SQLServer2017の新機能
より新しいバージョンのSQLServerへのアップグレードを検討していますか? SQLServer2016とSQLServer2017のどちらを選択していますか?もしそうなら、この投稿で説明しているように、SQLServer2017にアップグレードすることをお勧めします。
SQL Serverテクノロジのリリースにより、SQL管理者と開発者が熟考するための興味深い新機能が多数提供されます。 SQL Server vNext(一般にSQL Server 2017と呼ばれます)用のCommunity TechnologyPreview(CTP)2.0も例外ではありません。多くの更新が、アプリケーションの既存の機能とサービスに実装されています。このブログ投稿では、データベース管理者(DBA)の観点から、SQLServer2017のデータベースエンジンの新機能について説明します。
Microsoft®SQLServer2017は、より高速な処理、より柔軟な使用、および結果としての大幅なコスト削減を提供する、より多くの新機能を備えたシーンになりました。 SQL Server 2016は多くの改善を提供し、Microsoftはこれを大きな飛躍と呼んでいます。ただし、SQL Server 2016が大きな飛躍であった場合、SQL Server2017は、すべてのレベルで企業顧客が必要とするものすべてとはるかに多くのものを約束します。データベースのパフォーマンスは、アダプティブクエリ処理、クロスプラットフォーム機能による新しい柔軟性、統計およびデータサイエンス分析の新しい統合、Linux®、Ubuntu®オペレーティングシステム、またはDocker®でのSQLServerバージョンによって新たなピークに達しました。新しいバージョンは、コストを節約しながら確かなテクノロジーを追加します。
ここで説明するSQLServer2017で導入された変更には、次の機能が含まれます。
- Linux上のSQLServer
- 再開可能なオンラインインデックスの再構築
- SQLServer機械学習サービス
- クエリ処理の改善
- データベースの自動調整
- TempDBファイルサイズの改善
- スマート差動バックアップ
- スマートトランザクションログのバックアップ
- 改善されたSELECTINTO ステートメント
- 分散トランザクションのサポート
- 新しい可用性グループ機能
- 新しい動的管理ビュー
- メモリ内の機能強化
- セキュリティの強化
- 高可用性とディザスタリカバリ
- パフォーマンスの向上
Linux上のSQLServer
SQL Serverは、もはや単なるWindowsベースのリレーショナルデータベース管理システム(RDBMS)ではありません。 Linuxオペレーティングシステムのさまざまなフレーバーで実行できます。 Linux、Windows、Ubuntuオペレーティングシステム、またはDockerでSQL Serverを使用してアプリケーションを開発し、これらのプラットフォームにデプロイすることもできます。
この機能は、データベースのフェイルオーバー、ディスクスペースの不足、一時停止などのイベントの後に停止した場所から、オンラインインデックスの再構築操作を再開します。
次の画像は、この操作の例を示しています。
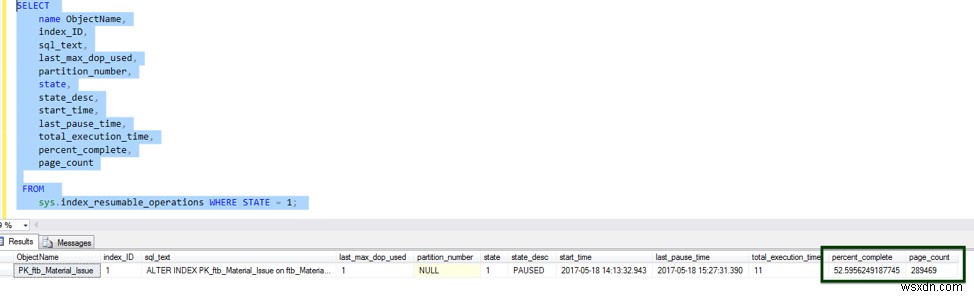
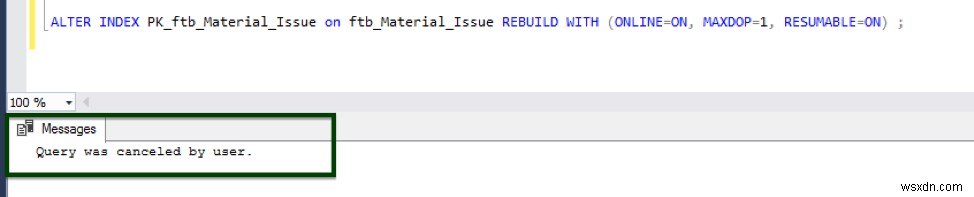
オンラインインデックス操作を実行する場合、次のガイドラインが適用されます。
- 基になるテーブルにimage、ntext、およびtext large object(LOB)データ型が含まれている場合は、クラスター化インデックスを作成、再構築、またはオフラインで削除する必要があります。
- テーブルにLOBデータ型が含まれている場合、一意ではない非クラスター化インデックスをオンラインで作成できますが、これらの列はいずれも、キーまたは非キー(含まれる)列としてインデックス定義で使用されません。
- ローカル一時テーブルのインデックスは、オンラインで作成、再構築、または削除できません。この制限は、グローバル一時テーブルのインデックスには適用されません。
- 複数の新しい非クラスター化インデックスを作成する場合、または非クラスター化インデックスを再編成する場合にのみ、同じテーブルまたはビューで同時オンラインインデックスデータ定義言語(DDL)操作を実行できます。同時に実行される他のすべてのonlineindex操作は失敗します。たとえば、同じテーブルで既存のインデックスをオンラインで再構築しているときに、新しいインデックスをオンラインで作成することはできません。
SQLServer機械学習サービス
SQL Server 2016は、データベースサーバー内で実行でき、Transact-SQL(T-SQL)スクリプトに埋め込むこともできるRプログラミング言語を統合しました。SQLServer2017では、データベースサーバー自体でPythonスクリプトを実行できます。 RとPythonはどちらも人気のあるプログラミング言語であり、自然言語の処理機能とともにデータ分析を広範囲にサポートします。
SQL Server 2017は、最適化戦略をアプリケーションワークロードの実行時の条件に適合させます。これには、SQLServerおよびSQLデータベースのクエリパフォーマンスを向上させるために使用できる適応クエリ処理機能が含まれています。
次の図に示すように、3つの新しいクエリの改善があります。

- バッチモードのメモリ付与フィードバック :このフィードバック手法は、実行プランに必要なメモリを再計算し、キャッシュから付与します。
- バッチモードのアダプティブ結合 :プランをより高速に実行するために、この手法ではハッシュ結合またはネストされたループ結合を使用できます。実行計画の最初の入力をスキャンした後、最速の速度で出力を生成するために使用する結合を決定します。
- インターリーブ実行 :インターリーブ実行は、マルチステートメントのテーブル値関数に遭遇すると、実行プランの最適化を一時停止します。次に、完全なカーディナリティを計算し、最適化を再開します。
この機能は、潜在的なパフォーマンスの問題が検出されたときに通知し、修正措置を適用できるようにします。または、データベースエンジンが、SQLプランの選択のリグレッションによって引き起こされたパフォーマンスの問題を自動的に修正できるようにします。したがって、データベースは、どのインデックスと計画により、ワークロードのパフォーマンスと、ワークロードに影響を与えるインデックスが改善される場合があります。これらの調査結果に基づいて、自動調整プロセスは、ワークロードのパフォーマンスを向上させるアクションを適用します。さらに、データベースは、自動調整によって変更が加えられた後もパフォーマンスを継続的に監視して、ワークロードのパフォーマンスが向上することを確認します。パフォーマンスを向上させないアクションはすべて自動的に元に戻されます。
SQLプラン選択回帰
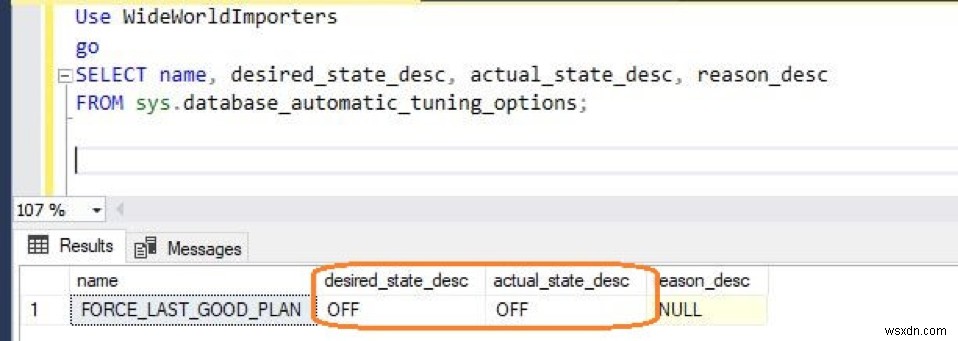
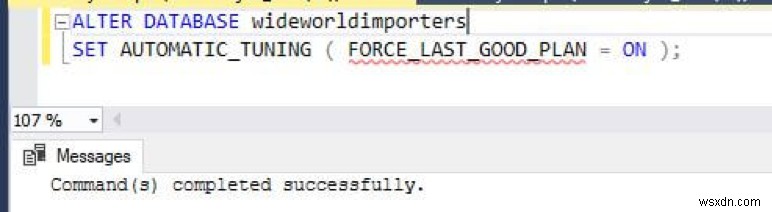
SQL Serverデータベースエンジンは、さまざまなSQLプランを使用してT-SQLクエリを実行する場合があります。クエリプランは、統計、インデックス、およびその他の要因によって異なります。場合によっては、新しいプランが以前のプランよりも優れていない可能性があり、新しいプランによってパフォーマンスが低下する可能性があります。不十分なプラン選択の回帰に気付いた場合は、以前に使用した適切なプランを見つけて、 sp_query_store_force_plan を使用して、現在のプランの代わりに強制的に使用する必要があります。 手順。 SQL Server 2017(v。14.x)のデータベースエンジンは、回帰計画と推奨される修正措置に関する情報を提供します。さらに、データベースエンジンを使用すると、このプロセスを完全に自動化し、データベースエンジンに、見つかった計画の変更に関連する問題を修正させることができます。
次の図に、計画の自動修正を示します。

次の自動調整機能を使用できます。
- 自動プラン修正 (SQL Server 2017 v14.xおよびAzureSQLデータベースで使用可能):問題のあるクエリ実行プランを特定し、SQLプランのパフォーマンスの問題を修正します。自動調整は、次のコマンドを使用して有効にします。
- 自動インデックス管理 (Azure SQLデータベースでのみ使用可能):データベースに追加する必要のあるインデックスと削除する必要のあるインデックスを識別します。
TempDBファイルサイズの改善
SQL Server 2017のセットアップでは、ファイルあたり最大256 GB(262,144 MB)の初期TempDBファイルサイズを指定できるようになりました。ファイルサイズが1 GBを超えて設定されている場合、インスタントファイル初期化(IFI)なしで警告が表示されます。 有効。指定されたTempDBデータファイルの初期サイズによっては、IFIを有効にしないと、セットアップ時間が指数関数的に増加する可能性があることを理解することが重要です。
新しい列modified_extent_page_count sys.dm_db_file_space_usageで紹介されています データベース内の各データベースファイルの差分変更を追跡します。新しい列modified_extent_page_count DBA、SQLコミュニティ、およびバックアップ独立ソフトウェアベンダー(ISV)は、データベース内の変更されたページの割合がしきい値(約70〜80%)を下回った場合に差分バックアップを実行する、スマートバックアップソリューションを構築できます。それ以外の場合は、完全なデータベースを実行します。バックアップ。データベースに多数の変更が加えられている場合、差分バックアップを完了するためのコストと時間は、データベース全体のバックアップを作成するのと同じです。したがって、この場合、差分バックアップを作成するメリットはありません。ただし、データベースの復元時間を確実に増やすことができます。このインテリジェンスをバックアップソリューションに追加することで、差分バックアップを使用して復元と復旧の時間を節約できるようになりました。
新しい動的管理機能(DMF)、 sys.dm_db_log_stats(database_id) 、解放された。この関数は、新しい列 log_since_last_log_backup_mbを公開します 、DBA、SQLコミュニティ、およびバックアップISVが、データベースのトランザクションアクティビティに基づいてバックアップを取るインテリジェントなTログバックアップソリューションを構築できるようにします。このT-logバックアップソリューションインテリジェンスは、T-logbackupの頻度が低すぎる場合に、トランザクションアクティビティのバーストが短時間で発生するために、トランザクションログのサイズが大きくならないようにします。また、サーバー上にトランザクションアクティビティがない場合でも、スケジュールされたトランザクションログバックアップによって作成されるT-logbackupファイルが多すぎる状況を回避するのにも役立ちます。その場合、ストレージ、ファイル管理、復元のオーバーヘッドが不必要に増加します。
改善されたSELECTINTO ステートメント
SQL Server 2017では、 ON を使用して、新しいテーブルを作成するファイルグループ名を指定できます。 SELECT INTOを含むキーワード 声明。テーブルは、デフォルトでユーザーのデフォルトのファイルグループに作成されます。この機能は以前のバージョンでは利用できませんでした。
SQL Server 2017は、可用性グループ内のデータベースの分散トランザクションをサポートしています。このサポートには、SQLServerの同じインスタンス上のデータベースとSQLServerの異なるインスタンス上のデータベースが含まれます。分散トランザクションは、データベースミラーリング用に構成されたデータベースではサポートされていません。
この機能には、クラスターレスサポート、最小レプリカCommitAvailabilityグループが含まれます 設定、およびWindows-LinuxのクロスOS移行とテスト。
この機能には、次の機能が含まれます。
-
可用性グループは、基盤となるクラスター(WindowsServerフェールオーバークラスターまたはWSFC)がなくても、混合環境(WindowsとLinuxまたはDocker上のインスタンス)でセットアップできるようになりました。
-
新しい最小レプリカコミット 設定により、セカンダリレプリカの特定の数を指定できます。プライマリでコミットする前に、トランザクションをコミットする必要があります。
動的管理ビュー(DMV)には、次の要素が含まれます。
- sys.dm_db_log_stats 要約レベルの属性とトランザクションログファイルの情報を公開し、トランザクションログの状態を監視するのに役立ちます。
- sys.dm_tran_version_store_space_usage 各データベースごとにグループ化された、影響のあるバージョンストアの使用状況を確認できます。その結果、これを使用して、テスト環境(変更の前後)でワークロードのプロファイルを作成し、他のデータベースもバージョンストアを使用している場合でも、時間の経過とともに影響を監視できます。
- sys.dm_db_log_info 仮想ログファイル(VLF)情報を公開して、潜在的なトランザクションログの問題を監視、警告、回避します。
- sys.dm_d_stats_histogram 次の画像に示すように、は統計を調べるための新しい動的管理ビューです。
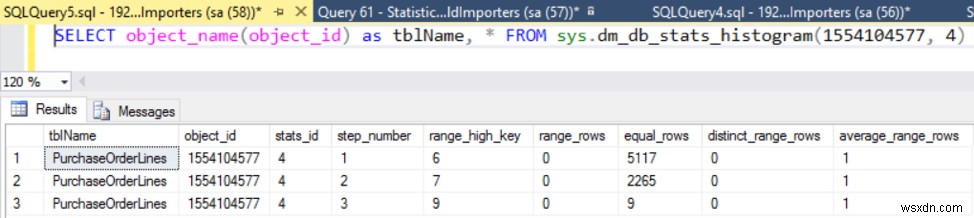
- sys.dm_os_host_info プラットフォーム、配布、サービスパックのレベル、言語などを公開します。
- sys.dm_os_sys_info が拡張され、CPU情報(アソシエート数、コア数、ソケットあたりのコア数など)が明らかになりました。
SQL Server 2017でのメモリ内の変更には、次の機能強化が含まれます。
- 計算列とそれらの列のインデックスがサポートされるようになりました。
- CASE式、CROSS APPLY、およびTOP(N)WITH TIESは、ネイティブにコンパイルされたモジュールでサポートされるようになりました。
- JSONコマンドは、チェック制約とネイティブにコンパイルされたモジュールの両方で完全にサポートされるようになりました。
- システムプロシージャsp_spaceused メモリ最適化テーブルのスペースを適切にレポートするようになりました。
- システムプロシージャsp_rename インメモリテーブルとネイティブにコンパイルされたモジュールで動作するようになりました。
- メモリ最適化テーブルの8つのインデックスの制限がなくなりました。
- メモリが最適化されたファイルグループファイルをAzureストレージに保存できるようになりました。
CONTROL、ALTER、REFERENCES、TAKE OWNERSHIP、VIEW DEFINITION権限など、データベーススコープの資格情報に対する権限を付与、拒否、または取り消すことができるようになりました。また、ADMINISTER DATABASEBULKOPERATIONSがsys.fn_builtin_permissionsに表示されるようになりました。 。
強化された常時オンにより、読み取り可能なセカンダリのミッションクリティカルな稼働時間、高速フェイルオーバー、簡単なセットアップ、および負荷分散を実現します。 SQLServer2017の機能。これは、LinuxおよびWindowsでの高可用性と災害復旧のための統合ソリューションです。非同期レプリカをAzure仮想マシンに配置して、ハイブリッド高可用性を実現することもできます。
SQL Server 2017では、クエリと統計の収集方法と表示方法に次の変更が加えられています。
- 新しいDMVsys.dm_exec_query_statistics_xml クエリプロファイリングが有効になっている限り、セッションをプランに関連付けることができます。次の画像はこれを示しています:

- Showplan XMLには、プランに使用される統計、実際のプラン、実行時メトリック、およびそのプランで経験された上位10の待機統計に関する情報が含まれるようになりました。これらの待機統計は、クエリストアでも追跡されています。
- 新しい動的管理関数sys.dm_db_stats_histogram データベースコンソールコマンド(DBCC)を使用せずに、プログラムでヒストグラム情報にアクセスできます。
SQL Server 2017には、実装に役立つ可能性のある多くの変更があり、豊富な情報が役立ちます。 SQL Server 2017は「単なるLinuxポート」であると思われるかもしれませんが、コアデータベースエンジンには、すべてのプラットフォームにメリットをもたらす重要な実際の改善があります。 Microsoftは、SQL Server 2017の累積的な更新で製品に機能を追加し続けており、SQL Server 2017は、SQLServer2016よりも長い間Microsoftによって完全にサポートされます。
データベースの詳細
コメントや質問をするには、[フィードバック]タブを使用します。私たちと会話を始めることもできます。
-
OracleDatabase18cの新機能
このブログ投稿では、DBAの作業を少し楽にするOracleDatabase18cで導入された新しい興味深い機能について説明しています。 Oracle Database 18cには、次の新機能が導入されています。 SQLのキャンセル パスワードファイルの場所 読み取り専用のOracleホーム プライベート一時テーブル SQLのキャンセル Oracle Database 18cには、データベース管理者(DBA)が元のセッションを強制終了することなく、ブロックまたは過度に高額なステートメントをキャンセルするために使用できる新しいコマンドが導入されています。以前のリリースでは、DBAはalte
-
Ruby2.6の9つの新機能
Rubyの新しいバージョンには、新しい機能とパフォーマンスの改善が含まれています。 変更についていきますか? 見てみましょう! 無限の範囲 Ruby 2.5以前のバージョンは、すでに1つの形式の無限範囲をサポートしています( Float ::INFINITY を使用) )、しかしRuby2.6はこれを次のレベルに引き上げます。 新しい無限の範囲 次のようになります: (1..) これは、(1..10)のような終了値がないため、通常の範囲とは異なります。 。 使用例 : [a, b, c].zip(1..) # [[a, 1], [b, 2], [c, 3]] [1,2,3,