メトロ仮想データセンター
ITが成長し続けるにつれて、情報システムはより重要な無関心な業界になりつつあります。情報システムでのサービスの中断は、経済的損失、重大なデータ損失を引き起こし、特に通信、金融、医療、eコマース、ロジスティクス、政府などの業界で、市場のブランドイメージに影響を与える可能性があります。したがって、サービスの継続性は、情報システムの構築にとって重要です。現在、サービスの継続性は通常、本番データのコピーが保存されるディザスタリカバリ(DR)センターを構築することで改善されています。
従来のDRソリューションでは、本番データセンター(DC)ごとに1つのDRセンターが展開されます。 DRセンターは、productionDCがサービスの故障につながる災害に遭遇しない限り、サービスアクセスを提供しません。災害は、短期間で修復できません。したがって、DRセンターは次の課題に直面しています。
-
生産センターで電源障害、火災、洪水、地震が発生した場合、DRセンターにサービスを切り替えるには手動操作が必要です。また、専門的な復旧対策とデバッグも必要です。これらの災害は、長期的なサービスの中断とサービスの中断を引き起こす可能性があります。
-
DRセンターはサービスを提供せず、ほとんどの時間アイドル状態のままであるため、リソースの使用量が少なくなります。
効率的なリソースの使用、負荷分散、および2つのDC間の自動切り替えに関する顧客の要件を満たすために、Oracle®はエンドツーエンドのアクティブ-アクティブDCソリューションを発表しました。このソリューションにより、両方のDCを同時に実行し、サービス負荷を共有して、全体的なサービス機能とリソース使用量を向上させることができます。このソリューションは、デバイス障害または単一DC障害の場合に、ゼロサービス認識で自動フェイルオーバーを保証します。さらに、目標復旧時点(RPO)と目標復旧時間(RTO)がゼロです。注:RTOは、アプリケーションシステムと展開モードによって異なります。
現在のストレージ業界には2つの可用性モードがあります。
- アクティブ-パッシブ(AP)またはアクティブ-スタンバイ
- アクティブ-アクティブ(AA)またはメトロ仮想データセンター(MVDC)
データベース(DB)は、データ損失ゼロのオプションを使用してアクティブスタンバイモードでセットアップする必要があります。次のアイテムは重要なコンポーネントです:
- Oracle Data Guard Broker:Data Guardの構成を自動化および一元化し、複雑な役割の変更を1つのコマンドで実行して、スイッチオーバーまたはフェイルオーバーを呼び出すことができます。
- フラッシュバックデータベース:DBの巻き戻しまたは復帰を提供し、フラッシュバックログ情報をフラッシュリカバリ領域に保存します。
- Fast-Start Failover(FSFO):データ損失なしでフェイルオーバーを有効にします。スタンバイDBがプライマリDBと同期していない限り、FSFOはトリガーされません。
- オブザーバー:DataGuardコマンドラインインターフェースに組み込まれた個別のプロセス
dgmgrlを提供します 、プライマリDBとスタンバイDBの状態を監視して、考えられる障害状態を確認します。
次の画像は、DataGuardの構成を示しています。
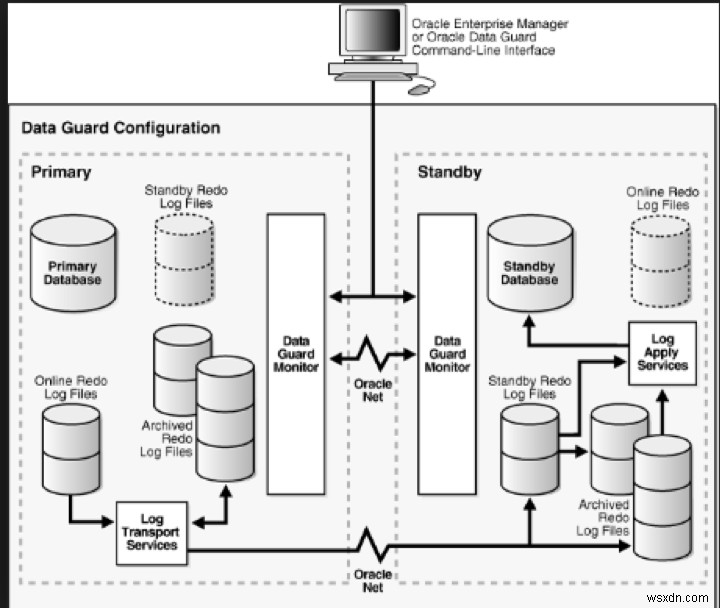
画像ソース: https://neeraj-dba.blogspot.com/2011/10/dataguard-broker-and-its-benefits_05.html
プライマリDBで、ログライター(LGWR)プロセスはREDOデータを1つ以上のログネットワークサーバー(LNSn)プロセスに送信し、LNSnプロセスは複数のリモート宛先へのネットワークI/Oを並行して開始します。すべてのLGWRSYNC宛先によって受信されたトランザクションを回復するためにREDOデータが必要になるまで、トランザクションはプライマリデータベースでコミットされません。
スタンバイDBでは、リモートファイルサーバー(RFS)がLGWRプロセスからネットワーク経由でREDOデータを受信し、スタンバイREDOログファイルにREDOデータを書き込みます。
最大の可用性を実現するアーキテクチャを設計するときは、ダウンタイムの考えられる原因と、計画外および計画中のダウンタイムを分類する方法の両方を考慮する必要があります。
計画外のダウンタイムには、次のアイテムへの予期しない中断が含まれます。
-
サーバーの可用性:ハードウェアまたはソフトウェアの障害が原因で発生する可能性のある、DBサーバーをホストする1つ以上のマシンの予期しない障害にもかかわらず、DBサービスへの中断のないアクセスを確保する必要があります。 OracleReal Application Clusters(RAC)は、このような障害に対する最も効果的な保護を提供します。
-
データの可用性:ビジネスクリティカルなデータの損失、損傷、破損などのデータ障害を軽減するために、計画では、常にデータにアクセスできるようにする必要があります。
計画的なダウンタイムには、次の項目を含むアクセスへのスケジュールされた中断が含まれます。
- システムの変更
- データの変更
- アプリの変更
MVDCのスイッチオーバーテストシナリオ
スイッチオーバーは、制御された計画的なロール反転操作であり、DataGuard構成のプライマリDBとスタンバイDBがロールを切り替えます。スイッチオーバー後も、各データベースは引き続き新しい役割でDataGuard構成に参加します。
切り替えは次の順序で行われます:
- 元のプライマリDBは役割をスタンバイに切り替えます。
- 元のスタンバイDBがプライマリロールに移行します。
スイッチオーバーを実行すると、DataGuardBrokerが次のアクティビティを自動的に処理します。
- プライマリDBとターゲットスタンバイDBがオンラインであり、エラーがないことを確認します。
- プライマリDBとスタンバイDBの両方のRAC構成で1つを除くすべてのインスタンスをシャットダウンします。
- プライマリDBとスタンバイDBの役割を切り替えます。 Data Guard Brokerは、最初に元のプライマリDBをスタンバイロールで実行するように変換します。次に、ブローカーはターゲットスタンバイDBをプライマリロールに移行します。また、ブローカー構成ファイルを更新して役割の変更を記録し、再起動後に各DBが正しい役割で実行されるようにします。
- 新しいスタンバイ(以前のプライマリ)DBを再起動し、REDO適用プロセスを開始して、新しいプライマリDBからREDOデータを適用します。これがRACDBの場合、ブローカーはスイッチオーバーの前にシャットダウンしたインスタンスを再起動します。
- 新しいプライマリDBを再起動し、REDOトランスポートサービスを開いて開始し、REDOデータをスタンバイDBに送信します。これがRACDBの場合、ブローカーはスイッチオーバーの前にシャットダウンしたインスタンスを再起動します。
切り替え前:
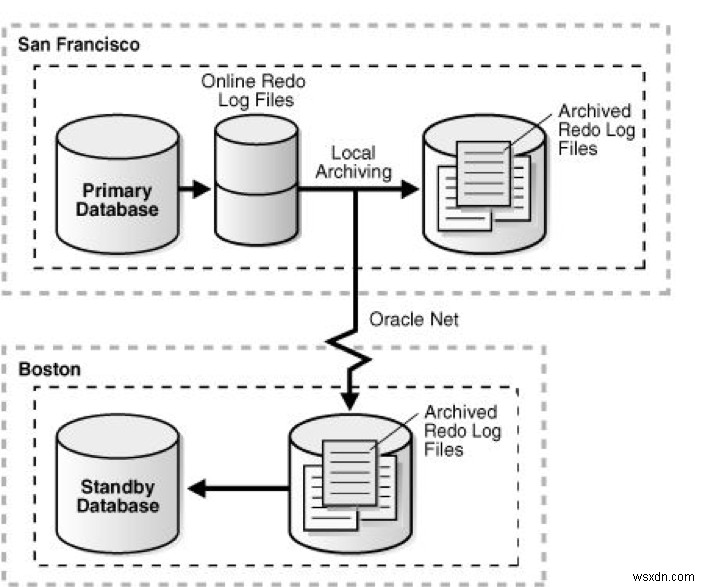
画像ソース: https://docs.oracle.com/cd/E11882_01/server.112/e41134/role_management.htm#SBYDB00615
切り替え後:
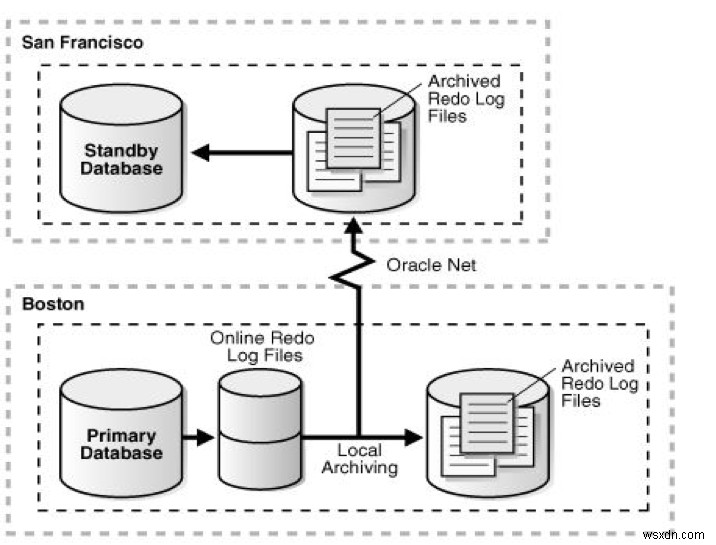
画像ソース: https://docs.oracle.com/cd/E11882_01/server.112/e41134/role_management.htm#SBYDB00615
スイッチオーバーを実行するには、次の手順を実行します。
-
アプリケーションが完全にシャットダウンされ、データベースにユーザーが接続されていないことを確認してください。
-
スイッチオーバーが開始する少なくとも30分前に、両方のDCで実行されているアーカイブUTLスクリプトを無効にします。テストが完了し、DBが適切な場所で実行されたら、アーカイブされたユーティリティスクリプトのコメントを解除します。
-
現在のプライマリDBで次のSQLクエリを実行します。
SELECT * FROM DBA_JOBS_RUNNING; (There should not be any sys owned jobs running) SELECT OWNER, JOB_NAME, START_DATE, END_DATE, ENABLED FROM DBA_SCHEDULER_JOBS WHERE ENABLED='TRUE' AND OWNER <> 'SYS'; (Data Guard Broker does not kill the jobs owned by sys.) -
job_queue_processesを設定します およびaq_tm_processesスイッチオーバーテストの完了後に元の値にリセットする必要があるため、元の値をメモしてください。 -
emagentを停止します プライマリDBで実行されています。 -
現在のプライマリDBで次のSQLクエリを実行します。
SELECT sid, username, status, program, inst_id FROM gv$session WHERE username is not null and status='ACTIVE' order by inst_id; (Validate and check the number of connections is active; a large number of active connections can lead to the switchover taking more time.) -
すべての
sqlplusからログアウトしますsysとして接続されているセッション 。 -
現在のプライマリDBで次のSQLクエリを実行します。
set linesize to 132 col value format a35 SELECT inst_id,name,value from gv$parameter WHERE name in ('job_queue_processes','aq_tm_processes'); (Check and validate the value of job_queue_processes and aq_tm_processes should be zero.) -
次のコマンドを実行して、DataGuardの構成を検証します。
DGMGRL> show configuration verbose ** STATUS Should show success, do not proceed if the status is not "success". -
Cluster Ready Services(CRS)のステータスをチェックして、すべてのリソースがオンラインで登録されていることを確認します。これは、ブローカーがこのプロセス中にDBをマウントおよびシャットダウンするためにCRSにハンドオーバーするためです。
-
プライマリDBでいくつかのログを切り替え、それらがスタンバイDBに適用されたことを確認します。
-
続行する前に、スイッチオーバーを実行し、DRCログとアラートログに障害がないか監視します。次のコマンドは、古いプライマリをスタンバイに変換してから、古いスタンバイをプライマリに変換します。
DGMGRL> switchover to ‘DDMPROD_STANDBY’; -
スイッチオーバーが完了したら、ログ転送およびログ適用サービスが稼働し、正しく機能していることを確認します。
MVDCのフェイルオーバーテストシナリオ
フェイルオーバーとは、プライマリDB(RACプライマリDBのすべてのインスタンス)に障害が発生し、スタンバイDBがプライマリの役割を引き継ぐように移行された場合です。フェイルオーバーは、次の場合に実行されます。
- プライマリDBの壊滅的な障害であり、プライマリDBをタイムリーに回復する可能性はありません。
- オブザーバーとスタンバイDBの両方がプライマリDBへのネットワーク接続を失ったとき、およびスタンバイDBが同期されていることを確認したとき 状態。
次のDB条件は、ファストスタートフェイルオーバーをトリガーします。
- プライマリサイトの障害
- 以下を含むプライマリDB条件:
- インスタンスの失敗
- RACの場合、最後に存続するインスタンス
- 最後に使用可能なインスタンスのシャットダウンアボート
- I / Oエラーのためにオフラインにされたデータファイル(オフラインデータファイルのためにフェイルオーバーを実行するときにしきい値は無視されます)
ネットワーク関連の状態は、プライマリとオブザーバー、およびプライマリとターゲットのスタンバイDB間のリンクがダウンしている場合にのみフェイルオーバーを引き起こす可能性があります。オブザーバーとスタンバイ間の接続は、構成が同期状態にあることをオブザーバーが確認できるようにするために必要です。 。
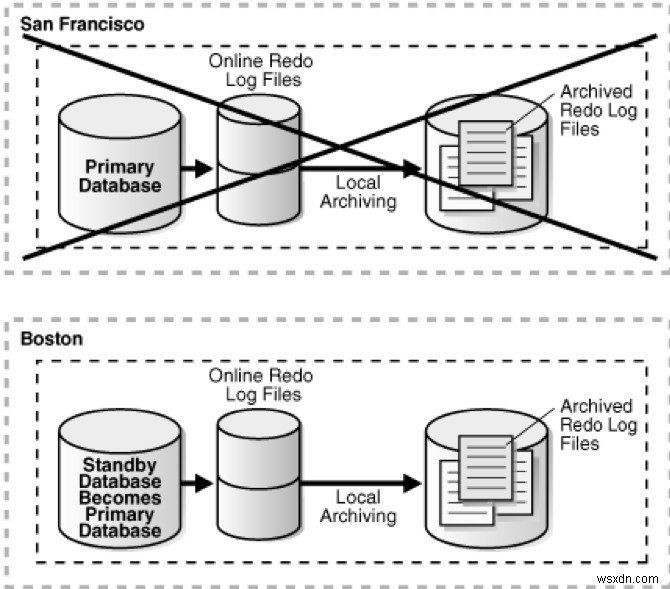
画像ソース: https://docs.oracle.com/cd/E11882_01/server.112/e41134/role_management.htm#SBYDB00615
MVDCは、効率的なリソースの使用、負荷分散、高可用性、および2つのDC間の自動切り替えを支援します。両方のDCが同時に(アクティブ-アクティブ)実行され、サービスの負荷を共有し、全体的なサービス機能を向上させます。 MVDCは、災害復旧のフェイルオーバーまたはアップグレード/メンテナンスの切り替えのためにデータベースを切り替えるために必要な人的介入を削減します。
[フィードバック]タブを使用して、コメントを書き込んだり、質問したりします。
専門家による管理、管理、構成で環境を最適化する
Rackspaceのアプリケーションサービス(RAS) 専門家は、幅広いアプリケーションポートフォリオにわたって次の専門的かつ管理されたサービスを提供します。
- eコマースおよびデジタルエクスペリエンスプラットフォーム
- エンタープライズリソースプランニング(ERP)
- ビジネスインテリジェンス
- Salesforceの顧客関係管理(CRM)
- データベース
- メールホスティングと生産性
お届けします:
- 偏りのない専門知識 :私たちは、即時の価値を提供する機能に焦点を当てて、お客様の近代化の旅を簡素化し、導きます。
- 狂信的な経験 ™:最初にプロセスを組み合わせます。テクノロジーセカンド。包括的なソリューションを提供するための専用のテクニカルサポートを備えたアプローチ。
- 比類のないポートフォリオ :豊富なクラウドエクスペリエンスを適用して、適切なテクノロジーを適切なクラウドに選択して導入できるようにします。
- アジャイルデリバリー :私たちはあなたがあなたの旅の途中であなたに会い、あなたの成功と一致します。
今すぐチャットして始めましょう。
-
iCloud データ リカバリ サービスとその設定方法
iCloud データへのアクセスを失うことは悪夢のシナリオです。それでも、iOS 15 では、Apple は iCloud Data Recovery Service と呼ばれる新機能を追加しました。これは、最悪の事態が発生したときにデータの (一部) を取り戻すことができます。 iOS や macOS でのセットアップは簡単です。時間をかけて作業すれば、いつの日か自分に感謝することでしょう。 iCloud データ復元サービスとは iCloud データ復旧サービスは、写真、メモ、ドキュメント、デバイスのバックアップ、その他ほとんどの種類の暗号化されたデータへのアクセスを取り戻すことができる
-
データ センター用のフラッシュ ストレージの必要性
テクノロジーと時代の変化に伴い、データを保存するためのさまざまな代替手段が利用できるようになりました。最初の段階ではフロッピー ドライブが使用され、続いて CD と DVD がメディアの書き込みに使用されました。しかし、私たちが話しているように、これらのデバイスは絶滅しつつあります。最新のラップトップ モデルを含む、今日の主流デバイスのほとんどには、CD/DVD ドライブが内蔵されていません。 市場の誇大宣伝と人々の言葉によると、今後数年のうちに、完全な世界のデータがクラウドに保存されるようになります。しかし、これは完全に正しいとは言えません。ビジネスは、クラウドが提供するデータよりも詳細に