SQLServerの実行計画を理解する
実行計画をどのように読みますか?右から左へ、左から右へ、またはコストをチェックアウトすることによって?または、インデックススキャン、テーブルスキャン、ルックアップなどのオブジェクトについてはどうでしょうか。このブログでは、Microsoft®SQLServer実行計画の読み方について説明しています。
SQL Serverは通常、適切な計画を生成しますが、計画を検証して不十分な計画を修正するのに十分ではない場合もあります。
SQLServerで推定実行プランと実際のグラフィカル実行プランを取得できます。コマンドctrlM を使用して、これらのプランを生成します またはctrlL または、SQL Server Management Studio(SSMS)の標準ツールバーの実行アイコンの右側に配置されているアイコンを使用します。 SQL Serverには他の種類のプランがありますが、これらのプランはこの投稿では取り上げられていません。
実行計画には次の2つのタイプがあります。
-
推定実行計画 :見積もり計画は、SQLサーバーがデータを取得するために実行すると予想される作業の見積もりを提供します。
-
実際の実行計画 :実際の実行プランは、Transact-SQLクエリまたはバッチの実行後に生成されます。このため、実際の実行計画には、実際のリソース使用量メトリックや実行時の警告などの実行時情報が含まれています。
同じクエリの推定計画と実際の計画の違いに気づいたことがありますか?ほとんどの場合同じですが、統計の変更、スキーマ関連の変更、またはデータの変更により異なる場合があります。トラブルシューティングを行うときは、常に実際の実行計画を確認する必要があります。
実行計画を正しく読んで、実際のポイントを特定します。コストではなく、データフローを確認することから始めます。論理的または物理的な読み取りについては考えないでください。入出力(I / O)操作の数を減らすことが重要です。データベース管理者(DBA)として、ストレージへのアクセスはハードウェアリソースの中で最も遅いことを知っているので、そのアクティビティを最小限に抑えるようにしてください。では、どのように統計を調査し、実行計画はそれを示していますか?はい、そうです!右から左のインジケータの上にマウスを置いて、方向線を確認してください。レコード数とデータサイズが表示されます。次の図に示すように、各行は、操作によって返されるデータ量に基づいて太くまたは細くなります。
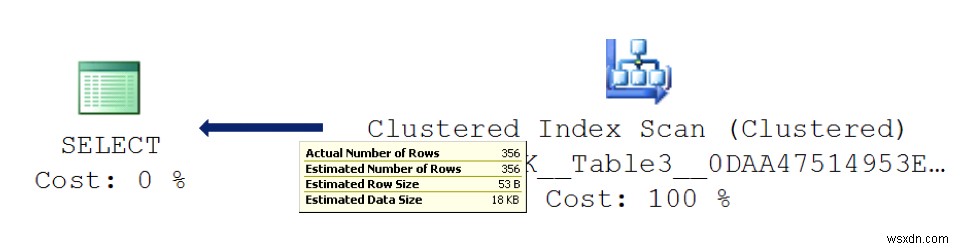
オブジェクトが多数ある場合は、各操作で処理されるデータ量の概要を取得するためのより良い方法が必要です。 SentryOneプランエクスプローラーをダウンロードし、このツールを使用してプランを表示すると、概要を簡単に確認できます。
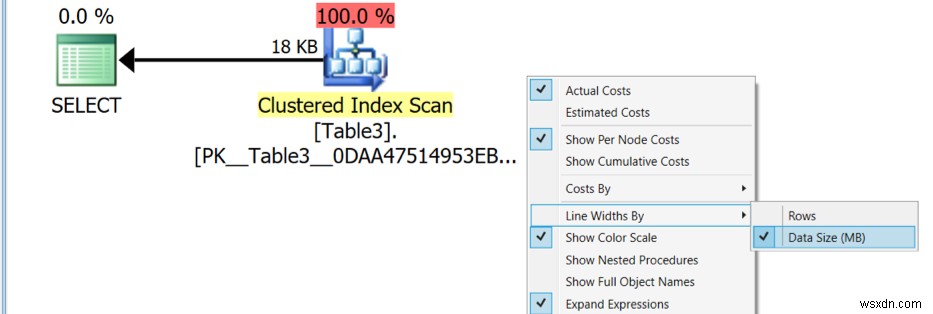
システムにSentryOneをダウンロードして構成したら、それを使用して実行計画を開きます。 SentryOneには多くのビューと説明があり、必要に応じて使用できます。データ処理ビューを取得するには、Data size in MBを選択してビューを変更します 次の画像に示すオプション。あなたの目標は、全体的なデータ処理を減らす機会を見つけることです。
I / Oストレスを軽減する必要がある場合は、SET STATISTICS IO ONを参照してください。 クエリのI/O使用量の全体像を把握するためのT-SQL値。 メッセージへの結果の切り替えを確認するには、SSMSでクエリを実行する前にこれを設定する必要があります 結果のタブ パネル。次の結果のようになります。
(356 row(s) affected)
Table 'Table3'. Scan count 1, logical reads 5, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
論理読み取り5 結果は、SQLServerがメモリからデータを取得するために40KB(5 * 8 KB)ページを読み取ることを示しています。クエリを最適化するときは、論理読み取りを無視しないでください。これは、ライブサーバーでは物理的であると同時に論理的である可能性があるためです。参照しているページがメモリ上にあるのかディスク上にあるのかはわかりません。目標は、累積読み取り操作の数を減らすことです。
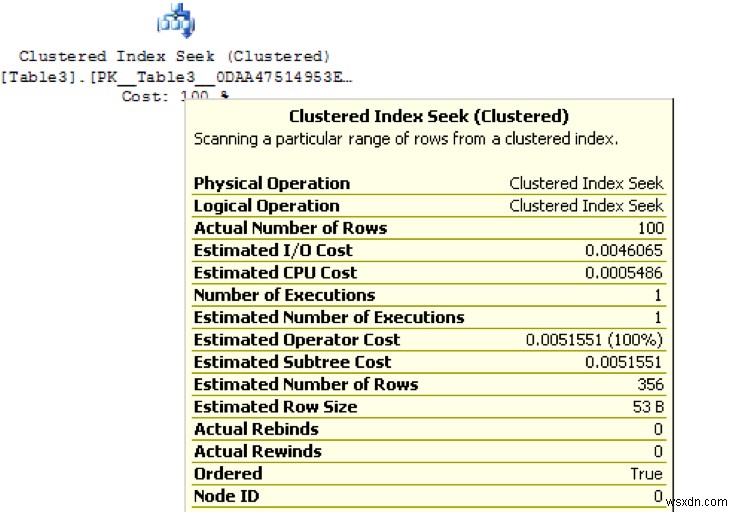
実際の計画が生成されたら、実行計画内の操作または論理ユニットのいずれかにマウスを合わせます。次の画像を参照して、クラスター化インデックスシークまたはスキャンなどの物理操作のタイプを確認してください。 結果。実行数と実際の行数および推定行数を探します。これは古いハードウェアに基づく1秒単位の見積もりであり、正確な詳細が提供されない可能性があるため、個々の操作のコストを見ることは避けてください。次の画像では、クラスター化されたインデックスシーク オペレーターは100レコードを取得するために1回実行し、SQLは356レコードを推定します。違いは、統計の古さやクエリのパフォーマンスが原因である可能性があります。
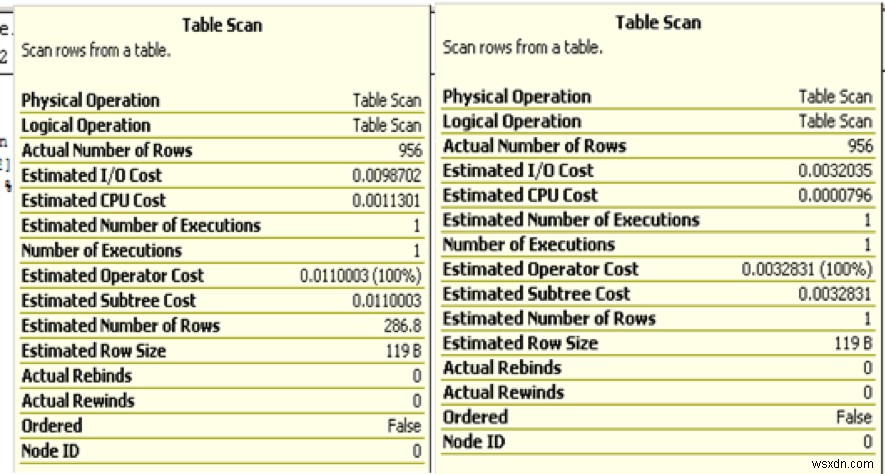
次の画像は、1つのレコードを取得するためのクラスターインデックスの推定実行回数が1154121回であることを示しています。それは重要です。オペレーターのコストが低く、それを単に無視して、代わりにコストの高い他のオペレーションを検討することもできたとしても、これはコストのかかる選択であることが判明した可能性があります。このような操作は、クラスターインデックスがあるにもかかわらず、クエリのパフォーマンスに大きな影響を与えます。行ID(RID)ルックアップは、ヒープの同様の操作です。
推定レコード数と実際のレコード数の違いは、考慮すべきもう1つのことです。見積もりが間違っていると、割り当てられたメモリが制限されたクエリが発生する可能性があります。その場合、一時データベース(tempdb)を使用して処理を実行します。次の図に示すように、SQL Serverによる演算子またはプランの選択を誤ると、操作が遅くなり、クエリが抽出される可能性があります。実際のレコード数は同じですが、見積もりは異なります。これは、統計が古くなっているか欠落していることが原因である可能性があります。テーブル変数には統計がないため、再コンパイルのオプションが使用されるまで、プランは常に新しいリリースで1と1Kを返すことに注意してください。したがって、テーブル変数は多数のレコードには適していません。
並べ替えの影響を考慮する必要があります。並べ替え演算子は、主に次の関数に使用されます:集約、マージ結合、または句による順序付け。これは、ほんの数レコードでは影響がない可能性がありますが、レコードが追加されるたびに、処理が遅くなります。並べ替えを避けるか、orderby句を使用しないでください。並べ替えが必要な場合は、並べ替えられたデータをアプリケーションに送信する代わりに、アプリケーショングリッドを使用して並べ替えを行います。
次の画像は、並べ替えコストを示しています。

あなたが見る必要があるもう一つの重要な演算子はスプールです。スプールは、非表示または一時オブジェクトまたは作業テーブルをintempdbに格納するため、slowoperatorです。これはまた、再バインドの巻き戻しを引き起こす特定の演算子で速度が低下します。 SQL Serverには、Eager、Lazy、Table / Indexなど、さまざまな種類のスプールがあります。 SQL Serverは、中間結果セットのソーステーブルに戻るよりも、一時的な作業テーブルを参照する方がよい場合にスプールを使用します。次の画像は例を示しています:
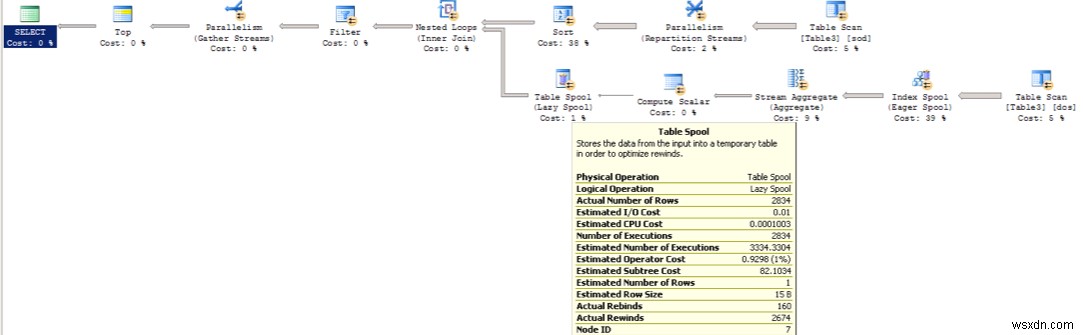
スプールでは、再バインドと巻き戻しの数に注意することが重要です。リワインドはリバインドよりもコストがかかります。たとえば、次の画像では、演算子は2674巻き戻しを示しています。これは、クエリが2674回再実行されてデータを取得することを意味します。各オペレーターをテーブルスプールからテーブルスキャンに戻し、各レコードを巻き戻します。再バインドとは、スプールからデータを取得し、テーブルスキャンに戻らなかったことを意味します。
これらは小さなレコードセットで適切に機能するため、ハッシュループとネストされたループは次に検討する必要のある演算子です。ただし、レコードセットが大きい場合、または見積もりと実際の計画に大きな違いがある場合、これらのオペレーターはメモリの代わりにtempdbを使用する可能性があるため、大きな影響を与える可能性があります。 SQL Serverは、オペレーターの詳細に次の警告を投稿します。「オペレーターは、実行中にtempdbを使用してデータをスピルしました」。これが発生した場合は、統計に注意してください。見積もりが間違っていると、ループがメモリ割り当てに不足するか、反復を続けます。実行に割り当てられたメモリを確認します。メモリ割り当てを表示するには、実行計画の開始点(左から右)を選択してプロパティボックスを開きます。異常がない場合は、クエリの調整が理想的な選択肢です。
クエリを最適化するための最初の目標は、全体的な読み取りと書き込み(つまり、ディスク上のI / O)を減らすことです。メモリ内の読み取りと書き込みの論理読み取りを忘れないでください。 I / Oを減らすと、ほとんどの問題が解決され、クエリの実行速度が大幅に向上します。
次に、ontempdbのアクティビティが原因でコストがかかる他の操作を確認します。 tempdbは多くの操作に使用され、常にコストがかかることを忘れないでください。巻き戻し(操作、スプール、並べ替え、ループの実行回数)を探してください。
これらはtempdbと一緒に使用すると高価です。各オペレーターの警告を確認することを忘れないでください。警告は良い手がかりを提供します。この投稿では欠落しているインデックス演算子については説明していませんが、それを無視できるわけではありません。
確認しますが、盲目的にインデックスを作成しないでください。同じ列で使用可能な他のインデックスを確認し、データベースで実行されているクエリへの影響を検討してください。
コメントや質問をするには、[フィードバック]タブを使用します。私たちと会話を始めることもできます。
-
MicrosoftSQLServerクエリストア
Microsoft®SQLServer®クエリストアは、その名前が示すように、実行されたクエリのデータベース履歴、クエリの実行時実行統計、および実行プランをキャプチャするストアのようなものです。データはディスクに保存されるため、トラブルシューティングの目的でいつでもクエリストアデータを取得できます。SQLServerを再起動してもデータに影響はありません。 SQL Server 2016で導入され、以降のすべてのエディションで利用できるクエリストアを使用して、クエリプランの変更によって引き起こされるパフォーマンスの問題をトラブルシューティングします。 はじめに ベースラインデータ分析はパフォ
-
ストレッチデータベース-理解を得る
こんにちは、みんな。私はここに、データベース(DB)をいくつかの方法で改善するのに役立つ非常にシンプルですが素晴らしいトピックを持っています—データベースのストレッチ!! それでは、始めましょう。 ストレッチデータベースとは何ですか? SQL 2016では、オンプレミスからAzurecloudにデータを拡張するのに役立つ機能が導入されました。この機能であるStretchDatabase(またはStretchDB)は、ローカルSQL Server上のウォーム(頻繁にアクセスされる)データを維持しながら、ローカルSQLServer®からAzure®にコールド(頻繁にアクセスされない)データを