プロフェッショナル向けの Excel データ分析を向上させる Python ライブラリ トップ 5

Excel はデータ分析のための最も強力なツールの 1 つですが、限界があります。データセットが数百万行に増加したり、レポートを自動的に実行する必要がある場合、または分析に機械学習が必要な場合、Excel だけでも時代遅れになり始めます。 Python はこれらのギャップの多くを埋めます。 Python の統合により、Excel は従来のスプレッドシート ツールからより強力なデータ分析プラットフォームに変わりました。 Excel 内で Python を直接利用できるため、アナリストはワークブックを離れることなく、高度な計算を実行し、予測モデルを構築し、高度なビジュアライゼーションを生成できるようになりました。
このチュートリアルでは、すべてのプロが使用すべき高度な Excel データ分析のための 5 つの Python ライブラリを紹介します。これらのライブラリを使用すると、高度なデータ操作、視覚化、機械学習を Excel 内で直接実行できます。
1. Pandas – データ操作と分析の中核
Excel 分析用の Python ライブラリを 1 つだけ学習する場合は、Pandas を学習してください。 まず。 Pandas は、Python でのほぼすべての高度な Excel 関連タスクの基盤です。 Excel データを強力なデータフレームに変換します。 大規模なデータセットを効率的にクリーニング、変換、フィルタリング、グループ化、結合、集約、探索するために使用します。
Excel プロの主な強み:
- pd.read_excel() を使用して Excel ファイルをネイティブに読み書きします とdf.to_excel()
- 乱雑なデータの処理:重複を削除し、欠損値を埋め、形式を標準化する
- ピボットテーブルを超えるロジックを使用して高度なグループ化と集計を実行する
- 複数のシートまたはファイルを結合または結合する
- df.describe() を使用して統計概要を生成する
- 数行のコードを実行すると、毎回同じ結果が得られます
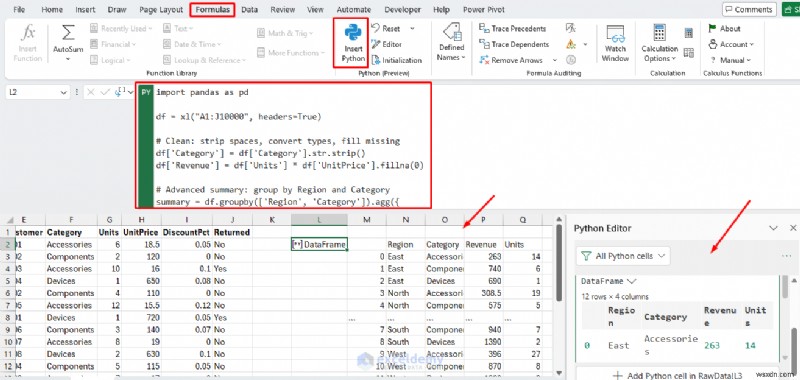
例:乱雑なデータのクリーニング
Excel でよくある問題は、型が混在し、値が欠落し、書式が一貫していないデータを受信することです。 Pandas を使用すると、1 つの反復可能なスクリプトですべてを修正できます。
Excel での Python:
import pandas as pd
df = xl("A1:J10000", headers=True)
# Clean: strip spaces, convert types, fill missing
df['Category'] = df['Category'].str.strip()
df['Revenue'] = df['Units'] * df['UnitPrice'].fillna(0)
# Advanced summary: group by Region and Category
summary = df.groupby(['Region', 'Category']).agg({
'Revenue': 'sum',
'Units': 'sum'
}).reset_index()
summary
VS コードの Python:
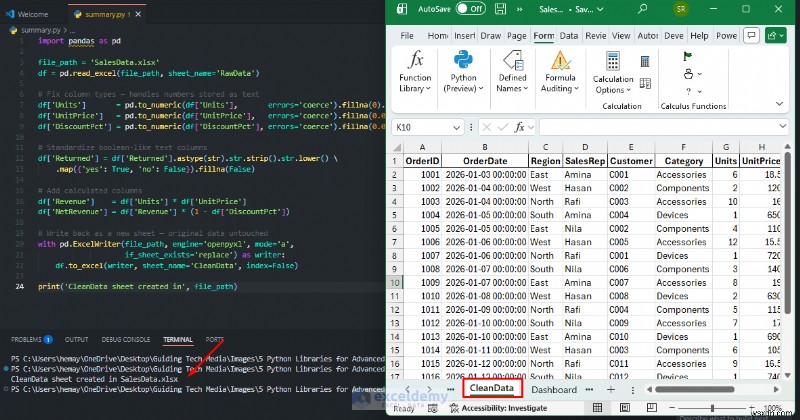
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='RawData')
# Fix column types — handles numbers stored as text
df['Units'] = pd.to_numeric(df['Units'], errors='coerce').fillna(0).astype(int)
df['UnitPrice'] = pd.to_numeric(df['UnitPrice'], errors='coerce').fillna(0.0)
df['DiscountPct'] = pd.to_numeric(df['DiscountPct'], errors='coerce').fillna(0.0)
# Standardize boolean-like text columns
df['Returned'] = df['Returned'].astype(str).str.strip().str.lower() \
.map({'yes': True, 'no': False}).fillna(False)
# Add calculated columns
df['Revenue'] = df['Units'] * df['UnitPrice']
df['NetRevenue'] = df['Revenue'] * (1 - df['DiscountPct'])
# Write back as a new sheet — original data untouched
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
df.to_excel(writer, sheet_name='CleanData', index=False)
print('CleanData sheet created in', file_path)
概要レポートの自動化
手動ピボットテーブルを Pandas groupby に置き換えます。 数秒で実行され、データが更新されるたびにすぐに共有できるシートをエクスポートするワークフロー:
summary = (
df.groupby(['Region', 'Category'], as_index=False)
.agg(
Orders = ('OrderID', 'count'),
Units = ('Units', 'sum'),
NetRevenue = ('NetRevenue', 'sum'),
Returns = ('Returned', 'sum')
)
)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
summary.to_excel(writer, sheet_name='Summary', index=False)
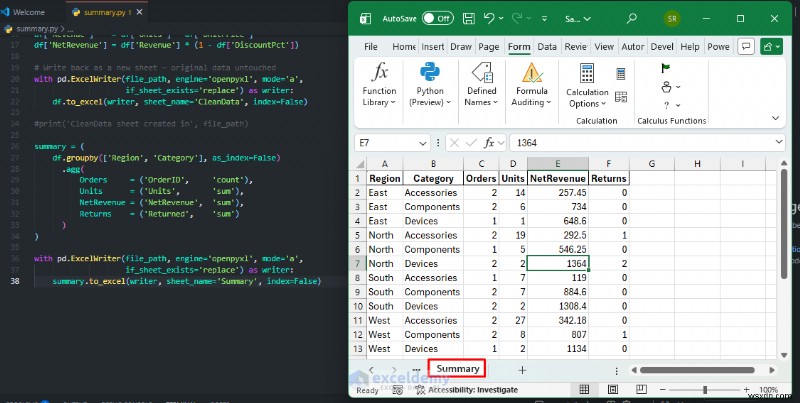
いつ使用するか: ピボットテーブル スタイルの出力が得られますが、クリーンアップとロジックは同じワークフローで行われます。つまり、壊れたレポートが減り、手動による介入が減ります。パワー ユーザーは、特にデータセットが数千行を超える場合、クリーニングや要約の手順を繰り返す必要がある場合、または複数のソースからのデータを自動的にマージする必要がある場合に、ネイティブ Excel には大きすぎる、または複雑すぎるデータセットを処理するために Pandas を利用します。
2. OpenPyXL – 高度な Excel ファイル操作とネイティブ書式設定
Pandas がデータを処理する一方で、OpenPyXL .xlsx のきめ細かい制御に優れています。 ファイル:Excel ネイティブの機能を失うことなく、セルの書式設定、グラフ、表、スタイル、数式、画像の追加。 .xlsx を直接操作できます。 ファイルを作成できるため、Python ワークフローは、生の分析だけではなく、Excel 対応の出力を生成できます。
Excel プロの主な強み:
- プログラムでワークブックを作成および変更する
- クリーンアップされたテーブルを新しいシートにエクスポートする
- プロ仕様のグラフを Excel 形式で直接追加し、自動的に更新する
- 古いレポート タブを自動的に置き換えます
- 条件付き書式、枠線、フォント、スタイルを特定のセルに適用する
- =SUM() などの Excel 数式を挿入する または =VLOOKUP() セルに
- プログラムでシートを保護し、ペインを固定し、列幅を設定する
- Python 以外のユーザー向けにワークブックベースの成果物を構築する
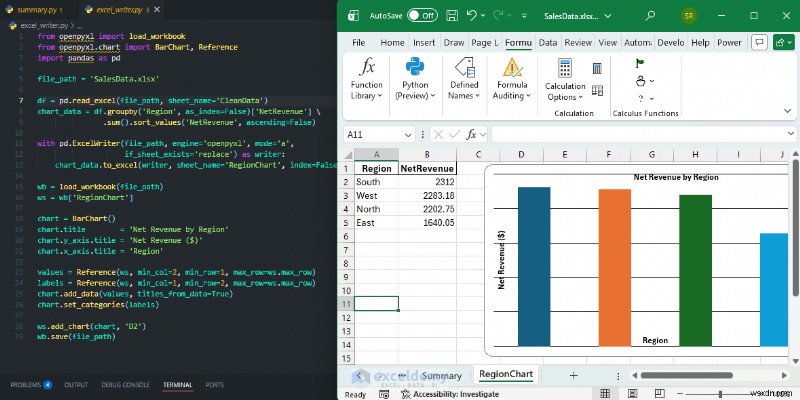
例:ワークブックにネイティブ グラフを追加する
Pandas でクリーンなデータを生成した後、Excel を手動で開かずに、openpyxl を使用して本格的な棒グラフを追加します。
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='CleanData')
chart_data = df.groupby('Region', as_index=False)['NetRevenue'] \
.sum().sort_values('NetRevenue', ascending=False)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
chart_data.to_excel(writer, sheet_name='RegionChart', index=False)
wb = load_workbook(file_path)
ws = wb['RegionChart']
chart = BarChart()
chart.title = 'Net Revenue by Region'
chart.y_axis.title = 'Net Revenue ($)'
chart.x_axis.title = 'Region'
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, 'D2')
wb.save(file_path)
いつ使用するか: Pandas はデータの分析に役立ちます。 openpyxl はそれを提供するのに役立ちます。 OpenPyXL は、手作りのように見えるレポートやダッシュボードなどのピクセル完璧な Excel 出力が必要な場合、および結果を .xlsx に保存する必要がある場合に使用します。 同僚が引き続き編集できるネイティブの Excel グラフと書式設定を含むファイル。
3. Matplotlib – Excel チャートを超えた強力な視覚化
Excel のグラフも便利ですがMatplotlib アナリストがより詳細に制御できるようになります。 Matplotlib は、静的で出版品質のプロットを作成するための頼りになるライブラリです。高度にカスタマイズ可能であり、Pandas とうまく統合されているため、迅速な探索的分析が可能です。
Excel プロの主な強み:
- ヒートマップ、傾向線を含む散布図、箱ひげ図、ヒストグラム、3D グラフなどの高度なプロットを作成する
- フォント、色、グリッド線、目盛り、凡例をより細かく制御できる
- 複数のグラフを一度に表示する複数パネルのサブプロット レイアウトを作成する
- OpenPyXL を使用して、画像、PDF、または SVG にエクスポートしたり、ビジュアルを Excel に埋め込んだりする
- カスタム ラベルと矢印を使用してデータ ポイントに注釈を付ける
例:マルチパネル販売ダッシュボードの作成
2 つのパネルからなるグラフを作成してみましょう。左側に月次収益の傾向、右側にカテゴリの内訳が表示されます。次に、それを高解像度画像として保存し、あらゆるレポートに使用できるようにします。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
df['Month'] = pd.to_datetime(df['OrderDate']).dt.to_period('M')
monthly = df.groupby('Month')['NetRevenue'].sum()
cat_rev = df.groupby('Category')['NetRevenue'].sum().sort_values(ascending=True)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
fig.suptitle('Sales Performance Dashboard', fontsize=16, fontweight='bold')
# Left panel — monthly revenue line chart
ax1.plot(list(monthly.index.astype(str)), monthly.values,
marker='o', color='#1E5FAD', linewidth=2)
ax1.set_title('Monthly Net Revenue')
ax1.set_xlabel('Month')
ax1.set_ylabel('Revenue ($)')
ax1.yaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
ax1.tick_params(axis='x', rotation=45)
ax1.grid(axis='y', linestyle='--', alpha=0.5)
# Right panel — revenue by category horizontal bar chart
ax2.barh(cat_rev.index, cat_rev.values, color='#217346')
ax2.set_title('Revenue by Category')
ax2.set_xlabel('Revenue ($)')
ax2.xaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
plt.tight_layout()
plt.savefig('sales_dashboard.png', dpi=150, bbox_inches='tight')
print('Dashboard saved as sales_dashboard.png')
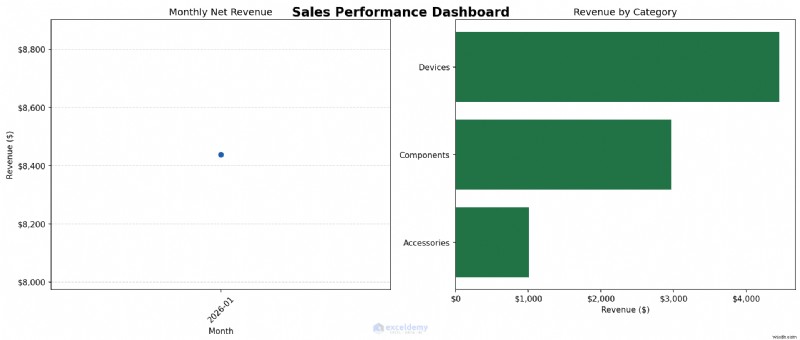
いつ使用するか: 最初に Python を使用して分析チャートを作成します。次に、グラフを Python 出力のままにするか、要約されたデータを Excel に返して最終的なダッシュボードの書式設定を行うかを決定します。レポートやプレゼンテーション用のグラフが必要な場合、または一貫したスタイルで更新されたデータから同じグラフを繰り返し作成する必要がある場合は、Matplotlib を使用します。
4. Seaborn – 統計データの視覚化
シーボーン Matplotlib に基づいて構築されており、統計的な視覚化に重点を置いています。パターンと相関関係を強調する、視覚的に魅力的なグラフの作成を簡素化します。 Matplotlib では洗練されたグラフを作成するために数十行が必要になる場合がありますが、Seaborn では魅力的なデフォルトのスタイルを使用して 1 ~ 2 行で同様の結果を得ることができます。データに隠された分布、相関関係、パターンを明らかにすることに優れています。
Excel プロの主な強み:
- 統計グラフを迅速に作成する
- 探索的なデータ分析に適している
- 相関ヒートマップを作成して列が互いにどのように関連しているかを確認する
- 密度曲線を組み込んだ分布プロットを作成する
- 箱ひげ図とバイオリンプロットを使用してグループを視覚的に比較する
- 数値列にわたる自動散布図行列のペア プロットを作成する
- 信頼区間を含む回帰プロットを 1 行で生成する
例:相関ヒートマップの作成
Excel データ内の隠れたパターンを見つけます。どの変数が一緒に移動するか?ヒートマップはこれに迅速に答えることができ、Excel の組み込みツールが通常提供するものをはるかに超えています。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
correlation = df.select_dtypes(include='number').corr()
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation,
annot=True, # show correlation values in each cell
fmt='.2f',
cmap='coolwarm', # red = positive, blue = negative
center=0,
square=True,
linewidths=0.5
)
plt.title('Correlation Matrix — Sales Variables', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('correlation_heatmap.png', dpi=150)
print('Heatmap saved!')
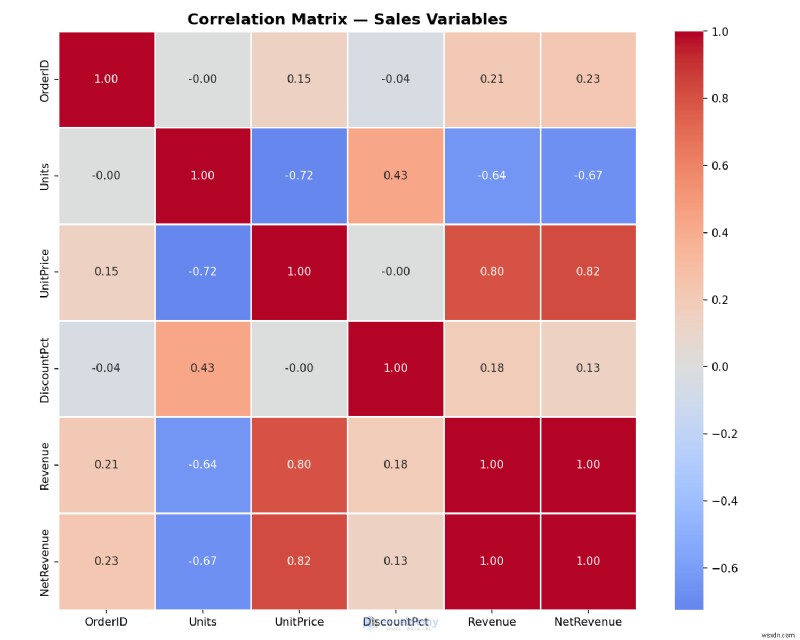
例:1 行で箱ひげ図を作成する
地域間の収益分布を比較して、異常値を即座に特定します。
plt.figure(figsize=(10, 6))
sns.boxplot(data=df, x='Region', y='NetRevenue', hue='Region', palette='Set2', legend=False)
plt.title('Revenue Distribution by Region')
plt.ylabel('Net Revenue ($)')
plt.tight_layout()
plt.savefig('region_boxplot.png', dpi=150)
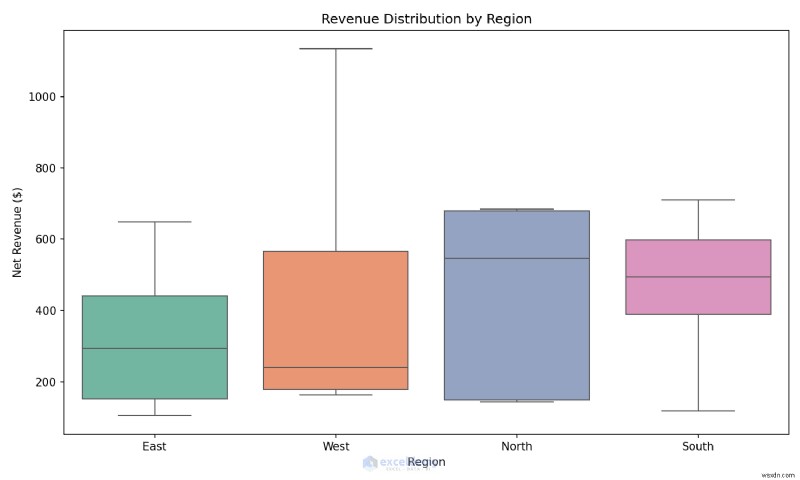
いつ使用するか: 正式なレポートを作成する前に、分布、外れ値、関係をすばやく理解したい場合は、探索的分析中に Seaborn を使用します。
5. Scikit-learn – Excel データで直接機械学習
これは、レポート作成から意思決定サポートに移行するライブラリです。 Scikit 学習 プロフェッショナルな機械学習を Excel ワークフローに導入します。これにより、ネイティブ Excel では簡単に処理できない回帰、分類、クラスタリング、予測などの予測分析が Excel ユーザーに可能になります。データ内で何が起こったかを説明するだけでなく、売上予測から顧客の分類、異常の検出まで、次に何が起こるかを予測するのに役立ちます。
Excel プロの主な強み:
- 数値的な結果やカテゴリ(解約リスクや売上予測など)を予測するための線形回帰とロジスティック回帰
- 解釈可能な予測のためのデシジョン ツリーとランダム フォレスト
- 類似したレコードを自動的にグループ化する K 平均法クラスタリング
- モデルの精度を測定するためのトレーニングとテストの分割と相互検証
- 機能のスケーリング、エンコード、前処理パイプライン
- フィルタリングと並べ替えのために予測を Excel に返す
例:純収益の予測
過去の販売データに基づいてモデルをトレーニングし、それを使用して新規注文の収益を予測します。これは、Excel がネイティブで実行できない分析です。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import LabelEncoder
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
# Encode categorical columns as numbers
for col in ['Region', 'Category', 'SalesRep']:
if col in df.columns:
df[col] = LabelEncoder().fit_transform(df[col].astype(str))
X = df[['Units', 'UnitPrice', 'DiscountPct', 'Region', 'Category']]
y = df['NetRevenue']
# Split: 80% train, 20% test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train a Random Forest model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate accuracy
predictions = model.predict(X_test)
print(f'Mean Absolute Error: ${mean_absolute_error(y_test, predictions):,.2f}')
print(f'R² Score: {r2_score(y_test, predictions):.4f}')
# Export predictions back to Excel
results = X_test.copy()
results['Actual'] = y_test.values
results['Predicted'] = predictions
results.to_excel('predictions.xlsx', index=False)
print('Predictions exported to predictions.xlsx')
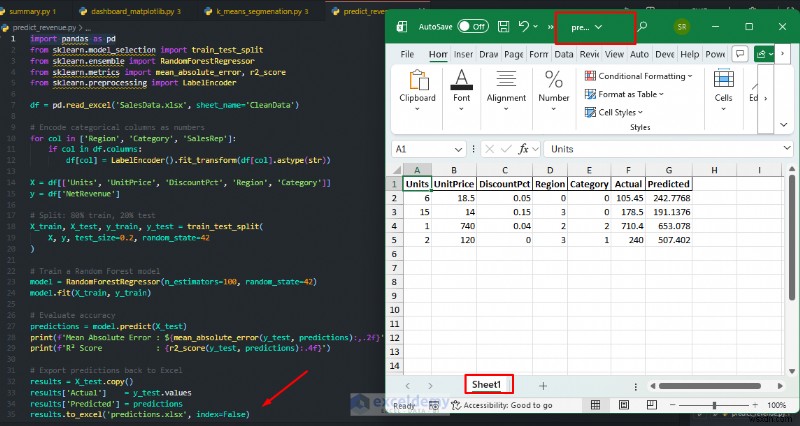
K 平均法による顧客セグメンテーション:
手動による基準を必要とせず、購買行動に基づいて顧客を自動的にグループに分類します。
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
customer = df.groupby('Customer').agg(
TotalOrders = ('OrderID', 'count'),
TotalRevenue = ('NetRevenue', 'sum'),
AvgDiscount = ('DiscountPct', 'mean')
).reset_index()
X_scaled = StandardScaler().fit_transform(
customer[['TotalOrders', 'TotalRevenue', 'AvgDiscount']]
)
customer['Segment'] = KMeans(n_clusters=3, random_state=42, n_init=10) \
.fit_predict(X_scaled)
customer.to_excel('customer_segments.xlsx', index=False)
print('Segmentation complete! See customer_segments.xlsx')
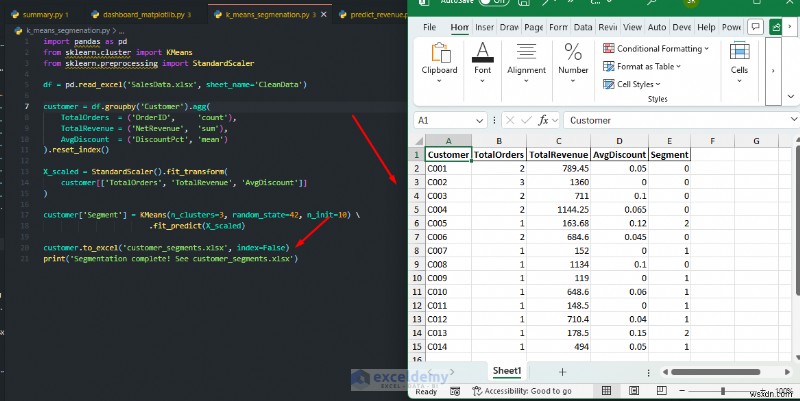
いつ使用するか: 予測をワークシートに書き戻すと、Excel ユーザーが結果をフィルター、並べ替え、グラフ化したり、数式や条件付き書式と組み合わせたりできるようになります。これにより、専門家は機械学習の洞察をスプレッドシートに直接追加できるようになります。 Scikit-learn は、将来の値を予測したり、レコードを分類したり、ピボットテーブルでは明らかにできない自然なグループを発見したりする必要がある場合に使用します。
ボーナス:Xlwings – 双方向オートメーションと Live Excel の統合
xlwings ライブラリは Excel インスタンスをリアルタイムで実行します。 Python と Excel を橋渡しし、真の自動化を可能にします。 openpyxl は静的ファイルの読み取りと書き込みを行いますが、xlwings では Excel を開いてライブで操作し、値を Python に読み取り、Excel ボタンから Python 関数をトリガーし、セルに表示される完全な UDF (ユーザー定義関数) を構築できます。これは、多くの VBA ベースのワークフローに代わる最新の代替手段です。
Excel プロの主な強み:
- ライブ Excel セッションを制御する:プログラムでブックを開いたり、読み取り、書き込み、閉じたりする
- Excel セルから直接呼び出し可能な Python 関数を UDF として作成する
- データの更新やレポートの生成などの反復的なタスクを自動化する
- Pandas DataFrame と Matplotlib チャートを名前付き範囲に直接プッシュする
- Excel ボタンによって Python スクリプトを実行する
- Windows と macOS の両方で動作
- デスクトップ ワークフローにおいて Excel の Python の強力な代替または補完として機能する
xlwing は、Excel との双方向のライブ対話が必要な場合、VBA マクロを置き換える場合、対話型ダッシュボードを構築する場合、または技術者以外の同僚がボタンのクリックで Python 分析をトリガーできるようにする場合に使用できます。
さまざまな Excel プロフェッショナルに最適なライブラリ スタックを選択する
すべてのアナリストが 5 つのライブラリすべてを一度に必要とするわけではありません。これらを採用する実際的な方法は、役割ごとに行うことです。
- レポート アナリスト向け: この組み合わせにより、データのクリーンアップ、概要の作成、グラフの生成、洗練されたワークブック出力のエクスポートが可能になります。
- パンダ
- Matplotlib
- Openpyxl
- 財務および運用アナリスト向け: このスタックは、モデリング、KPI 計算、割り当て、反復可能な月次レポートに適しています。
- パンダ
- シーボーン
- Openpyxl
- 高度な分析チームの場合: この組み合わせにより、データの準備から予測スコアリング、ワークブックの配信までの完全なパイプラインが実現します。
- パンダ
- Matplotlib
- Scikit 学習
- Openpyxl
- シーボーン
最終的な考え
これらは、すべてのプロが使用すべき高度な Excel データ分析用の 5 つの Python ライブラリです。これらのツールをマスターすると、Excel を単純なスプレッドシート アプリケーションから、より有能な分析プラットフォームに変えることができます。賢明な学習パスは、Pandas から始めて、次に openpyxl を追加し、次に Matplotlib と Seaborn を一緒に学習し、その後 Scikit-learn に取り組むことです。各ライブラリは同じ .xlsx で動作します。 すでに使用しているファイル。より有能なデータ アナリストになるために、これらを探索し始めてください。
ソリューション付きの高度な Excel 演習を無料で入手しましょう!-
Windows上のWordでドキュメントを共同編集および共有する方法
Microsoft Office コラボレーション機能が強化され、多数の作成者が同時にドキュメントで作業できるようになりました。これにより、ユーザーはOneDriveでファイルを共有し、誰がそのファイルで作業しているかを確認できます。さらに、検討中のドキュメントに簡単にアクセスできるように、他のユーザーに送信するためのリンクを取得することもできます。 コラボレーションは、多くの作業環境で優れたドキュメントを作成するための重要な要素です。 Microsoft Wordの他のほとんどの関数とは異なり 、コラボレーションツールの使用は少し難しいです。ただし、この優れた機能により、ユーザーは他の
-
MicrosoftPowerPointOnlineでPresenterCoachを使用する方法
Microsoft PowerPoint は地球上で最も使用されているプレゼンテーションツールであり、非常に理由があります。仕事用のプロフェッショナルなプレゼンテーションを作成したい場合は、このプログラムが非常に使いやすく、準備に時間がかからないため、このプログラムが最善の策です。 現在、PowerPoint Webアプリは、デスクトップバージョンと比較すると機能が豊富ではない可能性がありますが、これから行うほとんどの作業には十分です。 Microsoftは、 Presenter Coachと呼ばれる優れた機能を導入しました Web上のPowerPoint用。このツールは、ユーザーが現実の