最適な二分探索木
整数のセットはソートされた順序で与えられ、別の配列は頻度カウントに頻繁に与えられます。私たちのタスクは、これらのデータを使用してバイナリ検索ツリーを作成し、すべての検索の最小コストを見つけることです。
サブ問題の解を解いて保存するために、補助配列cost [n、n]が作成されます。コストマトリックスは、ボトムアップ方式で問題を解決するためのデータを保持します。
入力と出力
Input:
The key values as node and the frequency.
Keys = {10, 12, 20}
Frequency = {34, 8, 50}
Output:
The minimum cost is 142.
These are possible BST from the given values.
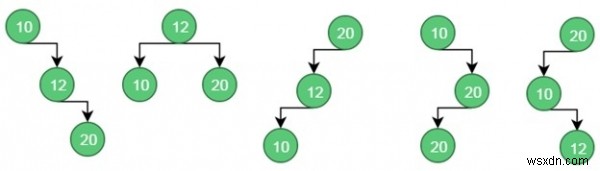 For case 1, the cost is: (34*1) + (8*2) + (50*3) = 200
For case 2, the cost is: (8*1) + (34*2) + (50*2) = 176.
Similarly for case 5, the cost is: (50*1) + (34 * 2) + (8 * 3) = 142 (Minimum)
For case 1, the cost is: (34*1) + (8*2) + (50*3) = 200
For case 2, the cost is: (8*1) + (34*2) + (50*2) = 176.
Similarly for case 5, the cost is: (50*1) + (34 * 2) + (8 * 3) = 142 (Minimum) アルゴリズム
optCostBst(keys, freq, n)
入力: BSTに挿入するキー、各キーの頻度、キーの数。
出力: 最適なBSTを作成するための最小コスト。
Begin define cost matrix of size n x n for i in range 0 to n-1, do cost[i, i] := freq[i] done for length in range 2 to n, do for i in range 0 to (n-length+1), do j := i + length – 1 cost[i, j] := ∞ for r in range i to j, done if r > i, then c := cost[i, r-1] else c := 0 if r < j, then c := c + cost[r+1, j] c := c + sum of frequency from i to j if c < cost[i, j], then cost[i, j] := c done done done return cost[0, n-1] End
例
#include <iostream>
using namespace std;
int sum(int freq[], int low, int high) { //sum of frequency from low to high range
int sum = 0;
for (int k = low; k <=high; k++)
sum += freq[k];
return sum;
}
int minCostBST(int keys[], int freq[], int n) {
int cost[n][n];
for (int i = 0; i < n; i++) //when only one key, move along diagonal elements
cost[i][i] = freq[i];
for (int length=2; length<=n; length++) {
for (int i=0; i<=n-length+1; i++) { //from 0th row to n-length+1 row as i
int j = i+length-1;
cost[i][j] = INT_MAX; //initially store to infinity
for (int r=i; r<=j; r++) {
//find cost when r is root of subtree
int c = ((r > i)?cost[i][r-1]:0)+((r < j)?cost[r+1][j]:0)+sum(freq, i, j);
if (c < cost[i][j])
cost[i][j] = c;
}
}
}
return cost[0][n-1];
}
int main() {
int keys[] = {10, 12, 20};
int freq[] = {34, 8, 50};
int n = 3;
cout << "Cost of Optimal BST is: "<< minCostBST(keys, freq, n);
} 出力
Cost of Optimal BST is: 142
-
データ構造における最適な二分木
整数のセットはソートされた順序で与えられ、別の配列は頻度カウントに頻繁に与えられます。私たちのタスクは、これらのデータを使用してバイナリ検索ツリーを作成し、すべての検索の最小コストを見つけることです。 サブ問題の解を解いて保存するために、補助配列cost [n、n]が作成されます。コストマトリックスは、ボトムアップ方式で問題を解決するためのデータを保持します。 入力 −ノードおよび頻度としてのキー値。 Keys = {10, 12, 20} Frequency = {34, 8, 50} 出力 −最小コストは142です。 これらは、指定された値から可能なBSTです。 ケース1の
-
C#での二分探索
バイナリ検索はソートされた配列で機能します。値は配列の中央の要素と比較されます。同等性が見つからない場合は、値が存在しない半分の部分が削除されます。同様に、残りの半分の部分が検索されます。 これが配列のmid要素です。 62を見つける必要があるとしましょう。そうすると、左側の部分が削除され、右側の部分が検索されます- これらは二分探索の複雑さです- 最悪の場合のパフォーマンス O(log n) ベストケースのパフォーマンス O(1) 平均パフォーマンス O(log n) 最悪の場合のスペースの複雑さ O(1) 例 二分