Upstash を使用して強力な RAG チャットボットを作成する:ステップバイステップ ガイド
この投稿では、Upstash Vector、Upstash Redis、Hugging Face Inference API、複製 LLAMA-2-70B チャット モデル、および Vercel を使用して、オープンソースのカスタム コンテンツ RAG チャットボットを構築した方法について説明します。 Upstash Vector は、ベクターの挿入とクエリ、各ユーザー メッセージの関連コンテキストの動的作成または更新に役立ち、Upstash Redis はチャットボットの会話の保存に役立ちました。
前提条件
次のものが必要です。
- Node.js 18 以降
- Upstash アカウント
- ハグフェイス アカウント
- レプリケートアカウント
- Vercel アカウント
技術スタック
Upstash Redis のセットアップ
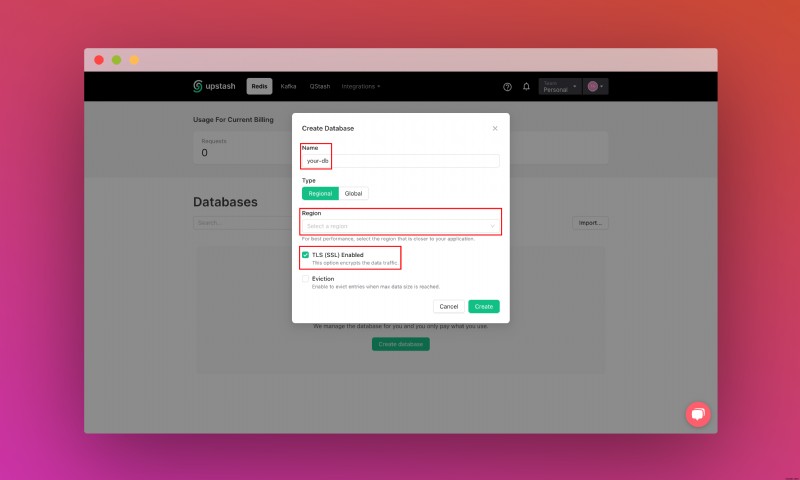
Upstash アカウントを作成してログインしたら、[Redis] タブに移動してデータベースを作成します。
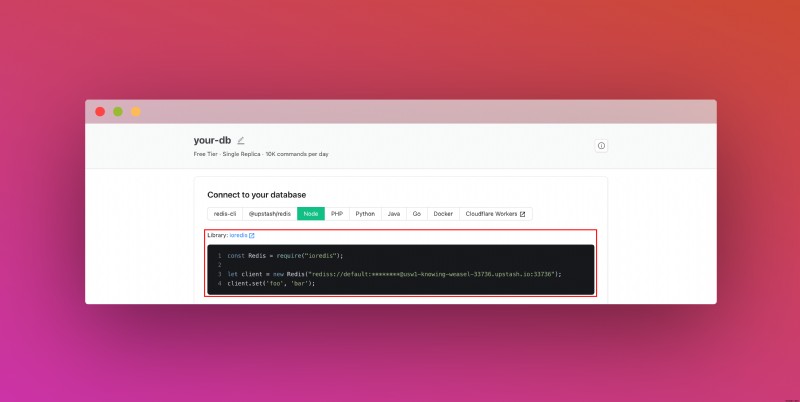
データベースを作成したら、「詳細」タブに移動します。 「データベースに接続する」セクションが見つかるまで下にスクロールします。コンテンツをコピーし、安全な場所に保存します。
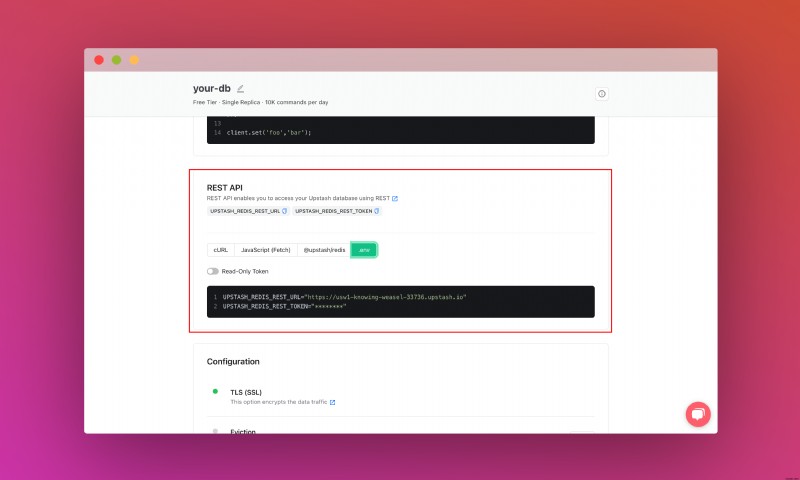
また、REST API セクションが見つかるまで下にスクロールし、.env ボタンを選択します。コンテンツをコピーし、安全な場所に保存します。
Upstash Vector のセットアップ
Upstash アカウントを作成してログインしたら、[Vector] タブに移動してインデックスを作成します。
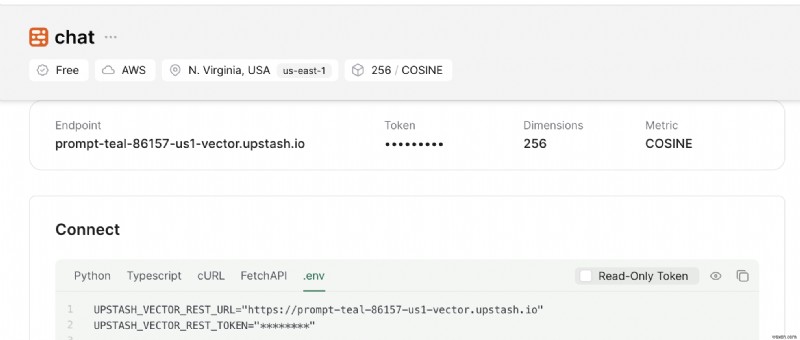
また、接続が見つかるまで下にスクロールします。 セクションを開き、.env を選択します。 ボタン。コンテンツをコピーし、安全な場所に保存します。
プロジェクトのセットアップ
セットアップするには、アプリ リポジトリのクローンを作成し、このチュートリアルに従ってそこに含まれる内容をすべて学習するだけです。プロジェクトをフォークするには、次を実行します。
git clone https://github.com/rishi-raj-jain/custom-rag-chatbot-upstash-vector
cd custom-rag-chatbot-upstash-vector
pnpm install
リポジトリのクローンを作成したら、.env を作成します。 ファイル。上記のセクションで保存したアイテムを追加します。
次のようになります:
# .env
# Obtained from the steps as above
# Upstash Redis URL and Token
UPSTASH_REDIS_REST_URL="https://....upstash.io"
UPSTASH_REDIS_REST_TOKEN="..."
# Upstash Vector URL and Token
UPSTASH_VECTOR_REST_URL="https://...-vector.upstash.io"
UPSTASH_VECTOR_REST_TOKEN="..."
# Replicate API Key
REPLICATE_API_TOKEN="r8_..."
# Hugging Face Inference API Key
HUGGINGFACEHUB_API_KEY="hf_..."これらの手順を完了すると、次のコマンドを使用してローカル環境を起動できるようになります。
pnpm devリポジトリの構造
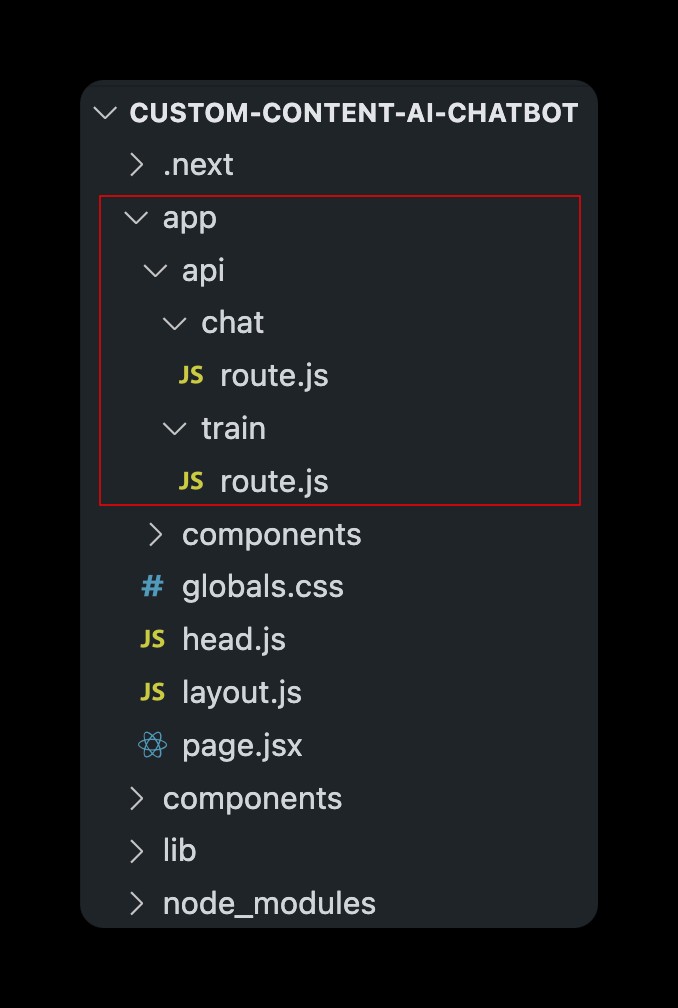
これはプロジェクトのメイン フォルダー構造です。この投稿では、カスタム コンテキストでトレーニングされた AI とチャットするための API ルートの作成と、upsert によるコンテキストの更新について詳しく説明するファイルを赤でマークしました。 ベクトルを既存のインデックスに -ing します。
Next.js App Router でチャット ルートを設定する
このセクションでは、ルート app/api/chat/route.js を設定する方法について説明します。 サーバーレス データベース内の会話を同期し、文字列の埋め込みを動的に作成し、特定のインデックスから関連するベクトルをクエリしてコンテキストを作成し、LLAMA-2-70B チャット モデルを使用して関連する予測をリクエストします。話を単純化するために、これをさらに複数の部分に分割します。
会話の保存
Upstash Redis で行われた会話をキャッシュするには、Redis リストを利用します。応答するメッセージがユーザーから届くとすぐに、チャットボットからの応答を条件付きで (以前に) リストにプッシュします。次に、ユーザーからの最新のメッセージもリストにプッシュして保存し、それに応答します。
// File: app/api/chat/route.js
import { Redis } from '@upstash/redis'
// Instantiate the Upstash Redis
const upstashRedis = new Redis({
url: process.env.UPSTASH_REDIS_REST_URL,
token: process.env.UPSTASH_REDIS_REST_TOKEN,
})
export async function POST(req) {
try {
// the whole chat as array of messages
const { messages } = await req.json()
// assuming user - assistant chat
// add assitant's response to the chat history
if (messages.length > 1) {
await upstashRedis.lpush('unique_conversation_id', JSON.stringify(messages[messages.length - 2]))
}
// add user's request to the chat history
await upstashRedis.lpush('unique_conversation_id', JSON.stringify(messages[messages.length - 1]))
// Proceed to create a response
}最新メッセージの埋め込みを作成
与えられたすべてのコンテキスト (つまり、ユーザーが指定したカスタム コンテンツ) でユーザーの最新のメッセージに効果的に返信するために、既存のインデックスから関連するコンテキスト (別名類似ベクトル) を取得するのに役立つ埋め込みを作成します。 LangChain で Hugging Face Inference API を使用して、エッジでの API 呼び出しだけで埋め込みを作成し、Upstash Vector Index (ここでは 256) をスピンアップしながら、取得したベクトルを構成した長さにスライスします。 ).
// File: app/api/chat/route.js
import { HuggingFaceInferenceEmbeddings } from '@langchain/community/embeddings/hf'
// Instantiate the Hugging Face Inference API
const embeddings = new HuggingFaceInferenceEmbeddings()
export async function POST(req) {
try {
// ...
// get the latest question stored in the last message of the chat array
const userMessages = messages.filter((i) => i.role === 'user')
const lastMessage = userMessages[userMessages.length - 1].content
// generate embeddings of the latest question
const queryVector = (await embeddings.embedQuery(lastMessage)).slice(0, 256)
// Proceed to create a response
}最新のメッセージに基づいて関連するコンテキスト ベクトルを取得する
ユーザーが指定したすべてのコンテキストをメッセージごとに動的に取得するのは、コストのかかる操作です。ユーザーの最新メッセージに関連するコンテキストのみを使用し、それをシステム プロンプトとして LLAMA-2-70B チャット モデルに渡したいと考えています。関連するコンテキストのみを取得するために、既存のベクトルのセットをクエリして、メタデータを含む最も関連性の高い 2 つのベクトルを取得し、信頼スコアが 70% を超える結果をフィルタリングします。
// File: app/api/chat/route.js
import { Index } from '@upstash/vector'
// Instantiate the Upstash Vector Index
const upstashVectorIndex = new Index()
export async function POST(req) {
try {
// ...
// query the relevant vectors from the embedding vector
const queryResult = await upstashVectorIndex.query({
vector: queryVector,
// get the top 2 relevant results
topK: 2,
// do not include the whole set of embeddings in the response
includeVectors: false,
// include the meta data so that can get the description out of the index
includeMetadata: true,
})
// console.log('The query result came in', queryResult.length)
// using the resulting set of relevant vectors
// filter the one that have score of greater than 70% match
// and get the description we stored while training
const queryPrompt = queryResult
.filter((match) => match.score && match.score > 0.7)
.map((match) => match.metadata.description)
.join('\n')
// console.log('The query prompt is', queryPrompt)
// Proceed to create a response
}予測のコンテキストを含む LLAMA-2-70B チャット モデルのプロンプト
関連するコンテキストを文字列として取得したので、最後のステップは、llama-2-70B チャット モデルにユーザーの最新のメッセージに応答するよう要求することです。 Vercel AI SDK の experimental_buildLlama2Prompt を使用します。 このメソッドは、llama-2-70B チャット モデルに適したプロンプト形式の作成を処理します。
// File: app/api/chat/route.js
import Replicate from 'replicate'
import { experimental_buildLlama2Prompt } from 'ai/prompts'
import { ReplicateStream, StreamingTextResponse } from 'ai'
// Instantiate the Replicate API
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
})
export async function POST(req) {
try {
// ...
const response = await replicate.predictions.create({
// You must enable streaming.
stream: true,
// The model must support streaming. See https://replicate.com/docs/streaming
// This is the model ID for Llama 2 70b Chat
version: '2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1',
// Format the message list into the format expected by Llama 2
// @see https://github.com/vercel/ai/blob/99cf16edf0a09405d15d3867f997c96a8da869c6/packages/core/prompts/huggingface.ts#L53C1-L78C2
input: {
prompt: experimental_buildLlama2Prompt([
{
// create a system content message to be added as
// the llama2prompt generator will supply it as the context with the API
role: 'system',
content: queryPrompt.substring(0, Math.min(queryPrompt.length, 2000)),
},
// also, pass the whole conversation!
...messages,
]),
},
})
// stream the result to the frontend
const stream = await ReplicateStream(response)
return new StreamingTextResponse(stream)
}Next.js App Router で電車のルートを設定する
このセクションでは、ルート app/api/train/route.js の設定方法について説明します。 リクエスト オブジェクトで渡された文字列の埋め込みを動的に作成し、それらを Upstash Vector Index に追加します。話を単純化するために、これをさらに複数の部分に分割します。
文字列の埋め込みを作成する
既存のインデックスの設定または更新に役立つ文字列の埋め込みを作成します。そうすることで、チャットボットの今後の応答のコンテキストを最新の状態に保つことができます。 LangChain で Hugging Face Inference API を使用し、エッジでの API 呼び出しだけでエンベディングを作成します。
// File: app/api/train/route.js
import { HuggingFaceInferenceEmbeddings } from '@langchain/community/embeddings/hf'
// Instantiate the Hugging Face Inference API
const embeddings = new HuggingFaceInferenceEmbeddings()
export async function POST(req) {
try {
// a default set of messages to create vector embeddings on
let messagesToVectorize = [
'Rishi is pretty much active on Twitter nowadays.',
'Rishi loves writing for Upstash',
"Rishi's recent article on building chatbot using Upstash went viral",
'Rishi is enjoying building launchfa.st.',
]
// if the POST request is of type application/json
if (req.headers.get('Content-Type') === 'application/json') {
// and if the request contains array of messages to train on
const { messages } = await req.json()
if (typeof messages !== 'string' && messages.length > 0) {
messagesToVectorize = messages
}
}
// Call the Hugging Face Inference API to get emebeddings on the messages
const generatedEmbeddings = await Promise.all(messagesToVectorize.map((i) => embeddings.embedQuery(i)))
// ...
}関連性検索のためにベクトルを保存する
生成されたエンベディングをベクトル インデックスに追加するには、Upstash ベクトル インデックス (ここでは 256) をスピンアップするときに、取得したベクトルを構成した長さにスライスします。 ) upsert を使用します。 メタデータ、つまり文字列自体を含む埋め込みを挿入するメソッド。これにより、同様のベクトルが検索されたときに文字列を取得できるため、LLAMA-2-70B チャット モデルを呼び出して応答を生成するときに会話のナレッジ ベースを設定できます。
// File: app/api/train/route.js
import { Index } from '@upstash/vector'
// Instantiate the Upstash Vector Index
const upstashVectorIndex = new Index()
export async function POST(req) {
try {
// ...
// Slice the vector into lengths of upto 256
await Promise.all(
generatedEmbeddings
.map((i) => i.slice(0, 256))
.map((vector, index) =>
// Upsert the vector with description to be further as the context to upcoming questions
upstashVectorIndex.upsert({
vector,
id: index.toString(),
metadata: { description: messagesToVectorize[index] },
}),
),
)
// Once done, return with a successful 200 response
return new Response(JSON.stringify({ code: 1 }), { status: 200, headers: { 'Content-Type': 'application/json' } })
}とても勉強になりました!これですべて完了です ✨
Vercel に展開
これで、リポジトリを Vercel にデプロイする準備が整いました。次の手順を使用してデプロイします 👇🏻
- まず、アプリのコードを含む GitHub リポジトリを作成します。
- 次に、Vercel ダッシュボードに移動し、新しいプロジェクトを作成します。 .
- 新しいプロジェクトを、作成したばかりの GitHub リポジトリにリンクします。
- 設定内 、
Environment Variablesを更新します。 ローカルの.envにあるものと一致するようにする ファイル。 - 展開してください! 🚀
詳細情報
さらに詳しい洞察については、この投稿で引用されている参考文献を参照してください。
結論
結論として、このプロジェクトは、必要に応じて拡張できるサービス (Upstash など) を使用しながら、エンベディングの作成方法、既存のベクトルのセットからクエリを実行する方法、コンテキストを使用して LLAMA-2-70B チャット モデルを使用して関連する予測を作成する方法を学ぶ貴重な経験を提供しました。
-
QStash:サーバーレス メッセージ キューおよびスケジューラ
QStash を発表できることを誇りに思い、興奮しています 🔥🔥🔥 正式には、QStash はサーバーレス ランタイム用に設計されたメッセージ キューおよびタスク スケジューラです。非公式には、QStash はサーバーレス機能の接着剤です。 サーバーレスは単純なタスクにのみ適しているという認識がありました。もうない。人々はサーバーレス スタックを使用して強力なシステムを構築します。強力なシステムは複数のコンポーネントで構成されています。これらのコンポーネント間の通信はエンジニアリング上の大きな問題です。この問題に対する優れた解決策はすでに存在します。しかし、既存のソリューションはサー
-
ソートされたセットの要素のランクを取得する方法– Redis ZRANK | ZREVRANK
このチュートリアルでは、redis ZRANKコマンドとZREVRANKコマンドを使用して、redisデータストアのキーに保存されている並べ替えられた設定値の要素のランクを取得する方法について学習します。 ZRANKコマンド このコマンドは、指定されたキーに格納されているソートされた設定値の要素のランクを返すために使用されます。並べ替えられたセットの要素はスコアの昇順であり、スコアが等しい要素には辞書式順序の昇順が使用されます。ランクはゼロベースです。つまり、スコアが最も低いメンバーのランクは0です。 ソートされたセットに要素が存在しない場合、またはキーが存在しない場合は、Nilが返され