Google が URL を変更したいですか?提案。
これについて聞いたことがあるかもしれません。 Google は、人々がウェブサイトとやり取りする方法を変えるというアイデアを検討しています。より具体的には、人々がどのように URL を操作するか、つまり、アクセスした Web サイトを主に識別して記憶する、人間が読み取れる Web アドレスです。控えめに言っても、この提案をめぐる波及効果は非常に興味深いものでした。そして考えさせられました。
1 つ目は、変更に対する実際の反発は、変更自体よりも明らかです。 2 つ目は、URL を現在の形式よりも意味のあるものや便利なものにしようとするメリットは本当にあるのでしょうか?そのために、あなたはこの記事を読んでいます。
URL の概要
人間は、記憶を数字ではなく言葉と関連付けます。一連の数字よりも文全体または段落全体を覚えておく方がはるかに簡単です。これは、私たちの言語がほとんど単語で構成されているためです。私たちは、8 桁または 9 桁を超える数字の並びに苦労しています。単純な理由は、文字の場合、情報の一意性が比較的小さいためです。1001 と 1002 は、いわば 1 文字しか離れていませんが、違いに意味を与えるのは最後の部分だけです。単語では、文字や音の短いシーケンスを超えてあいまいになる組み合わせは比較的ほとんどありません。
したがって、Web が出現するにつれて、Web サイトを識別するために、機械による解釈ではなく単語 (文字列) を使用することがより論理的になりました。面白いサイクルです。私たちは単語 (コード) を機械語に変換し、その逆を行って、人々が意味のある方法でコンピューターと対話できるようにします。数値を使用して Web を操作するのは、機械的な方法です。弦は人間の道です。問題は、URL が人間の言語と機械の言語の混成形式であることです。一方で、アドレス自体 (dedoimedo.com など) という人間的な要素がありますが、残りはすべて、リモート サーバーが情報を見つけて検索し、ユーザーに提示するためのほとんどの指示です。これは、人々が通常の人間の脳にとって必ずしも意味をなさない方法で Web サイトと対話するという問題を引き起こします.
もう 1 つの問題は、URL に埋め込まれた情報の忠実度がまったくないことです。現実世界の物理アドレスによく似ています。 17 Orchard Drive に行っても、その住所はわかりません。それはオフィスかもしれないし、私邸かもしれないし、ダンスホールかもしれない。人、瓦礫、いけにえの祭壇など、コンテンツに関する情報もありません。
同様に、URL は目的地 (接続しているサイト) をまったく反映しません。場合によっては相関関係があるかもしれませんが、全体として、サイトが何であるか、またその目的を理解していない限り、意味がありません。これは、大企業だけでなく小規模なサイトにも当てはまります。
たとえば、Google は実際には検索エンジンであるとは言いません。 Yahoo は検索エンジンだとは言いません。 Bing とはどういう意味ですか?アマゾンは川なのか、森なのか、それとも巨大なオンライン市場なのか?これらのサイトを信頼するようになったのは、URL 情報にプロトバリューがあるからではなく、使用と一般的な評判によってです。しかし、良くなったり悪くなったりします:
- サイトの文字列とサイトの目的の間に相関関係がない
- サイト文字列とサイト名 (またはその背後にあるビジネス) の間に相関関係がないこと。
- ウェブサイトのページ タイトルとサイト名の間に相関関係がない
- サイトの目的に関する情報なし
さらに、特定のページに移動したときに、ページ タイトル、URL、およびコンテンツの間に相関関係がない場合があります。何かのサイト、kittens.html というページに行くこともできますが、それは車の猫の形をしたデカールに関するものかもしれませんし、実際には小さな毛むくじゃらのものに関するものかもしれません。または、まったく別の何か。サイトは実際にはダニーのショップと呼ばれ、URL は mysitenstuff.org のようになります。
そして、それはさらに悪化します。ここまでは、方程式の人間的要素についてのみ説明してきました。次に機械部分です。サブドメイン。 m、www、www3のようなもの。 http、https、ftp などのプロトコル。区切り文字、サブディレクトリ。サイトがページを表示する不均一な方法 - 日付、乱数、文字列など。それから、指示もあります。ページの URL 文字列の末尾に &uid=1234567&ref=true のようなものが追加されている場合がありますが、これはユーザーにとっては何の意味もありませんが、コンテンツを提供または解析している Web サーバーやアプリケーションに特定のことを伝えます。 .
これらの URL オプションはすべて同じコンテンツに解決されますが、見た目とレンダリングはすべて異なります。
最後に、信頼の尺度はありません。 Web サイトは、何らかの方法で検証されるまでは同等の価値があります。早い段階で、オンライン ショッピングがより一般的になるにつれて、デジタル証明書の概念が生まれました。信頼できる機関は、暗号化された改ざん防止バッジの背後で信頼性とセキュリティの両方を保証します。コミュニティの取り組みとページ ランキング (独自の場合もある) は、ドメイン (サイト) とそのコンテンツに関連する価値の二次的な尺度になりましたが、基本的に、これは URL 自体にはまったく反映されません。
問題は、変更が必要かどうかです。多分。そうでないかもしれない。インターネットは機能し、問題なく拡張できます。
答えはソリューションにあります。しかし、最初に、もう少し哲学について説明します。提案を聞いたときの反応はどうでしたか?
私が見た限りでは、ここには 2 つの主要なキャンプがあります。変化を歓迎し、これが Web をより良くするだろうと感じている人々 (改善の量を定義する必要があります。そうでなければ、それは単なる空論です)。そして、変化に反対する人々。 2 番目のグループは 3 つに分けることができます:目的の変更に抵抗する人々、技術的なメリットと想定される利点に反対する人々、3 番目のグループは、この変更を提案または主導する営利企業を信頼しない人々です。
実際、これははるかに大きな哲学的問題を提起します。 Google がこれを主導することを許可する必要がありますか?
結局のところ、何年にもわたって、多くの営利企業が、私たちが何も考えずに今日使用している優れた製品を作成してきました.初期の騒ぎと議論は長い間忘れられています。しかし、そこにはお金が関係しており、それは強力な動機付け要因であり、会社の収益を強化するために行われました.名前が何であれ、株主に対して責任を負う会社には、同じことが必然的に起こります。 Google は、モバイルの世界と検索分野で大きな影響力を持っているため、リーダーの地位を占めています。しかし、これはどの企業にも当てはまる可能性があり、最終的には根本的な要因は同じです。一部の人にとっては、これだけが重要です。営利目的であれば、人類に利益をもたらす公平な解決策とは言えません。副次的効果としてかもしれませんが、主な目的としてではありません.
そして、これは本当に興味深いものです。抵抗は、テクノロジー自体と関係があるというよりも、Google の長年にわたる反映です。一見、無害な (会社のマニフェストから消えた) から、ありふれたビッグボーイ スーツの会社に変わりました。
この主張を裏付けるもう 1 つの例は、Google が AMP を主張していることです。AMP は、通常の HTML を特別な AMP ディレクティブでラップする独自のモバイル最適化プロジェクトです。ページの読み込みなどに関しては多少のメリットはありますが、全体として、これは非常に悪いです。これは、Internet Explorer 6 で見られた問題の繰り返しです。Microsoft は、Web 標準に準拠していない新しいディレクティブを大量に作成し、ブラウザ固有の HTML/CSS の混乱を引き起こしましたが、最近部分的に解明されたばかりです。
2006 年にデドイメドを始めたとき、これは大きな問題でした。当時、ほぼすべてのサイトの HTML に IE6/7/8 オーバーライドがありました。私はこれらを実装せず、W3C 仕様に固執することに決めました。ビジターにペナルティが課せられる可能性などにかかわらずです。共通の標準化された方法で設計を行う唯一の方法は、伝説のティム・バーナーズ=リーがそれを思い描いた方法であるからです。歴史は私の正しさを証明した。今日でも、すべてのページに有効な HTML と CSS が含まれていることを確認しています。これは、最近の市場ではめったに見られないことです。また、特定のブラウザに特別なオーバーライドを使用すると、インターネットの質が低下します。
絶滅危惧種の有効な HTML。
現在、Google は AMP を使用して HTML/CSS コンプライアンスの相違の問題を再現しています。 Web は中立であり、公平な国際基準に準拠している必要があります。どちらの会社が望んでいようとも、それに従って形作られるべきではありません。
したがって、この URL は、大企業、特に個人データを扱う企業に対する不信感を高める触媒にすぎません。感情をテクノロジーから切り離すためには、まずこの問題に取り組む必要があります。そうしないと、技術的なニーズではなく感情的なニーズに対処しようとするため、将来のすべての提案に欠陥が生じます。
これに対する解決策はありません。Google だけが Google を変えることができます。もちろん、彼らが望むなら。
変化
これを忘れてはなりません。慈悲深いアイデアは、人生の勢いに飲み込まれ、初期の概念の倒錯したバージョンになります。これは、意図的な設計によって発生することもあれば、事前に確認または計画することができなかった無数の小さな決定や制約によって偶然発生することもあります。使用しているほとんどすべての製品について考えてみてください。 5 年か 10 年前のことを考えてみてください。変化が見られますか?あなたはそれが好きですか?そして、あなたも人として変化したことを忘れないでください。今日の世界に対する認識は、数年前に感じたものとはまったく異なります.
Google のソリューション、または他の誰かのソリューションは、世界で最高のものかもしれません。今から 17 年か 20 年後には、最善の意図と世界中のあらゆる深い学習にもかかわらず、予測不可能な方法で変化する可能性があります。そこに悪意がある必要はありません。物事がどのように行われるかがゆっくりと忍び寄り、人々は新しい規範に慣れて古い伝統として受け入れ、元のものが長い間忘れられるまで先に進みます.
そこに大きな問題があります。今日合意された提案が何であれ、たとえ Google のソリューションが完璧であったとしても、Google 自身を含め、企業が非公開の独自の実装を作成することを止めるものは何もありません。または競合他社。
インターネットの民営化は実際にすでに起こっています。インターネットはますます小さくなっています。まず、ブローカー (検索エンジン、ニュース ポータル) を通じてほとんどの情報を消費しています。人気のある検索サイトに掲載されていない限り、新しいコンテンツを見つけることはめったにありません。モバイルでは、それはさらに悪いです。人々はもうブラウジングすることはほとんどありません。彼らはアプリを使用し、単一の集中型ストアでサービスを提供しています。
典型的なスマートフォンやスマート TV が何であるかを見てみましょう。これは、キュレーションおよびフィルタリングされたコンテンツを備えた、厳密に制御されたプラットフォームです。電話アプリを起動すると、バックグラウンドで何をしているのか、どの URL に接続しているのかわかりません。プラットフォームが言うことを実行することを信頼するか、それを使用しないかのどちらかです。これは、日常生活に侵入的で必要なテクノロジーがどれほど増えているかを考えると、ますます難しくなっています。そしてこれが起こったのは、インターネットが本格的にブームになってからわずか 10 年か 15 年後のことでしょうか。 20 年か 50 年後に何が起こるか想像してみてください。
人権としてのインターネット
いわば、インターネットはすでに世界人権宣言に追加されています。しかし、それだけでは不十分です。
私たちはすでにインターネットタスクフォースを持っています。私たちには基準があります。また、主に国内のプライバシー法もあります。しかし、デジタルの自由と、ウェブの中立性に対する私人による個人レベルでの不干渉を保証する超政府機関はありません。パイが大きすぎて手放せないので、これが起こらない可能性は十分にあります。
私に言わせれば、ウェブの特定の部分を本当に手に負えないものにする唯一の方法は、それらをジュネーブのようなデジタルのコンベンションに組み込むことです。これは素朴で理想主義的に聞こえるかもしれませんが、今日、あなたは、あなたのインターネットを支配し、彼らがあなたにそれを与えることをどのように決定したかに左右されます.
私の提案
よし、最後に技術的な話だ。
いずれにせよ、URL 構造の大部分は次のとおりです。人間 |
推進要因は、中立性、セキュリティ、完全性、使いやすさです。セキュリティと整合性は、デジタル証明書によってすでに比較的うまく解決されていますが、改善の余地があります。中立性は URL 文字列の人間の部分に埋め込まれており、使いやすさは最初と最後の部分にかかっています。
機械部品 1
ご存知のように、最近のブラウザは、アドレスの https:// や www の部分を表示しないことで、Web アドレス文字列の人間の部分からマシンの部分を分離しようとしています。 http または https。これは悪くない。ただし、Secure-Not Secure の概念は十分に明確ではありません。それは驚くべきことであり、慰めでもありますが、正当な理由によるものではありません - これについては、人間の部分のセクションで説明します.
HTTP:// や HTTPS:// は 99% の人にとって何の意味もありません。 URL 文字列を他のアプリケーションに渡して、適切なプロトコルを使用して接続できるようにする場合に便利です。さらに、ここには実際に冗長性があります。証明書は、接続のセキュリティを確認する役割を既に果たしています。
答えは、接頭辞 (機械部分 1) を完全に削除して証明書のみを使用するか、象徴的な理由で接頭辞を web のようなもの (実際の区切り文字など) に置き換えることです。これにより、仮想現実、純粋なメディア ストリーミング、チャットなど、他の非 Web プロトコルの将来の実装への可能性が開かれる可能性があります。また、config、chrome などのブラウザー固有の内部ページにも対応します。
人間の部分
人間の部分は侵害されていない必要があります。サイト ページのアドレスが何であれ、それは保持され、難読化されることなく常にユーザーに表示される必要があります。一部のサーバーが行うドメイン名、目的、ロジック、日付、タイトルの一致など、アプリケーションが従うことができる適切な URL プラクティスのガイドラインが必要です。しかし、これは物理アドレスのようなものです。 We don't get to choose how streets are named, or how the home address is formed, and there are so many options worldwide. Same here.
This is part of what we are - and changing this language also breaks communication. There is no universal piece of objective information in a domain name, page title or similar. It's all down to what we want to write, and so, trying to tame this into submission is the wrong way forward.
But what about trust, integrity, spoofing?
If you mistype a site name, you could land on a wrong page. Or people ignore security warnings and give their credentials out on fake domains. Are there ways to work around these without breaking the human communication?
Well, certificates help - but they won't stop you going to a digitally signed site that is serving bogus content. Nor can they stop you from giving out your personal data. But on its own, technology CANNOT stop human stupidity or ignorance. It can be mitigated, but the unholy obsession with security degrades the user experience and breaks the Internet. So what to do?
I believe it is better to compromise on security than on user experience. The benefits outweigh the costs. There is crime out there, but largely, there's no breakdown of society and no anarchy. Because if we compromise on freedom for the sake of security, well, you know where this leads.
All that said, if the question is how to guarantee human users can differentiate between legitimate and fake sources supposedly serving identical content, beyond what we already have, then the answer lies in another question. If you give out two seemingly identical pages to a user, what is the one piece that separates them? The immediate answer is:URL. But if the user is not paying attention to the URL, what then?
The answer to that question could be a whitelist mechanism. In other words, if a user tries to input information on a page that is not recognized (in some way) as a known (read good) source, the browser could prompt the user with something like:You're currently on a page XYZ and about to fill in personal information, is this what you expect?
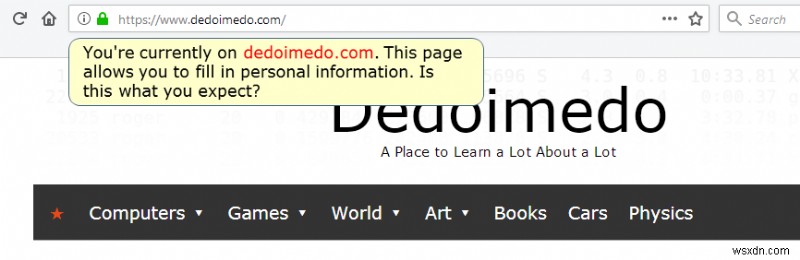
Crude illustration/mockup of what could be used to warn users when they are about to provide personal information on websites that are not "whitelisted" in some way.
People might still proceed and give away their data, but hey, nothing stops people from electrocuting themselves with toaster ovens in a bath tub, either. It is NOT about changing the URL - it's about helping people understand they are at the RIGHT address. In a way that does not break the user experience.
Now, let's talk about the machine string some more, shall we.
Machine part 2
The second part needs to be standardized. Today, servers and applications parse, mangle and structure URLs any which way they want. You can add all sorts of qualifies and key pair values, and end up with things like video autoplay, shopping cart contents, pre-filled forms, and more. In a way, this is lazy, convenient coding.
The standardization needs to be neutral - not dependent on how the browser or the site wants to present its information, because it's part of the problem today (including phishing and whatnot). I think that websites need to be forced to present a simple URL structure to the user that responds in a valid way.
The answer is:URL language. The same way browsers parse HTML and CSS, there could be a URL standard for the machine part. This could be a relatively small dictionary, and it would include somewhat STILL human-readable keys like (just a small subset of possible examples):
- unique-user-identifier - this would be a value that maps to an individual browser/user.
- javascript-status - if the client supports or runs Javascript.
- media-autoplay - whether media should play.
- media-timestamp - playback position for media.
- page - navigation element.
- Other similar keys.
And the rest would be ignored by the browser - provided all browsers adhere to the international standards and offer the same behavior and responses. Yes, the same way if you invent a new CSS class or HTML directive, and it does not exist and/or hasn't been properly declared, it gets ignored. The same way the remote application should ignore non-existent standard keys.
There must be special keys (flags), like dev=1 or debug=1 that would force the browser to interpret all provided machine parts and forward them to the server, which would also allow site devs/owners to troubleshoot their applications and offer full backward compatibility to everything we have on the market today. But then, the user could be prompted if such a combo is spotted in the URL address:
This site wants to run in dev mode. Do you want to allow it?
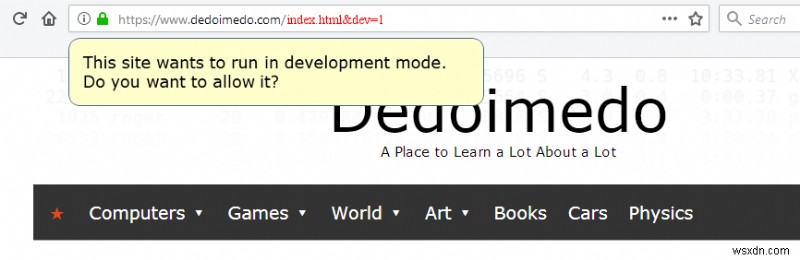
Crude illustration/mockup of what a standardized URL construct might be, with dev/debug flags.
This might enhance security too. Theoretically, the browsers could allow the user to block tracking via URL and not just on loaded pages. For instance, lots of email invitations and such come with a whole load of tracking, embedded in the URL. Privacy-conscious browsers could strip those away - or ask the user.
The URL is convenient for passing information to the application - but there's no real reason for this. When you click Buy on Amazon or PayPal, you don't see what happens. When you read Gmail, you don't see what happens. Buttons hide functionality, and it is not reflected in the URL.
To sum it up:the machine-part of the URL would contain a limited dictionary of standardized keys that would allow the information to be passed this way, but the rest would be ignored unless special flags like dev or debug are used, with the option to prompt the user. Enhanced security, enhanced privacy.
If ever defined, standardized and adopted, this will take time - an industry-wide effort. Now, is there a way to ignore forty years of legacy and existing implementations? The answer is, no bloody way. A change to the URL structure is something that will take decades. If you think IPv4 to IPv6 is complex, the URL journey will be even longer.
Finally, Quis custodiet ipsos custodes? Back to square one.
結論
The URL change is not important on its own - it is, but the technical part is relatively easy. The bigger issue is that, at the moment, people still have a fairly unrestricted access to the Web, largely due to the nerdy nature of the human-readable Web addresses. The URL is one of the old pieces of the Internet, and as such, it is mostly unfiltered and without abstractions. Once that goes away, we truly lose control of information. The world becomes a walled garden.
Google's general call to action makes sense, from the technical perspective, but the change could accidentally lead to something far bigger. Something sinister. Something sad. The death of the Internet as we know it. The ugly, cumbersome URL was invented in an age of innocence and exploration. As confusing as it is, it's the one piece that does not really belong to anyone. Any future change must preserve that neutrality.
If I were Google, I wouldn't worry about the URL. I would focus on why people don't want Google to be the arbiter of their Internet. Understand why people oppose you, regardless of the technical detail. Because, in the end, it's not about the URL. It's about freedom. Once that piece clicks into place, the technical solution will be trivial.
Food for thought.
乾杯。
-
Google ドキュメントで余白を変更する方法
特に他の人に送信したい場合は、ファイルにすっきりした外観を提供するため、Google ドキュメントの余白に問題はありません。または、毎日同じワークブックに飽きて、毎日 Google ドキュメントを取得している人に感銘を与えたい場合は、Google ドキュメントの余白を変更できます。 Google ドキュメントの余白 ページのすべての面に表示されます。ページの左、右、上、下。デフォルトの余白は優れていますが、作業に応じて変更できます。実際、この余白はドキュメント全体で同じにする必要はありません。それに応じて、Google ドキュメントで余白を変更することもできます。 それでは、Google
-
Google Chrome 69 で UI テーマを変更する
Chrome について何を言いたいかというと、何年にもわたってかなり一貫したルック アンド フィールを維持してきました。変更はほとんど内部で行われ、ユーザーがブラウザーを操作する方法を妨げることはありません。しかし時折、OS スペース、特にモバイルの世界での幅広い影響力に導かれて、Google はいくつかのスタイル変更を行いました。最も注目すべきは、Chrome UI にマテリアル デザインを導入したことです。そして今、別の改良が行われています。 Kubuntu Beaver で新しく更新された Chrome 69 の新しい外観に気付きましたが、あまり満足できませんでした。フォントは灰色で淡