RedisとApacheKafkaを使用した時系列データの処理
RedisTimeSeriesは、ネイティブの時系列データ構造をRedisにもたらすRedisモジュールです。以前に並べ替えられたセット(またはRedisストリーム)の上に構築された時系列ソリューションは、大量の挿入、低レイテンシの読み取り、柔軟なクエリ言語、ダウンサンプリングなどのRedisTimeSeries機能の恩恵を受けることができます!
一般的に、時系列データは(比較的)単純です。そうは言っても、他の特性も考慮する必要があります。
- データ速度:例: 1秒あたり数千のデバイスからの数百のメトリックを考えてください
- ボリューム(ビッグデータ):数か月(さらには数年)にわたるデータの蓄積を考える
したがって、RedisTimeSeriesなどのデータベースは、ソリューション全体の一部にすぎません。 収集の方法についても考える必要があります (取り込み)、プロセス、 および送信 すべてのデータをRedisTimeSeriesに送信します。本当に必要なのは、プロデューサーとコンシューマーを分離するためのバッファーとして機能できるスケーラブルなデータパイプラインです。
そこでApacheKafkaが登場します。コアブローカーに加えて、Kafka Connect(このブログ投稿で紹介されているソリューションアーキテクチャの一部)、複数言語のクライアントライブラリ、Kafka Streams、MirrorMakerなどのコンポーネントの豊富なエコシステムがあります。
このブログ投稿は、時系列データを分析するためにRedisTimeSeriesをApacheKafkaで使用する方法の実際的な例を提供します。
コードはこのGitHubリポジトリで利用できます https://github.com/abhirockzz/redis-timeseries-kafka
まず、ユースケースを検討することから始めましょう。ブログ投稿の目的のために単純に保たれ、その後のセクションでさらに説明されていることに注意してください。
シナリオ:デバイスの監視
多くの場所があり、それぞれに複数のデバイスがあり、デバイスの指標を監視する責任があると想像してください。ここでは、温度と圧力について検討します。これらのメトリックはRedisTimeSeriesに保存され(もちろん!)、キーには次の命名規則を使用します— <メトリック名>:<場所>:<デバイス>。たとえば、場所5のデバイス1の温度は、temp:5:1として表されます。各時系列データポイントには、メトリック、場所、デバイスの次のラベル(キーと値のペア)もあります。これは、次のセクションで説明するように、柔軟なクエリを可能にするためです。
TS.ADDコマンドを使用してデータポイントを追加する方法を理解するための例をいくつか示します。
#場所3のデバイス2の温度とラベル:
TS.ADD temp:3:2 * 20 LABELS metric temp location 3 device 2
#場所3のデバイス2の圧力:
TS.ADD pressure:3:2 * 60 LABELS metric pressure location 3 device 2
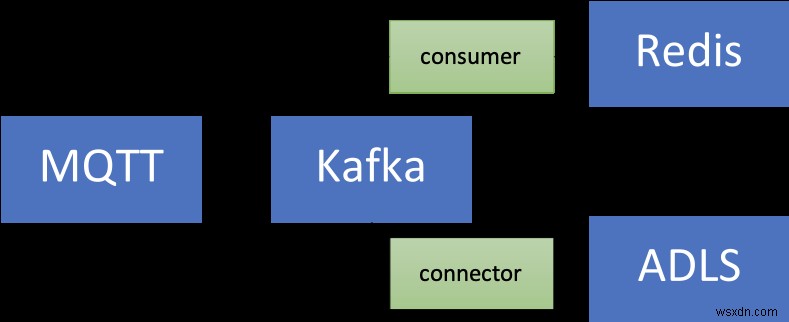
ソリューションアーキテクチャ
ソリューションの概要は次のとおりです。
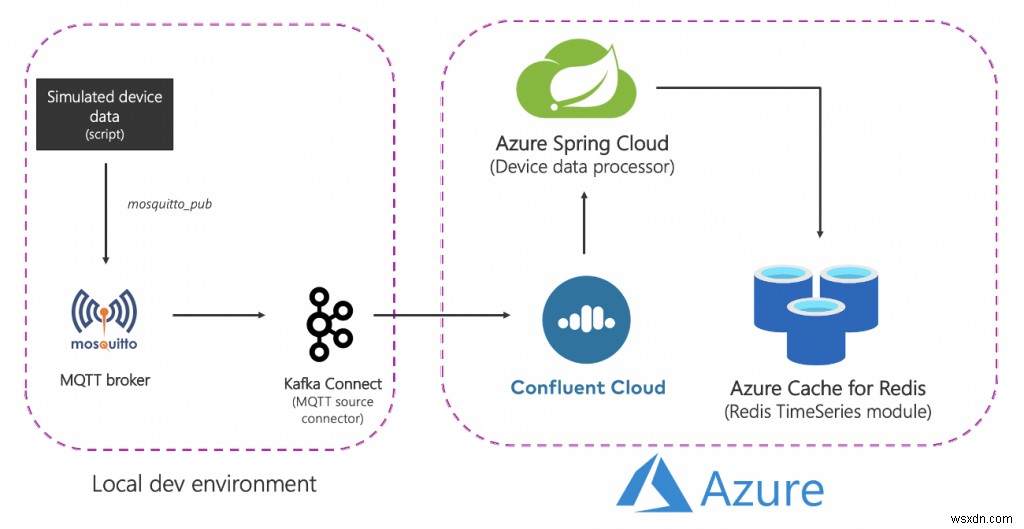
分解してみましょう:
ソース(ローカル)コンポーネント
- MQTTブローカー(mosquitto):MQTTは、IoTユースケースの事実上のプロトコルです。使用するシナリオは、IoTと時系列の組み合わせです。これについては後で詳しく説明します。
- Kafka Connect:MQTTソースコネクタは、MQTTブローカーからKafkaクラスターにデータを転送するために使用されます。
Azureサービス
- Redis Enterprise層用のAzureキャッシュ:Enterprise層は、RedisのRedisの商用バリアントであるRedisEnterpriseに基づいています。エンタープライズ層は、RedisTimeSeriesに加えて、RediSearchとRedisBloomもサポートしています。お客様は、エンタープライズ層のライセンス取得について心配する必要はありません。 Azure Cache for Redisはこのプロセスを促進し、顧客はAzureMarketplaceのオファーを通じてこのソフトウェアのライセンスを取得して支払うことができます。
- Confluent Cloud on Azure:AzureからConfluent Cloudへの統合プロビジョニングレイヤーのおかげで、ApacheKafkaをサービスとして提供するフルマネージドオファリング。クロスプラットフォーム管理の負担を軽減し、AzureインフラストラクチャでConfluent Cloudを使用するための統合されたエクスペリエンスを提供することで、ConfluentCloudをAzureアプリケーションと簡単に統合できるようになります。
- Azure Spring Cloud:Azure Spring Cloudのおかげで、SpringBootマイクロサービスをAzureに簡単にデプロイできます。 Azure Spring Cloudは、インフラストラクチャの懸念を軽減し、構成管理、サービスディスカバリ、CI / CD統合、青緑色の展開などを提供します。このサービスは、開発者が自分のコードに集中できるように、すべての面倒な作業を行います。
一部のサービスは、物事を簡単にするためにローカルでホストされていることに注意してください。本番環境グレードのデプロイでは、Azureでも実行する必要があります。たとえば、AzureKubernetesServiceのMQTTコネクタと一緒にKafkaConnectクラスターを操作できます。
要約すると、エンドツーエンドのフローは次のとおりです。
- スクリプトは、ローカルMQTTブローカーに送信されるシミュレートされたデバイスデータを生成します。
- このデータはMQTTKafkaConnectソースコネクタによって取得され、Azureで実行されているConfluentCloudKafkaクラスターのトピックに送信されます。
- Azure SpringCloudでホストされているSpringBootアプリケーションによってさらに処理され、Azure CacheforRedisインスタンスに永続化されます。
実用的なものから始める時が来ました!その前に、次のものがあることを確認してください。
前提条件:
- Azureアカウント—ここから無料で入手できます
- AzureCLIをインストールする
- JDK 11(例: OpenJDK
- MavenとGitの最近のバージョン
インフラストラクチャコンポーネントを設定する
ドキュメントに従って、RedisTimeSeriesモジュールに付属するAzure Cache for Redis(エンタープライズ層)をプロビジョニングします。
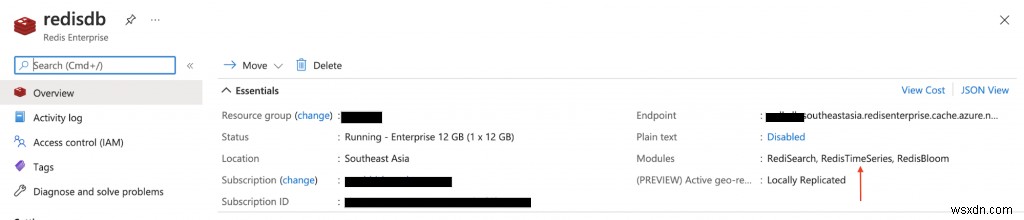
AzureMarketplaceでConfluentCloudクラスターをプロビジョニングします。また、Kafkaトピックを作成し(mqtt.device-stats) and create credentials (API key and secret) that you will use later on to connect to your cluster securely.

Azureポータルを使用してAzureSpringCloudのインスタンスをプロビジョニングするか、AzureCLIを使用できます。
az spring-cloud create -n <name of Azure Spring Cloud service> -g <resource group name> -l <enter location e.g southeastasia>
先に進む前に、GitHubリポジトリのクローンを作成してください:
git clone https://github.com/abhirockzz/redis-timeseries-kafka
cd redis-timeseries-kafkaローカルサービスを設定する
コンポーネントは次のとおりです。
- MosquittoMQTTブローカー
- MQTTソースコネクタを使用したKafkaConnect
- ダッシュボードで時系列データを追跡するためのGrafana
MQTTブローカー
Macにローカルでmosquittoブローカーをインストールして起動しました。
brew install mosquitto
brew services start mosquittoOSに対応する手順に従うか、このDockerイメージを自由に使用できます。
グラファナ
GrafanaをローカルでMacにインストールして起動しました。
brew install grafana
brew services start grafanaOSでも同じことができますが、このDockerイメージを自由に使用できます。
docker run -d -p 3000:3000 --name=grafana -e "GF_INSTALL_PLUGINS=redis-datasource" grafana/grafanaカフカコネクト
クローンを作成したリポジトリでconnect-distributed.propertiesファイルを見つけることができるはずです。 bootstrap.servers、sasl.jaas.configなどのプロパティの値を置き換えます。
まず、ApacheKafkaをローカルでダウンロードして解凍します。
ローカルのKafkaConnectクラスターを開始します:
export KAFKA_INSTALL_DIR=<kafka installation directory e.g. /home/foo/kafka_2.12-2.5.0>
$KAFKA_INSTALL_DIR/bin/connect-distributed.sh connect-distributed.propertiesMQTTソースコネクタを手動でインストールするには:
- このリンクからコネクタ/プラグインのZIPファイルをダウンロードし、
- Connectワーカーのplugin.path構成プロパティにリストされているディレクトリの1つに抽出します
ローカルでConfluentPlatformを使用している場合は、ConfluentHubCLIを使用するだけです。 confluent-hub install confluentinc/kafka-connect-mqtt:latest
MQTTソースコネクタインスタンスを作成する
必ずmqtt-source-config.jsonファイルを確認してください。 kafka.topicに正しいトピック名を入力し、mqtt.topicsは変更しないでください。
curl -X POST -H 'Content-Type: application/json'
https://localhost:8083/connectors -d @mqtt-source-config.json
# wait for a minute before checking the connector status
curl https://localhost:8083/connectors/mqtt-source/statusデバイスデータプロセッサアプリケーションを導入する
クローンを作成したGitHubリポジトリで、consumer/src/resources folder and replace the values for:
- Azure Cache for Redisのホスト、ポート、およびプライマリアクセスキー
- Confluent Cloud onAzureAPIのキーとシークレット
アプリケーションJARファイルを作成します:
cd consumer
export JAVA_HOME=<enter absolute path e.g. /Library/Java/JavaVirtualMachines/zulu-11.jdk/Contents/Home>
mvn clean packageAzure Spring Cloudアプリケーションを作成し、それにJARファイルをデプロイします。
az spring-cloud app create -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --runtime-version Java_11
az spring-cloud app deploy -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --jar-path target/device-data-processor-0.0.1-SNAPSHOT.jarシミュレートされたデバイスデータジェネレーターを起動します
クローンを作成したGitHubリポジトリのスクリプトを使用できます:
./gen-timeseries-data.sh注-データを送信するには、mosquitto_pubCLIコマンドを使用するだけです。
データはdevice-statsMQTTトピックに送信されます(これはではありません カフカトピック)。 CLIサブスクライバーを使用して再確認できます:
mosquitto_sub -h localhost -t device-statsConfluentCloudポータルでKafkaトピックを確認してください。 AzureSpringCloudのデバイスデータプロセッサアプリのログも確認する必要があります。
az spring-cloud app logs -f -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group>Grafanaダッシュボードをお楽しみください!
localhost:3000でGrafanaUIを参照します。
Grafana用のRedisデータソースプラグインは、Azure CacheforRedisを含むすべてのRedisデータベースで動作します。このブログ投稿の指示に従って、データソースを構成します。
クローンを作成したGitHubリポジトリのgrafana_dashboardsフォルダーにダッシュボードをインポートします(ダッシュボードのインポート方法についてサポートが必要な場合は、Grafanaのドキュメントを参照してください)。
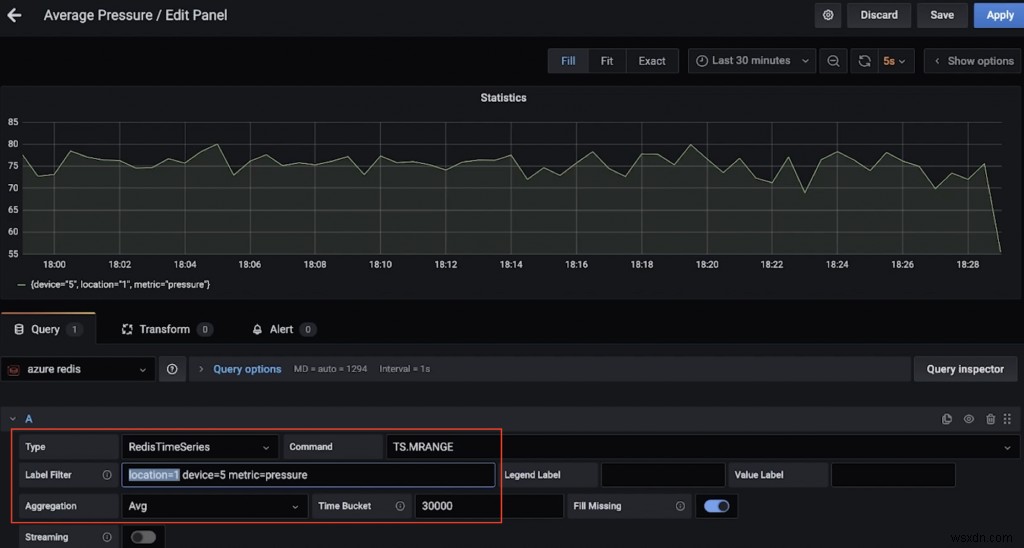
たとえば、これは場所1のデバイス5の平均圧力(30秒以上)を示すダッシュボードです(TS.MRANGEを使用)。
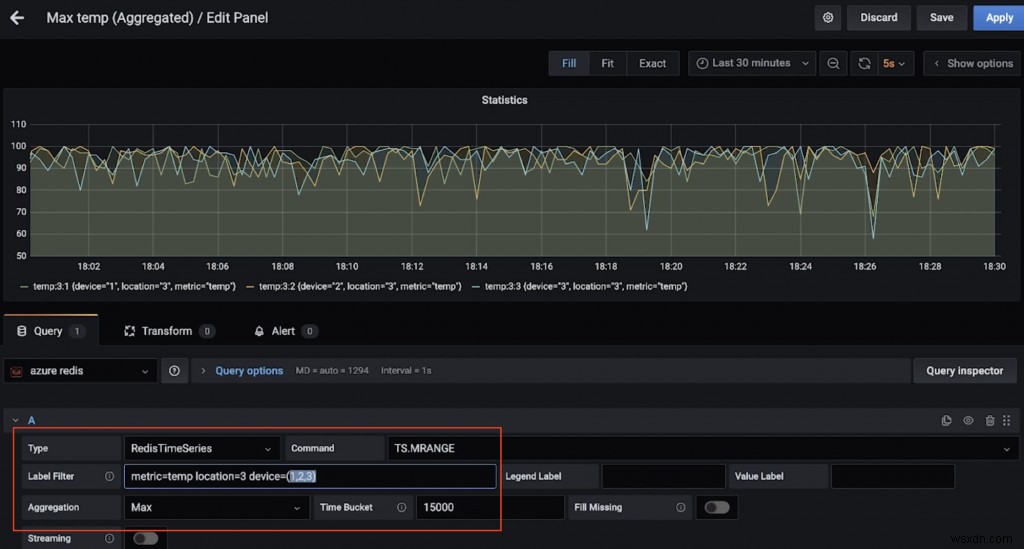
これは、場所3にある複数のデバイスの最高気温(15秒以上)を示す別のダッシュボードです(これもTS.MRANGEのおかげです)。
では、RedisTimeSeriesコマンドを実行しますか?
redis-cliをクランクアップし、Azure CacheforRedisインスタンスに接続します。
redis-cli -h <azure redis hostname e.g. myredis.southeastasia.redisenterprise.cache.azure.net> -p 10000 -a <azure redis access key> --tls簡単なクエリから始めます:
# pressure in device 5 for location 1
TS.GET pressure:1:5
# temperature in device 5 for location 4
TS.GET temp:4:5場所でフィルタリングし、すべての温度と圧力を取得します デバイス:
TS.MGET WITHLABELS FILTER location=3特定の時間範囲内の1つ以上の場所にあるすべてのデバイスの温度と圧力を抽出します:
TS.MRANGE - + WITHLABELS FILTER location=3
TS.MRANGE - + WITHLABELS FILTER location=(3,5)– +は、開始から最新のタイムスタンプまでのすべてを指しますが、より具体的にすることもできます。
MRANGE is what we needed! We can also filter by a specific device in a location and further drill down by either temperature or pressure:
TS.MRANGE - + WITHLABELS FILTER location=3 device=2
TS.MRANGE - + WITHLABELS FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS FILTER location=3 device=2 metric=tempこれらはすべて、集計と組み合わせることができます。
# all the temp data points are not useful. how about an average (or max) instead of every temp data points?
TS.MRANGE - + WITHLABELS AGGREGATION avg 10000 FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS AGGREGATION max 10000 FILTER location=3 metric=tempこの集計を行うルールを作成して、別の時系列に保存することもできます。
完了したら、不要なコストを回避するためにリソースを削除することを忘れないでください。
リソースを削除
- ドキュメントの手順に従って、ConfluentCloudクラスターを削除します。必要なのはConfluent組織を削除することだけです。
- 同様に、Azure CacheforRedisインスタンスも削除する必要があります。
ローカルマシンの場合:
- KafkaConnectクラスターを停止します
- 蚊のブローカーを停止します(例:醸造サービスは蚊を停止します)
- Grafanaサービスを停止します(例:brewサービスはgrafanaを停止します)
RedisとKafkaを使用して時系列データを取り込み、処理し、クエリするためのデータパイプラインを調査しました。次のステップについて考え、製品グレードのソリューションに移行するときは、さらにいくつかのことを検討する必要があります。
追加の考慮事項
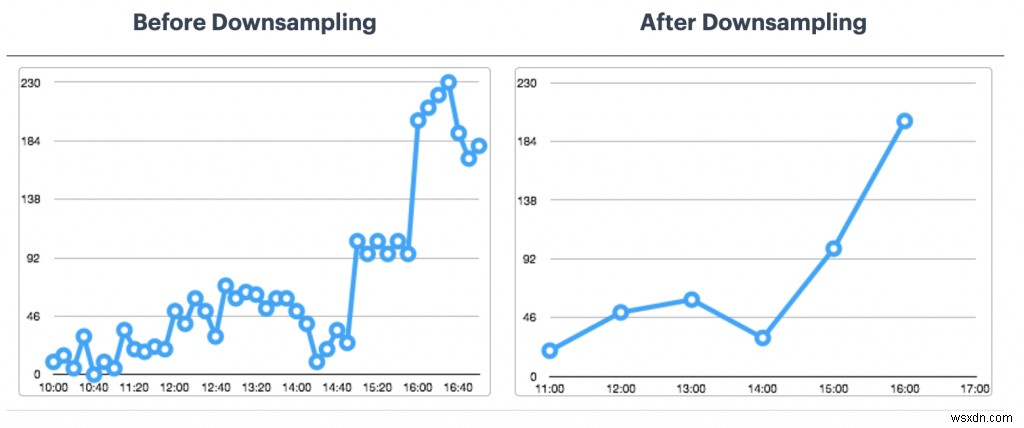
RedisTimeSeriesの最適化
- 保持ポリシー:時系列データポイントはしないので、これについて考えてください。 デフォルトでトリミングまたは削除されます。
- ダウンサンプリングと集計のルール:データを永久に保存したくないですよね?これを処理するための適切なルールを構成してください(例:TS.CREATERULE temp:1:2 temp:avg:30 AGGREGATION avg 30000)。
- 重複データポリシー:重複サンプルをどのように処理しますか?デフォルトのポリシー(BLOCK)が実際に必要なものであることを確認してください。そうでない場合は、他のオプションを検討してください。
これは完全なリストではありません。その他の構成オプションについては、RedisTimeSeriesのドキュメントを参照してください
長期的なデータ保持についてはどうですか?
時系列を含むデータは貴重です!さらに処理することもできます(たとえば、機械学習を実行して洞察を抽出したり、予知保全など)。これを可能にするには、このデータをより長い期間保持する必要があります。これを費用効果が高く効率的にするには、Azure Data Lake Storage Gen2(ADLS Gen2)などのスケーラブルなオブジェクトストレージサービスを使用する必要があります。 。
そのためのコネクタがあります!フルマネージドのAzureDataLake Storage Gen2 Sink Connector for Confluent Cloudを使用して既存のデータパイプラインを拡張し、データを処理してADLSに保存し、AzureSynapseAnalyticsまたはAzureDatabricksを使用して機械学習を実行できます。
スケーラビリティ
時系列データボリュームは、一方向、つまり上にしか移動できません。ソリューションがスケーラブルであることが重要です:
- コアインフラストラクチャ:マネージドサービスを使用すると、チームはインフラストラクチャをセットアップして維持するのではなく、ソリューションに集中できます。特に、データベースなどの複雑な分散システムや、RedisやKafkaなどのストリーミングプラットフォームに関してはそうです。
- Kafka Connect:Kafka Connectプラットフォームは本質的にステートレスであり、水平方向にスケーラブルであるため、データパイプラインに関する限り、あなたは手元にあります。 KafkaConnectワーカークラスターをどのように設計およびサイズ設定するかに関しては、多くのオプションがあります。
- カスタムアプリケーション:このソリューションの場合と同様に、Kafkaトピックのデータを処理するカスタムアプリケーションを作成しました。幸い、同じスケーラビリティ特性がそれらにも適用されます。水平方向のスケールに関しては、Kafkaトピックパーティションの数によってのみ制限されます。
統合 :Grafanaだけではありません! RedisTimeSeriesは、PrometheusおよびTelegrafとも統合されています。ただし、このブログ投稿が作成された時点では、Kafkaコネクタはありません。これは、優れたアドオンになります。
結論

もちろん、時系列のワークロードを含め、(ほぼ)すべてにRedisを使用できます。時系列データソースからRedisに至るまで、データパイプラインと統合のためのエンドツーエンドのアーキテクチャについて必ず検討してください。
-
サーバーレスRedisとReactNativeを使用したアプリ内アナウンス
モバイルアプリケーションでは、アプリのエンドユーザーに情報、警告、またはガイダンスを送信する必要がある場合があります。これを行う1つの方法は、アプリ内アナウンスをユーザーに送信することです。 このブログ投稿では、サーバーレスRedisを使用してユーザーにアナウンスを送信する方法を示すモバイルアプリケーションを開発します。 React Nativeを使用してモバイルアプリケーションを開発し、アプリに直接接続されているサーバーレスRedis用のUpstashを開発します。 アプリ内アナウンスとは何ですか? アプリ内アナウンスは、重要なことをエンドユーザーに通知したり、アクションについて通知した
-
Nuxt3とサーバーレスRedisの使用を開始する
はじめに アプリケーションの使用状況を追跡したり、リソースの使用率を制限したり、キャッシュからデータをフェッチしてアプリのパフォーマンスを向上させたりする必要がある場合は、Redisがこれらの要件に対する答えであることがわかります。 Redisは、メモリ内のKey-Valueデータベースです。これはオープンソースであり、RemoteDictionaryServerの略です。 この記事では、Upstash、Redisデータベース、およびVueSSRフレームワークの最近のベータリリースであるNuxt3について説明します。これは、Redisデータベースについて説明する初心者向けの記事で、 Nux