「インピーダンス不一致テスト」:データプラットフォームは単純ですか、それとも複雑ですか?
「シンプルさは究極の洗練さです」 —レオナルドダヴィンチ
「ほとんどの情報は無関係であり、ほとんどの労力が無駄になりますが、無視すべきことを知っているのは専門家だけです。 」—ジェームズ・クリア、原子の習慣
さまざまなシステムを備えた豪華なデータパイプラインがあります。表面的には非常に洗練されているように見えますが、実際には内部の複雑な混乱です。さまざまな部品を接続するために多くの配管作業が必要になる場合があり、継続的な監視が必要になる場合があります。また、実行、デバッグ、および管理するために独自の専門知識を持つ大規模なチームが必要になる場合があります。言うまでもなく、使用するシステムが多いほど、データを複製する場所が増え、データが同期しなくなったり古くなったりする可能性が高くなります。さらに、これらのサブシステムはそれぞれ異なる企業によって独立して開発されているため、それらのアップグレードまたはバグ修正により、パイプラインとデータレイヤーが破損する可能性があります。
注意しないと、下の3分間のビデオに示されているように、次のような状況になる可能性があります。先に進む前にご覧になることを強くお勧めします。

複雑さは、各システムが表面上は単純に見えるかもしれませんが、実際には次の変数をパイプラインに持ち込み、非常に複雑になる可能性があるために発生します。
- プロトコル-システムはどのようにデータを転送しますか? (HTTP、TCP、REST、GraphQL、FTP、JDBC)
- データ形式-システムはどの形式をサポートしていますか? (バイナリ、CSV、JSON、Avro)
- データスキーマと進化—データはどのように保存されますか? (表、ストリーム、グラフ、ドキュメント)
- SDKとAPI-システムは必要なSDKとAPIを提供していますか?
- ACIDおよびBASE-ACIDまたはBASEの一貫性を提供しますか?
- 移行-システムは、すべてのデータをシステムに移行したり、システムから移行したりする簡単な方法を提供しますか?
- 耐久性—システムの耐久性についてどのような保証がありますか?
- 柔軟性-システムの可用性に関してどのような保証がありますか? (99.9%、99.999%)
- スケーラビリティ-どのようにスケーリングしますか?
- セキュリティ-システムはどの程度安全ですか?
- パフォーマンス-システムによるデータ処理の速度はどれくらいですか?
- ホスティングオプション-ホスティングかオンプレミスのみか、それとも組み合わせか?
- クラウド-クラウド、リージョンなどで機能しますか?
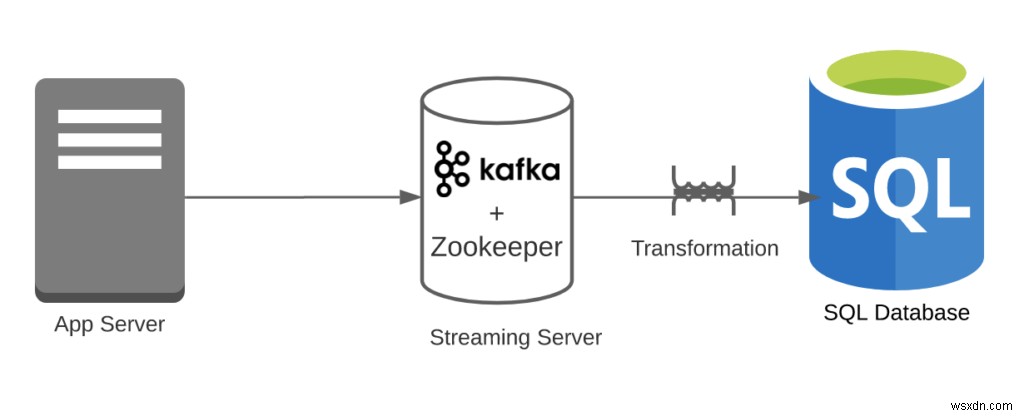
- 追加のシステム—追加のシステムが必要ですか? (例:KafkaのZookeeper)
データ形式、スキーマ、プロトコルなどの変数は、「変換オーバーヘッド」と呼ばれるものになります。パフォーマンス、耐久性、スケーラビリティなどの他の変数は、「パイプラインオーバーヘッド」と呼ばれるものになります。まとめると、これらの分類は「インピーダンスの不一致」と呼ばれるものに寄与します。それを測定できれば、複雑さを計算し、それを使用してシステムを単純化できます。これについては後ほど説明します。
さて、あなたのシステムは複雑に見えるかもしれませんが、実際にはあなたのニーズにとって最も単純なシステムであると主張するかもしれません。しかし、どうすればそれを証明できますか?
言い換えれば、データレイヤーが本当に単純なのか複雑なのかを実際にどのように測定して判断するのでしょうか。次に、機能を追加してもシステムがシンプルなままであるかどうかをどのように見積もることができますか?つまり、ロードマップに機能を追加する場合、システムも追加する必要がありますか?
そこで「インピーダンス不整合テスト」が登場します。しかし、最初にインピーダンス不整合とは何かを調べてから、テスト自体について説明します。
インピーダンスミスマッチとは何ですか?
この用語は、電気インピーダンスの不一致を説明するために電気工学に由来し、エネルギーがポイントAからポイントBに転送されるときにエネルギーが失われます。
簡単に言えば、それはあなたが持っているものがあなたが必要としているものと一致しないことを意味します。それを使用するには、現在持っているものを取得し、必要なものに変換してから使用します。したがって、不一致と、不一致の修正に関連するオーバーヘッドがあります。
私たちの場合、あなたは何らかの形または量のデータを持っており、それを使用する前にそれを変換する必要があります。変換は複数回発生する可能性があり、その間に複数のシステムを使用することもあります。
データベースの世界では、インピーダンスの不一致は2つの理由で発生します。
- 変換オーバーヘッド:システムがデータを処理または保存する方法は、データが実際にどのように見えるか、またはデータについてどのように考えるかとは異なります。例:サーバーでは、コレクション、ストリーム、リスト、セット、配列など、多数のデータ構造にデータを格納する柔軟性があります。データを自然にモデル化するのに役立ちます。ただし、これらのデータを保存するには、このデータをRDBMSまたはJSONドキュメントストアのテーブルにマップする必要があります。次に、データを読み取るために反対の操作を行います。オブジェクト指向言語モデルとリレーショナルテーブルモデルの間の特定の不一致は、「オブジェクト-リレーショナルインピーダンス不一致」として知られていることに注意してください。
- パイプラインのオーバーヘッド:サーバーで処理するデータの量とタイプは、データベースが処理できるデータの量とは異なります。たとえば、モバイルデバイスからの何百万ものイベントを処理している場合、通常のRDBMSまたはドキュメントストアはそれを保存できないか、それらのイベントを簡単に集計または計算するためのAPIを提供できない可能性があります。そのため、KafkaやRedis Streamsなどの特別なストリーム処理システムが必要です。また、それを保存するためのデータウェアハウスも必要です。
インピーダンス不整合テスト
テストの目的は、プラットフォーム全体の複雑さを測定し、将来機能を追加するにつれて複雑さが増加するか縮小するかを測定することです。
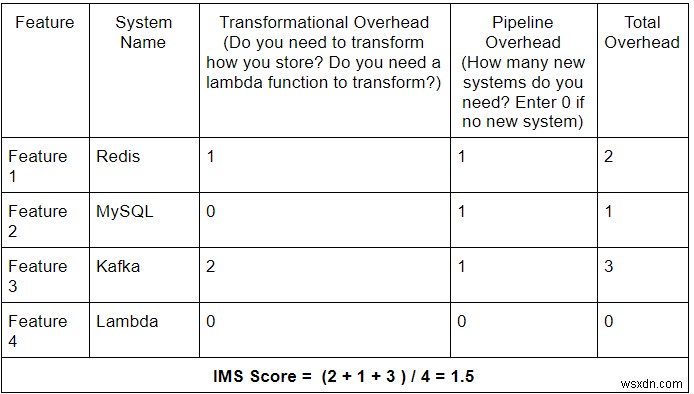
テストの仕組みは、「インピーダンス不一致スコア」(IMS)を使用して、「トランスフォーメーショナルオーバーヘッド」と「パイプラインオーバーヘッド」を単純に計算することです。これにより、システムが他のシステムと比較してすでに複雑であるかどうか、また、機能を追加するにつれてその複雑さが時間の経過とともに増大するかどうかがわかります。
IMSを計算する式は次のとおりです。

この式は、両方のタイプのオーバーヘッドを単純に追加してから、それらを機能の数で除算します。このようにして、オーバーヘッド/機能の合計(つまり、複雑さのスコア)を取得します。
これをよりよく理解するために、4つの異なる単純なデータパイプラインを比較して、それらのスコアを計算してみましょう。次に、2つのフェーズでシンプルなアプリを構築していると想像してみましょう。これにより、時間の経過とともに機能を追加するにつれて、IMSスコアがどのように変化するかを確認できます。
フェーズ1:リアルタイムダッシュボードの構築
モバイルデバイスから何百万ものボタンクリックイベントを受信していて、ドロップまたはスパイクがある場合はアラートが必要だとします。さらに、このすべてをより大きなアプリケーションの機能と見なしています。
ケース1:RDBMSを使用してこれらのイベントを保存したとしましょう。ただし、テーブルが収まらない場合があります。

- 変換オーバーヘッド=1
- イベントストリームをテーブルに変換する必要があります。
- パイプラインオーバーヘッド=1
- パイプラインに単一のDBがあります。
- 機能の数=1
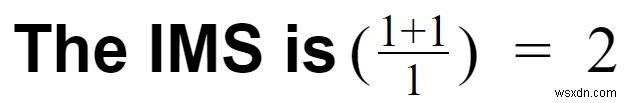
ケース2:Kafkaを使用してこれらのイベントを処理し、RDBMSに保存したとします。
- 変換オーバーヘッド=1
- Kafkaはクリックストリームを簡単に処理できます。ただし、KafkaからRDBMSへの移行はオーバーヘッドです。
- パイプラインオーバーヘッド=2
- 2つのシステム(RDBMSとKafka)があります。 Zookeeperを無視していることに注意してください。
- 機能の数=1
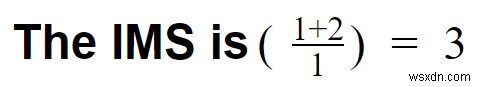
ケース3:Kafkaを使用してこれらのイベントを処理し、KsqlDBに保存したとします。
- 変換オーバーヘッド=0
- Kafkaはクリックストリームを簡単に処理できます
- パイプラインオーバーヘッド=1
- システムは1つだけです(Kafka + KSqlDB)。 Zookeeperを無視していることに注意してください。
- 機能の数=1
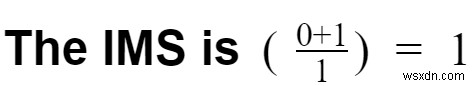
ケース4:Redis Streamsを使用してこれらのイベントを処理し、RedisTimeseriesに保存したとします(どちらもRedisの一部であり、Redisとネイティブに連携します)。

- 変換オーバーヘッド=0
- RedisStreamsはクリックストリームを簡単に処理できます
- パイプラインオーバーヘッド=1
- システムは1つだけです(Redis Streams + RedisTimeSeries)
- 機能の数=1
フェーズ1後の結論:
この例の4つのシステムを比較したところ、IMSが1の場合、「ケース3」または「ケース4」が最も単純であることがわかりました。この時点では、どちらも同じですが、機能を追加しても同じままです。 ?
システムに機能を追加して、IMSがどのように機能するかを見てみましょう。
フェーズ2:IPホワイトリストを使用したリアルタイムダッシュボードの構築
同じアプリを作成しているが、それらがホワイトリストに登録されたIPアドレスのみからのものであることを確認したいとします。今、あなたは新しい機能を追加しています。
ケース1:RDBMSを使用してこれらのイベントを保存したとしましょう。ただし、テーブルが適合しない可能性があり、IPホワイトリストにRedisまたはMemCachedを使用していました。
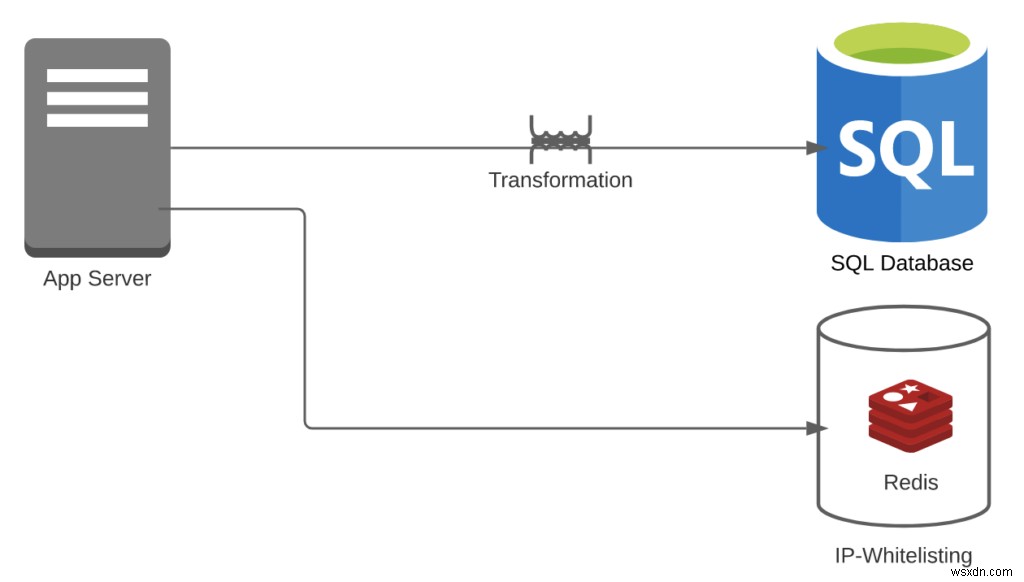
- 変換オーバーヘッド=1
- IPホワイトリストの場合、変換は必要ありません。ただし、イベントストリームをテーブルに変換する必要があります
- パイプラインオーバーヘッド=2
- Redis+RDBMSがあります
- 機能の数=2

ケース2:Redis + Kafka+RDBMSを使用しているとします。
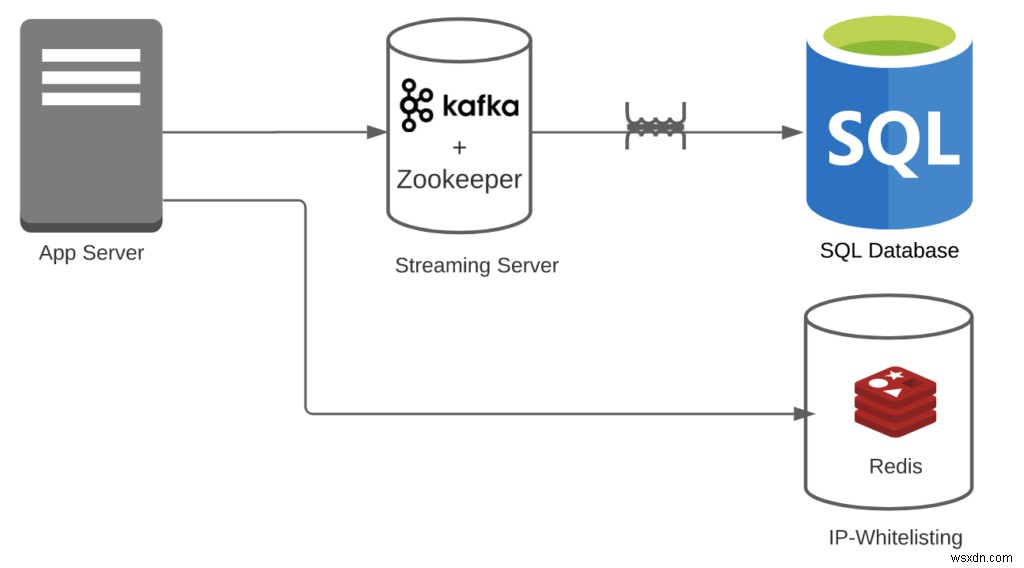
- 変換オーバーヘッド=1
- IPホワイトリストの場合、変換は必要ありません。また、Kafkaはストリームを簡単に処理できます。
- パイプラインのオーバーヘッド=3
- Redis + Kafka+RDBMSがあります。注:KafkaにもZookeeperが必要であることを無視しています。これを追加すると、数はさらに減ります。
- 機能の数=2

ケース3:Redis + Kafka+KsqlDBを使用しているとします。
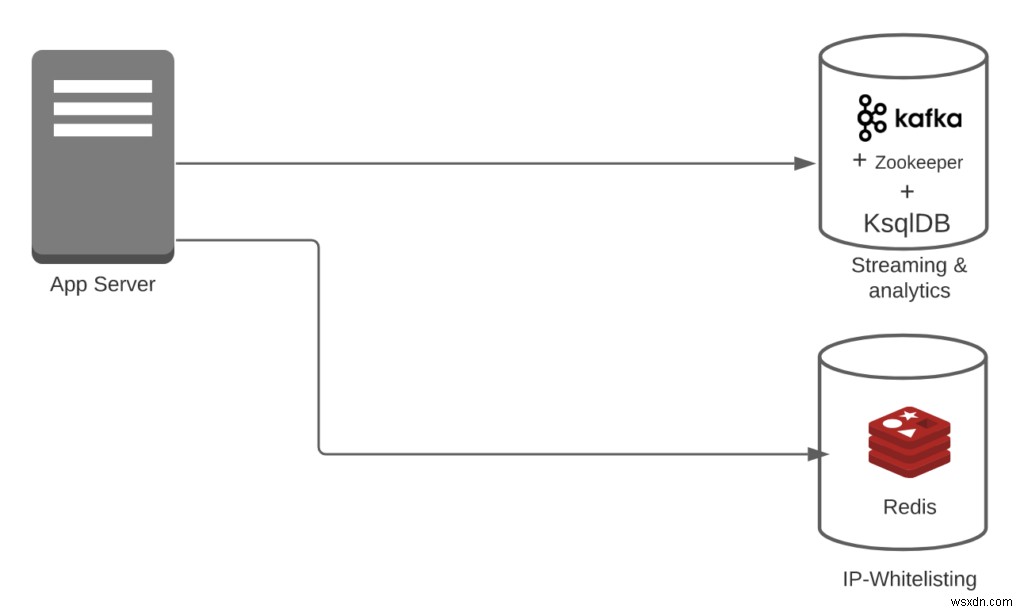
- 変換オーバーヘッド=0
- IPホワイトリストの場合、変換は必要ありません。また、KafkaとKsqlDBはストリームを簡単に処理できます。
- パイプラインオーバーヘッド=2
- Redis +(Kafka + KsqlDB)があります。注:この場合、同じシステムのKafka+KsqlDBの一部を検討しています。
- 機能の数=2

ケース4:Redis + Redis Streams+RedisTimeSeriesを使用しているとします。

- 変換オーバーヘッド=0
- IPホワイトリストの場合、変換は必要ありません。また、Redis StreamsとRedisTimeseriesは、ストリームとアラートを簡単に処理できます。
- パイプラインオーバーヘッド=1
- Redis + Redis Streams +RedisTimeSeriesがあります。注:この場合、3つすべてが同じシステムの一部です。
- 機能の数=2

フェーズ2後の結論:
追加機能を追加したとき、
- ケース1はフェーズ1では2でしたが、1.5に低下しました。
- ケース2はフェーズ1で3でしたが、2になりました
- ケース3はフェーズ1で1であり、1のままでした
- ケース4はフェーズ1で1でしたが、0.5(ベスト)に低下しました
したがって、この例では、IMSスコアが1と最も低いケース4は、新しい機能を追加するにつれて実際に改善され、最終的に0.5になりました。
注意:機能を追加したり、異なる機能を追加したりすると、ケース4が最も単純なままにならない場合があります。しかし、それがIMSスコアの考え方です。すべての機能を一覧表示し、さまざまなアーキテクチャを比較して、ユースケースに最適なアーキテクチャを確認するだけです。
さらに使いやすくするために、IMSスコアを計算するための簡単なスプレッドシートに実装できる計算機を提供しています。
IMS電卓
使用方法は次のとおりです。
- データレイヤーまたはデータパイプラインごとに、以下をリストします。
- 現在お持ちの機能。
- ロードマップにある機能。データレイヤーが追加のオーバーヘッドなしで今後の機能を引き続きサポートできるようにするため、これは重要です。
- 次に、各機能のトランスフォーメーショナルオーバーヘッドとパイプラインオーバーヘッドをマッピングします。
- 最後に、すべてのオーバーヘッドの合計を機能の数で割ります。
- 異なるシステムのパイプラインについて手順2と3を繰り返し、それらを比較対照します。
データパイプライン1
データパイプライン2

概要
結果を考えずに、夢中になって複雑なデータレイヤーを構築するのは非常に簡単です。 IMSスコアは、意思決定を意識するのに役立つように作成されました。
IMSスコアを使用して、ユースケースの複数のシステムを簡単に比較および対比し、機能のセットに本当に最適なシステムを確認できます。また、システムが機能の拡張に耐え、可能な限りシンプルな状態を維持できるかどうかを検証することもできます。
常に覚えておいてください:
「シンプルさは究極の洗練さです」 —レオナルド・ダ・ヴィンチ
「ほとんどの情報は無関係であり、ほとんどの労力が無駄になりますが、無視すべきことを知っているのは専門家だけです。 」—ジェームズ・クリア、原子の習慣
-
Google Chromeで閲覧データを消去する方法:2つの簡単な方法
Webサイトが保存するデータをこれまで以上に制御できることをご存知ですか? Google Chromeにはプライバシーツールが満載です。たとえば、個々のウェブサイトのCookieしか削除できなかった以前とは異なり、ウェブサイトに保存されているすべてのデータを削除できます。 この記事では、Chromeのアクションと設定の2つの方法でGoogleChromeのデータを削除する方法を説明します。両方の方法を使用してデータを削除する方法については、読み続けてください。 Chromeアクションを使用して閲覧データをクリアする方法 ブラウジングデータをクリアする最初の方法は、ショートカットのChro
-
インターネットから個人データを削除する方法
GoogleやFacebookなどの企業がサービスを利用するために多くの個人情報を提供しています。これについて心配するのは自然なことです。幸いなことに、インターネットから個人データを簡単に削除できます。さまざまな場所からデータを削除するには、さまざまな方法に従う必要があります。このガイドでは、最も人気のあるWebサービスから個人情報を削除する方法を紹介します。 Googleアカウントを削除する方法 グーグルは間違いなくウェブ上で最も訪問された場所の1つです。パーソナライズされたコンテンツを配信するための大量のデータを保存します。個人情報、ウェブ検索、視聴した動画、位置データなどを保存します。