Upstash Kafka と MongoDB コネクタを使用した低遅延セグメンテーション プラットフォームの構築
はじめに
- セグメンテーション プラットフォームは、顧客、商品、その他の関連データを理解して分類する上で重要な役割を果たします。
- セグメンテーションでは、特定の基準に基づいて、大きなグループをより小規模で均質なサブグループに分割します。
- ここでは、パーソナライズされたマーケティング戦略、ターゲットを絞ったプロモーション、よりカスタマイズされたショッピング エクスペリエンスのための顧客のセグメンテーションなど、さまざまなドメインでのセグメンテーション プラットフォームの例をいくつか紹介します。
目次
<オル>1.要件を理解する
電子商取引における顧客セグメント向けの低遅延セグメンテーション プラットフォームを設計すると、リアルタイム処理、ユーザー エクスペリエンス、顧客行動の動的な性質に関連する特有の課題が生じます。この状況で遭遇する可能性のあるいくつかの課題を次に示します。
<オル>大規模で動的なデータセット
- E コマース プラットフォームは、顧客プロフィール、商品カタログ、取引履歴など、常に変化する大規模なデータセットを扱います。
- 低遅延を維持しながら、これらの膨大なデータセットをリアルタイムで管理および処理することは、大きな課題です。
スケーラビリティ
- さまざまなワークロードを処理するには、スケーラビリティを考慮した設計が不可欠です。レイテンシを犠牲にすることなく処理ユニットを追加してシステムを水平方向に拡張できるようにするには、慎重なアーキテクチャ計画が必要です。
非同期処理
- 非同期処理を活用すると、コンポーネントを分離し、システム全体の応答性を向上させることができます。ただし、複雑さや遅延を生じさせずに非同期通信を管理するには、慎重な設計が必要です。
データ フローとパイプライン
- 効率的なデータ フローと処理パイプラインを設計することは、低レイテンシ システムにとって非常に重要です。
- コンポーネント間のデータの転送にかかる時間を最小限に抑え、一連の処理ステップを最適化すると、全体的なレイテンシに大きな影響を与える可能性があります。
マイクロサービス アーキテクチャ
- マイクロサービス アーキテクチャを実装すると、スケーラビリティと柔軟性が向上します。ただし、レイテンシーを発生させずにマイクロサービス間のシームレスな通信を確保することは困難な場合があります。
- 効率的な API を設計し、サービス間通信を管理することが重要です。
2.基本アーキテクチャ
セグメンテーション プラットフォームは、次の 3 つの主要なサブシステムで構成されます。 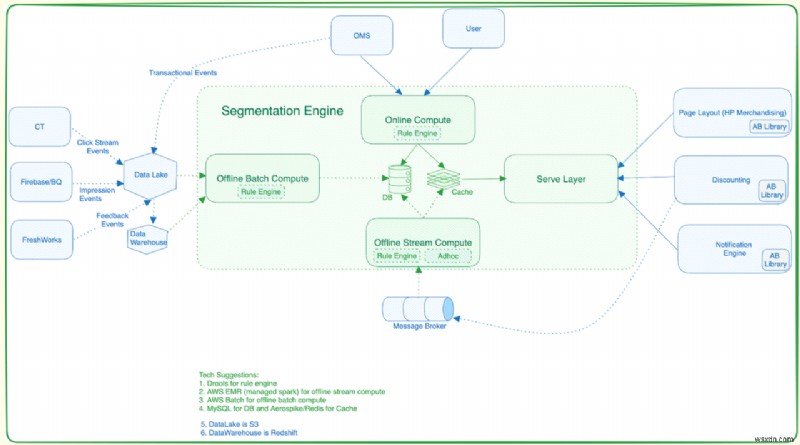
コンピューティング サービス (オフライン バッチ コンピューティング/オンライン コンピューティング):
- Spark ジョブを使用して生データからユーザー セグメントを抽出します。
- Spark ジョブは、データ レイクからデータを取得、クリーンアップ、検証します。
- 結果のデータはサービスを提供するサブシステムに送信されます。
取り込みサービス:
- 計算されたセグメントをコンピューティング サービスからセグメンテーション サービスに転送します。
- セグメント内でのユーザーの包含と除外を管理します。
セグメント サービス (サービス レイヤ):
-
ユーザー サービスまたは割引サービスの特定の要件に基づいてユーザー セグメントを提供します。
-
割引サービスはユーザー ID に基づいてクエリを実行し、利用可能な割引を計算する場合があります
ユーザー ID セグメント ID 作成日 2521セグメント X2023 年 12 月 3 日2788セグメント Y2023 年 12 月 3 日3943セグメント Z2023 年 12 月 3 日
3.建築コンポーネント
セグメンテーション プラットフォームは、次の主要コンポーネントで構成されます。 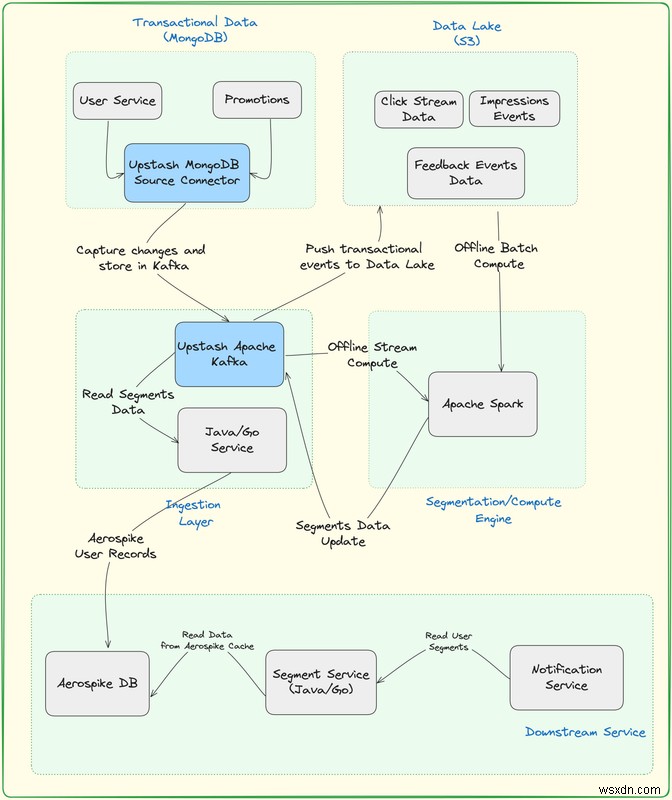
データ レイク - S3
- S3 は、データレイクとして機能するために広く採用されている多用途のオプションです。スケーラブルで耐久性のあるオブジェクト ストレージ機能により、さまざまな種類のデータを大量に効率的に保存および管理するのに適しています。
- S3 をデータレイクとして利用することで、組織はデータの保存、取得、管理のための堅牢な機能の恩恵を受けることができ、さまざまなデータ中心のアプリケーションやアーキテクチャで人気の選択肢となっています。
トランザクション データベース MongoDB
- MongoDB のドキュメント指向モデルは、複雑なデータ構造を JSON に似た形式で保存できるため、トランザクションのユースケースに有益です。この柔軟性は、時間の経過とともにデータ構造が進化する可能性があるアプリケーションに特に役立ちます。
Upstash Kafka クラスタ
- トラフィック (クリック) イベントをウェブ アプリケーションから Upstash Kafka にストリーミングし、その後の処理のためにデータ レイクに保存できます。
- Upstash Kafka は、最初のサーバーレス Kafka 製品です。リクエストごとの支払いモデルを使用すると、数百ドルを支払うことなく、フルマネージドの Kafka クラスターを構築できます。無料利用枠を使用すると、クレジット カードを入力することなく、数秒で Kafka クラスターを作成できます。 Upstash チームは、ユーザーがアプリに集中している間、可用性、メンテナンス、スケーリング、アップグレード、その他すべての面倒な作業を処理します。
Upstash MongoDB ソース コネクタ
- MongoDB ソース コネクタは、MongoDB データベースに接続し、変更やイベントをリアルタイムでキャプチャするために、Apache Kafka Connect などのデータ統合およびストリーミング プラットフォームで使用されるコンポーネントです。
- Upstash MongoDB ソース コネクタは、MongoDB から別のシステムまたはプラットフォームへのデータの移動を容易にし、シームレスなデータ統合と分析を可能にします。
Apache スパーク
- Apache Spark は、単一ノード マシンまたはクラスタ上でデータ エンジニアリング、データ サイエンス、機械学習を実行するための多言語エンジンです。
- Upstash Kafka を、Upstash がすぐに提供する Apache Spark と統合することで、ウェブ アプリケーションからトラフィック (クリック) イベントを Upstash Kafka にストリーミングし、リアルタイムで分析できるようになります。
- Apache Spark は、ユーザー セグメントの更新を処理します。これらの更新は、Aerospike データベースを更新するために伝播される前に、Upstash Kafka に書き込まれます。
4.設計上の課題
セグメンテーション エンジンの導入と使用が増加すると、システムに特定の課題が生じる可能性があります。
- 書き込み QPS のボトルネック:より多くの大きなセグメントを作成すると、1 秒あたりの書き込みクエリ数 (QPS) のボトルネックが発生し、セグメント作成の待ち時間が長くなる可能性があります。
- 低レイテンシのリクエスト:特定の通信を送信する場合、特にユーザーが特定のセグメントに属しているかどうかを判断する場合、非常に低いレイテンシを達成することが重要です。
読み取りレイテンシ
-
さらに、プラットフォームが進化し続けるにつれて、読み取りに 50 ミリ秒未満のレイテンシが必要とされても、この速度は特定のサービスやその将来のユースケースには十分ではない可能性があることが予想されます。
-
たとえば、通知サービスでは、通信を送信する前にユーザー セグメントのメンバーシップを判断するための迅速なチェックが必要になることが予想されます。通信リクエストごとに遅延が増加することは、将来的には受け入れられなくなることが予想されます。
Kafka インフラストラクチャの管理
-
Kafka インフラストラクチャを使用する場合、トランザクション ソースから毎分数百万のイベントを処理することは確かに課題となる可能性があり、このような高スループットを効果的に管理するには、さまざまな要素を慎重に検討する必要があります。
-
定期的なパフォーマンス テストと最適化は、高スループットの Kafka インフラストラクチャを維持するための鍵となります。
MongoDB 変更データ キャプチャ
-
Web アプリケーションからのイベントを集約すること、特にイベントが MongoDB などの従来のトランザクション データベースに保存されている場合、それをデータ レイクにプッシュすることには、確かにある程度の労力がかかることがあります。
-
MongoDB が提供する変更データ キャプチャ メカニズムを利用するか、カスタム ソリューションを実装してデータベース内の変更をキャプチャします。
5.提案されたソリューション
<オル>分散キャッシュ Aerospike による読み取りレイテンシの改善
-
Aerospike にはユーザーのセグメントが含まれており、ユーザー ID がユーザー セグメントにアクセスするための主キーとして機能します。
-
さらに、セグメント ID にセカンダリ インデックスを実装して、セグメント ユーザーの取得を合理化し、セグメント ユーザーを個別に保存する必要をなくすこともできます。
-
さらに、この設計はレイテンシ要件を満たすことを目的としており、キャッシュとして機能する可能性があり、潜在的に Redis の必要性を置き換えることができます。
-
現在の Aerospike を Upstash Redis に置き換えるには、セグメント ユーザーとユーザー セグメントという 2 つのデータ セットを管理する必要があります。
Kafka インフラストラクチャを管理するためのサーバーレス Upstash Kafka
-
Upstash Kafka を使用すると、完全にマネージドされたサービスが得られます。これは、Kafka クラスタの実行に伴うサーバーのプロビジョニング、スケーリング、メンテナンスなどの技術的なタスクを Upstash がすべて処理することを意味します。
-
これにより、インフラストラクチャのセットアップ、すべてが正しく動作すること、長期にわたるメンテナンスなどについて心配する必要がなくなります。
-
これにより、独自の要件と目的のために Kafka を活用することに集中できます。インフラストラクチャの管理の負担がなくなり、特に急速に進化する開発環境において、アプリケーションの全体的な品質の向上にエネルギーを注ぐことができます。
-
価格はゼロにスケールされます: 真のサーバーレス製品は、積極的に使用していない場合には料金を請求する必要はありません。リクエストごとの価格は当社の最も優れた機能です。あなたは、初日からこの価格モデルに適合するように製品とインフラストラクチャを設計してきました。これには固定費を最小限に抑える必要がありますが、カフカのような野獣にとってこれは非常に困難です。
-
ユーザーの操作負担なし: ユーザーは Kafka トピックを作成し、それを使用し始めます。高可用性、拡張性、アップグレード、バックアップ…それはすべて私たちの責任です。
-
コネクションレス: サーバーレス関数は状態を保持しません。したがって、ステートレス接続を使用してデータにアクセスできる必要があります。当社の Kafka 製品は Kafka TCP プロトコルをサポートしているため、すべての Kafka クライアントが Upstash で動作します。また、AWS Lambda や Cloudflare Workers などのコネクションレス環境を有効にする組み込み REST API もあります。
Upstash MongoDB ソース コネクタを使用した MongoDB CDC
-
Kafka Connect は、コードを 1 行も記述することなく、Apache Kafka と他のシステムの間でデータをストリーミングするためのツールです。 Kafka シンク コネクタを介して、データを他のストレージにエクスポートできます。 Kafka ソース コネクタを介して、他のシステムから Kafka トピックにデータをプルできます。
-
Kafka コネクタは自己ホストすることができますが、追加のプロセス/マシンをセットアップして維持する必要があります。 Upstash は、Kafka クラスター用のホストされたバージョンのコネクタを提供します。これにより、追加のシステムを維持する負担が軽減され、クラスターに近いためパフォーマンスも向上します。
6.終わりのメモ
このブログ投稿では、Upstash が提供するテクノロジーを活用した低遅延セグメンテーション プラットフォームの設計原則について説明します。このインフラストラクチャはシームレスに拡張できるように設計されており、数百万のユーザーに対応し、データ レイクに保存されたテラバイト単位のデータを処理できます。
-
Next.jsアプリケーションのフィードバックウィジェット
ユーザーのフィードバックは、製品の決定を導くために重要です。ユーザーからのフィードバックを得るのに役立つウィジェットを作成しました。これは、Next.jsAPIをバックエンドとして呼び出すReactコンポーネントです。バックエンドAPIは、フィードバックデータをUpstashRedisデータベースに送信するだけです。また、提出されたデータはUpstashConsoleIntegrationsページで表示および管理できます コンポーネントをNext.jsページに追加すると、右下隅にアイコンが表示されます。クリックすると、フィードバックフォームが表示されます。デモをチェックして、どのように機能す
-
DBaaSプロバイダーを選択する際に考慮すべき6つの主要な機能
クラウドベースのデータベース管理システム(DBMS)を成功させるには、適切なサービスとしてのデータベース(DBaaS)環境を選択することが重要です。そして、これはますます重要な決定です。最近のResearch and Marketsのレポートによると、世界のクラウドデータベースとDBaaS市場は、2020年の推定120億ドルから2025年には248億ドルに成長すると予想されています。 その成長を推進しているのは何ですか?最小のレイテンシでクエリを処理するという需要はますます高まっています。 DBaaSモデルは、クラウドに管理対象データベース資産を迅速に展開するための魅力的なオプションです