データを保護:スプレッドシートのエラーを避けるために生データをそのままの状態に保ちます

スプレッドシートでよくある間違いは、生データを変更することです。誰かがデータの唯一のコピーで「1 つだけ修正」したり、誤って元のデータセットを上書きしたりすると、混乱を元に戻すのに何時間も費やすことになります。誰もが経験したことがあります。簡単な修正が情報の損失と疑わしい結果の悪夢に変わるのです。
これを避けるには、「生データには触れない」という黄金律に従ってください。元のデータセットを変更せずにコピーまたは派生バージョンで作業することで、エラーを最小限に抑え、トレーサビリティを維持し、ワークフローの再現性を高めることができます。
このチュートリアルでは、自分自身を救うことができる簡単なワークフローの調整について説明します。
このワークフローが重要な理由
- エラー防止: 生データは真実の情報源です。直接変更すると(行の削除やセルの上書きなど)、特に大規模または複雑なデータセットの場合、取り返しのつかない間違いが発生する可能性があります。
- 再現性: 分析を再検討したり、他のユーザーと共有したりする必要がある場合、未加工の生データがあれば、推測に頼らずに手順をたどることができます。
- バージョン コントロール ライト: 未加工データを読み取り専用として扱うことは、基本的なバージョン管理を模倣し、「データ災害」から保護します。
- 効率: データをクリーニングして別のシートに変換すると、すべてが整理された状態に保たれるため、後で繰り返したり自動化したりすることが容易になります。
このアプローチは、一貫性のない書式設定、重複値、欠落値を持つ CSV ファイルをインポートする場合など、乱雑なデータセットに特に役立ちます。元のファイルを編集する代わりに、それを複製して新しいシートにクリーンアップします。
この段階的なワークフローを構築してみましょう。
ステップ 1:未加工データをインポートする
- 新しいスプレッドシート ファイルを開く
- 「Raw_Data」という名前の新しいシートを作成します
- 生のデータセットをインポートする
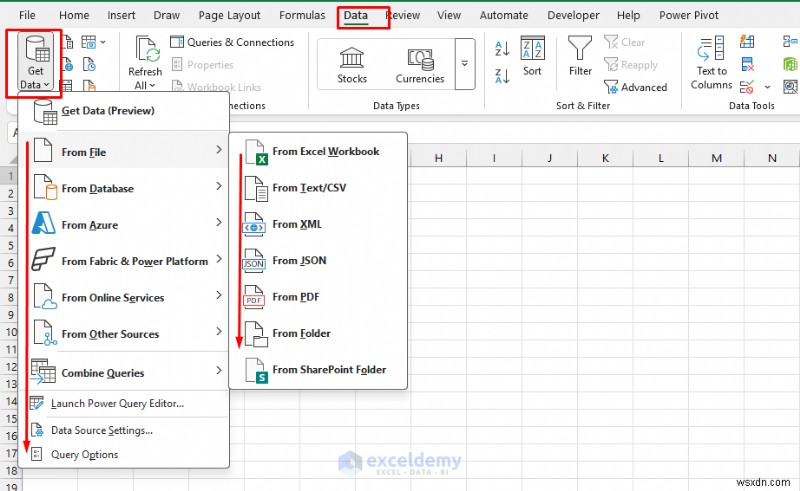
- データに移動します。 タブ>> データの取得を選択します>> ソースを選択してください
重要なルール:
インポートしたら、誤って編集しないようにこのシートをロックしてください。
- シート タブを右クリックし、シートの保護を選択します。
- 必要に応じてパスワードを設定します
- 上部に「編集しないでください。ソース データのみです。」という注記を追加します。
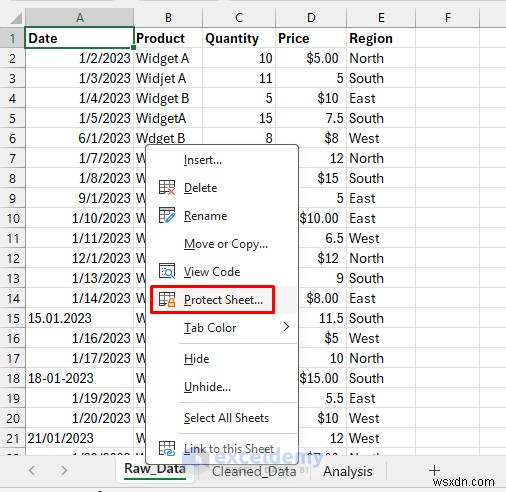
このシートは現在、あなたのアンタッチャブルなアーカイブです。ここでセルを編集しないでください。
ステップ 2:クリーニング シートの作成
- 「Cleaned_Data」という名前の新しいシートを追加します
- 人的ミスを避けるために、生データを手動でコピーするのではなく参照する
- 数式を使用してデータを動的に取得する
- セル A1 に次の数式を挿入します。
- ドラッグして範囲を満たすか、配列数式を使用して効率を高めます:
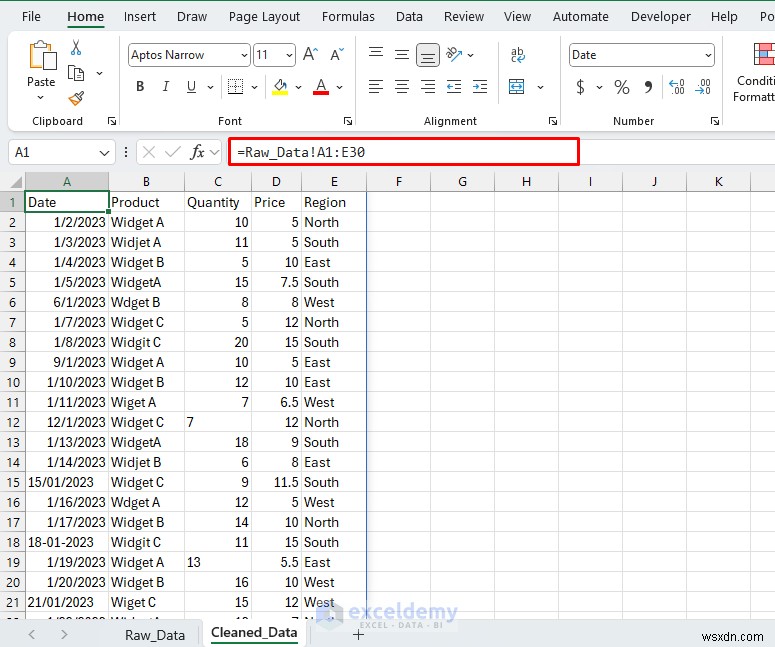
この式はリンクされたコピーを作成します。これで、オリジナルに影響を与えることなく、このシートをクリーニングできるようになります。
ステップ 3:新しいシートのデータをクリーニングする
次に、このシート内の乱雑なデータを整理します。列ごとに作業するか、バッチ操作用の組み込みツールを使用します。
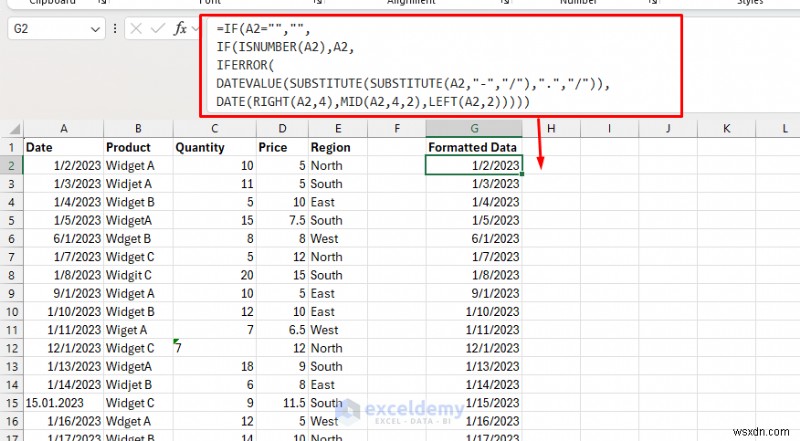
一貫性のない形式の修正 (日付など):
- 列 A の日付が矛盾していると仮定します。
- 新しい列で、数式を使用して日付を標準化します。
形式:
=IF(A2="","", IF(ISNUMBER(A2),A2, IFERROR( DATEVALUE(SUBSTITUTE(SUBSTITUTE(A2,"-","/"),".","/")), DATE(RIGHT(A2,4),MID(A2,4,2),LEFT(A2,2)))))
タイプミスや不一致への対処:
- PROPER() などの数式を使用します。 テキストの大文字化を標準化する
タイプミスの修正:
- Ctrl + H を押します。 検索と置換を開きます。 ダイアログボックス
- 間違ったエントリを正しい値に置き換えます
- [すべて置換] をクリックします。
重複の削除:
- 必要に応じて列を並べ替えます
- データに移動します。 タブ>> 重複の削除を選択します
欠損値の処理:
- 次のような数式を使用して論理的に空白を埋めます。
必要に応じて派生列を追加する:
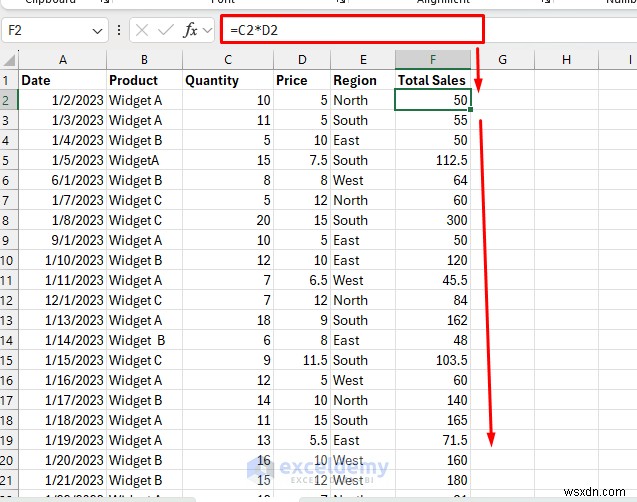
- 総売上高:
- クリーンアップしたら、新しい列をコピーし、元の乱雑な列に値として貼り付けます
- 右クリック>> 形式を選択して貼り付けを選択します>> 値を選択します
プロセス全体を通じて、変更内容を別の「メモ」シートに記録するか、インライン コメント ([挿入]>> [コメント]) を使用して記録します。
ステップ 4:レポート シートの作成 (データの分析)
分析を新しいシートに分割することをお勧めします。別のシートを追加し、「分析」という名前を付けます。 「Cleaned_Data」シートのデータを数式、ピボットテーブル、クエリに使用します。
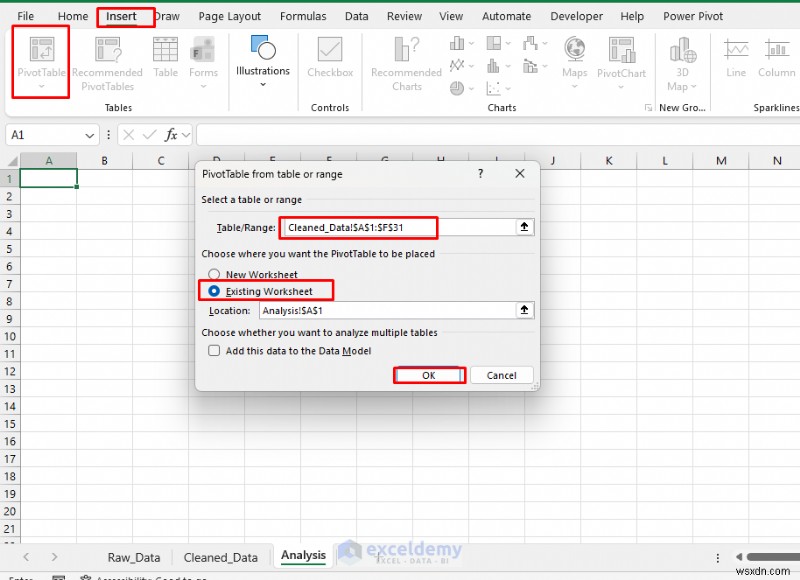
ピボットテーブルの作成:
- 挿入に移動します タブ>> ピボットテーブルを選択します
- 「Cleaned_Data」からソース範囲を選択します
- 場所を選択します>> [OK] をクリックします。
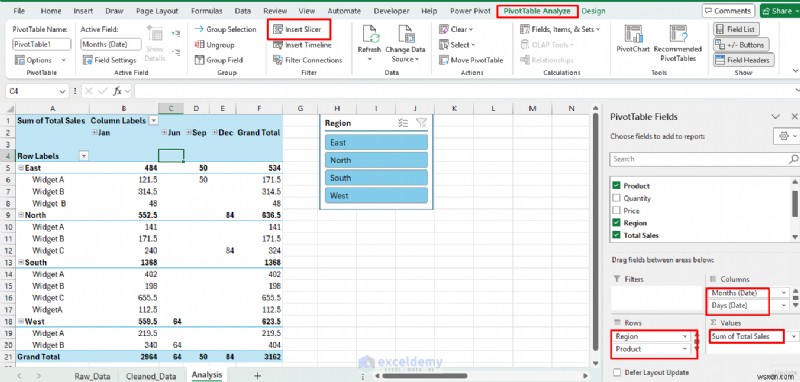
毎月の概要を作成する:
- ピボットテーブル フィールドから リスト
- 領域をドラッグします と製品 行へ エリア
- 日付をドラッグします コラムへ エリア
- 総売上高をドラッグします 価値観へ エリア
スライサーの挿入:
- ピボットテーブル分析に移動します。 タブ>> スライサーの挿入を選択します。
- 地域を選択します
- [OK] をクリックします。
これで、レポートは乱雑なエクスポートではなく、クリーンなデータに依存するようになります。これにより、クリーニングが分析情報から切り離され、クリーニング ロジックを更新した場合に簡単に更新できるようになります。
ステップ 5:「リフレッシュ」ルーチンを作成する (時間を節約する習慣)
新しいエクスポートが到着するたびに、次のようになります。
- 「Raw_Data」シートのデータを置き換えます(同じヘッダーを維持します)
- しないでください 「Raw_Data」シートの値を編集します
- 「Cleaned_Data」シートを更新します
- 自動更新のタイミングを設定するか、手動で更新する
- データに移動します。 タブ>> [すべて更新] をクリックします。
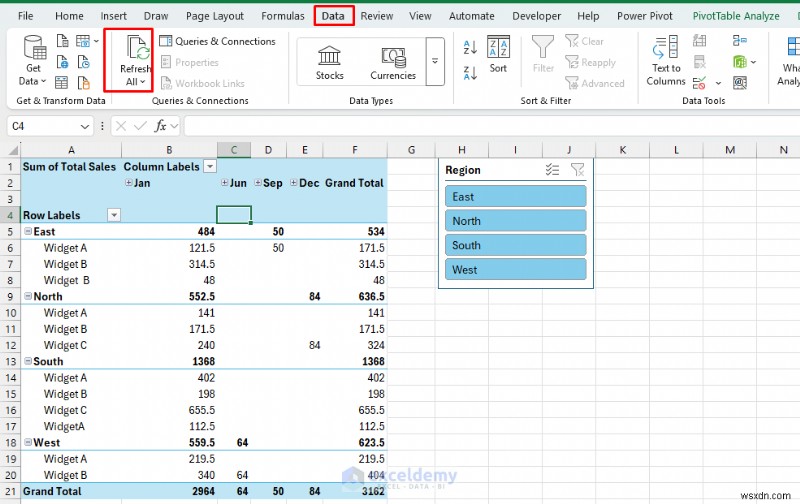
これにより、週次レポートが手動のクリーンアップ プロジェクトではなく、反復可能なプロセスに変わります。
ステップ 6:ファイルの保存とバージョン管理
- 名前を付けて保存: 「Project_Data_v1.xlsx」のようなファイル名を使用し、時間の経過とともにバージョン番号を増やします
- コラボレーションの場合: ワークフローの整合性を維持するために読み取り専用バージョンを共有する
- 自動化: Excel での Power Query を学習して、生のデータをクエリに読み込み、生のシートに触れることなく自動的にクリーンアップして更新する
概要
これらの手順に従うことで、分析の柔軟性を維持しながら生データを保護するワークフローを構築できます。未処理のエクスポートを 1 つのシートにそのまま保持し、別のシートでクリーニングを実行します。特に乱雑なデータセットを扱う場合、ワークフロー全体が安全になり、更新が簡単になり、信頼性が大幅に高まります。
次のデータセットを小規模から始めれば、レポート プロセスがどれほどスムーズになるかすぐに気づくでしょう。
ソリューション付きの高度な Excel 演習を無料で入手しましょう!-
MicrosoftPublisherでビルディングブロック機能を使用する方法
ビルディングブロック Microsoft Publisher は、事前にフォーマットおよびカスタマイズされたテキストおよびフォーマット技術のブロックです。ビルディングブロックは、ユーザーが作業用のコンテンツを作成する時間を節約します。 Publisherでは、ビルディングブロックはデフォルトでテンプレートに保存されます。ユーザーは簡単にカスタマイズした変更を加えることができます。 パブリッシャーのビルディングブロック このチュートリアルでは、ページパーツのビルディングブロック、カレンダーのビルディングブロック、境界線とアクセントのビルディングブロック、および広告のビルディングブロックの使
-
Wordでぶら下がっているインデントを修正する方法
Microsoft Wordのぶら下がっているインデントを修正するためにどのくらいの時間を費やしましたか? 「なぜ、ああ、なぜ、最初の行がすべての段落の左側に飛び込み台のようにぶら下がっているのですか?なぜ誰かがそのように段落をフォーマットしたいと思うのでしょうか?」 ユーザーは、MicrosoftWordに組み込まれている3つのインデントスタイルから選択できます。それぞれを選択する理由、インデントスタイルを選択してドキュメントに適用する方法、および希望どおりに機能しないぶら下がっているインデントを修正する方法について説明します。 MicrosoftWordの3つのインデントスタイル