中断せずにRedisSQLクエリを実行する方法
RedisSQLクエリの実行は難しいことではありません。数年前、小売企業でデータウェアハウジングソリューションを管理している友人と話をしたときに、私は実際にこの点を指摘しました。彼が直面している問題を説明した後、Redisのクエリについて話し始めました。
「データウェアハウジングソリューションには問題点があります。データを記録し、リアルタイムで分析操作を実行する必要があるユースケースがあります。ただし、結果が得られるまでに数分かかる場合があります。 Redisはここで役に立ちますか? SQLベースのソリューションを一度にリッピングして置き換えることはできないことに注意してください。一度に一歩しか踏み出せません。 」
さて、あなたが私の友人と同じ状況にあるなら、私たちはあなたに良い知らせがあります。 Redisクエリを実行し、なしでアーキテクチャにRedisを導入する方法はいくつかあります。 現在のSQLベースのソリューションを混乱させます。
これを行う方法を見てみましょう。ただし、先に進む前に、SQLを使用してRedisのデータをクエリできる独自のアプリを作成したRedisハッカソンの出場者がいます。
下のビデオをご覧ください。
テーブルをRedisデータ構造として改造する
テーブルをRedisデータ構造にマッピングするのは非常に簡単です。従うべき最も有用なデータ構造は次のとおりです。
- ハッシュ
- ソート済みセット
- 設定
これを行う1つの方法は、すべての行を、テーブルの主キーに基づくキーを含むハッシュとして保存し、そのキーをセットまたはソートされたセットに保存することです。
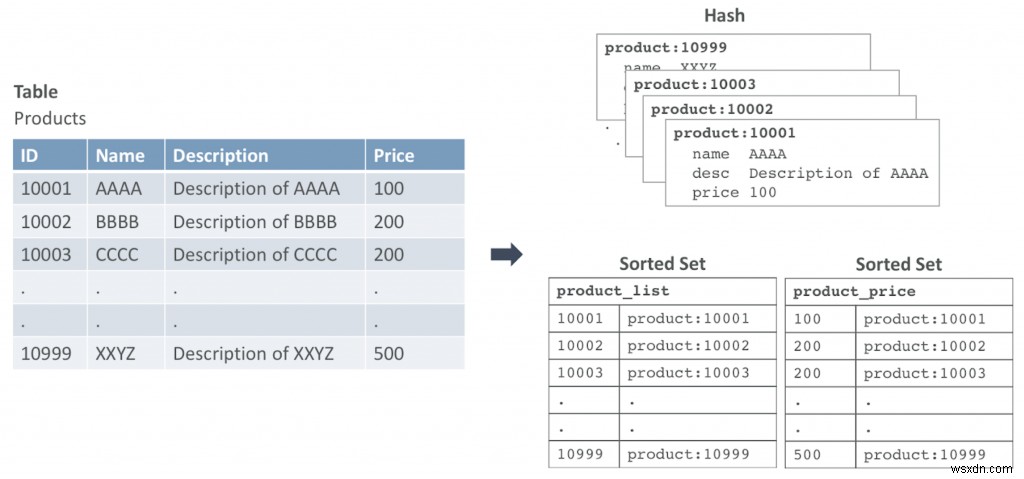
図1は、テーブルをRedisデータ構造にマップする方法の例を示しています。この例では、Productsというテーブルがあります。すべての行はハッシュデータ構造にマップされます。
プライマリIDが10001の行は、キーがproduct:10001のハッシュとして入力されます。この例では、2つのソートされたセットがあります。1つは主キーによってデータセットを反復処理し、2つ目は価格に基づいてクエリを実行します。
このオプションでは、SQLコマンドの代わりにRedisクエリを使用するようにコードを変更する必要があります。以下は、SQLとRedisの同等のコマンドの例です。
A。データを挿入
SQL: insert into Products (id, name, description, price) values = (10200, “ZXYW”,“Description for ZXYW”, 300);
Redis: MULTI HMSET product:10200 name ZXYW desc “Description for ZXYW” price 300 ZADD product_list 10200 product:10200 ZADD product_price 300 product:10200 EXEC
B。製品IDによるクエリ
SQL: select * from Products where id = 10200
Redis: HGETALL product:10200
C。価格でクエリ
SQL: select * from Product where price < 300
Redis: ZRANGEBYSCORE product_price 0 300
これにより、次のキーが返されます:product:10001、product:10002、product:10003。次に、キーごとにHGETALLを実行します。
HGETALL product:10001 HGETALL product:10002 HGETALL product:10003
DataFramesを使用して、テーブルをRedisデータ構造に自動的にマッピングします
これで、ソリューションでSQLインターフェイスを維持し、基盤となるデータストアのみをRedisに変更して高速化する場合は、ApacheSparkとSpark-Redisライブラリを使用して行うことができます。
Spark-Redisライブラリを使用すると、DataFrameAPIを使用してRedisデータを保存およびアクセスできます。つまり、SQLコマンドを使用してデータを挿入、更新、クエリできますが、データは内部でRedisデータ構造にマッピングされます。
まず、spark-redisをダウンロードし、ライブラリをビルドしてjarファイルを取得する必要があります。たとえば、spark-redis 2.3.1では、spark-redis-2.3.1-SNAPSHOT-jar-with-dependencies.jarを取得します。
次に、Redisインスタンスが実行されていることを確認する必要があります。この例では、ローカルホストとデフォルトのポート6379でRedisを実行します。
ApacheSparkエンジンでクエリを実行することもできます。これを行う方法の例を次に示します。
$ spark-shell --jars spark-redis-2.3.1-SNAPSHOT-jar-with-dependencies.jar
scala> import org.apache.spark.sql.SparkSession
scala> val spark = SparkSession
.builder()
.appName("redis-sql")
.master("local[*]")
.config("spark.redis.host","localhost")
.config("spark.redis.port","6379").getOrCreate()
scala> import spark.sql
scala> import spark.implicits._
scala> sql("create table if not exists products(id string, name string, description string, price int) using org.apache.spark.sql.redis options (table 'product')")
scala> sql("insert into products values = ('10200','ZXYW','Description of ZXYW', 300)")
scala> val results = sql("select * from products")
scala> results.show()
+-----+----+-------------------+-----+
| id|name| description|price|
+-----+----+-------------------+-----+
|10200|ZXYW|Description of ZXYW| 300|
+-----+----+-------------------+-----+ これで、Redisクライアントを使用して、Redisデータ構造としてこのデータにアクセスすることもできます。
127.0.0.1:6379> keys product* 1) "product:2e3f8611dbe94a588706a2aaea547caa"
より効果的なアプローチは、データをナビゲートするときにページ付けできるため、スキャンコマンドを使用することです。
127.0.0.1:6379> scan 0 match product* 1) "3" 2) 1) "product:2e3f8611dbe94a588706a2aaea547caa" 127.0.0.1:6379> hgetall product:2e3f8611dbe94a588706a2aaea547caa 1) "name" 2) "ZXYW" 3) "price" 4) "300" 5) "description" 6) "Description of ZXYW" 7) "id" 8) "10200"
これで、RedisSQLクエリを中断することなく実行できる2つの簡単な方法ができました。さらに一歩進んで、SQLServerにRedisが必要な理由を確認することをお勧めします。 新しいホワイトペーパーで。
ただし、Redisを使用したリアルタイムデータに関しては、これはリアルタイムエクスペリエンスを提供するために使用できる多くの方法の1つにすぎません。
Redisがリアルタイムのデータ送信を保証する方法を知りたい場合は、必ずお問い合わせください。
-
データを失うことなくMBRをGPTに変換する方法
PCの使用年数と仕様に応じて、マスターブートレコード(MBR)を使用します。 またはGUIDパーティションテーブル(GPT)。 ドライブタイプを新しく改良された形式(GPT)に移行する場合は、データを失うことなく移行できることを知って喜んでいただけることでしょう。 MBRからGPTに切り替えたい理由はたくさんあります。ただし、ディスクをMBRからGPTに移行し、レガシーBIOSから新しく改良されたUEFIに変換できる最も一般的な方法のいくつかは、実際にはディスク上に存在するすべてのデータを消去することになります。 MBR VS GPT MBRからGPTに切り替えることを決定する前
-
3人のRedisコミュニティメンバーがRedisを再発見した方法
私たちは、RedisコミュニティがRedisを使用して革新的なアプリケーションを強化する創造的で強力な方法から常に刺激を受けています。 RediscoverMagazineの初版で 、データの課題を克服するためにRedisを再発見した3人のコミュニティメンバーを紹介しました。 さて、Carlos Justiniano、Matthew Goos、Dan Pipe-Mazoについてもう少し詳しく知り、バイオテクノロジー、メドテック、ロボット工学でそれぞれRedisをどのように使用しているかを学ぶチャンスです。 RediscoverMagazineの「MeettheRedisStars」をご