Upstash と Node.js を使用してリアルタイム記事レコメンデーション エンジンを作成する
Google または Perplexity.ai を使用したことがありますか?オンライン記事へのリンクを含む最新の検索結果をどのようにして表示できるのか不思議に思いませんか?このガイドでは、そのようなシステムを自分で作成する方法を学びます。成長を続けるナレッジ バンクに追加した記事のリンクに基づいて推奨事項を生成できるシステムの作成方法を学びます。
前提条件
次のものが必要です。
- Node.js 18 以降
- Upstash アカウント
- OpenAI アカウント
- Fly.io アカウント
技術スタック
手順
このガイドを完了し、独自の記事推奨システムを導入するには、次の手順に従う必要があります。
- OpenAI トークンを生成する
- Upstash Vector インデックスを作成する
- プロジェクトをセットアップする
- OpenAI API クライアントをインスタンス化する
- OpenAI API 埋め込みクライアントを作成する
- Upstash Vector クライアントを作成する
- コンテキスト API エンドポイントを作成する
- チャット API エンドポイントを作成する
- Fly.io にデプロイする
- 参考文献
- 結論
OpenAI トークンを生成する
OpenAI API を使用すると、記事のベクトル埋め込みを取得し、AI を使用してチャットボット応答を作成できます。 OpenAI API へのリクエストには認証トークンが必要です。トークンを取得するには、OpenAI アカウントの API キーに移動し、新しい秘密キーの作成 をクリックします。 ボタン。このトークンをコピーして安全に保存し、後で OPENAI_API_KEY として使用します。 環境変数。
Upstash Vector インデックスを作成する
Upstash アカウントを作成してログインしたら、[Vector] タブに移動して [インデックスの作成] をクリックします。
をクリックして、ベクトル インデックスの作成を開始します。
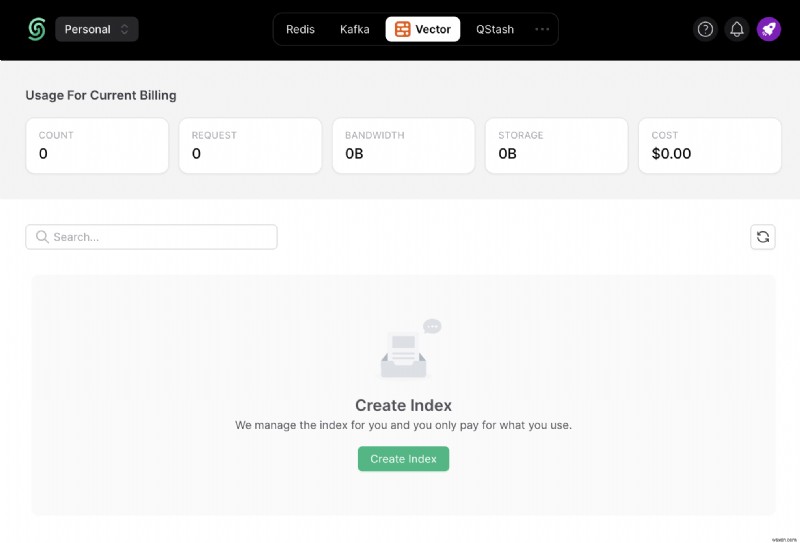
選択したインデックス名を入力します (たとえば、article) ) を選択し、ベクトルの次元を 1536 に設定します。
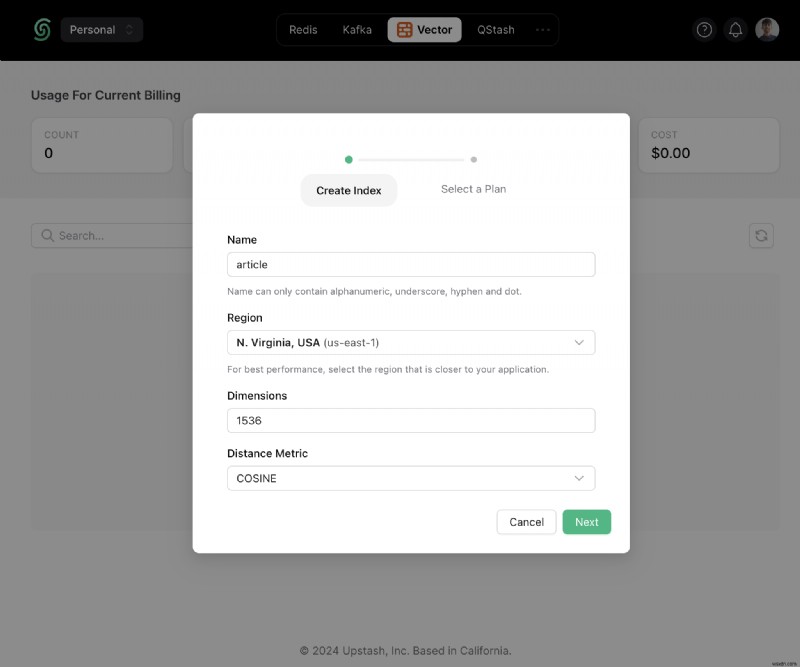
次に、接続まで下にスクロールします。 セクションに移動し、.env をクリックします。 ボタン。内容をコピーし、アプリケーションで今後使用できるように安全な場所に保存します。
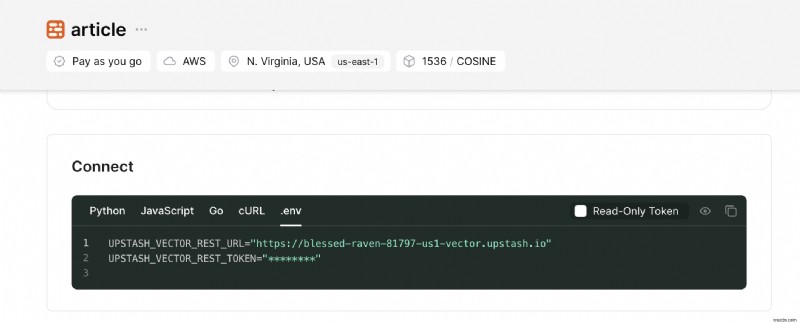
プロジェクトをセットアップする
セットアップするには、アプリ リポジトリのクローンを作成し、このガイドに従ってその内容をすべて学習するだけです。プロジェクトのクローンを作成するには、ターミナルで次のコマンドを実行します。
# Clone the project
git clone https://github.com/rishi-raj-jain/article-recommendation-system
cd article-recommendation-system
# Install the dependencies
pnpm install
リポジトリのクローンを作成したら、.env を作成します。 ファイル。上のセクションで取得した秘密キーを追加します。
.env ファイルには次のキーが含まれている必要があります:
# .env
# OpenAI API Key
OPENAI_API_KEY="sk-..."
# Upstash Vector Keys
UPSTASH_VECTOR_REST_URL="https://...-us1-vector.upstash.io"
UPSTASH_VECTOR_REST_TOKEN="...="これが完了すると、側での構成セットアップが完了します。ターミナルで次のコマンドを実行し、localhost:3000 にアクセスすると、アプリケーションの動作を確認できます。
pnpm run build && pnpm run start手順に従って、コードの関連部分を理解することで、独自の記事推奨システムを適切に構築できるようになります。
OpenAI API クライアントをインスタンス化する
openai の場合 パッケージを使用すると、時間を節約し、数行のコード内で OpenAI REST API を操作できるようになります。次のコードでは、チャット完了応答の作成にさらに使用できるように、OpenAI API クライアント ライブラリをインスタンス化しました。
// File: app/lib/openai/completion.server.ts
import OpenAI from 'openai'
// Instantiate class to generate text completion using the OpenAI API
export default new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
})
注:.server.ts を追加することにより、 Remix 内のファイルにコピーすると、そのコードが強制的に出力されていることを確認できます。 クライアント側バンドルの。
OpenAI API 埋め込みクライアントの作成
@langchain/openai の場合 パッケージでは、OpenAIEmbeddings を使用できます。 指定されたテキストのベクトル埋め込みを生成するためのクラス。 OpenAIEmbeddings クラスを LangChain Vector Store と組み合わせると、各ベクトル エンベディングを独自に作成して挿入するプロセスが不要になります。次のコードでは、内部でベクトル埋め込みを作成するためにさらに使用できるように、OpenAIEmbeddings クラスをインスタンス化しました。
// File: app/lib/openai/embedding.server.ts
import { OpenAIEmbeddings } from '@langchain/openai'
// Instantiate class to generate embeddings using the OpenAI API
export default new OpenAIEmbeddings({
modelName: 'text-embedding-3-small',
openAIApiKey: process.env.OPENAI_API_KEY,
})Upstash Vector クライアントの作成
@upstash/vector を使用する および @langchain/community/vectorstores/upstash パッケージを使用すると、Remix アプリケーションでコネクションレス クライアントを作成し、Upstash Vector インデックスからベクトル エンベディングを保存、削除、クエリできるようになります。
// File: app/lib/upstash/vectorStore.server.ts
import embeddings from '~/lib/openai/embedding.server'
import { Index as UpstashIndex } from '@upstash/vector'
import { UpstashVectorStore } from '@langchain/community/vectorstores/upstash'
// Instantiate the Upstash Vector Index
const index = new UpstashIndex({
url: process.env.UPSTASH_VECTOR_REST_URL as string,
token: process.env.UPSTASH_VECTOR_REST_TOKEN as string,
})
// Instantiate the Upstash Vector Store that'll create and save embeddings
export default new UpstashVectorStore(embeddings, { index })コンテキスト API エンドポイントを作成する
Remix アプリケーションを実行すると、複数の記事の URL を入力として受け入れるテキスト ボックスが表示されます。これらの記事は、将来のユーザー検索でパーソナライズされた応答を作成するためにチャットボットの知識に追加されます。このセクションでは、コンテキスト エンドポイント (app/routes/api_.context.tsx) がどのように機能するかを学習します。 ) は、これらの複数の記事 URL を受け入れ、そのコンテンツを取得し、ベクトル埋め込みを生成し、Upstash Vector Index に動的に保存するように設定されています。
// File: app/routes/api_.context.tsx
import { Document } from 'langchain/document'
import { ActionFunctionArgs } from '@remix-run/node'
import vectorServer from '~/lib/vector/vectorStore.server'
import { CheerioWebBaseLoader } from 'langchain/document_loaders/web/cheerio'
export const action = async ({ request }: ActionFunctionArgs) => {
const formData = await request.formData()
// Check if any article link are present in the form submission
const articlesToEmbed = formData.get('articles') as string
if (articlesToEmbed) {
// Create the documents to be added to the Upstash Vector Store
const documents: any[] = []
await Promise.all(
articlesToEmbed.split(',').map(async (link) => {
// Use the link to render in the search results
// Parse the link using Cheerio
const loader = new CheerioWebBaseLoader(link.trim())
const scraper = await loader.scrape()
// Get the content of title tag to render in the search results
const name = scraper('title').html()
// Get the page content as string
const pageContent = scraper.text()
// Create metadata object to be inserted in the vector store
const metadata = { link, name }
documents.push(new Document({ pageContent, metadata }))
}),
)
// Creating embeddings from the provided documents along with metadata
// and add them to Upstash database
await vectorServer.addDocuments(documents.filter(Boolean))
}
}
上記のリミックス アクションでは、コンテキスト エンドポイント (/api/context への POST リクエストに含まれるフォーム データ) ) が解析されます。さらに、コンマ (,) で区切られた記事リンクのセットに対するループがあり、次の処理を実行します。
pageContentを作成します 記事の Web ページから取得したテキスト コンテンツとしての変数nameを作成します 記事のウェブページのタイトルとして変数- テキストコンテンツ、参照、記事名を含む LangChain ドキュメントを作成します (
new Document({ pageContent, metadata })) ) - 各ドキュメントをグローバル
documentsに追加します。 配列
最後に、グローバル documents に保存されているすべてのドキュメント 配列は Upstash Vector Index に挿入されます。内部では、各ドキュメントのベクトル埋め込みが pageContent を使用して生成されます。 プロパティ。
チャット API エンドポイントを作成する
このセクションでは、チャット API エンドポイント (app/routes/api_.chat.tsx) の仕組みを学習します。 ) は、ユーザーの検索に関連する記事への推奨事項を含む検索エンジンのような応答を作成するように設定されています。検索に関連する記事は、指定されたベクトル インデックスから最も近い上位 K 個のベクトルを見つけることによって検索されます。さらに、ベクターのメタデータのタイトルとリンクがコンテキストとして OpenAI API に渡されます。これにより、チャットボットはユーザーの検索に応答するとともに、記事を外部リンクとして含めることができます。話を単純化するために、これをさらに複数の部分に分割します。
類似性検索を使用して関連するベクトル埋め込みを検索する
ユーザーが検索するたびに記事のナレッジ バンク全体に再度アクセスするのは、コストがかかる作業です。ユーザー検索に関連性の高い上位 3 つの記事に範囲を絞るには、Upstash Vector Index 内の既存のベクトルのセットをクエリします。さらに、ユーザー検索のベクトル埋め込みに対して少なくとも 70% の類似性スコアを持つ埋め込みを持つベクトルを維持するようにフィルタをかけます。
// File: app/routes/api_.chat.tsx
import vectorServer from '~/lib/upstash/vectorStore.server'
import type { ActionFunctionArgs } from '@remix-run/node'
export const action = async ({ request }: ActionFunctionArgs) => {
// Set of messages between user and chatbot
const { messages = [] } = await request.json()
// Get the latest question stored in the last message of the chat array
const searchQuery = messages[messages.length - 1].content
// Perform Similarity Search using the Upstash Vector Store
const queryResult = await vectorServer.similaritySearchWithScore(searchQuery, 3)
// Filter the records with confidence score > 70% and
// set the metadata as response to render search results
const results = queryResult.filter((i) => i[1] >= 0.7).map((i) => i[0].metadata)
// Proceed to create a response
}チャットボットのシステム コンテキストと手順を作成する
関連性の高いベクトルのセットを取得したので、チャットボットがユーザーの検索に応答する前に、関連する記事を認識して参照できるようにする必要があります。 OpenAI の gpt-3.5-turbo を使用してこれを行うには モデルで、ロール プロパティをシステムとして指定してメッセージ オブジェクトを作成します。 そして content プロパティには次の指示が含まれます:
- チャットボットは Google と同じように応答する必要があります
- チャットボットは応答がマークダウン形式であることを確認する必要があります
- チャットボットの応答には記事へのハイパーリンクが必要です
- チャットボットは記事への参照を含めるだけではありません
// File: app/routes/api_.train.tsx
import { OpenAIStream, StreamingTextResponse } from 'ai'
import completionServer from '~/lib/openai/completion.server'
export const action = async ({ request }: ActionFunctionArgs) => {
// ...
// Now use OpenAI Text Completion with relevant articles as context
const completionResponse = await completionServer.chat.completions.create({
stream: true,
model: 'gpt-3.5-turbo',
messages: [
{
// create a system content message to be added as
// the open ai text completion will supply it as the context with the API
role: 'system',
content: `Behave like a Google. You have the knowledge of the following articles: ${JSON.stringify(results)}. Each response should be in 100% markdown compatible format and should have hyperlinks in it. Be precise. Do add some general text in the response related to the query.`,
},
// also, pass the whole conversation!
...messages,
],
})
// Convert the response into a friendly text-stream
const stream = OpenAIStream(completionResponse)
// Respond with the stream
return new StreamingTextResponse(stream)
}
上記のコードを使用すると、コンテキストを認識した OpenAI からの結果をストリーミングでき、ユーザーの検索に関連する記事を推奨できます。
とても勉強になりました!これですべて完了です ✨
Fly.io にデプロイ
リポジトリには、特に以下に関連する Fly.io の組み込みセットアップが付属しています。
- Dockerfile
- fly.toml
- .dockerignore
Fly.io アカウントを取得したら、ターミナルのルート ディレクトリで次のコマンドを実行して、Fly.io でアプリを作成できます。
# Create an app based on the baked-in configuration in your account
# This will result only in the change of app name in existing fly.toml
fly launchターミナルで次のコマンドを実行して Fly.io にデプロイします。
# Deploy the app based on the configuration created above
fly deploy参考文献
さらに詳しい情報については、このガイドで使用されている参考資料を参照してください。
- GitHub リポジトリ
- Upstash Vector ストアと LangChain の統合
- OpenAI の Chat Completions API のシステム命令
- LangChain の Cheerio を使用してウェブページからデータをロードする
- React アプリで AI チャット UI を作成する
結論
このガイドでは、Vector Embeddings と動的に生成されたシステム コンテキストを備えた OpenAI Completion API を使用して記事推奨システムを構築する方法を学習しました。 Upstash Vector と LangChain を使用すると、数行のコード内で、ベクトルをインデックスに保存し、上位 K 個のベクトル検索クエリを実行し、各ユーザー検索に関連するコンテキストを作成することができます。
ご質問やコメントがございましたら、お気軽に GitHub までご連絡ください。
-
Redisキー–1つ以上のキーをredisデータストアに保存する方法
このチュートリアルでは、コマンド-redis-cliのキーを使用してredisデータストアに保存されている1つ以上のキーを取得する方法について学習します。 このコマンドは、指定されたパターンに一致する1つ以上のキーを返すために使用されます。パターンはglobスタイルで指定されます。 グロブスタイルパターン:- *ワイルドカード:- スペースを含む0個以上の文字に一致します。たとえば、foo *はfooccc、foo、fooqに一致します。 ?ワイルドカード:- スペースを含む任意の文字の1つと正確に一致します。たとえば、f?0はfao、fbo、fcoと一致します。 [list
-
設定値の差分の実行方法-RedisSDIFF| SDIFFSTORE
このチュートリアルでは、redis SDIFFおよびSDIFFSTOREコマンドを使用して、redisデータストアに格納されている2つ以上のセット値に対して差分演算を実行する方法について学習します。 セットの違い: 集合論では、A – Bと書かれた2つの集合AとBの差は、集合Bにない集合Aのすべての要素を含む集合です。例: A = {1, 2, 3, 4, 5}B = {4, 5, 6, 7, 8, 9}Difference of A & B :-A - B = {1, 2, 3} SDIFFコマンド:- このコマンドは、指定された2つ以上のセットに対して差分演算