OracleExadataとストレージインデックス機能
Oracle®Exadata®システムは、データベースのパフォーマンスを向上させるストレージ・インデックスを導入しています。ストレージインデックスは、キー統計を含むメモリ内の構造ストアです。このストレージインデックスにより、Exadataは、すべての行を読み取るのではなく、最初にインデックスをチェックして関連データを見つけることにより、ディスクI/O操作とクエリを高速化できます。
ストレージ・インデックスに関する重要な考慮事項の1つは、Exadataがストレージ・インデックスのI / Oを節約するために、システムがこれらのインデックスのデータをインデックスのストレージ領域に書き込む必要があることです。つまり、ストレージインデックスデータを使用するには、セルサーバーのリージョンインデックスメモリ構造でプライミングする必要があります。初めてクエリを実行すると、リージョンインデックスに関連データが含まれていないため、ストレージインデックスのI/Oの節約は見られません。
ストレージ・インデックスの主な目標は、ExadataSmartScanの要求を処理するために必要なディスクI/Oの量を減らすことです。スキャンされた実際のデータベースを検討することで、ストレージインデックスの使用によるI / Oの節約を測定できます。ストレージインデックスは、クエリに述語(つまり、WHERE句)と基になる自動ストレージ管理(WHERE句が含まれている場合)のダイレクトパス読み取り操作中に使用されます。 ASM)ディスクグループにはcell.smart_scan_capable=TRUEがあります 属性セット。つまり、ストレージ・インデックスは、Exadata SmartScanforSQLステートメントをクエリ述語で補完します。さらに、ストレージインデックスは、クエリ述語の列に関してデータが適切に順序付けられている場合に、パフォーマンスを最大に節約します。
OracleExadataアーキテクチャ
設計の観点から、ストレージインデックスは、従来のOracle B*Treeインデックスやその他のインデックスタイプとは異なります。ストレージインデックスは、データベース内にセグメントとして格納される物理構造ではなく、Exadataストレージセルに存在するメモリ構造です。従来のインデックスの目的は、Oracleがテーブル内の行を迅速に検索できるようにすることですが、ストレージインデックスの目的は、ストレージインデックスの値が要求されたことを示している場合に、物理データベースの行の読み取りをスキップするようにセルサービスソフトウェアに指示する非常に効率的な手段を提供することです。これらの行にはデータが含まれていません。
ストレージ領域内のデータが、クエリ述語で通常使用される列に対して適切に順序付けられている場合、ストレージインデックスにより、セルサーバー(CELLSRV)プロセスは物理I / O要求をバイパスし、ディスクI/Oを節約できます。ストレージインデックスによって節約されたセルの物理I/Oバイトは、このI/O節約のメリットを測定するために使用できるシステム統計です。
一方、データの順序が適切でない場合、各ストレージ領域には特定の列またはクエリ述語の潜在的な値が広範囲に含まれる可能性が高いため、ストレージインデックスのメリットは限られているか、まったくありません。従来のB*Treeインデックスと同様に、クラスタリングはストレージインデックスの重要な考慮事項です。 storageindexesに関する興味深い事実の1つは、ExadataのCELLSVRプロセスは、ストレージ領域に追跡範囲内のデータが実際に含まれているかどうかに関係なく、クエリの述語値が各ストレージ領域の領域インデックスで追跡される高値と低値の範囲外である場合にのみ使用することです。
ストレージ領域にatableの10行のデータが含まれている例を考えてみます。これらの10行の中に、 FIRST_NAMEという列があると仮定します。 この列内の領域には、FIRST_NAMEに「john」、「anto」、「max」、「leigh」、「theo」、「rachel」、「lauren」、「bob」、「denise」、および「ジェン」。 FIRST_NAME="chris"を検索するクエリを発行した場合 、このテーブルの既存のストレージインデックスは、「chris」がアルファベット順に「anto」と「theo」の間にあるため、このリージョンへのアクセスを失格にすることはありません。ただし、FIRST_NAME="victor"に基づくクエリの場合 、CELLSVRは、値が高値と低値の範囲外であるため、このストレージ領域への物理I/Oをバイパスします。
つまり、これは、ストレージインデックス関数が(I / O要求の発行を許可することに関して)誤検知を返す可能性があることを意味しますが、誤検知を返すことはありません。
I / Oをバイパスすることは、物理的な読み取りをスキップすることと同じであり、物理的な読み取りをスキップすることで時間を節約できます。次の画像は、ストレージインデックスがどのように機能するかを論理的に表したものです。
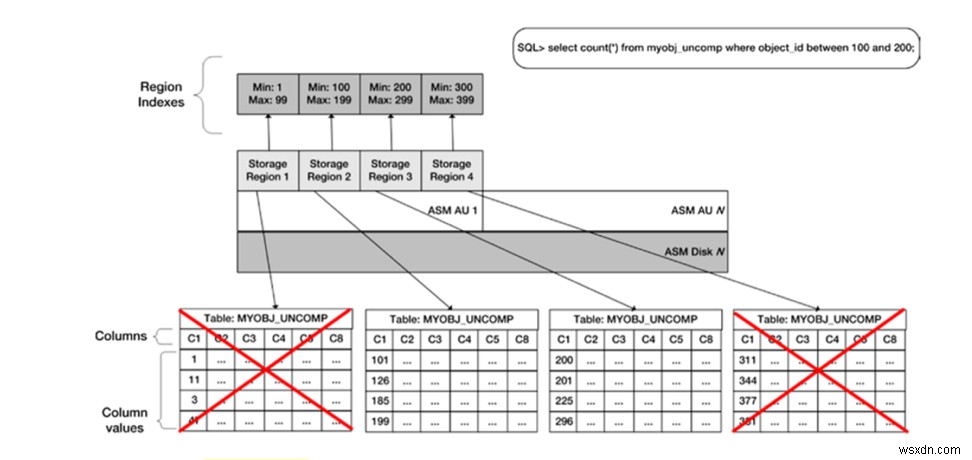
画像ソース :JohnClarkeによるOracleExadataレシピ。
Exadataは、アプリケーションの使用状況で時間ベースのストレージインデックスを自動的に維持します。 Exadata Database Machine Administrator(DMA)が、データの使用を促進したり、アプリケーションのクエリ述語を変更したりするためにデータを順序付ける可能性以外に、ストレージインデックスの動作に影響を与えるためにできることは何もありません。
次の状況でストレージインデックスを使用することを検討してください。
- ダイレクトパス読み取り操作中。
- スマートスキャンを使用します。
- クエリに述語が含まれている場合。
Storage Indexは、Oracle Exadata製品で利用できる最もスマートな機能であり、データを最速かつ最適化された方法で検索するのに役立ちます。
[フィードバック]タブを使用して、コメントを書き込んだり、質問したりします。
専門家による管理、管理、構成で環境を最適化する
Rackspaceのアプリケーションサービス(RAS) 専門家は、幅広いアプリケーションポートフォリオにわたって次の専門的かつ管理されたサービスを提供します。
- eコマースおよびデジタルエクスペリエンスプラットフォーム
- エンタープライズリソースプランニング(ERP)
- ビジネスインテリジェンス
- Salesforceの顧客関係管理(CRM)
- データベース
- メールホスティングと生産性
お届けします:
- 偏りのない専門知識 :私たちは、即時の価値を提供する機能に焦点を当てて、お客様の近代化の旅を簡素化し、導きます。
- 狂信的な経験 ™:最初にプロセスを組み合わせます。テクノロジーセカンド。包括的なソリューションを提供するための専用のテクニカルサポートを備えたアプローチ。
- 比類のないポートフォリオ :豊富なクラウドエクスペリエンスを適用して、適切なテクノロジーを適切なクラウドに選択して導入できるようにします。
- アジャイルデリバリー :私たちはあなたがあなたの旅の途中であなたに会い、あなたの成功と一致します。
今すぐチャットして始めましょう。
-
AutonomousDatabaseDedicatedおよびExadataクラウドインフラストラクチャ
この投稿では、Oracle®AutonomousDatabaseDedicatedおよびExadata®クラウドインフラストラクチャに関するさまざまなソースからの情報を紹介します。 はじめに Oracle Autonomous Databaseの技術概要によると、「Oracle Autonomous Databaseは、クラウドの柔軟性と機械学習の能力を組み合わせて、データ管理をサービスとして提供します。」このドキュメントは後で追加します。「OracleAutonomousデータベースには、OracleExadataおよびExadataCloud Serviceにある製品のフルセットが含まれ
-
Windows 10 Feature Update 1909 をダウンロードしてインストールする方法。
2019 年 11 月 12 日、Microsoft は Windows 10 バージョン 1909 の最新の機能更新プログラムをリリースし、翌日にはすべてのユーザーが Windows Update を介してダウンロードおよびインストールできるようになります。 Windows 10 バージョン 1909 は、バージョン 1903 と同じシステム ファイルを共有します。システムを Windows 10 バージョン 1909 に更新すると、10 月 8 日をインストールした後、コンピューターに既にインストールされている (ただし休止状態のままである) 新機能が実際に有効になります。 2019—