Excel と Python を活用して高度なデータ サイエンス ワークフローを実現

Excel は、そのシンプルさと柔軟性により、多くのデータ アナリストにとって頼りになるツールです。ただし、大規模、反復的、または複雑なデータ タスクの場合、Python は速度、自動化、高度な分析を提供します。 Excel と Python を統合することで、両方の長所を活用できます。
このチュートリアルでは、Excel と Python を組み合わせて強力なデータ サイエンス ワークフローを実現する方法を説明します。
必要なツールとセットアップ
Excel と Python を組み合わせる前に、環境をセットアップします。これにより、最初のステップからワークフローがスムーズで生産的になります。
前提条件:
- Microsoft Excel :最初のデータのレビューとレポート用。
- Python 3.x :データ サイエンス ワークフローのエンジン
- Python ライブラリ :
- パンダ データ分析のため。
- マットプロットライブラリ プロット用。
- openpyxl (オプション、Excel ファイルの書き込み用)。
- しつこい (数値)。
- matplotlib/seaborn 視覚化のため。
Python ライブラリをインストールします:
pip install pandas matplotlib openpyxl
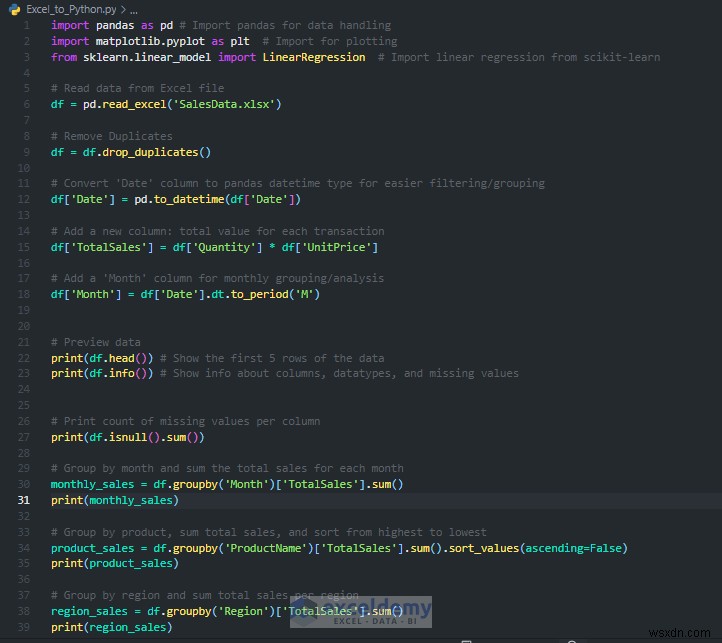
1.データを Python に読み取る
pandas を使用してデータを Python にロードできるため、表形式データの操作と分析が簡単になります。
import pandas as pd
# Read data from Excel file
df = pd.read_excel('SalesData.xlsx')
# Preview data
print(df.head()) # Show the first 5 rows of the data
print(df.info()) # Show info about columns, datatypes, and missing values
- pd.read_csv() Excel ファイルを pandas DataFrame に読み込みます。
- df.head() 最初の 5 行が表示されるので、簡単に確認するのに最適です。
- df.info() 行、列、データ型の数を示します。
販売データの最初の数行と、次のような概要が表示されます。
TransactionID Date CustomerID ProductID ProductName Category Quantity UnitPrice Region Channel SalesRep 0 100001 2024-01-02 C-100 P-101 Laptop Electronics 2.0 800.0 East Online Smith 1 100002 2024-01-02 C-101 P-102 Printer Electronics 1.0 200.0 West Retail Johnson 2 100003 2024-01-03 C-102 P-103 Mouse Electronics 5.0 25.0 North Online Lee 3 100004 2024-01-04 C-103 P-104 Desk Furniture 1.0 150.0 South Retail Brown 4 100005 2024-01-05 C-104 P-105 Monitor Electronics 3.0 175.0 NaN Online Davis <class 'pandas.core.frame.DataFrame'> RangeIndex: 63 entries, 0 to 62 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 TransactionID 63 non-null int64 1 Date 62 non-null datetime64[ns] 2 CustomerID 62 non-null object 3 ProductID 61 non-null object 4 ProductName 63 non-null object 5 Category 61 non-null object 6 Quantity 61 non-null float64 7 UnitPrice 62 non-null float64 8 Region 62 non-null object 9 Channel 62 non-null object 10 SalesRep 62 non-null object dtypes: datetime64[ns](1), float64(2), int64(1), object(7) memory usage: 5.5+ KB None
2.データのクリーニングと変換
生データがすぐに分析できる状態になることはほとんどありません。このステップでは、欠落している値を修正し、列を正しいタイプに変換し、新しい計算フィールドを追加します。
重複を削除:
# Remove Duplicates df = df.drop_duplicates()
- 重複した値を削除します。
欠損値がないか確認します:
# Print count of missing values per column print(df.isnull().sum())
- 各列に欠損値 (NaN) がいくつあるかを示します。見つかった場合は、削除するか埋めるかを決定できます。
#Output: TransactionID 0 Date 1 CustomerID 1 ProductID 2 ProductName 0 Category 2 Quantity 2 UnitPrice 1 Region 1 Channel 1 SalesRep 1 dtype: int64
データ型の変換:
# Convert 'Date' column to pandas datetime type for easier filtering/grouping df['Date'] = pd.to_datetime(df['Date'])
- フィルタリングとグループ化を容易にするために、Date 列をテキストから pandas 日時形式に変換します。
「TotalSales」列を作成します:
# Add a new column: total value for each transaction df['TotalSales'] = df['Quantity'] * df['UnitPrice']
- 各トランザクションの合計値を示す新しい列を追加します。
時系列分析の月の抽出:
df['Month'] = df['Date'].dt.to_period('M')
- これにより、月ごとに売上をグループ化して分析するための「月」列が作成されます。
- 次に、print(df.head()) を使用して、クリーンアップされたデータをプレビューします。
#Ouput: TransactionID Date CustomerID ProductID ProductName Category ... UnitPrice Region Channel SalesRep TotalSales Month 0 100001 2024-01-02 C-100 P-101 Laptop Electronics ... 800.0 East Online Smith 1600.0 2024-01 1 100002 2024-01-02 C-101 P-102 Printer Electronics ... 200.0 West Retail Johnson 200.0 2024-01 2 100003 2024-01-03 C-102 P-103 Mouse Electronics ... 25.0 North Online Lee 125.0 2024-01 3 100004 2024-01-04 C-103 P-104 Desk Furniture ... 150.0 South Retail Brown 150.0 2024-01 4 100005 2024-01-05 C-104 P-105 Monitor Electronics ... 175.0 NaN Online Davis 525.0 2024-01
3.データを分析する
クリーンなデータセットを使用すると、ビジネス価値を高める洞察を生成できるようになります。これには、月、製品、地域ごとの売上の集計が含まれます。
月別の総売上高:
# Group by month and sum the total sales for each month
monthly_sales = df.groupby('Month')['TotalSales'].sum()
print(monthly_sales)
- データを月ごとにグループ化し、各月の TotalSales を合計します。
#Output: Month 2024-01 9075.0 2024-02 9800.0 2024-03 9075.0 Freq: M, Name: TotalSales, dtype: float64
売れ筋商品:
# Group by product, sum total sales, and sort from highest to lowest
product_sales = df.groupby('ProductName')['TotalSales'].sum().sort_values(ascending=False)
print(product_sales)
- 商品ごとの売上を合計し、人気の高いものから人気の低いものに並べ替えます。
#Output: ProductName Laptop 15200.0 Monitor 3850.0 Printer 3200.0 Desk 2550.0 Chair 2325.0 Mouse 1125.0 Name: TotalSales, dtype: float64
地域別の売上高:
# Group by region and sum total sales per region
region_sales = df.groupby('Region')['TotalSales'].sum()
print(region_sales)
- 地域ごとに総売上高を集計します。
#Output: Region East 6075.0 North 5925.0 South 8225.0 West 7500.0
4.重要な洞察を視覚化する
データは視覚化するとさらに強力になります。あなたや関係者が主要な傾向を一目で把握できるように、簡単なチャートを作成しましょう。
4.1.月次売上推移
import matplotlib.pyplot as plt # Import for plotting
# Create a bar chart of sales by month
monthly_sales.plot(
kind='bar',
title='Total Sales by Month',
ylabel='Sales ($)',
xlabel='Month'
)
plt.tight_layout() # Avoid label overlap
plt.savefig('monthly_sales.png') # Save the figure as a PNG file
plt.show() # Display the chart - 月次売上高を棒グラフとしてプロットします。
- plt.savefig はレポート用のグラフを保存します
- 棒グラフには月ごとの売上の変化が表示されます。
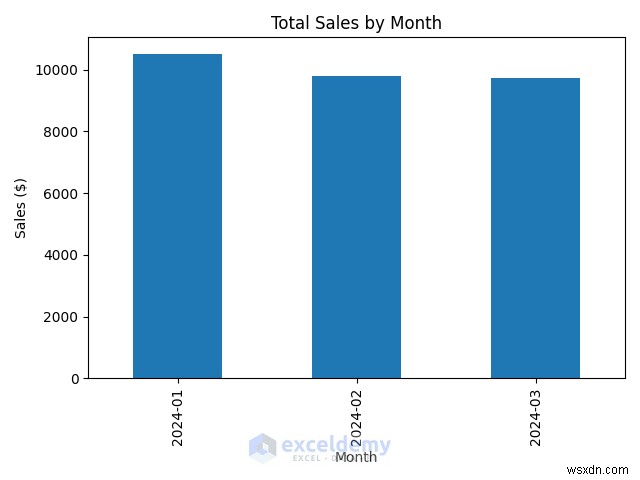
4.2.地域別売上高
# Pie chart of sales by region
region_sales.plot(
kind='pie',
autopct='%1.1f%%',
title='Sales Distribution by Region'
)
plt.ylabel('') # Remove default y-label
plt.tight_layout()
plt.savefig('region_sales.png')
plt.show()
- 地域別の売上の円グラフ。管理やマーケティングに最適です。
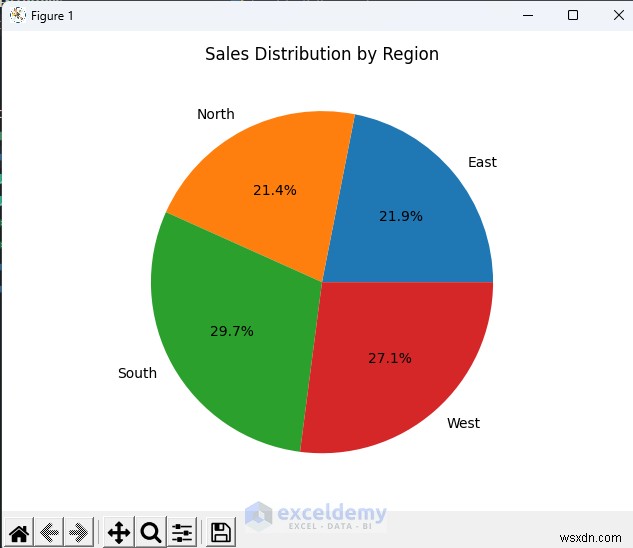
5.高度な分析とモデリング
Python では、基本的なグループ化や集計のほかに、高度な統計分析、ピボット テーブル、さらには機械学習さえも、すべてわずか数行のコードで実行できます。データをさらに深く掘り下げて、さらに多くの洞察を引き出しましょう。
5.1.記述統計
記述統計により、データセットの簡単な概要が得られ、数値列の平均、標準偏差、分位数が表示されます。
# Show summary statistics for numeric columns (mean, std, min, max, quartiles, etc.) print(df.describe())
- df.describe() すべての数値列 (数量、単価、合計売上高など) をすばやく要約します。
#Output: TransactionID Quantity UnitPrice TotalSales count 61.000000 59.000000 60.000000 59.000000 mean 100030.180328 2.542373 262.083333 478.813559 std 17.497150 1.534905 277.339497 527.085627 min 100001.000000 1.000000 25.000000 75.000000 25% 100015.000000 1.000000 75.000000 162.500000 50% 100030.000000 2.000000 175.000000 300.000000 75% 100045.000000 3.000000 200.000000 525.000000 max 100060.000000 7.000000 800.000000 2400.000000
5.2.パンダのピボット テーブル
ピボット テーブルは Excel での対話型レポートに強力であり、パンダでも実行できます。
# Create a pivot table: sum TotalSales for each Region pivot = df.pivot_table(index='Region', values='TotalSales', aggfunc='sum') print(pivot)
- ピボットテーブル() Excel のピボット テーブルと同様に、各地域の TotalSales を要約します。
#Output TotalSales Region East 6075.0 North 5925.0 South 8225.0 West 7500.0
5.3.単純な機械学習の例
単純な線形回帰 (機械学習) モデルを使用して、販売数量だけから総売上高を予測できるかどうかを見てみましょう。
from sklearn.linear_model import LinearRegression # Import linear regression from scikit-learn
# Prepare features and target variable
X = df[['Quantity']] # Feature: Quantity sold
y = df['TotalSales'] # Target: Total sales value
# Create and fit the regression model
model = LinearRegression()
model.fit(X, y)
# Print the regression coefficient (slope)
print('Coefficient:', model.coef_)
# Print the intercept (base value when Quantity=0)
print('Intercept:', model.intercept_) - scikit-learn から LinearRegression をインポートします。
- 数量を使用して TotalSales を予測します。
- モデルを適合させ、係数 (販売単位が追加されるごとに売上がどれだけ増加するか) を出力します。
#Output: Coefficient: [-37.65294772] Intercept: 596.8483500185391
6.クリーンアップ/分析されたデータを Excel にエクスポートして戻す
データのクリーニング、分析、モデリングを行った後、要約テーブルと分析情報を複数シートの Excel ファイルにエクスポートできます。これにより、重要な結果がすべてまとめられ、Excel でレビューできるようになります。
# Export summary and advanced analysis tables to a multi-sheet Excel file
with pd.ExcelWriter('sales_summary.xlsx') as writer:
# Monthly summary
monthly_sales.to_frame().to_excel(writer, sheet_name='Monthly Sales')
# Product summary
product_sales.to_frame().to_excel(writer, sheet_name='Product Sales')
# Region summary
region_sales.to_frame().to_excel(writer, sheet_name='Region Sales')
# Pivot table (total sales by region)
pivot.to_excel(writer, sheet_name='Pivot Table')
# Optionally, you can export descriptive statistics
df.describe().to_excel(writer, sheet_name='Descriptive Stats')
- コンテキスト マネージャー (… をライターとして使用): Excel ファイルが適切に保存され、書き込み後に閉じられていることを確認します。
- 各テーブルの.to_excel(): 各データフレームまたは概要を独自のシートに保存して、簡単にアクセスできるようにします。
- カスタムシート名: 各シートには、分析手順に合わせて明確に名前が付けられています。
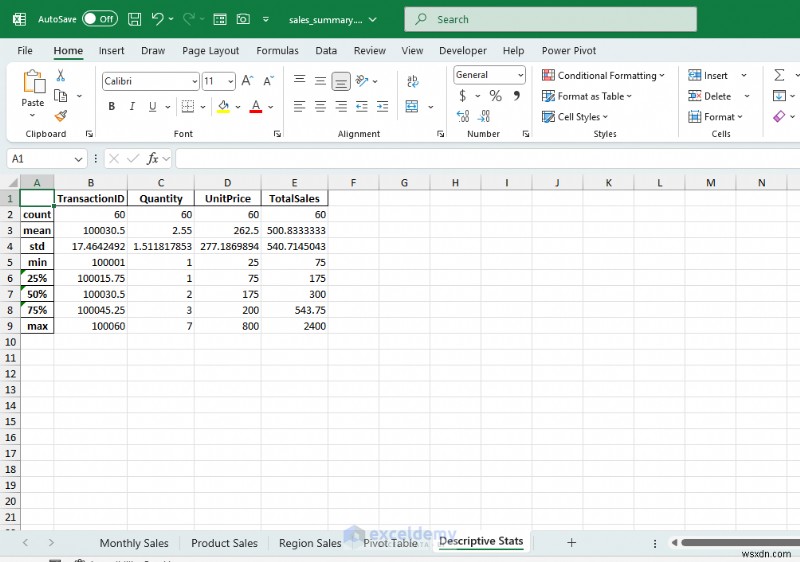
- sales_summary.xlsx を開きます Excel で。
- 月次売上、製品売上、地域売上、ピボット テーブル、記述統計の個別のシートが表示されます。
7.ワークフローを自動化および拡張する
Python を使用すると、定期的なレポートや分析を自動化できます。 次回新しい Excel ファイルを取得した場合は、ファイルを置き換えてスクリプトを再実行するだけです。すべての分析とレポートは即座に更新されます。
- すべての分析コードを 1 つの Python ファイルに保存します。
- レポートを更新するには、CSV を置き換えて次を実行します。
python Excel_to_Python.py
- さらに効果を高めるには、これを毎週または毎月のタスクとしてスケジュールできます。
結論
Excel の直感的なデータ入力とレポート機能を Python のデータ サイエンス能力と組み合わせることで、大規模で乱雑なデータセットを効率的に処理および分析できます。反復的なレポート作成タスクを自動化します。機械学習と高度な視覚化を実現します。一夜にして Python のエキスパートになる必要はありません。 1 つの単純なタスクから始めてください。それが機能したら、もう 1 つの手順を追加します。気づかないうちに、複雑なレポートを自動化することになります。
ソリューション付きの高度な Excel 演習を無料で入手しましょう!-
添付ファイルのサイズがMicrosoftOutlookの許容制限を超えています
通常、 Microsoft Outlookを使用してメールを送信する場合 、添付ファイルのサイズには注意を払いません。ただし、添付するファイルは、 Outlookに指定された制限を下回っている必要があります。 これは20MB 。したがって、メールの添付ファイルのサイズがこの制限を回避する場合は常に、 Outlook 次のエラーが発生し、ファイルの添付やメールの送信ができなくなります。 アタッチメントのサイズが許容限度を超えています したがって、 Outlookの場合 大きなサイズのファイルを電子メールの添付ファイルとして送信する必要があるユーザーは、 Outlookを変更する必要が
-
メモ帳を列のある Excel に変換する方法 (5 つの方法)
データセットは、Microsoft が所有する専用のテキスト エディター アプリケーションであるメモ帳にテキスト (.txt) 形式で保存される場合があります。ただし、Excel では、さまざまなソースからデータセットをインポートできます。さらに重要なことに、Excel はテキストを変換し、別の列を作成します。この有益なセッションでは、メモ帳を列を含む Excel に変換する 5 つの方法と適切な説明を紹介します。 メモ帳を列付きの Excel に変換する 5 つの方法 販売レポート 商品アイテムの一部 製品 ID とともに提供されます 、サテ 、および セールス 以下のスクリーンショ