ApacheCassandraのバックアップとリカバリ
データベースのバックアップとリカバリは、データベース管理者(DBA)が実行する重要な日常業務の1つです。データベースバックアップは、データが失われた場合にデータを回復するために使用できるデータのコピーです。
このブログでは、Apache®Cassandra®データベースをバックアップし、障害が発生した後にそれらを復元する方法を紹介しています。
Apache Cassandraは分散化されていますが、クラスター内のノードの1つにデータが含まれている限り、ビジネスデータを失うことなくシングルノードおよびマルチノードの障害に耐えることができます。ただし、ベストプラクティスとして、データベースのバックアップを構成する必要があります。
クラスタ全体の再構築、データの破損、偶発的なデータの削除などの障害が発生した場合、バックアップからデータを回復し、影響を最小限に抑えるか、まったく影響を与えずに業務を継続できます。
ますます多くの企業が、CassandraなどのNoSQLデータベースを使用して、より一般的にはビッグデータとして知られる大量のビジネスデータを正常に管理しています。多くの主要な組織で広く使用されているCassandraは、ビッグデータをサポートするためのスケーラビリティ、フォールトトレランス、および一貫性を保証します。
Cassandraデータベースのバックアップと復元
次のユーティリティを使用して、Cassandraデータベースのスナップショットを作成し、必要に応じて復元できます。
-
nodetool(スナップショットを撮るには) -
sstableloader(スナップショットバックアップを復元するには)
次の画像は、sstableloaderを使用してクラウドクラスターからCassandraclusterに移動する方法を示しています。 :
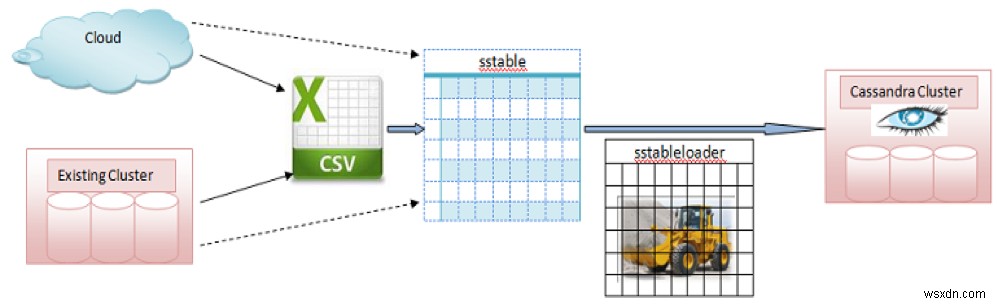
画像ソース :https://dzone.com/articles/using-casandras-sstable-bulk
次の例では、nodetoolを使用しています Cassandraデータベースのスナップショットを作成するキースペース(ユーザー) 従業員というテーブルがあります 。
ソースCassandraクラスターの詳細:
$ nodetool -u cassandra -pw ******** -h localhost status
Datacenter: us-central1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 10.128.0.2 121.52 KiB 256 63.3% 5957997f-7471-4c21-bead-37a6604812e2 f
UN 10.128.0.3 92.22 KiB 256 68.0% 87c2a663-a965-4675-b5ed-c4a46d77c796 f
UN 10.128.0.4 225.3 KiB 256 68.8% 8e12557f-be00-4387-bff3-ef51f431b9a0 f
次のコマンドを使用して、キースペースをバックアップします :
$ nodetool -h localhost -u cassandra -pw ****** snapshot users -t "users-201904201800"
Requested creating snapshot(s) for [users] with snapshot name [users-201904201800] and options {skipFlush=false}
Snapshot directory: users-201904201800
これにより、次の例に示すようにバックアップスナップショットが作成されます。
/bitnami/cassandra/data/data/users/employee-c1319df0636211e9a0e3570eb7f8fd5f/snapshots/users-201904201800
$ ls -ltr
total 44
-rw-r--r-- 2 cassandra cassandra 16 Apr 20 12:05 md-1-big-Filter.db
-rw-r--r-- 2 cassandra cassandra 56 Apr 20 12:05 md-1-big-Summary.db
-rw-r--r-- 2 cassandra cassandra 32 Apr 20 12:05 md-1-big-Index.db
-rw-r--r-- 2 cassandra cassandra 134 Apr 20 12:05 md-1-big-Data.db
-rw-r--r-- 2 cassandra cassandra 10 Apr 20 12:05 md-1-big-Digest.crc32
-rw-r--r-- 2 cassandra cassandra 43 Apr 20 12:05 md-1-big-CompressionInfo.db
-rw-r--r-- 2 cassandra cassandra 4683 Apr 20 12:05 md-1-big-Statistics.db
-rw-r--r-- 2 cassandra cassandra 92 Apr 20 12:05 md-1-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 31 Apr 20 12:05 manifest.json
-rw-r--r-- 1 cassandra cassandra 865 Apr 20 12:05 schema.cql
$ date
Sat Apr 20 12:08:21 UTC 2019
次に、/スナップショットをアーカイブします ディレクトリファイルをバックアップし、tarファイルを / bitnami / Cassandra / data / data / backupに移動します ディレクトリ。
$ tar -cvf users-201904201800.tar *.*
manifest.json
md-1-big-CompressionInfo.db
md-1-big-Data.db
md-1-big-Digest.crc32
md-1-big-Filter.db
md-1-big-Index.db
md-1-big-Statistics.db
md-1-big-Summary.db
md-1-big-TOC.txt
schema.cql
$ ls -ltr
total 64
-rw-r--r-- 2 cassandra cassandra 16 Apr 20 12:05 md-1-big-Filter.db
-rw-r--r-- 2 cassandra cassandra 56 Apr 20 12:05 md-1-big-Summary.db
-rw-r--r-- 2 cassandra cassandra 32 Apr 20 12:05 md-1-big-Index.db
-rw-r--r-- 2 cassandra cassandra 134 Apr 20 12:05 md-1-big-Data.db
-rw-r--r-- 2 cassandra cassandra 10 Apr 20 12:05 md-1-big-Digest.crc32
-rw-r--r-- 2 cassandra cassandra 43 Apr 20 12:05 md-1-big-CompressionInfo.db
-rw-r--r-- 2 cassandra cassandra 4683 Apr 20 12:05 md-1-big-Statistics.db
-rw-r--r-- 2 cassandra cassandra 92 Apr 20 12:05 md-1-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 31 Apr 20 12:05 manifest.json
-rw-r--r-- 1 cassandra cassandra 865 Apr 20 12:05 schema.cql
-rw-r--r-- 1 cassandra cassandra 20480 Apr 20 12:22 users-201904201800.tar
cp *.tar /bitnami/cassandra/data/data/backup.
/bitnami/cassandra/data/data/backup
$ ls -ltr
-rw-r--r-- 1 cassandra cassandra 20480 Apr 20 12:23 users-201904201800.tar
バックアップtarファイルをデフォルト以外の場所にコピーした後、従業員を削除します テーブル。
注 :Cassandraは、定義されたパーティションキーとレプリケーション係数に基づいてデータをクラスタ全体に分散するため、すべてのノードからこのバックアップコマンドを実行する必要があります。この例では、crontabでLinux®シェルスクリプトを使用しています。これにより、すべてのノードが一度にバックアップされます。
$ cqlsh -u cassandra -p *******
Connected to Test_Cassandra at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.4 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cassandra@cqlsh> use users;
cassandra@cqlsh:users> select * from employee;
emp_id | employee_address | employee_name
--------+------------------+---------------
8796 | Singapore | Joy
5647 | London | Mike
3452 | Canada | Nancy
6453 | China | John
(4 rows)
cassandra@cqlsh:users> drop table employee;
cassandra@cqlsh:users> select * from employee;
InvalidRequest: Error from server: code=2200 [Invalid query] message="unconfigured table employee"
従業員を復元するには キースペース(ユーザー)のテーブル スナップショットバックアップ。sstableloaderを使用する必要があります 効用。 sstableloader ユーティリティは、sstableのセットを各ノードにコピーするだけでなく、クラスターに対して定義されたレプリケーション戦略に基づいて、データの適切な部分をすべてのノードに転送します。データを復元するために空のテーブルを用意する必要はないことに注意してください。
次の手順を使用して、tarファイルを backup / usersに復元します。 :
$ pwd
/bitnami/cassandra/data/data/backup/users
$ ls -ltr
total 20
-rw-r--r-- 1 cassandra cassandra 20480 Apr 20 12:23 users-201904201800.tar
$ tar -xvf *.tar
manifest.json
md-1-big-CompressionInfo.db
md-1-big-Data.db
md-1-big-Digest.crc32
md-1-big-Filter.db
md-1-big-Index.db
md-1-big-Statistics.db
md-1-big-Summary.db
md-1-big-TOC.txt
schema.cql
復元するテーブルの名前を使用して、ユーザーディレクトリのソフトリンクを作成します。
$ ln -s /bitnami/cassandra/data/data/backup/users employee
$ ls -ltr
total 64
-rw-r--r-- 1 cassandra cassandra 865 Apr 20 12:05 schema.cql
-rw-r--r-- 1 cassandra cassandra 92 Apr 20 12:05 md-1-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 56 Apr 20 12:05 md-1-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 4683 Apr 20 12:05 md-1-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 32 Apr 20 12:05 md-1-big-Index.db
-rw-r--r-- 1 cassandra cassandra 16 Apr 20 12:05 md-1-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 10 Apr 20 12:05 md-1-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 134 Apr 20 12:05 md-1-big-Data.db
-rw-r--r-- 1 cassandra cassandra 43 Apr 20 12:05 md-1-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 31 Apr 20 12:05 manifest.json
-rw-r--r-- 1 cassandra cassandra 20480 Apr 20 12:23 users-201904201800.tar
lrwxrwxrwx 1 cassandra cassandra 41 Apr 20 15:56 employee -> /bitnami/cassandra/data/data/backup/users
.cqlを使用してテーブル構造を作成します スナップショットバックアップによって生成されたファイル。
キースペースのバックアップを実行する場合 、 schema.cqlというファイルを生成します キースペースに存在するオブジェクトのデータ定義言語(DDL)が含まれています 。
schema.cqlを使用します 誤って削除された従業員オブジェクトを作成します。
$ cqlsh -u cassandra -p ******** -f schema.cql
Warnings:
dclocal_read_repair_chance table option has been deprecated and will be removed in version 4.0
dclocal_read_repair_chance table option has been deprecated and will be removed in version 4.0
$ cqlsh -u cassandra -p ******* -f schema.cql
sstableloaderを使用して、スナップショットからデータを復元します 、すべての安定版を読み取ります バックアップからデータをクラスターにストリーミングします。次に、クラスターで定義されたレプリケーション戦略に基づいて、データの関連部分を各ノードに転送します。
Syntax: sstableloader -u <username> -pw passwrod -d <hostname> <employee table softlink name with location>
次のコマンドを使用して、データを復元します。
$ sstableloader -u cassandra -pw ******** -d cassandra-cluster-1-node-0 /bitnami/cassandra/data/data/backup/users/employee
Established connection to initial hosts
Opening sstables and calculating sections to stream
Streaming relevant part of /bitnami/cassandra/data/data/backup/users/md-1-big-Data.db to [/10.128.0.2, /10.128.0.3, /10.128.0.4]
progress: [/10.128.0.2]0:0/1 0 % [/10.128.0.3]0:0/1 0 % [/10.128.0.4]0:1/1 100% total: 33% 0.032KiB/s (avg: 0.032KiB/s)
progress: [/10.128.0.2]0:0/1 0 % [/10.128.0.3]0:0/1 0 % [/10.128.0.4]0:1/1 100% total: 33% 0.000KiB/s (avg: 0.031KiB/s)
progress: [/10.128.0.2]0:0/1 0 % [/10.128.0.3]0:1/1 100% [/10.128.0.4]0:1/1 100% total: 66% 0.113KiB/s (avg: 0.050KiB/s)
progress: [/10.128.0.2]0:1/1 100% [/10.128.0.3]0:1/1 100% [/10.128.0.4]0:1/1 100% total: 100% 85.129KiB/s (avg: 0.074KiB/s)
progress: [/10.128.0.2]0:1/1 100% [/10.128.0.3]0:1/1 100% [/10.128.0.4]0:1/1 100% total: 100% 0.000KiB/s (avg: 0.073KiB/s)
progress: [/10.128.0.2]0:1/1 100% [/10.128.0.3]0:1/1 100% [/10.128.0.4]0:1/1 100% total: 100% 0.000KiB/s (avg: 0.073KiB/s)
Summary statistics:
Connections per host : 1
Total files transferred : 3
Total bytes transferred : 0.393KiB
Total duration : 5346 ms
Average transfer rate : 0.073KiB/s
Peak transfer rate : 0.074KiB/s
すべてのノードでこれらの手順を繰り返して、安定版からデータを取得します。
nodetool repairを使用してデータを修復します 、コマンドが実行されるノードに保存されているデータのすべてのレプリカを比較し、各レプリカを最新バージョンに更新します。
$ nodetool repair -u Cassandra -pw ********
[2019-04-21 07:59:14,701] Starting repair command #1 (5b123ad0-640b-11e9-a0e3-570eb7f8fd5f), repairing keyspace users with repair options (parallelism: parallel, primary range: false, incremental: true, job threads: 1, ColumnFamilies: [], dataCenters: [], hosts: [], # of ranges: 768, pull repair: false)
[2019-04-21 07:59:16,450] Repair completed successfully
[2019-04-21 07:59:16,451] Repair command #1 finished in 1 second
[2019-04-21 07:59:16,460] Replication factor is 1. No repair is needed for keyspace 'system_auth'
[2019-04-21 07:59:16,474] Starting repair command #2 (5c22e780-640b-11e9-a0e3-570eb7f8fd5f), repairing keyspace system_traces with repair options (parallelism: parallel, primary range: false, incremental: true, job threads: 1, ColumnFamilies: [], dataCenters: [], hosts: [], # of ranges: 513, pull repair: false)
finished (progress: 1%)
[2019-04-21 07:59:17,653] Repair completed successfully
[2019-04-21 07:59:17,653] Repair command #2 finished in 1 second
従業員へのデータを検証します 私たちが落としたテーブル。前のコマンドは、前に作成したバックアップからデータを復元しました。次に、データを検証して、正しく復元されたかどうかを確認する必要があります。
$ cqlsh -u cassandra -p ********
Connected to Test_Cassandra at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.4 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cassandra@cqlsh> use users;
cassandra@cqlsh:users> select * from employee;
emp_id | employee_address | employee_name
--------+------------------+---------------
8796 | Singapore | Joy
5647 | London | Mike
3452 | Canada | Nancy
6453 | China | John
(4 rows)
この投稿では、テーブルをバックアップしてCassandradatabaseに復元する方法を学びました。ただし、完全なキースペース/データベースを復元する必要がある場合は、テーブルの復元部分なしで前の手順を使用してください。 キースペースを再作成する必要があります sstableloaderを使用してデータをロードします 。
sstableloaderでは、ソースデータベースとターゲットデータベースのクラスター内のノードの数は関係ありません。 各安定版を読み取るため 次に、定義されたレプリケーション戦略に従ってデータをクラスターに配置しながら、データをクラスターにストリーミングします。
[フィードバック]タブを使用して、コメントを書き込んだり、質問したりします。
専門家による管理、管理、構成で環境を最適化する
Rackspaceのアプリケーションサービス(RAS) 専門家は、幅広いアプリケーションポートフォリオにわたって次の専門的かつ管理されたサービスを提供します。
- eコマースおよびデジタルエクスペリエンスプラットフォーム
- エンタープライズリソースプランニング(ERP)
- ビジネスインテリジェンス
- Salesforceの顧客関係管理(CRM)
- データベース
- メールホスティングと生産性
お届けします:
- 偏りのない専門知識 :私たちは、即時の価値を提供する機能に焦点を当てて、お客様の近代化の旅を簡素化し、導きます。
- 狂信的な経験 ™:最初にプロセスを組み合わせます。テクノロジーセカンド。包括的なソリューションを提供するための専用のテクニカルサポートを備えたアプローチ。
- 比類のないポートフォリオ :豊富なクラウドエクスペリエンスを適用して、適切なテクノロジーを適切なクラウドに選択して導入できるようにします。
- アジャイルデリバリー :私たちはあなたがあなたの旅の途中であなたに会い、あなたの成功と一致します。
今すぐチャットして始めましょう。
-
Google のバックアップと同期をスケジュールする方法
ご存知かもしれませんが、「バックアップと同期」は Google が提供するデスクトップ アプリで、ローカル ファイルを Windows PC または MAC コンピュータから Google ドライブに簡単にバックアップできます。 Google バックアップと同期は、バックアップ プロセスを自動化し、ローカル ファイルをクラウドと同期したり、その逆を行ったりするための優れたバックアップ アプリケーションですが、営業時間外にバックアップ操作をスケジュールするオプションは提供していません。その結果、バックアップ アプリケーションがインストールされているコンピューターのパフォーマンスが低下したり、ネ
-
Windows レジストリをバックアップおよび復元する方法
レジストリコンピューターにとって頭脳のような役割を果たします。コンポーネント、サービス、アプリケーション、および Windows のほとんどすべてで使用されるすべての構成と設定が含まれています。レジストリには、キーと値という 2 つの基本的な概念があります。レジストリ キーはフォルダーであるオブジェクトであり、インターフェイスではフォルダーのように見えます。値はフォルダ内のファイルに少し似ており、実際の設定が含まれています。 Windows コンピュータの設定に大きな変更を加える必要があるときはいつでも、Windows レジストリを変更する必要があります。ただし、レジストリ エディターを使用し