データスクレイピングツールを使用してWebページからデータを抽出する方法

Webページからコピーして貼り付け、手動でスプレッドシートに配置する場合は、データスクレイピング(またはWebスクレイピング)が何であるかを知らないか、それが何であるかは知っていますが、クリックの数時間を節約するためだけにコーディングする方法を学びます。
いずれにせよ、あなたを助けることができる多くのノーコードデータスクレイピングツールがあり、DataMinerのChrome拡張機能はより直感的なオプションの1つです。運が良ければ、実行しようとしているタスクはすでにツールのレシピブックに含まれているので、独自の作成に必要なポイントアンドクリックの手順を実行する必要もありません。
>データマイニングはどのように機能しますか?
Data Minerは、ロードしたページのテキストを調べることにより、Webページから適切にフォーマットされたExcel/CSVファイルにデータを取得するのに役立ちます。つまり、少なくともいくつかのパターンを認識するのに十分なHTMLに慣れている必要がありますが、あまり広範ではありません。高度なHTMLやJavaScriptのスキルは確かに一部のタスクに役立ちますが、ほとんどの場合は必要ありません。また、出力がクリーンで整理されていることを確認できるように、少なくとも基本的なスプレッドシートのスキルが必要です。
1。データマイニングを設定する
Chromeまたは別のChromiumブラウザを使用して、拡張機能をインストールします。拡張機能のつるはしアイコンがツールバーに表示され、それをクリックすると、アカウントを設定できるページに移動します。無料版では、月に500回のスクレイプが提供されます。これが毎日行うことでない限り、おそらくこれで十分です。
2。データを読み込む
まず、データを抽出するページに移動します。複数のページのデータがある場合、またはその一部がボタンの後ろに隠れている場合は、問題ありません。これに対処する方法があります。今のところ、プログラムが何を探すべきかを認識できるように、代表的なサンプルが必要です。
3。レシピを確認する
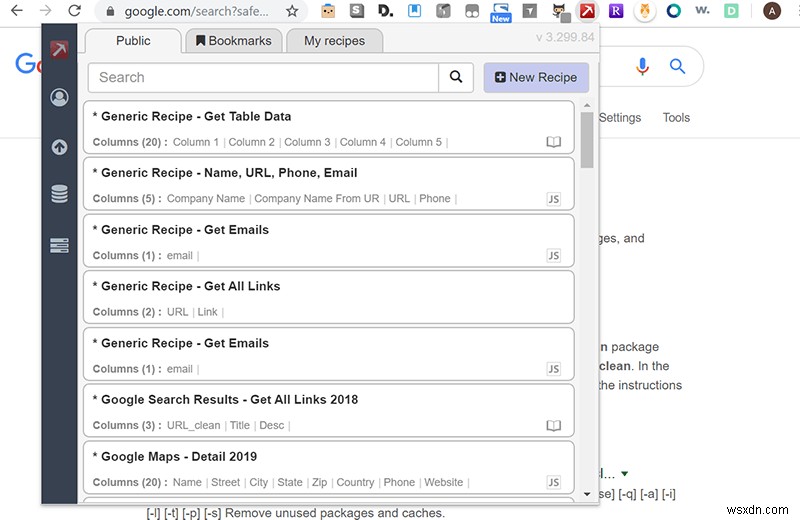
次に、データマイナーを開き、[公開]タブで既存のレシピを確認します。人気のあるサイトを利用している場合は、他の誰かがあなたが探しているデータを取得するプロセスをすでに作成している可能性があります。これにより、かなりの時間を節約できます。たとえば、Google、Amazon、Twitterなどのサイトには、リンク、価格、テキスト、その他のデータを即座にダウンロードするのに役立つレシピがたくさんあります。 「実行」ボタンをクリックしてレシピをテストし、DataMinerが生成するスプレッドシートのプレビューを表示できます。 [編集]ボタンを押して、ニーズに合わせて既存のレシピを微調整することもできます。
4。ページタイプ
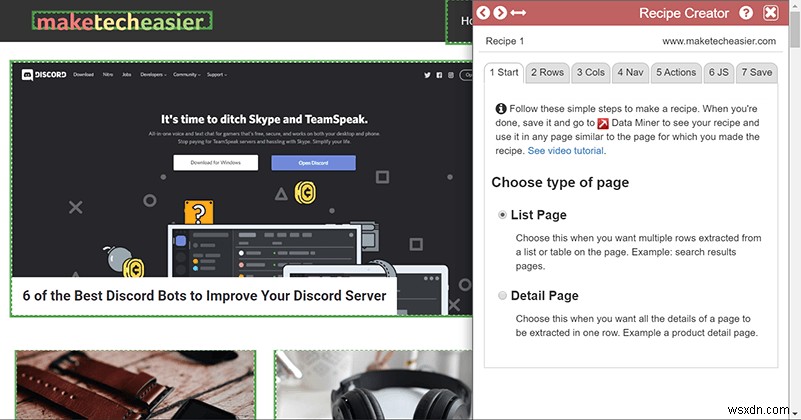
さて、事前に作成されたレシピはあなたのために働きませんでした。大丈夫です、あなたはあなた自身のものを作ることができます。 「新しいレシピ」ボタンをクリックするだけで開始できます。
最初に選択するのは「リストページ」または「詳細ページ」です。
1つのページから複数行のデータを取得する場合は、[リストページ]を選択します。たとえば、すべての検索結果のリンクとページタイトルをダウンロードしたり、フィード内の投稿の日付とコンテンツを取得したりできます。これはおそらく最も一般的なタイプであり、ここでデモとして使用します。 (詳細ページの手順は基本的に同じです。)
1つのページに1つの情報に関するさまざまな情報がある場合は、[詳細ページ]を選択します。たとえば、価格、説明、リンク、評価を取得してすべてを1行にまとめる必要がある商品ページなどです。 。
ステップ5:行を作成する
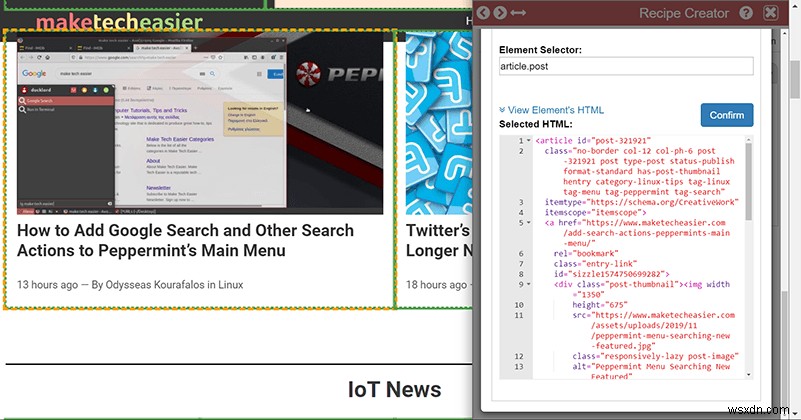
「検索」ボタンを押して、黄色の選択ボックスが最終的なスプレッドシートへの1つのエントリに必要なすべてのデータをカバーするまでマウスを動かします。たとえば、検索結果をダウンロードする場合は、タイトル、URL、説明を含めるのに十分な大きさの領域を強調表示する必要があります。これらはそれぞれ、次の手順で別々の列に配置できます。選択するには、 Shiftを押します 鍵。誤ってクリックしても心配しないでください。 Data Minerは、ページから移動した場合でも、レシピの進行状況をすべて保存します。
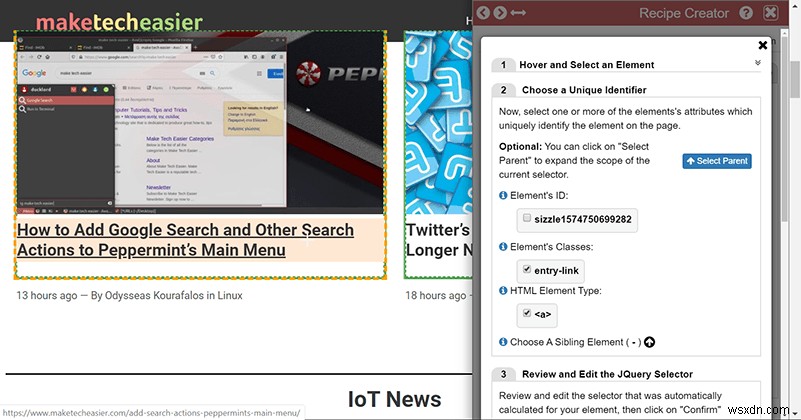
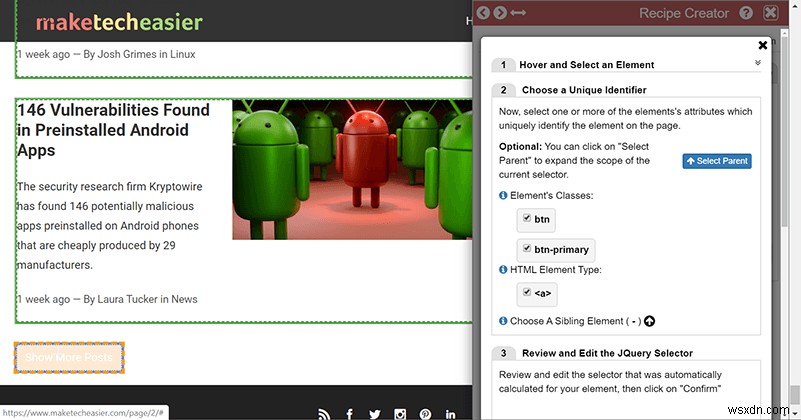
次に、[要素のクラス]または[HTML要素の種類]セクションのチェックボックスの少なくとも1つをオンにします。理想的には、選択したものと同じカテゴリにあるページ上のすべての要素をカバーするために、選択の複製が表示されます。
セレクターで必要なものがすべて網羅されていない場合は、要素の1つだけを選択して、[親を選択]を押してみてください。これにより、ボックスが大きくなり、必要なものがすべてキャプチャされます。そうでない場合は、HTMLを少し掘り下げて、必要な要素のクラスとタイプを特定する必要があります。疑わしい場合は、複数のリストエントリをカバーせずにボックスができるだけ大きくなるまで、[親を選択]をクリックします。これにより、列を選択する際の柔軟性が高まります。
Data Minerには、下部に「要素のHTMLの表示」オプションがあり、カスタムセレクターを入力することもできます。言いたい場合は、クラス「product」のページ上のすべてのリンクを取得し、a.productと入力するだけです。 。ここで、HTML/CSSの基本的な知識が本当に役立ちます。
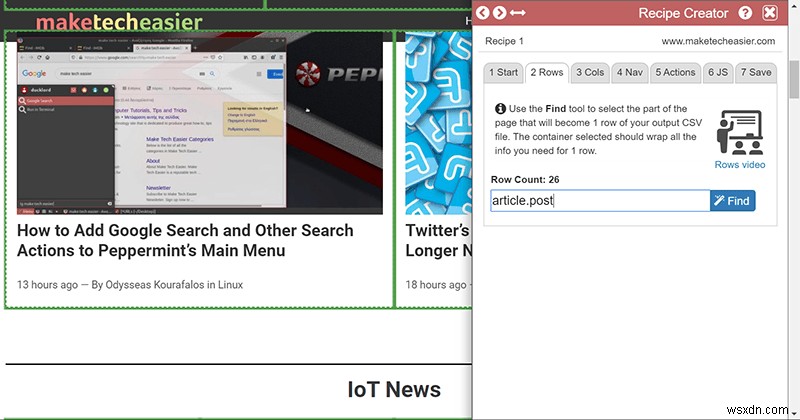
メインの行メニューに戻ると、レシピがスプレッドシートに作成するエントリの数を示す「行数」が表示されます。すべてを把握していない場合は、行の選択を再確認する必要があります。
6。データを列に分割する
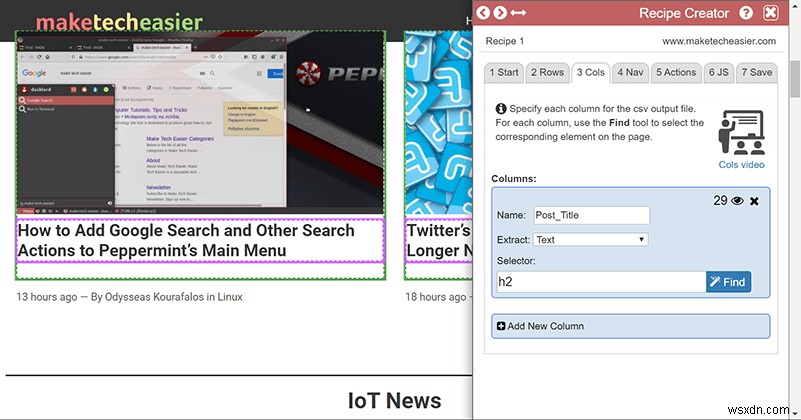
行に対してすべてのデータを選択したら、それをさまざまな列カテゴリに細分化して、すべての見栄えを良くします。ここで行うすべての選択は、行に対して選択したボックスのサブセクションである必要があります。
列を作成するには、行の場合と同じように、列の名前を入力し、[検索]ボタンを使用して抽出するものを選択します。最も一般的なデータは、おそらくテキスト、URL、または画像のURLです。テキストリンクにカーソルを合わせてURLを取得するのは、少し難しい場合があります。要素タイプが<a>になるレベルに達するまで、「親の選択」を押す必要がある場合があります。 、これはリンクのHTMLタグです。
列に適切な種類のデータがあることを確認するには、各列の名前の右側にある、選択されている列の数を示す数字の横にある目のアイコンを押すだけです。これにより、その列のすべての行エントリのプレビューが表示されます。何かがオフになっている場合は、戻って、行を識別するために選択したタグとタイプを微調整します。 HTMLビューアを開いて、取得しようとしているデータに関連付けられているパターンを確認することを恐れないでください。
7。次のページに移動する方法をデータマイニングに指示します
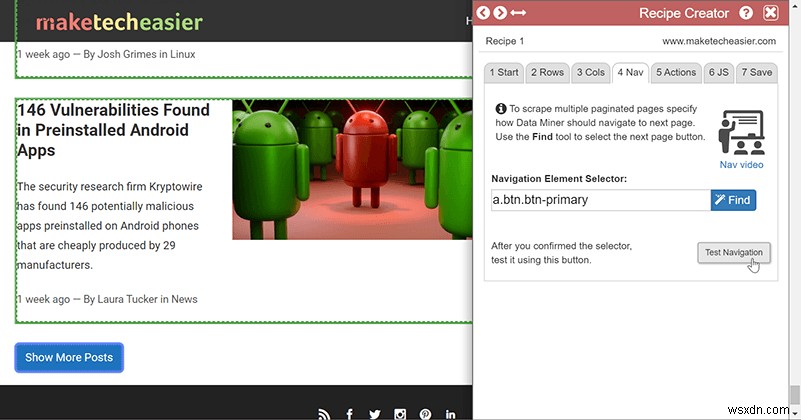
抽出するデータのページが複数ある場合は、すべてのページをクリックしてレシピを何度も実行したくないでしょう。これを回避するには、次のページに移動するためにクリックする必要のあるナビゲーションボタンの場所をDataMinerに指示するだけです。 「ページ2」のようなものをクリックしないように注意してください。クリックすると、ページ2に移動します。ここでも、<a>を選択していることを確認してください。 要素を選択し、[ナビゲーションのテスト]ボタンを使用して、機能していることを確認します。
8。データをロードするためにクリックまたはスクロールする場所をデータマイニングに指示します
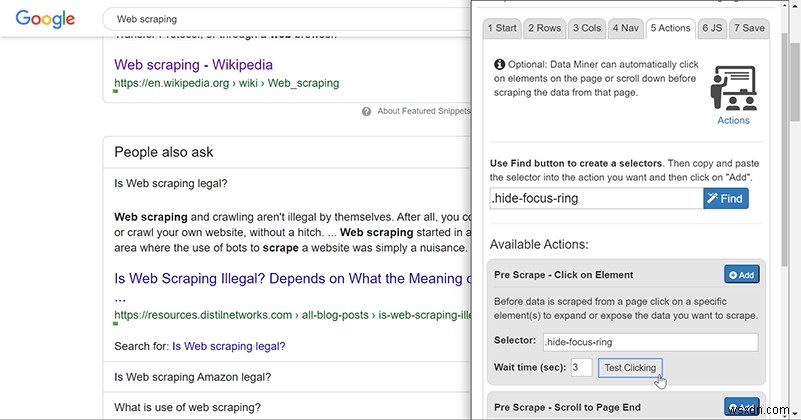
一部のページでは、何かをクリックするか下にスクロールするまでデータが読み込まれません。幸い、DataMinerはこれらのことも実行できます。上部にある「検索」ツールを使用して(これでかなり上手くいくはずです)、操作する必要のある要素を選択し、セレクターを適切なボックスに入れてテストし、機能することを確認します。
どのセレクターが要素または無限スクロールバーをアクティブにするかを正確に把握するのは難しい場合がありますが、基本的なHTMLの知識と試行錯誤により、ここでかなりの距離を得ることができます。ここで操作する必要があるもののほとんどはJavaScriptベースですが、Data Minerはアクションに関連付けられたCSSセレクターを知っているだけで、アクションをアクティブ化できるため、ほとんどの場合、コードをいじくり回す必要はありません。
次のステップでは、カスタムJSを追加して、ほぼすべてのことを実行できますが、これは非常に高度であり、基本的なスクレイピングに必要なものを超えています。
9。レシピを保存して実行します
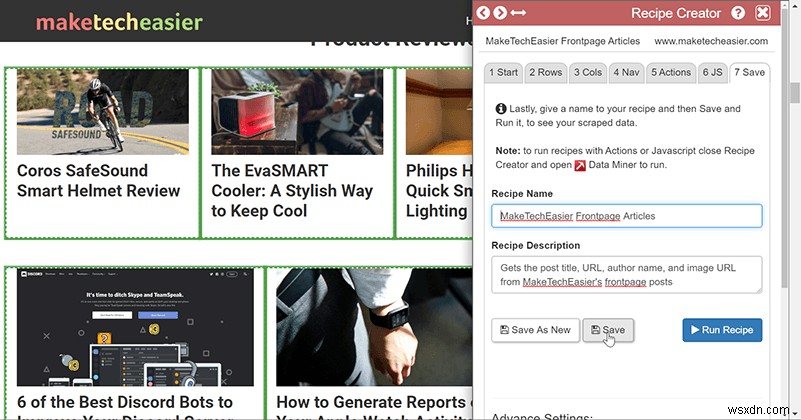
おめでとう!それでは、すべてが一緒になっているかどうかを確認します。現在のページでレシピを実行し、プレビューをチェックして、行と列が想定どおりに機能しているかどうかを確認します。そうでない場合は、戻ってレシピを編集できます。
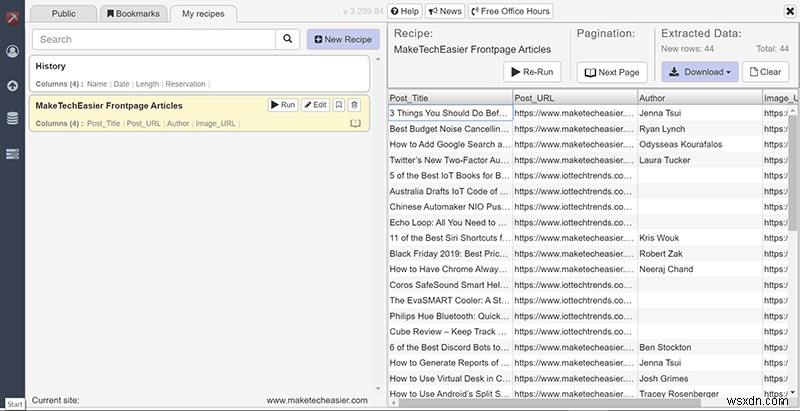
すべてが正常に動作している場合は、[次のページ]ボタンを使用して、クロールするページ数と移動速度をスクレーパーに指示できます/(速度が速すぎると、システムがボットとしてフラグを立てる可能性があります)
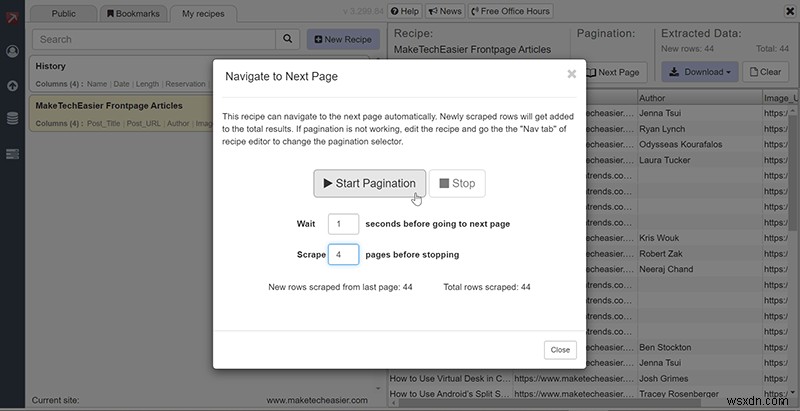
必要なデータがすべて揃ったら、ダウンロードに使用するファイル形式を選択できます。
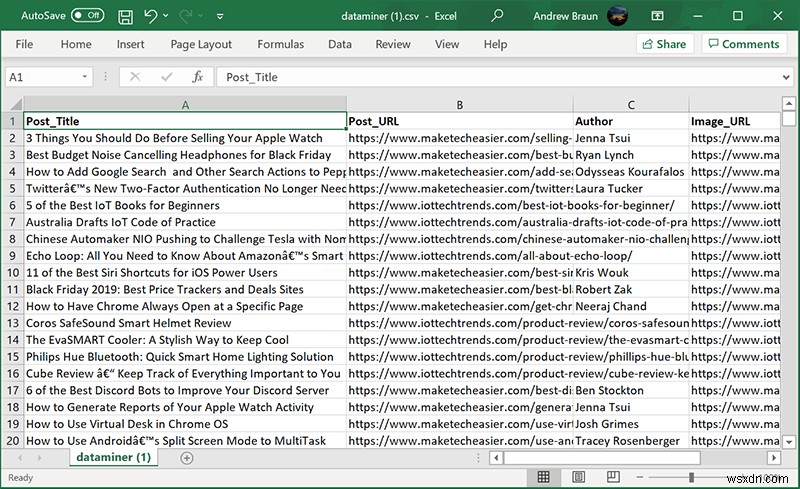
問題が発生しています。もっと簡単な方法はありますか?
Data Minerプログラムが機能しない場合は、ParseHub、Scraper、Octoparse、Import.io、VisualScraperなど、他にも多くのデータスクレイピングツールを利用できます。これらのツールの中には、より直感的なインターフェイスと自動化機能を備えているものもあります。ただし、HTMLとWebの編成方法について少なくとも少し知っておく必要があります。 Data Minerを初心者にとって特に優れているのは、クラウドソーシングされたレシピライブラリです。これは、コードとのごくわずかな遭遇さえも回避するのに役立つ可能性があります。それは、かなり寛大な無料の毎月のスクレイプパッケージと組み合わされて、ほとんどのニーズに非常に適したツールになります。
-
PDF から Excel にデータを抽出する方法 (4 つの適切な方法)
私たちの日常業務では、PDF ファイルから Excel スプレッドシートにデータを抽出することはよくあることです。手動で行う場合は、面倒で時間のかかる作業になります。ただし、PDF から Excel にデータを抽出する方法に精通している場合は、 、瞬く間に仕事をすることができます。この記事では、PDF から Excel にデータを抽出する 4 つの方法を紹介します。これらの方法に興味がある場合は、フォローしてください。 この記事を読んでいる間に、この練習用ワークブックと PDF ファイルをダウンロードして練習してください。 PDF から Excel にデータを抽出する 4 つの簡単な方法
-
XML ファイルから Excel にデータを抽出する方法 (2 つの簡単な方法)
この記事では、XML ファイルから Excel にデータを抽出する方法を学習します。 . XML 形式は、主に Web でデータを格納するために使用されます。また、システムに保存することもできます。場合によっては、ユーザーは Excel で XML ファイルからデータを抽出する必要があります。今日は 2 を表示します さまざまな方法。これらの方法を使用すると、XML ファイルから Excel にデータを簡単に抽出できます。 ここから練習用ワークブックをダウンロードできます。 XML ファイルとは XML ファイルには、さまざまなアプリケーションやシステムで読み取り可能な形式でデータを保