from sklearn.linear_model import LinearRegression
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
# Convert to numeric and fill missing values with median
df["Quantity"] = pd.to_numeric(df["Quantity"], errors="coerce")
df["Unit_Price"] = pd.to_numeric(df["Unit_Price"], errors="coerce")
df["Quantity"] = df["Quantity"].fillna(df["Quantity"].median())
df["Unit_Price"] = df["Unit_Price"].fillna(df["Unit_Price"].median())
# Calculate Revenue
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# One-hot encode Product
X = pd.get_dummies(df[["Product", "Unit_Price"]], drop_first=True)
y = df["Revenue"]
# Fit the Linear Regression model
model = LinearRegression().fit(X, y)
# Add predictions
df["Predicted_Revenue"] = model.predict(X).round(2)
# Create final result with useful columns
result = df[["Order_Id", "Product", "Revenue", "Predicted_Revenue"]].copy()
result["Difference"] = (result["Revenue"] - result["Predicted_Revenue"]).round(2)
# Optional: Show model performance
print("Model R² Score:", round(model.score(X, y), 4))
result
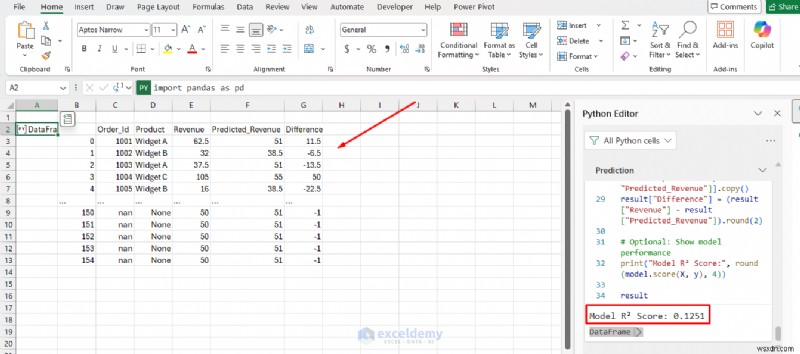
ビジネス アナリストは、別の環境に切り替えることなく、機械学習モデルを既存のデータに適用できます。
5.ローリング計算と時系列
Excel の数式だけを使用して移動平均、累積合計、ラグ特徴を計算するのは困難です。 Python はこれらのタスクを簡素化します。
Python:
import pandas as pd
# Load your full sales data
df = xl("SalesData!K1:S156", headers=True)
# Calculate Daily Revenue
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# Rolling Calculations (Time Series)
# Sort by date first (important for time series)
df = df.sort_values("Order_Date").reset_index(drop=True)
# 7-day Rolling Metrics on Revenue (weekly trend)
df["Revenue_7d_Mean"] = df["Revenue"].rolling(window=7, min_periods=1).mean().round(2)
df["Revenue_7d_Sum"] = df["Revenue"].rolling(window=7, min_periods=1).sum().round(2)
df["Revenue_7d_Max"] = df["Revenue"].rolling(window=7, min_periods=1).max().round(2)
df["Revenue_7d_Std"] = df["Revenue"].rolling(window=7, min_periods=1).std().round(2)
# 30-day Rolling Mean (monthly trend)
df["Revenue_30d_Mean"] = df["Revenue"].rolling(window=30, min_periods=1).mean().round(2)
# Cumulative Revenue (running total)
df["Cumulative_Revenue"] = df["Revenue"].cumsum().round(2)
# Select columns to display
result = df[["Order_Id", "Order_Date", "Product", "Revenue",
"Revenue_7d_Mean", "Revenue_7d_Sum", "Revenue_30d_Mean",
"Cumulative_Revenue"]]
result
このアプローチは、販売傾向の分析、日次または週次の変動の平滑化、異常の検出、勢いの予測に役立ちます。
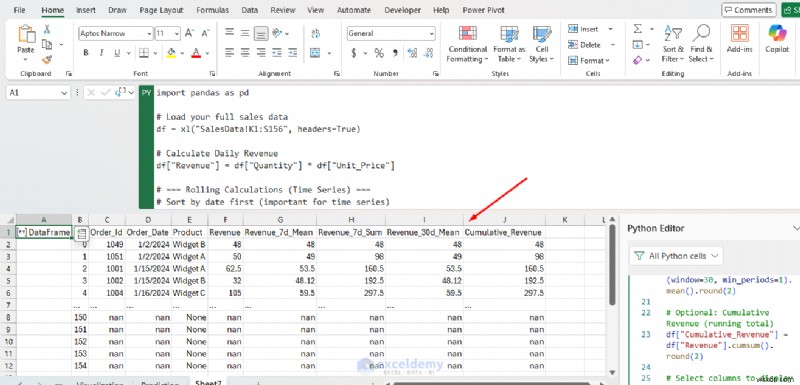
- 収益_7d_平均: 7 日間移動平均 (週次の売上傾向を平滑化)
- 収益_7d_合計: 過去 7 日間の総収益
- 収益_30d_平均: 30 日移動平均 (長期トレンド)
- 累積収益: その日までのすべての収益の累計
ヒントとベスト プラクティス
- チェーンセル: 以前の Python オブジェクト (変数として表示される) を参照して、単一のセルを乱雑にせずに複数ステップのワークフローを構築する
- パフォーマンス: 大量の計算を行う場合は、クラウド クォータに注意してください。必要に応じて、大規模なタスクをステップに分割するか、プレミアム コンピューティングを使用する
- セキュリティ: コードは分離されたクラウド コンテナーで実行されます。機密性の高い操作は避けてください。 Microsoft はプライバシーを管理します
- デバッグ: print() を使用するか、DataFrame を段階的に出力します。セルにエラーが表示される
- Excel と組み合わせる: 複雑な作業には Python を使用し、書式設定、ピボット、ダッシュボードには Excel を使用する
- 学習曲線: Python を初めて使用する場合は、まずパンダに注目してください。多くの無料のチュートリアルとサンプル ファイルが利用可能です
- 共有: 互換性のある Microsoft 365 を使用する受信者は、結果を表示または更新できます。それ以外の場合、結果は静的な値に変換されます
知っておくべき制限事項
- クラウドのみでの実行。インターネット接続が必要です
- 標準プランでのコンピューティング割り当て
- Python 環境は Anaconda によって管理されます。独自のパッケージをインストールしたり、ローカルのカスタマイズを使用したりすることはできません
- モバイルとウェブのサポートはデスクトップに比べて制限されています
- 非常に大規模なデータセットまたは長時間実行されるコードはタイムアウトに達する可能性があります
結論
Excel の Python は、作業がまだ基本的にスプレッドシート ベースであるものの、分析自体はより高度になっている場合に最も役立ちます。データ クリーニング、DataFrame スタイルの分析、高度な統計、視覚化に優れています。 Excel はすでに十分に処理できますが、日常的なスプレッドシートのタスクにはあまり役に立ちません。 Excel の Python は、スプレッドシート ユーザーとデータ サイエンティストの間のギャップを埋め、使い慣れたワークフローを中断することなく高度な分析にアクセスできるようにします。分析が数式だけでは複雑すぎる場合には、Excel を Python に置き換えるのではなく、Python を選択的に使用します。
ソリューション付きの高度な Excel 演習を無料で入手しましょう!-
Microsoftの無料PowerPointビューアの使用方法
PowerPointドキュメントを開いたり編集したりするために、コンピューターにPowerPointをインストールする必要はありません。これらのファイルを作成、共有、編集、印刷、および開くには、Microsoftが承認した2つの方法があり、どちらも100%無料です。 Microsoftは、無料のビューアツールを使用してPowerPointなしでPowerPointファイルを開くことを許可していましたが、表示のみに制限されており、Webサイトからは利用できなくなりました。現在使用できるのは、Webベースバージョンまたはモバイルアプリのいずれかです。 この記事の説明は、PowerPoint O
-
Windows11/10上のMicrosoftOutlookで古いアイテムを自動アーカイブする
Microsoft Outlookを使用したことがある場合 Windows PC 、メールをアーカイブするかどうかを尋ねるポップアップが突然表示される場合があります。 Outlookは定期的にそうするように通知しますが、この投稿では、古いアイテムの自動アーカイブの使用方法を説明します。 メール、タスク、メモ、連絡先など、Microsoft Outlook 2021/19で、Windows11/10/8/7のOutlookパフォーマンスをオンデマンドで改善します。 自動アーカイブ Outlookの機能は、古いアイテムを自動的にアーカイブして次の場所に移動し、.pst形式で保存すること