Server‑Sent Events (SSE) を使用した Next.js でのリアルタイム LLM ストリーミング
迅速に応答する AI を活用したアプリケーションは、瞬時に聞いたり見たりできるようにすることで、ユーザー エクスペリエンスを向上させます。ストリーミングを使用すると、クエリに即座に対応したり、パーソナライズされた推奨事項をリアルタイムで提供したりするチャットボットを作成できます。それはスピードだけではありません。ユーザーのニーズを迅速に満たし、その価値を高めることが重要です。
ストリーミングでは、データを 1 つの大きなブロックではなく、小さな連続したチャンクで送信します。チャットボットやレコメンデーション システムなどの AI アプリケーションのコンテキストでは、ストリーミングとは、応答全体をまとめて一度に配信するのを待つのではなく、応答が利用可能になり次第、部分的な応答をユーザーに送信することを意味します。このアプローチにより、ユーザーはフィードバックや情報を即座に受け取ることができ、よりダイナミックで応答性の高いユーザー エクスペリエンスが実現されます。
このガイドでは、Server-Sent Events (SSE) を利用して、LangChain と OpenAI の言語モデルを使用して Next.js エンドポイントにストリーミングを実装する方法を学習します。さらに、Upstash を使用してストリーミング レスポンスをキャッシュする方法を学習します。
前提条件
以下が必要になります。
- Node.js 18 以降
- OpenAI アカウント
- Upstash アカウント
- Vercel アカウント
技術スタック
OpenAI トークンを生成する
OpenAI APIを使用すると、AIを活用したチャットボットの応答を作成できます。 OpenAI API へのリクエストには認証トークンが必要です。トークンを取得するには、OpenAI アカウントの API キーに移動し、新しい秘密キーの作成 をクリックします。 ボタン。このトークンをコピーして安全に保存し、後で OPENAI_API_KEY として使用します。 環境変数。
Upstash Redis のセットアップ
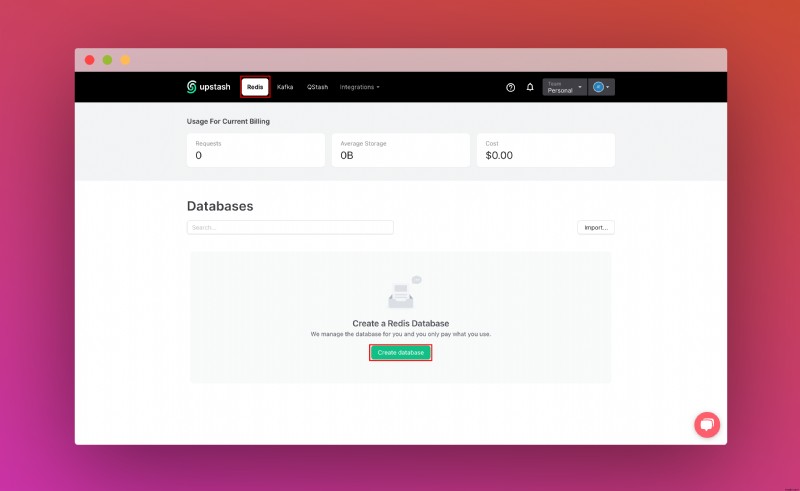
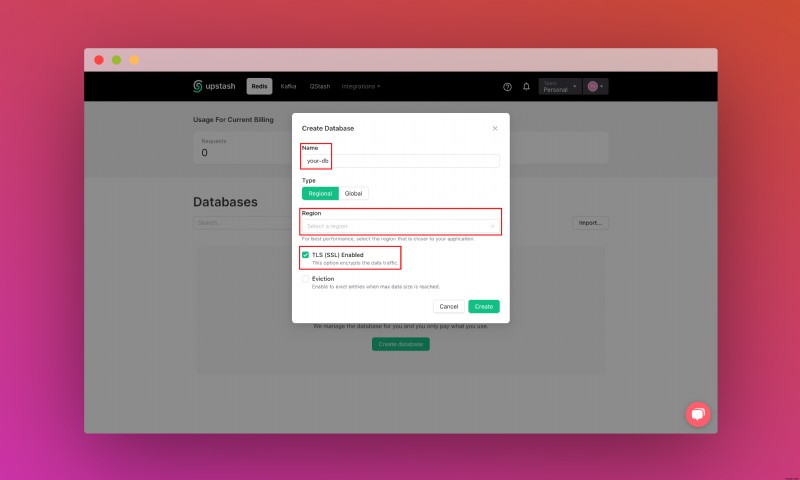
Upstash アカウントを作成してログインしたら、[Redis] タブに移動してデータベースを作成します。
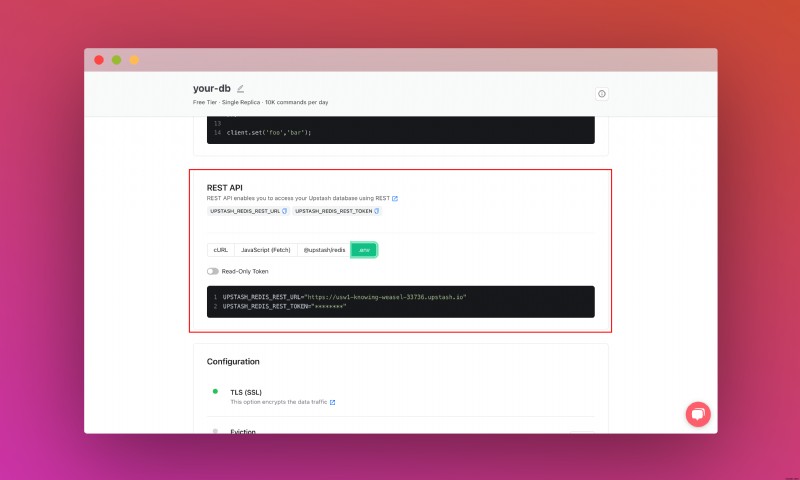
REST API セクションが見つかるまで下にスクロールし、.env を選択します。 ボタン。コンテンツをコピーし、安全な場所に保存します。
新しい Next.js アプリケーションを作成する
新しい Next.js プロジェクトを作成することから始めましょう。ターミナルを開いて次のコマンドを実行します。
npx create-next-app@latest my-appプロンプトが表示されたら、次のものを選択します。
YesTypeScript を使用するように求められた場合。NoESLint を使用するように求められた場合。YesTailwind CSS を使用するよう求められた場合。Nosrc/を使用するように求められた場合 ディレクトリ。YesApp Router を使用するように求められた場合。Noデフォルトのインポート エイリアス (@/*) をカスタマイズするように求められた場合 ).
それが完了したら、プロジェクト ディレクトリに移動し、次のコマンドを実行してアプリを開発モードで開始します。
cd my-app
npm run devアプリは localhost:3000 で実行されている必要があります。次のコマンドを実行して、開発サーバーを停止し、アプリケーションに LangChain 依存関係をインストールします。
npm install @langchain/openai @langchain/communityこのコマンドにより、次のライブラリがインストールされました:
@langchain/openai:OpenAI シリーズのモデルとインターフェースするための LangChain パッケージ。@langchain/community:LangChain コアとのプラグアンドプレイのためのサードパーティ統合のコレクション。
次に、.env を作成します。 プロジェクトのルートにあるファイル。 OPENAI_API_KEY を追加します。
次のようになります:
# .env
# OpenAI Environment Variable
OPENAI_API_KEY="..."
# Upstash Redis Environment Variables
UPSTASH_REDIS_REST_URL="..."
UPSTASH_REDIS_REST_TOKEN="..."Next.js で API エンドポイントを作成するには、Web リクエスト API およびレスポンス API を介して応答を提供できる Next.js ルート ハンドラーを使用します。 Next.js で応答をユーザーにストリーミングする API ルートの作成を開始するには、次のコマンドを実行します。
mkdir -p app/api/stream/completion/chat
mkdir app/lib
-p フラグは chat の親ディレクトリを作成します ディレクトリがない場合は、ディレクトリを参照してください。
これにより、Next.js プロジェクトが設定されます。それでは、Upstash を使用したキャッシュ ハンドラーの作成に進みましょう。
Upstash Redis Cache クライアントをインスタンス化する
UpstashRedisCache の場合 クラスを使用すると、数行のコード内で OpenAI API 応答をキャッシュするための Redis キャッシュ クライアントを初期化できます。ファイル upstashCache.tsx を作成します app/lib 内 ディレクトリ:
キャッシュ ハンドラーを使用すると、OpenAI API によって生成された会話や完了応答をキャッシュすることが非常に簡単になります。 Next.js で Server-Sent Events の使用を開始する方法を理解しましょう。
Next.js App Router での Server-Sent Events API の作成
Server-Sent Events (SSE) を使用すると、継続的なポーリングを必要とせずに、リアルタイムのデータ更新をサーバーからクライアントに配信できます。 SSE により、単一の長期間有効な HTTP 接続を介した一方向のデータ フローが可能になります。
route.ts という名前のファイルを作成します。 app/api/stream に次のコードを追加します。 Server-Sent Events を使用して応答をストリーミングするために必要な最小限の設定を理解するには、ディレクトリを参照してください。
// File: app/api/stream/route.ts
// Prevents this route's response from being cached on Vercel
export const dynamic = "force-dynamic";
export async function POST(request: Request) {
const encoder = new TextEncoder()
// Create a streaming response
const customReadable = new ReadableStream({
start(controller) {
const message = "A sample message."
controller.enqueue(encoder.encode(`data: ${message}\n\n`))
},
})
// Return the stream response and keep the connection alive
return new Response(customReadable, {
// Set the headers for Server-Sent Events (SSE)
headers: {
Connection: "keep-alive",
"Content-Encoding": "none",
"Cache-Control": "no-cache, no-transform",
"Content-Type": "text/event-stream; charset=utf-8",
},
})
}上記のコードは次のことを行います:
- 動的定数は
force-dynamicに設定されます 、Vercel プラットフォームでの応答のキャッシュを防ぎます。これにより、SSE ストリームに対する各リクエストが新しいデータを取得し、キャッシュから提供されないことが保証されます。 - A
ReadableStreamクライアントに送信されるデータのストリームを生成するために作成されます。ストリームの start メソッドでは、メッセージがエンコードされ、ストリームのコントローラーのキューに入れられます。このメッセージは、SSE ストリームの一部としてクライアントに送信されます。 Responseオブジェクトは、Server-Sent Events に固有のヘッダーを使用して作成されます。これらのヘッダーには次のものが含まれます:Connection: keep-aliveストリーミング用に接続を開いた状態に維持するため。Cache-Control: no-cache, no-transformブラウザでのキャッシュを防ぐため。Content-Type: text/event-stream; charset=utf-8コンテンツ タイプをサーバー送信イベントとして指定します。
- カスタム ReadableStream を含む Response オブジェクトがエンドポイントから返されます。このレスポンスは、SSE ストリームをリクエストしているクライアントに送信されます。
これで、応答をストリーミングできるエンドポイントが作成されました。次のセクションでは、LangChain コールバックを使用して OpenAI から Completion および Chat Completion API 応答をストリーミングする方法を理解します。
LangChain コールバックを使用した OpenAI Completion API 応答のストリーミング
OpenAI Completion API は、指定されたプロンプトに基づいてテキストを生成する強力なツールを提供します。これは、コンテンツ生成や言語翻訳など、さまざまな現実のシナリオで役立ちます。 LangChain コールバックを統合すると、応答のリアルタイム ストリーミングが可能になり、アプリケーションの知覚応答性が向上します。
completionModel.tsx という名前のファイルを作成します。 app/lib で ディレクトリを作成し、ストリーミングを有効にして LangChain コールバックを使用して OpenAI インスタンスを初期化し、リアルタイムでテキストを生成する関数を定義します。
// File: app/lib/completionModel.tsx
import { OpenAI } from "@langchain/openai";
export const completionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new OpenAI({
streaming: true,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(`data: ${token}\n\n`));
},
async handleLLMEnd(output) {
controller.close();
},
},
],
});上記のコードは次のことを行います:
OpenAIをインポートします@langchain/openaiのクラス パッケージ。completionModelという名前の関数をエクスポートします。 これは 2 つのパラメータを取ります:- コントローラ:
ReadableStreamDefaultControllerメッセージをストリームにエンキューできるようにするオブジェクト。 - エンコーダ:
TextEncoderメッセージをUint8Arrayにエンコードするオブジェクト オブジェクト。
- コントローラ:
OpenAIの新しいインスタンスを作成します 次の構成オプションを含むクラス:streaming:true に設定すると、API がストリーミング応答を返す必要があることが示されます。callbacks:2 つのコールバック関数を持つ 1 つのオブジェクトを含む配列。各ステージで LLM によるレスポンスの作成をインターセプトするために使用されます。
handleLLMNewToken:言語モデルによって新しいトークンが生成されるときに呼び出されるコールバック。エンコードされたトークンをコントローラにエンキューします。handleLLMEnd:言語モデルの生成が完了したときに呼び出される非同期コールバック。コントローラを閉じます。
さらに、route.ts という名前のファイルを作成します。 app/api/stream/completion 内の次のコード ディレクトリ。作成した最初のストリーミング ルート ハンドラーからの変更は、以下で強調表示されています。
// File: app/api/stream/completion/route.ts
// Prevents this route's response from being cached on Vercel
export const dynamic = "force-dynamic";
+ import { completionModel } from "@/app/lib/completionModel";
export async function POST(request: Request) {
+ // Obtain the user message from request's body
+ const { message } = await request.json();
const encoder = new TextEncoder();
// Create a streaming response
const customReadable = new ReadableStream({
async start(controller) {
+ // Generate a streaming response from OpenAI with LangChain
+ await completionModel(controller, encoder).invoke(message);
},
});
// Return the stream response and keep the connection alive
return new Response(customReadable, {
// Set the headers for Server-Sent Events (SSE)
headers: {
Connection: "keep-alive",
"Content-Encoding": "none",
"Cache-Control": "no-cache, no-transform",
"Content-Type": "text/event-stream; charset=utf-8",
},
});
}Next.js でストリーミング エンドポイントを作成するために以前に行ったこととは別に、上記のコード追加により次のことが行われます。
completionModelをインポートします 関数。request.json()を使用してリクエスト本文からユーザー メッセージを抽出します。 .startの内部 ReadableStream のメソッド、completionModel関数は、リクエストから取得したメッセージと非同期で呼び出されます。この関数は、LangChain を使用して OpenAI からのストリーミング レスポンスを生成します。
ユーザーのクエリとその応答を Upstash でキャッシュするには、Upstash Redis キャッシュ クライアントを completionModel にインポートします。 次のように機能します:
import { OpenAI } from "@langchain/openai";
+ import cache from '@/app/lib/upstashCache';
export const completionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new OpenAI({
+ cache,
streaming: true,
temperature: 0.9,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(token));
},
async handleLLMEnd(output) {
console.log(output.generations[0][0].text);
controller.close();
},
},
],
});最小限の変更で、Upstash による OpenAI Completion API レスポンスのキャッシュが有効になりました。
次に、OpenAI Chat Completion API の応答を Next.js エンドポイントでストリーミングする方法を学習しましょう。
LangChain コールバックを使用した OpenAI Chat Completion API 応答のストリーミング
OpenAI Chat Completion API は、提供されたメッセージに基づいてリアルタイムの会話応答を生成するための強力なツールを提供します。アプリケーションは、自然な対話が可能なチャットボットの構築から、AI 主導の対話機能による顧客サポート システムの強化まで多岐にわたります。これにより、開発者は動的で応答性の高い会話型インターフェースを作成できます。
chatCompletionModel.tsx という名前のファイルを作成します。 app/lib で ディレクトリ、chatCompletionModel を定義 この関数は、LangChain コールバックを使用して OpenAI の Chat Completion API のストリーミング インターフェイスを作成し、提供されたメッセージに基づいたリアルタイムの会話生成を容易にします。
// File: app/lib/chatCompletionModel.tsx
import { ChatOpenAI } from "@langchain/openai";
export type ConversationMessage = {
role: string;
content: string;
};
export type ConversationMessages = ConversationMessage[];
export const chatCompletionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new ChatOpenAI({
streaming: true,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(`data: ${token}\n\n`));
},
async handleLLMEnd(output) {
controller.close();
},
},
],
});上記のコードは次のことを行います:
ChatOpenAIをインポートします@langchain/openaiのクラス パッケージ。- 次の型定義を作成します:
ConversationMessage:会話内の単一メッセージのタイプを定義します。これには、役割 という 2 つのプロパティが含まれています。 (送信者の役割を示す) とコンテンツ (メッセージの内容)。ConversationMessages:会話メッセージの配列のタイプを定義します。
chatCompletionModelという名前の関数をエクスポートします これは 2 つのパラメータを取ります:- コントローラ:
ReadableStreamDefaultControllerメッセージをストリームにエンキューできるようにするオブジェクト。 - エンコーダ:
TextEncoderメッセージをUint8Arrayにエンコードするオブジェクト オブジェクト。
- コントローラ:
ChatOpenAIの新しいインスタンスを作成します 次の構成オプションを含むクラス:streaming:true に設定すると、API がストリーミング応答を返す必要があることが示されます。callbacks:2 つのコールバック関数を持つ 1 つのオブジェクトを含む配列。各ステージで LLM によるレスポンスの作成をインターセプトするために使用されます。
handleLLMNewToken:言語モデルによって新しいトークンが生成されるときに呼び出されるコールバック。エンコードされたトークンをコントローラにエンキューします。handleLLMEnd:言語モデルの生成が完了したときに呼び出される非同期コールバック。コントローラを閉じます。
さらに、route.ts という名前のファイルを作成します。 app/api/stream/completion/chat 内の次のコード ディレクトリ。作成した最初のストリーミング ルート ハンドラーからの変更は、以下で強調表示されています。
// File: app/api/stream/completion/chat/route.ts
// Prevents this route's response from being cached on Vercel
export const dynamic = "force-dynamic";
+ import {
+ type ConversationMessage,
+ chatCompletionModel,
+ } from "@/app/lib/chatCompletionModel";
export async function POST(request: Request) {
+ // Obtain the conversation messages from request's body
+ const { messages = [] } = await request.json();
const encoder = new TextEncoder();
// Create a streaming response
const customReadable = new ReadableStream({
async start(controller) {
+ // Generate a streaming response from OpenAI with LangChain
+ await chatCompletionModel(controller, encoder).invoke(
+ messages.map((i: ConversationMessage) => [i["role"], i["content"]])
+ );
},
});
// Return the stream response and keep the connection alive
return new Response(customReadable, {
// Set the headers for Server-Sent Events (SSE)
headers: {
Connection: "keep-alive",
"Content-Encoding": "none",
"Cache-Control": "no-cache, no-transform",
"Content-Type": "text/event-stream; charset=utf-8",
},
});
}Next.js でストリーミング エンドポイントを作成するために以前に行ったこととは別に、上記のコード追加により次のことが行われます。
chatCompletionModelをインポートします 関数とConversationMessage型定義。request.json()を使用して、リクエスト本文から会話内のメッセージを抽出します。 .startの内部 ReadableStream のメソッド、chatCompletionModel関数は、メッセージ配列の変換後に非同期的に呼び出されます。各メッセージは、メッセージの役割と内容を含む配列に変換されます。この関数は、LangChain を使用して OpenAI からのストリーミング レスポンスを生成します。
Upstash でチャット履歴をキャッシュするには、Upstash Redis キャッシュ クライアントを chatCompletionModel にインポートします。 次のように機能します:
+ import cache from '@/app/lib/upstashCache';
import { ChatOpenAI } from "@langchain/openai";
export type ConversationMessage = {
role: string;
content: string;
};
export type ConversationMessages = ConversationMessage[];
export const chatCompletionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new ChatOpenAI({
+ cache,
streaming: true,
temperature: 0.9,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(token));
},
async handleLLMEnd(output) {
console.log(output.generations[0][0].text);
controller.close();
},
},
],
});最小限の変更で、Upstash によるチャット履歴全体のキャッシュが有効になりました。
次に、ストリーミング エンドポイントを使用するクライアント側 React コンポーネントの作成に進みましょう。
サーバー送信イベントをリッスンするために Next.js フロントエンドをセットアップする
このセクションでは、Server-Sent Events API メッセージに対する最小限のリスナーをセットアップする方法と、ユーザーと AI の間で交換されるメッセージの状態を管理するアプローチを学習します。
React でサーバー送信イベント API をリッスンする
React のクライアント側コンポーネントで SSE API をリッスンするには、指定された API ルートへの POST リクエストを開始します。応答を受信したら、TextDecoderStream を使用して受信データを文字列としてデコードします。 メソッドを使用して、ストリームからデータを継続的に読み取ります。
"use client";
export default function () {
const obtainAPIResponse = async (apiRoute: string, apiData: any) => {
// Initiate the first call to connect to SSE API
const apiResponse = await fetch(apiRoute, {
method: "POST",
headers: {
"Content-Type": "text/event-stream",
},
body: JSON.stringify(apiData),
});
if (!apiResponse.body) return;
// To decode incoming data as a string
const reader = apiResponse.body
.pipeThrough(new TextDecoderStream())
.getReader();
while (true) {
const { value, done } = await reader.read();
if (done) {
break;
}
if (value) {
// Do something
}
}
};
return <></>
}React での会話の状態の管理
ユーザーとチャットボット間の会話の状態を管理するには、状態変数を使用できます。状態変数 messages を更新します。 と latestMessage 会話履歴と最新のメッセージをそれぞれ保存します。 SSE API から受信したデータを処理するループ内でこれらの状態変数を更新することで、会話表示をリアルタイムに更新できます。同じことを実現するためのコード追加は次のとおりです。
"use client";
+ import { useEffect, useState } from "react";
+ import { ConversationMessages } from "@/app/lib/chatCompletionModel";
export default function () {
+ const [latestMessage, setLatestMessage] = useState<string>("");
+ const [messages, setMessages] = useState<ConversationMessages>([]);
const obtainAPIResponse = async (apiRoute: string, apiData: any) => {
// Initiate the first call to connect to SSE API
const apiResponse = await fetch(apiRoute, {
method: "POST",
headers: {
"Content-Type": "text/event-stream",
},
body: JSON.stringify(apiData),
});
if (!apiResponse.body) return;
// To decode incoming data as a string
const reader = apiResponse.body
.pipeThrough(new TextDecoderStream())
.getReader();
+ let incomingMessage = "";
while (true) {
const { value, done } = await reader.read();
if (done) {
+ // Insert the response received into the messages state
+ setMessages((messages) => [
+ ...messages,
+ { role: "assistant", content: incomingMessage },
+ ]);
+ // Reset the latest message's state received
+ setLatestMessage("");
break;
}
if (value) {
+ // Append the incoming data to latest message's value
+ incomingMessage += value;
+ setLatestMessage(incomingMessage);
}
}
};
return <></>
}上記のコードを追加すると、次のことが行われます。
- 状態変数は、SSE API から受信した受信データ ストリームを保存するために宣言されます。
- 完全なメッセージを受信したとき (
doneで示される) true)、最後に受信したメッセージがmessagesに追加されます。 状態配列。このメッセージはアシスタントの役割でフォーマットされています。 ユーザーメッセージと区別するためです。また、次の受信メッセージに備えて、最新のメッセージの状態が空の文字列にリセットされます。 - データは段階的に受信されると (まだ完全なメッセージを形成していない)、
incomingMessageに追加されます。 変数。 - 最新のメッセージ状態は連結された受信データで更新され、新しいデータが到着するとリアルタイムで更新されます。
素晴らしい!リアクティブ latestMessage を使用する および messages 変数を使用して、会話で交換されるメッセージと AI が生成した最新の応答を表す動的なユーザー インターフェースを作成できるようになりました。
とても勉強になりました!これですべて完了です ✨
Vercel に展開
これで、リポジトリを Vercel にデプロイする準備ができました。導入するには、次の手順を使用します。
- まず、アプリのコードを含む GitHub リポジトリを作成します。
- 次に、Vercel ダッシュボードに移動し、新しいプロジェクトを作成します。 .
- 新しいプロジェクトを、作成したばかりの GitHub リポジトリにリンクします。
- 設定内 、環境変数を更新します。 ローカルの
.envにあるものと一致するようにする ファイル。 - 展開してください! 🚀
詳細情報
さらに詳しい洞察については、この投稿で引用されている参考文献を参照してください。
- GitHub リポジトリ
- サーバー送信イベント
- Next.js ストリーミング
- LLM のキャッシュ層
-
Redisエンタープライズモニタリングオプション
新しい役割を開始し、最初の顧客との最初の会議に到着した場合、.NETでの容量計画、DNSの問題、地理的分散、および開発に関する2日間の計画を備えています。質問は次のとおりです。「クラスターとデータベースを効率的に監視するにはどうすればよいですか?」 さて、16年の運用経験で、準備ができていると思いました。もちろん、実際には、「学べば学ぶほど、自分の知らないことがどれだけあるかがわかります。」さて、新しいソフトウェアを見ると、最初の質問の1つは、それが本番環境で正しく動作することを確認する方法です。言い換えれば、どうすればそれを監視できますか? そのことを念頭に置いて、システムの組み込み監
-
例を含むRedisGEORADIUSBYMEMBERコマンド–Redisチュートリアル
このチュートリアルでは、特定の領域に該当するキーに格納されている地理空間値の要素を取得する方法について学習します。このために、Redis GEORADIUSBYMEMBERを使用します コマンド。 GEORADIUSBYMEMBERコマンド このコマンドは、キーに格納されている地理空間値(Sorted Set)の1つ以上のメンバーを返すために使用されます。これらのメンバーは、経度、指定されたメンバーの緯度値、および半径の引数を使用して計算された領域の境界内にあります。この面積は、指定されたメンバーの経度、緯度の値を円の中心位置として使用し、指定された単位の半径を円の半径として使用して計算