データ構造のB+ツリークエリ
ここでは、B+ツリーで検索を実行する方法を説明します。 B +ツリー検索は、B+ツリークエリとも呼ばれます。このアルゴリズムは、Bツリーのクエリと非常によく似ています。さらに、これは範囲クエリをサポートします。以下のようなB+ツリーがあるとします-
B+ツリーの例 −
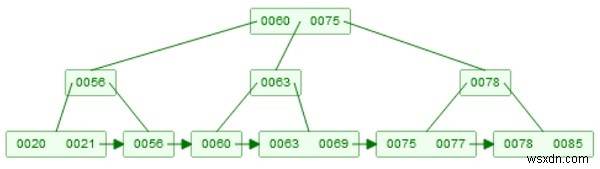
検索手法は、二分探索木と非常によく似ています。上記のツリーから63を検索するとします。したがって、ルートから開始します。63はルート要素60よりも大きく、75よりも小さくなります。したがって、要素60の右の子に移動します。右の子は63です。ただし、Bツリーを使用すると、次のようになります。結果。この場合、現在のノードは内部ノードであるため、それは実際のデータではありません。最初に適切な子に移動する必要があります。そして、リーフレベルでは、63をレコードとして見つけることができます。それが実際の結果になります。
63から78までのすべての要素を検索する場合は、各要素を1つずつバックトラックする必要はありません。初期値のリーフノードを見つけ、リンクされたリーフノードを使用して、78より前のすべてのノードを見つけるだけです。したがって、これは範囲クエリをサポートします。
Bツリー内の要素を検索するアルゴリズムを見てみましょう。
アルゴリズム
BPlusTreeSearch(root、key)-
入力 −木の根、そして見つけるための鍵
出力 −キーを持つノードの値(存在しない場合はnullを返す
)Apply binary search on records if record with the ‘key’ is found, then return required record else if current node is leaf node, and key is not found, then return null
-
データ構造の範囲ツリー
範囲ツリーは、ポイントのリストを保持するための順序付けられたツリーデータ構造として定義されます。これにより、特定の範囲内のすべてのポイントを効率的に取得でき、通常は2次元以上で実装されます。 O(log d のクエリ時間が速いことを除いて、kdツリーと同じです。 n + k)が、O(n log d-1 のストレージが悪い n)、dはスペースの次元を示し、nはツリー内のポイントの数を示し、kは特定のクエリで取得されたポイントの数を示します。範囲ツリーは、間隔ツリーで区別できます。ポイントを格納して特定の範囲内のポイントを効率的に取得できるようにする代わりに、間隔ツリーは間隔を保存し、特定のポ
-
データ構造の仮想ツリーでのスプレー
仮想ツリーでは、一部のエッジは実線として扱われ、一部は破線として扱われます。通常のスプレイは、堅い木でのみ実行されます。仮想ツリーのノードyで表示するには、次の方法を実装します。 アルゴリズムは、パスごとに1回ずつ、ツリーを3回調べ、それを変更します。最初のパスでは、ノードyから開始して、ソリッドツリーのみでスプレイすることにより、yからツリー全体のルートへのパスが破線になります。このパスは、スプライシングによって確実に作成されます。ノードyでの最後のスプレイにより、yがツリーのルートになります。非公式ではありませんが、アルゴリズムは次のように説明されています Splay(y)のアルゴリズ