Excel と Python を組み合わせて高度なデータ ワークフローを実現する 5 つの強力な方法

Excel は強力なデータ管理および分析ツールです。迅速なレポート作成や計算には最適ですが、作業が面倒だったり、反復的だったり、大きすぎる場合には Python が役に立ちます。 Python は、Excel の組み込み機能を超える自動化、高度な分析、統合の可能性を広げます。 パンダ などの Python ライブラリ データ操作とopenpyxl用 Excel ファイルの直接処理により、これがシームレスになります。
このチュートリアルでは、Excel + Python でできることを 5 つ紹介します。
サンプル販売データを検討して、Excel と Python でできる 5 つのことを検討してください。
1.乱雑な Excel データのクリーン化と標準化 (繰り返し)
現実世界のデータがきれいであることはほとんどないため、Excel ではデータが乱雑になるのが一般的です。多くの場合、データには余分なスペース、大文字混合、テキストとして保存された数値、一貫性のない書式設定、欠損値、重複エントリ、または分析前に再構築が必要なデータが含まれています。この問題により、式と分析が台無しになります。
Python はデータ クリーニング タスクに優れています。さまざまなファイル間でデータ形式を標準化し、インテリジェントな方法を使用して欠損値を埋め、重複を削除し、パターンに基づいて列を分割または結合し、ビジネス ルールに照らしてデータを検証するスクリプトを作成できます。これらの手順では、Excel での手動による検索と置換の操作に数時間かかる場合があります。 Python を使用すると、数秒で数千行を処理する繰り返し可能なスクリプトを作成できます。
乱雑な販売データを受け取ったとします。乱雑なデータを読み取り、列をクリーンアップして標準化し、計算フィールドを追加する Python スクリプトを使用してみましょう。
- 収益 =単位 * 単価
- 純収益 =収益 * (1 – 割引率)
import pandas as pd
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="Sales Data")
# Clean types
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
df["DiscountPct"] = pd.to_numeric(df["DiscountPct"], errors="coerce").fillna(0.0)
df["Returned"] = (
df["Returned"].astype(str).str.strip().str.lower()
.map({"yes": True, "no": False})
.fillna(False)
)
# Add calculated fields
df["Revenue"] = df["Units"] * df["UnitPrice"]
df["NetRevenue"] = df["Revenue"] * (1 - df["DiscountPct"])
# Write back into the SAME file as a NEW sheet
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="CleanData", index=False)
print("Saved CleanData sheet inside:", file_path)
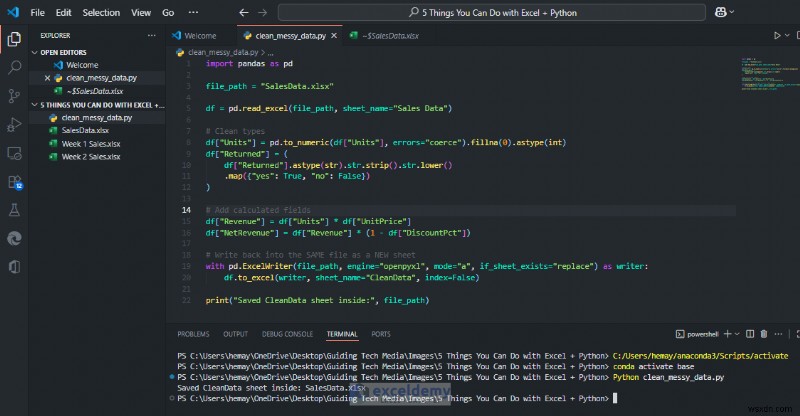
ピボット、チャート、ルックアップが壊れないクリーンなデータセットを含む新しいシートが得られます。 Excel では、クリーンアップされたデータのピボット/グラフを使用し続けることができ、実行のたびに一貫性が保たれることがわかります。
2.概要を自動的に作成 (繰り返し可能なレポート)
Excel には行制限があるため、複雑な計算を行うと速度が低下する可能性があります。 Python のパンダ ライブラリは大規模なデータセットを効率的に処理し、計算をより高速に実行します。
パンダと一緒に を使用すると、数百万のレコードを含むデータセットを操作したり、複雑なグループ化および集計操作を実行したり、Excel では現実的ではない可能性のある統計分析を実行したりできます。 Python はピボット スタイルの概要を生成し、Excel にエクスポートできます。地域とカテゴリごとの簡単な概要が必要だが、毎回ピボットを再構築したくないとします。
import pandas as pd
file_path = "SalesData.xlsx"
clean_sheet = "CleanData"
out_sheet = "Summary"
df = pd.read_excel(file_path, sheet_name=clean_sheet)
summary = (
df.groupby(["Region", "Category"], as_index=False)
.agg(
Orders=("OrderID", "count"),
Units=("Units", "sum"),
NetRevenue=("NetRevenue", "sum"),
Returns=("Returned", "sum")
)
)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
summary.to_excel(writer, sheet_name=out_sheet, index=False)
print(f"✅ Saved '{out_sheet}' sheet inside: {file_path}")
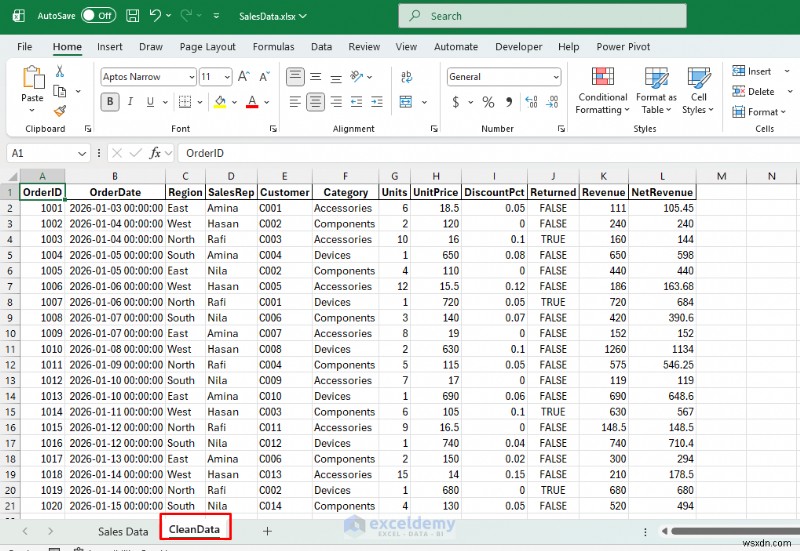
地域別の収益の概要が表示されます。これは、スクリプトを再実行するたびに更新される、すぐに共有できるピボット スタイル シートです。
3. Excel データからグラフを生成 (手動書式設定なし)
多くの場合、グラフはレポート作成の中で最も時間のかかる部分です。 Excel は標準的なグラフを提供しますが、Matplotlib などの Python の視覚化ライブラリも提供します。 、シーボーン 、 そしてプロットします。 はるかに優れた柔軟性と洗練性を提供します。データが変更されたときに自動的に更新されるカスタム ビジュアライゼーションを生成したり、ユーザーが探索できるインタラクティブなダッシュボードを作成したり、あらゆる要素を正確に制御して出版品質のグラフィックを作成したりできます。
地域別のパフォーマンス (地域別純収益) を視覚化してみましょう。
import pandas as pd
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
file_path = "SalesData.xlsx"
source_sheet = "CleanData"
output_sheet = "RegionChart" # data + chart in this one sheet
# Prepare chart data (NetRevenue by Region)
df = pd.read_excel(file_path, sheet_name=source_sheet)
chart_data = (
df.groupby("Region", as_index=False)["NetRevenue"]
.sum()
.sort_values("NetRevenue", ascending=False)
)
# Write chart data into output_sheet (same workbook)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
chart_data.to_excel(writer, sheet_name=output_sheet, index=False)
# Add the native Excel chart on the same sheet
wb = load_workbook(file_path)
ws = wb[output_sheet]
chart = BarChart()
chart.title = "Net Revenue by Region"
chart.y_axis.title = "Net Revenue"
chart.x_axis.title = "Region"
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, "D2") # place chart to the right of the data table
wb.save(file_path)
print(f"✅ Chart Created: {output_sheet}")
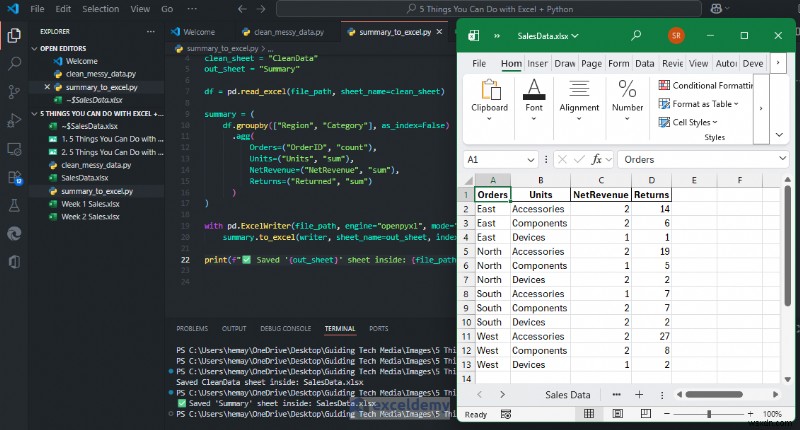
これで、地域別の収益の概要が棒グラフとともに表示されました。
4.多数の Excel ファイルを 1 つのマスター テーブルに結合する
さまざまなソースからの週次、月次、または四半期のデータを結合するのが一般的です。さまざまな人やチームの Excel ファイルをマージすると時間がかかり、エラーが発生しやすくなります。 Python はそれらを数秒で結合し、ソース ファイルを追跡できます。
週次ファイルを weekly Reports/ という名前のフォルダにマージしましょう。 (すべて同じ列です)。
import pandas as pd
from pathlib import Path
base_folder = Path(__file__).resolve().parent
folder = base_folder / "Weekly Reports"
files = sorted(folder.glob("*.xlsx"))
files = [f for f in files if not f.name.startswith("~$")] # ignore Excel lock files
print("Looking in:", folder)
print("Files found:", [f.name for f in files])
frames = []
for f in files:
temp = pd.read_excel(f)
temp["SourceFile"] = f.name
frames.append(temp)
master = pd.concat(frames, ignore_index=True)
master.to_excel(base_folder / "master_report.xlsx", index=False)
print("Saved: master_report.xlsx")
SourceFile を含む 1 つの統合テーブルが得られます。 監査用の欄です。毎週、スクリプトを実行するだけです。
5. Excel では簡単に実行できないことを予測する (機械学習の例)
パターン (割引、カテゴリ、単位、価格) を使用して収益リスクを推定し、Excel ユーザーがフィルターや並べ替えできるように確率を書き戻すことができます。 Python では、このような機械学習操作を簡単に実行できます。
私たちのものは小さなデータセットです。それでも、ワークフローは示されています。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="CleanData")
X = df[["Region", "SalesRep", "Category", "Units", "UnitPrice", "DiscountPct"]]
y = df["Returned"].astype(int)
cat_cols = ["Region", "SalesRep", "Category"]
num_cols = ["Units", "UnitPrice", "DiscountPct"]
preprocess = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(handle_unknown="ignore"), cat_cols),
("num", "passthrough", num_cols),
]
)
model = Pipeline(steps=[
("prep", preprocess),
("clf", LogisticRegression(max_iter=1000))
])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model.fit(X_train, y_train)
# Predict probability of return for all rows
df["ReturnProb"] = model.predict_proba(X)[:, 1]
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="WithReturnRisk", index=False)
Excel で、WithReturnRisk を調べます。 ReturnProb をフィルターします 高値から低値まで順に並べて、どの注文がリスクがあるかを確認します。
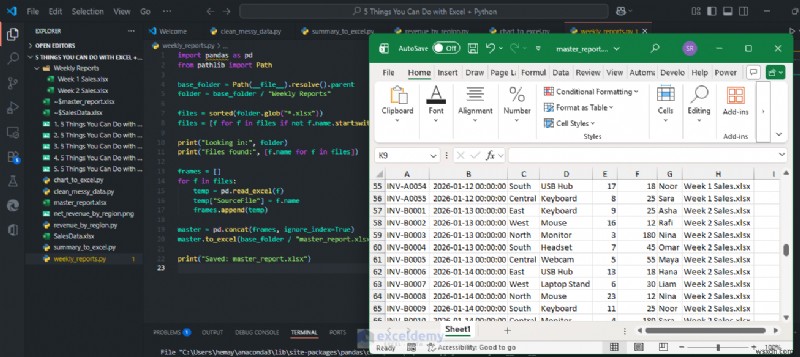
Excel の Python (Excel で利用可能な場合)
コンピューター上の Excel に Python (プレビュー) が搭載されている場合は、セル内で Python を直接実行し、結果をシートに返すことができます。 (Microsoft によるExcel での Python の概要を参照してください) .) これは、狭い範囲を読み取り、テキストをクリーンアップし、収益を計算し、クリーンなテーブルを返す簡単な例です。
- Excel でデータセットを入力します
- 空のセルをクリックします
- 数式に移動します タブ>> Python の挿入 を選択します。
- Python スクリプトを貼り付けます
import pandas as pd
# Read the Excel range A1:J21 (including headers)
df = xl("A1:J21", headers=True)
# Clean text columns
for col in ["Region", "SalesRep"]:
df[col] = df[col].astype(str).str.strip().str.title()
# Fix data types
df["OrderDate"] = pd.to_datetime(df["OrderDate"], errors="coerce")
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
# Add a calculated column
df["Revenue"] = df["Units"] * df["UnitPrice"]
df
DataFrame が返されます。 、これは Python のテーブル オブジェクトです。 Excel では、テーブル プレビュー (およびカード) として表示されます。
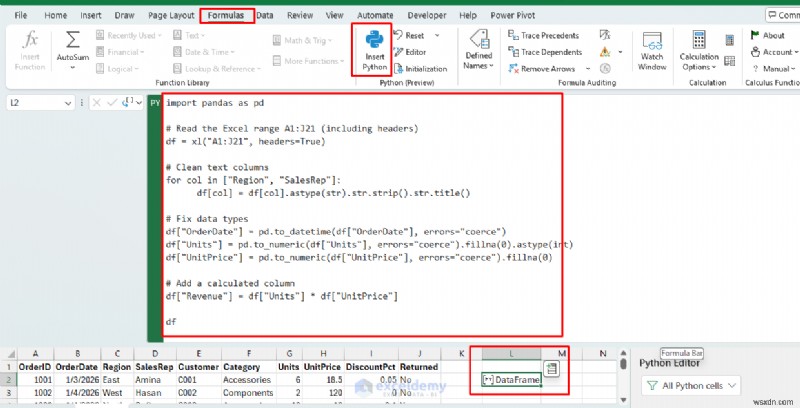
ここで、出力をクリーンなテーブルとしてセルに「スピル」します。
- [データの挿入] をクリックします。 データフレームから>> [データタイプ カードを表示] を選択します。 テーブルをプレビューするには
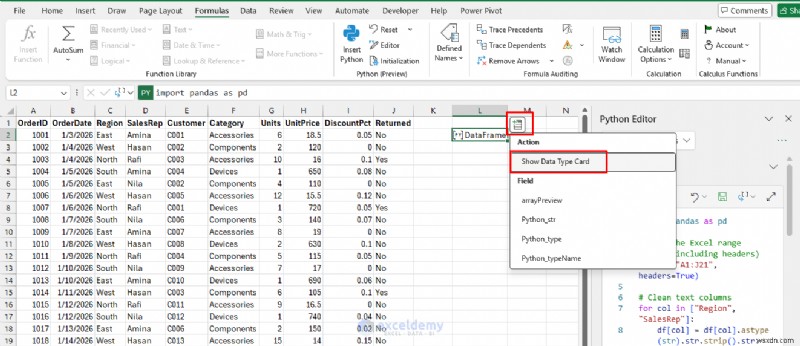
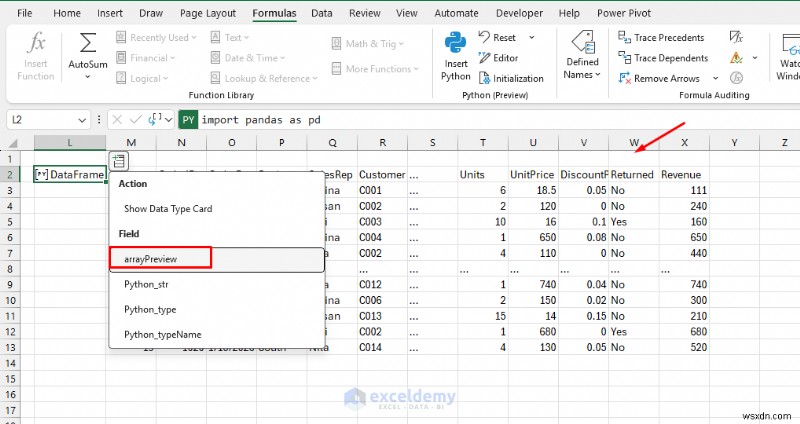
- 配列プレビューを選択します テーブルを Excel に取り込む
- 標準化されたテキストと新しい収益が完成しました。 列
結論
この記事では、Excel + Python でできることを 5 つ紹介します。 Excel は Python を使用するとさらに強力になります。乱雑なデータセットのクリーンアップ、ピボット スタイルの要約の生成、グラフの自動化、多くの Excel ファイルの結合、シンプルな機械学習の洞察の追加が簡単になります。 Excel と Python を組み合わせることで、データのインポート/エクスポートから自動化と視覚化に至るまで、ワークフローが合理化されます。小さなスクリプトから始めて、さらに多くのライブラリを試してください。
ソリューション付きの高度な Excel 演習を無料で入手しましょう!-
Office 365米国政府の機能、価格設定、および計画
クラウドアプリケーションの経済的な実現可能性と使いやすさにもかかわらず、最近のセキュリティ侵害はクラウドテクノロジーに対して否定的な感情を生み出しています。政府のセキュリティの懸念に対処するために、Microsoftは Office 365 U.S. Governmentと呼ばれる製品を提供しています 。これらのOffice365アプリケーションは、クラウドテクノロジーへの移行を検討しながら、コスト、セキュリティ、生産性の交渉を行うための効果的なソリューションです。 Office365米国政府 クラウドテクノロジーに取り組んでいる人々にとって最も重要な懸念の1つは、セキュリティです。
-
アクセスでスペルをチェックする方法
Microsoft Accessを使用している人は、文章を入力して単語を綴ろうとするとエラーが発生することがあります。 Microsoft Accessには、スペルミスのある単語を修正するのに役立つスペル機能があります。この投稿では、MicrosoftAccessでスペルと文法を確認する方法を紹介します。 。 Accessでスペルを使用する方法 以下の手順に従って、MicrosoftAccessのスペルと文法を確認してください。 Accessを起動するか既存のデータベースを開きます。 セルを選択 [レコード]グループの[スペル]ボタンをクリックします。 必要な提案をクリックして、[変