AI 推論パフォーマンスに影響を与える目に見えないバージョニングの問題
モデルは後退しませんでした。バグを出荷したわけではありません。プラットフォームがそれを変えました。
実稼働 AI アプリケーションは、ほとんどのチームが制御を引き継いだことに気づいていないもの、つまりエンドポイントの背後にあるモデルの動作に依存しています。実際には、モデルは固定された成果物ではありません。動くターゲットです。競争力を維持するために、プラットフォームは継続的に重みを更新し、量子化レベルを交換し、推論エンジンをアップグレードし、ハードウェア全体でトラフィックを再ルーティングし、場合によってはエンドポイント名を変更せずにモデルを完全に置き換えます。
それが起こると、アプリケーションもそれに伴って変化します。シフトを出力します。プロンプトが機能しなくなります。慎重に調整された動作は低下します。そして、通常は変更ログからはわかりません。ユーザーからわかります。
これが最新の AI インフラストラクチャの隠れたリスクです。つまり、いつでも変更される可能性のあるシステムの上に構築しているため、明日の「同じモデル」が今日テストしたのと同じモデルであるという保証はありません。この記事では、それが実際にどのようなものなのか、なぜそれが起こるのか、そしてなぜほとんどのプラットフォームがそれをうまく解決できていないのか、そしてそれに対処するためにチームが何をしているのかを探ります。
出荷されたモデルは、現在実行しているモデルではありません。
重要なポイント
- 「モデルのバージョニング」は設計上不完全です。単一のモデルのように見えても、実際には重み、推論エンジン、ハードウェア、ルーティング、ガードレールなどの可動部品のスタックであり、これらはすべて、エンドポイント名を変更せずに個別に変更できます。
- サイレントな変更は実際の運用上のリスクを生み出します。これらのアップデートは再現性を損ない、迅速な調整を無効にし、チームがプラットフォームの可視化やモニタリングを通じてではなく、ユーザーに影響を与えた後でのみ検出することが多い回帰を引き起こします。
- ギャップは技術的なものではなく、透明性と所有権です。プラットフォームはすでにこれらの変更を内部的に追跡していますが、公開していません。 AI が本番環境に不可欠なものになると、フルスタックのバージョニング、変更ログ、再現性の保証がプラットフォーム選択の重要な基準になります。
バージョン管理の問題の形態
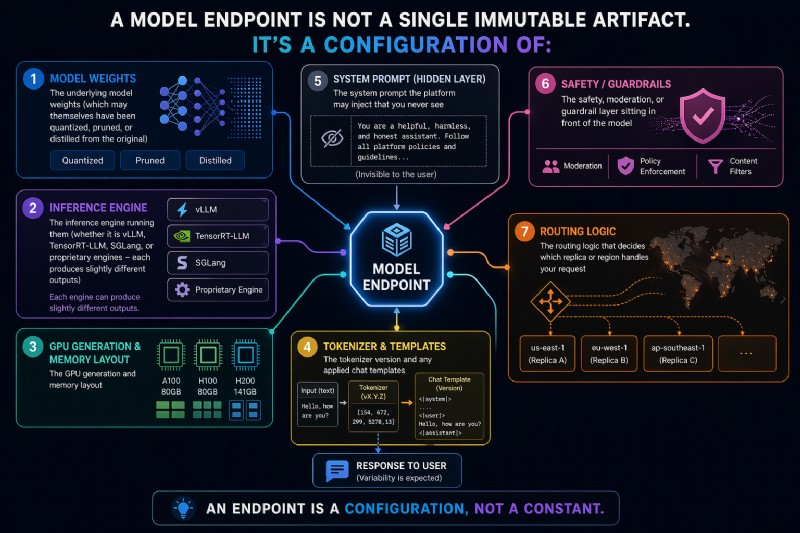
「同じモデル」の実際の意味
モデルのエンドポイントは、単一の不変のアーティファクトではありません。これは次の構成です:
- 基礎となるモデルの重み(それ自体が量子化、プルーニング、またはオリジナルから抽出された可能性があります)
- それらを実行する推論エンジン (vLLM、TensorRT-LLM、SGLang、または独自のエンジンのいずれであっても、それぞれわずかに異なる出力を生成します)
- GPU の世代とメモリ レイアウト
- トークナイザーのバージョンと適用されたチャット テンプレート
- プラットフォームが挿入する、決して目にすることのないシステム プロンプト
- モデルの前に座っている安全、モデレーション、またはガードレールのレイヤー
- どのレプリカまたはリージョンがリクエストを処理するかを決定するルーティング ロジック
これらはモデル名を変更せずに変更できます。理解するのに重要なことは、それらのほとんどは実稼働アプリケーションの存続期間全体にわたって定期的に変更されるということです。通常、基盤となるテクノロジーは変更のたびに改善されるため、この変更は AI 製品の開発にとって不可欠です。この漸進的な変化は、AI ソフトウェア業界の中核部分です。
静かな変化の 3 つのカテゴリ
最初のカテゴリは、エンドポイントが指す重み付けを変更するプラットフォームの明示的なバージョン更新です。たとえば、「GPT-4」は時間の経過とともに複数の異なるモデルになり、Claude エンドポイントは定期的に更新されます。ホスト型プラットフォーム上のオープンソース モデルのエンドポイントは、多くの場合、アップストリーム リリースを自動的に追跡します。
2 番目のカテゴリはインフラストラクチャ レベルの変更で、重みは同じままですが、サービス スタック内の何かが変更されます。この例としては、次のような場合が挙げられます。
- 推論エンジンがアップグレードされる
- コスト上の理由により量子化レベルが変更される
- ルーティングの決定により、同等であるはずの異なる展開間でトラフィックが移動します。
3 番目のカテゴリは、プラットフォーム レベルの追加による動作の変更です。新しいモデレーション レイヤー、システム プロンプトの変更、安全フィルターの追加、チャット テンプレートの変更などです。これらのシナリオでは、モデルは同じですが、モデルが受け取るものとユーザーが受け取るものは異なります。
各カテゴリが実際にモデルの動作にどのような影響を与えるか
サイレント回帰問題
サイレント回帰とは、サービング スタック内のどこかで、発表も文書化もバージョン バンプにも関連付けられていない変更によって引き起こされるモデルの出力品質の低下です。エンドポイントのモデル名は同じです。 API コントラクトも同様です。送信したリクエストは、先月送信したものとバイトが同一です。しかし、応答の品質は、時には微妙に、時には急激に低下しており、プラットフォームの公開画面にはその理由を示すものは何もありません。
メカニズムはほとんどの場合、以前の 3 つの変更カテゴリの 1 つです。つまり、重みが静かに更新されたか、インフラストラクチャ内の何かが変更されたか、プラットフォーム レベルのレイヤー (新しいガードレール、改訂されたシステム プロンプト、強化されたモデレーション フィルター) が追加または変更されました。外から見ると、3 つはすべて同じに見えますが、出力は悪化しましたが、プラットフォームはそれを教えてくれませんでした。内部から見ると、それらは根本原因が異なり、修正も異なるため、プラットフォームの協力がなければそれらを区別する方法はありません。
サイレント回帰が通常のモデル ドリフトと異なる点は、情報の非対称性です。プラットフォームは何が変わったかを知っています。あなたはしない。また、モニタリングではほぼ確実にゴールデン データセットの出力品質ではなく、稼働時間、レイテンシ、エラー率を測定しているため、回帰は所有するダッシュボードに表示される前にユーザーに伝播します。回帰が本物であることを確認し、それを独自のコードではなくモデルに分離し、サポート チケットをオープンするまでに、通常、プラットフォームはすでに次のサイレント変更に移行しています。結局、半分の情報を使って移動ターゲットをデバッグすることになりますが、ユーザーは上流のどこかで行われた、知らされていなかった意思決定のコストを負担することになります。
これは、プラットフォームが問題を即座に解決する情報を保持しているにもかかわらず、それを共有しないことを選択している唯一の問題であるため、このセクションの 4 つの問題の中で最悪です。再現性の失敗、即時負債、評価から本番へのドリフトはすべて、チームが少なくとも自分たちで診断できる症状です。サイレント回帰とは、必要な診断ツールが API の反対側にある回帰です。
再現性の問題
一般的な AI 導入タイプの優れた例として GPT モデルは本質的に確率的ですが、同じプロンプトで同じモデルを使用すると同様の答えが得られることが期待できます。ただし、前述の変更のいずれかが発生すると、昨日得られた出力が今日は再現できない可能性があります。これが再現性の問題の核心です。モデルがどのように動作するかという期待は、これらの変更によって無効になる可能性があります。
自動評価を実行したり、モデルのバージョンを相互に比較したりするアプリケーションの場合、これは、同じシードが与えられた場合、同一の入力が同一の (確率モデルの場合は類似の) 出力を生成するという基本的な前提を破ることになります。基礎となるスタックが移動している場合、温度がゼロであっても実際には決定論は得られません。プロンプト エンジニアリング負債の問題
チームは、特定のモデルの癖に合わせてプロンプトを調整し、ユーザーのニーズをより適切に満たせるように最適化するために、一度に数週間を費やすことがよくあります。そのモデルが黙って交換または更新されると、調整作業はすべて部分的な負債に変わります。あるモデルの障害モードを処理するために慎重に構築されたプロンプトが、わずかに異なる障害モードを持つわずかに異なるモデルに遭遇すると、ユーザーが遭遇する最終的な動作は変化します。
評価から本番環境へのドリフト問題
もう 1 つの一般的なシナリオは、テスト セットに対してモデル バージョンを評価し、その後実稼働環境に出荷するというものです。ただし、実稼働エンドポイントは、エンドポイント上の名前が同じであっても、評価したモデルを使用しなくなりました。繰り返しになりますが、これは最終製品の動作に顕著な影響を与える可能性があります。
プラットフォームが実際に行うこと
このセクションでは、公開ドキュメントと観察可能な動作に基づいて、主要な推論プラットフォームがバージョニングをどのように処理するかを説明します。
OpenAI スタイルのバージョニング
OpenAI はスナップショットを明示的に固定し (gpt-4-0613、gpt-4o-2024-08-06)、それらをターゲットにできるようにします。エイリアス化されたエンドポイント (gpt-4、gpt-4o) は、時間の経過とともに変化する現在のデフォルトを指します。スナップショットを固定する方法を知らないチームは、最新のバージョンを取得し、エイリアスがその下に移動する可能性があります。
ただし、OpenAI はさまざまな理由からモデルを変更します。その一例が「おべっか事件」です。 GPT-4o は「過度にお世辞または好意的であり、しばしばおべっかだと言われている」と伝えられ、OpenAI は最終的にモデルを非推奨にする前に一連のロールアウト修正を発行しました (ソース)。最終的にモデルが廃止されると、人々はモデルの喪失を嘆き、さらに波紋を広げました。
おべっか事件を有益なものにしているのは、性格の変化そのものではなく、エンドポイント契約について明らかになった点です。おべっかのロールアウト前、ロールアウト中、ロールアウト後に gpt-4o を呼び出したチームは、同じエンドポイント名を使用していましたが、意味のある異なるモデルを使用していました。おべっか以前のバージョンに合わせて調整されたカスタマー サポート ボットは、運用期間の途中でより温かみのある、より快適なモデルに遭遇し、その後 OpenAI が軌道修正したときに 3 番目の動作プロファイルに遭遇し、モデルが最終的に非推奨になったときに 4 番目の動作プロファイルに遭遇したでしょう。これらの移行では、顧客側でコードを変更する必要はありませんでした。それらのいずれも、エンドポイント文字列のバージョンバンプをトリガーしませんでした。同じ 2 行の API 呼び出しによって、数か月にわたって 4 つの異なる動作体制が生成されました。ほとんどのチームが得た唯一のシグナルは、ユーザーが製品の感触が違うと言ったことだけでした。OpenAI のアプローチは、OpenAI がまだサービスを提供している限り、古いモデルのバージョンを使用できるオプションが提供されているため、ほとんどのチームよりも優れています。ただし、選択は手動で行われるため、モデルを古いバージョンに変更する方法を知るために調査を行わない人にとっては困難であることに注意する必要があります。
Anthropic のアプローチ
Anthropic は日付付きのモデル識別子 (claude-opus-4-5-20251101 スタイル) を使用します。ピン留めが機能します。ただし、プラットフォーム レベルのシステム プロンプト インジェクションと安全層はモデルのバージョンとは独立して進化するため、別の日に同じ固定モデルに対する 2 つのリクエストが異なる動作をする可能性があります。これは、モデル内ではなく周囲で何が起こっているかが原因です。これは透明性においては一歩前進ですが、コア モデルの選択は OpenAI の選択と同様のままです。
Anthropic からのサイレント回帰の一例は、最近、注目すべき Github Issue で発生しました。そこでは、大手 AI 開発者が、複雑なエンジニアリング作業における Claude Opus モデルの明らかな「弱体化」を批判しました。彼らは、クロードが指示を無視し始め、正しくない「最も簡単な修正」を主張し、要求されたアクティビティとは逆のことを行うようになったと報告し、モデルが指示に反して完了を実行したと主張しました。これらすべては、使用されているモデルの変更が報告されていません。このサイレントな変更は同じスレッドでクロードの開発者によって反論されましたが、コメントへの応答に基づいて、他のユーザーによって変更が行われたということで広く同意されています。
「同じモデル」は常にマーケティングの抽象概念でした。
ホストされたオープンソース モデル
オープンソース モデルをホストするプラットフォーム (Baseten、Fireworks、Togetter、DigitalOcean、Nebius Token Factory、Modal) は、多くの場合、どの特定の量子化、どの推論エンジンのバージョン、または実際にリクエストを処理しているデプロイメント構成を公開せずに、「llama-3.1-70b-instruct」など、基礎となるモデルにちなんでエンドポイントに名前を付けます。モデルのパフォーマンスは同じ名前であってもプラットフォームごとに異なるため、これは大きな問題となる可能性があります。通常、これらの更新は、モデルのバージョンが変更されても通知されません。オープンソース ホスティング プロバイダーに関しては、サーバーレス推論シナリオでの基礎となるモデルの展開に対する変更について調査する責任はユーザーにあります。カスタム デプロイメントでは、状況が少し異なります。
カスタム展開
Modal や Baseten などのプラットフォームに独自のモデルをデプロイすると、バージョン管理ストーリーを所有することになります。これは、再現性、生産管理、および下流製品のモデル変更の管理にとって最もクリーンな状況ですが、モデルのライフサイクルを管理するという運用上の負担を自分で負うことを意味します。変更の管理に必要な開発者の時間が急増するため、スケーリングの際にはこのトレードオフを考慮することが重要です。
チームはそれに対して何をしているか
以下のセクションでは、チームが採用した一般的な回避策について説明します。どれも問題を完全に解決するものではありませんが、それぞれが正しい方向への手順を提供します。可能な場合はスナップショットを固定します。
プラットフォームが日付の付いたスナップショットを公開する場合、それらを固定することは一大事です。ただし、すべてのプラットフォームがそれらを公開しているわけではなく、固定されたスナップショットは最終的には非推奨になります。 AI プロダクトのモデルをホストするプラットフォームを慎重に選択するときは、これを考慮してください。そうしないと、バックアップ計画なしでモデルが失われる状況に陥る可能性があります。
ゴールデン データセット回帰テスト
ゴールデン データセット回帰テストでは、実稼働エンドポイントを介して一定の入力セットをスケジュールに従って実行し、出力を既知の正常なベースラインと比較します。このプロセスにより、品質の回帰やその他のモデルの重大な動作の変化を簡単に把握できますが、維持にコストがかかり、観察できると考えられるパターンしかカバーできません。定期的にゴールデン データセットの回帰テストを行うことで、製品の動作の変化をあなたより先に顧客が発見してしまったという恐ろしい知らせを防ぐことができます。
出力のサンプリングとロギング
これは、後で分析するために、実稼働リクエストと応答のサンプリングされた割合を記録するプロセスです。これにより、事後にドリフトを検出できますが、サンプリング、ストレージ、分析インフラストラクチャを自分で構築する必要があります。
シャドウ展開
現在の実稼働エンドポイントと候補となる新しいエンドポイントに対して同じリクエストを同時に実行し、出力を比較して、それがモデルの動作にどのような影響を与えるかを確認できます。これは、加えた変更を評価するのに非常に効果的です。プラットフォームがあなたのもとで行う変更には役に立ちません。
モデルの自己ホスト
究極の制御手段:制御するインフラストラクチャ上でモデルを自分で実行します。これにより、使用している重み、推論エンジン、量子化、その他出力に影響を与える可能性のあるものを完全に制御できるようになります。これにより、バージョン管理の問題がモデル ホスティングの運用上の負担と引き換えになります。そのため、ほとんどのチームがそれを行わないのです。
バージョニングに実際にかかる費用
観察可能性税
プラットフォームでは評価インフラストラクチャが提供されないため、出力の品質を重視するすべてのチームが独自の評価インフラストラクチャを構築しています。これは業界全体で行われている重複した作業です。プロンプト回帰フレームワーク、出力差分ツール、品質監視システムなどはすべて、実際の製品を構築したいアプリケーション チームによって構築されています。信託税
モデルが変更されたために AI 機能が壊れた場合、ユーザーは「AI が信頼できない」と「プラットフォームが黙ってモデルを更新した」の違いがわかりません。あなたの製品は、上流で行われた意思決定による評判コストを吸収します。
移民税
プラットフォームの切り替えを検討しているチームは、API の違いだけでなく、異なるプラットフォーム上の同じ名前のモデル間の動作の違いも考慮する必要があります。 Fireworks の「Llama 3.1 70B」は Together の「Llama 3.1 70B」と必ずしも同じではありません。量子化が異なるか、異なる推論エンジンを使用するか、または完全に異なるガードレール スタックを備えている可能性があります。この明確さの欠如により、広範なテストを行わずにプロバイダーを切り替えることが困難になります。
もっと良く見えるもの
2026 年の本格的な推論プラットフォームは、クラウド プロバイダーが稼働時間を扱うのと同じように、モデルの動作をブラック ボックスではなく契約上の表面として扱う必要があります。
現状は技術的な限界ではなく、情報開示のギャップです。重み、エンジン、量子化レベル、ルーティングの決定を追跡するためのインフラストラクチャはすでに存在しています。プラットフォームはそれを公開しないだけです。
実際の動作は次のとおりです。
<オル>完全なバージョン識別子今日のモデル名は、重量を識別する場合があります。完全なサービス構成を特定する必要があります。完全なバージョン文字列は、エンドポイントから出力されるものを変更できるすべてのものをキャプチャします:重み (量子化レベル付き)、推論エンジンとバージョン、ハードウェア生成、トークナイザーのバージョン、チャット テンプレート、プラットフォームに挿入されたシステム プロンプトまたはガードレール層。 llama-3.1-70b-instruct.fp8.vllm-0.6.3.h100.tmpl-v2.guardrail-v4 のようなものは醜いですが正直です。チームは、依存するコンポーネントを固定し、他のコンポーネントが変更されたときに通知を受け取ることができます。
スタックプラットフォーム全体の変更ログフィードは、モデルの重みを更新するときにリリースノートを公開します。 vLLM をアップグレードしたり、コスト上の理由で量子化を変更したり、リージョン間のトラフィックを再ルーティングしたりするときに、ほとんど何も公開しません。適切な変更ログ フィード (理想的には機械可読) は、タイムスタンプと影響を受けるエンドポイントを含む、サービス提供スタックのすべての層をカバーします。チームは、特定の固定設定の変更をサブスクライブし、ユーザーからの苦情の後ではなく、ロールアウト前にアラートを受信できる必要があります。
明示された保持期間による再現性の保証ピン留めされたスナップショットには何らかの意味があるはずです。プラットフォームは、指定された保持期間 (たとえば 12 か月または 24 か月) を守る必要があります。この期間中、ピン留めされた構成は、重みだけでなくスタック全体について、温度ゼロでの同一入力に対してバイト同一の出力を返します。その期間が終了すると、チームは事前通知と移行パスを受け取ります。これが、データベースとオペレーティング システムがバージョン管理を処理する方法です。推論が異なる理由はありません。
プラットフォームが提供する回帰テスト真剣なチームはすべて、同じ評価インフラストラクチャを個別に構築しています。プラットフォームはこれを最上級の機能として提供する必要があります。つまり、ゴールデン データセットを登録し、固定されたエンドポイントに対してスケジュールに従って実行し、出力が設定したしきい値を超えたときにアラートを受け取ります。スナップショット間の差分テストにボーナス ポイントが付与されるため、チームは強制的に移行するかどうかを評価できます。
何がいつ変更されるかについての正直な文書このリストの中で最も難しい項目です。これは、プラットフォームが「同じモデル」が常にマーケティングの抽象概念であることを認める必要があるためです。ドキュメントでは、モデルのバージョンとは関係なく変更できるすべてのレイヤーに名前を付け、各レイヤーの変更に関するプラットフォームのポリシーを示し、顧客への通知方法を説明する必要があります。これにより、チームは、どのプラットフォームがリスク許容度に適合するかについて情報に基づいた決定を下すことができます。
購入者のチェックリスト
現在推論プラットフォームを評価している場合は、署名する前にベンダーに次の質問をしてください。
- 「特定のモデルのスナップショットを固定できますか?そのスナップショットはどのくらいの期間使用可能であることが保証されますか?」
- 「固定したバージョン文字列は、推論エンジン、量子化、ハードウェアをカバーしますか? それとも重みのみをカバーしますか?」
- 「サービススタックのレイヤーが変更された場合の通知ポリシーは何ですか?」
- 「目に見えないシステム プロンプト、ガードレール、またはモデレーション レイヤーを挿入しますか? オプトアウトできますか?」
- 「同じリクエストを温度ゼロで 1 か月おきに 2 回実行した場合、出力の同一性はどのように保証されますか?」
- 「回帰テスト ツールは提供されていますか? それとも自分で構築しますか?」
- 「固定されたスナップショットが非推奨になった場合、どれくらいの通知が届きますか?また、移行パスは何ですか?」
プラットフォームがこれらのほとんどに明確に答えられない場合、それが答えになります。あなたは、あなたの下で変化する可能性のあるインフラストラクチャの上に構築しており、それをユーザーに説明するのはあなたです。
商業上の現実
上記はどれも技術的に難しいものではありません。それを難しくしているのは商業的なものです。プラットフォームは物事を静かに変更できる柔軟性の恩恵を受けており、代替手段であるセルフホスティングは運用コストが高いため、顧客は歴史的にそれを受け入れてきました。 AI機能がデモから人々が依存する製品に移行するにつれて、この取引は悪化し始めています。これを最初に解決するプラットフォームが、実際に信頼性を重視する市場セグメントを獲得することになります。そうでないチームは、ユーザーから発見されたリグレッションをチームにサイレントに送信し続けることになります。
終わりの言葉
業界は、名前付きアーティファクトが安定したアーティファクトであるという、従来のソフトウェアから借用した前提に基づいて AI インフラストラクチャを構築しました。その仮定は成り立ちません。重み、エンジン、ルーティング、ガードレールはすべて、エンドポイントの名前とは無関係に変更され、「モデル バージョン」が意味するものと実際に保証されているものとの間にギャップがあり、本番 AI が静かに壊れます。
これは予測です。今後 18 か月以内に、サイレント バージョニングは単なるエンジニアリングの問題ではなく、調達の問題になるでしょう。推論能力を購入するチームは、上記のチェックリストの質問をし始めており、それに答えることができるプラットフォームは、他のチームが負けたことさえ知らない取引を獲得し始めるでしょう。 「再現性 SLA」、「スタックレベルの変更ログ」、および「スナップショット保持期間」がエンジニアリングのウィッシュリストからエンタープライズ契約に移行することが期待されます。ドキュメントの詳細な脚注ではなく、製品機能としてフルスタックのバージョン文字列を公開する最初のプラットフォームは、他のプラットフォームに対する顧客の期待をリセットします。
現在、推論に基づいて構築しているチームにとって、実際的な問題は、サイレント変更が製品に影響を与えるかどうかではありません。それは。問題は、モニタリングから発見するのか、独自の回帰テストから発見するのか、それとも月曜日の朝のユーザーからの苦情から発見するのかということです。これら 3 つのうちのどれになるかは、ほぼ完全に、次のサイレント アップデートが適用される前に行う決定によって決まります。
出荷されたモデルは、現在実行されているモデルではありません。それに応じて構築します。
DigitalOcean は、AI 製品を大規模に構築するのに役立ちます。
 この作品は、クリエイティブ コモンズ 表示 - 非営利 - 継承 4.0 国際ライセンスに基づいてライセンスされています。
この作品は、クリエイティブ コモンズ 表示 - 非営利 - 継承 4.0 国際ライセンスに基づいてライセンスされています。
-
データ構造における2つの最大HBLTの融合
メルド戦略は、再帰を使用して簡単に実行できます。 AとBが2つのHBLTであり、それらが融合するとします。それらの1つが空の場合は、最終結果として別の1つを作成するだけです。空のHBLTがない場合は、2つのルートの要素を比較する必要があります。より大きな要素を持つルートは、融合したHBLTのルートになります。 Aのルートが大きいとします。そして、それはその左側のサブツリーがLです。Cが最大HBLTであると仮定します。これは、AとHBLT Bの右側のサブツリーをマージした結果です。最終的なHBLTは、ルートとしてAを持ち、サブツリーとしてLとCを持ちます。 Lのs値がCの値よりも小さい場合、C
-
データ構造の有向グラフの深さ優先探索
グラフの深さ優先探索も同様です。しかし、有向グラフまたは有向グラフの場合、いくつかのタイプのエッジを見つけることができます。 DFSアルゴリズムは、DFSツリーと呼ばれるツリーを形成します。 -と呼ばれるエッジには4つのタイプがあります ツリーエッジ(T) −DFSツリーに存在するエッジ フォワードエッジ(F) −ツリーエッジのセットに平行。 (小さいDFS番号から大きいDFS番号へ、大きいDFS完了番号から小さいDFS完了番号へ) バックワードエッジ(B) −大きいDFS番号から小さいDFS番号へ、小さいDFS完了番号から大きいDFS完了番号へ。 クロスエッジ(C)