RediSearch2.0が最初のマイルストーンに到達
RediSearch2.0の開発における最初のマイルストーンのリリースを発表できることを嬉しく思います。 RediSearchは、Redisデータをクエリして、さまざまな複雑な質問に答えることができるリアルタイム検索エンジンです。
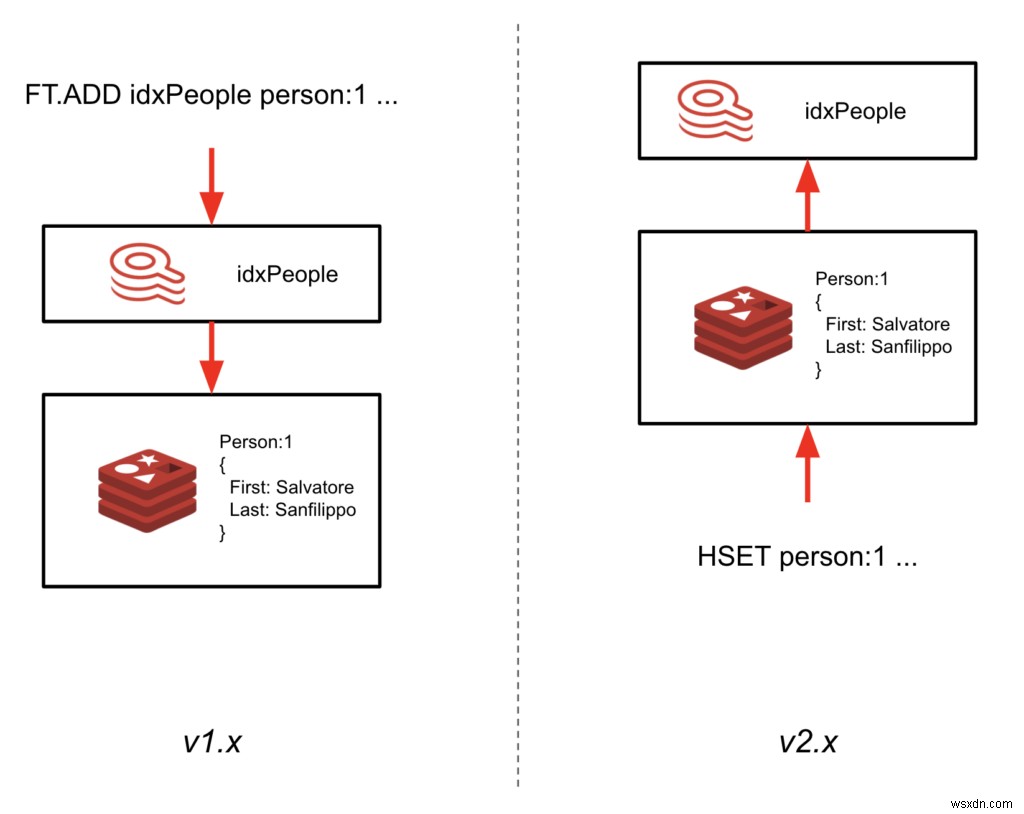
2.0-M01と呼ばれるこのマイルストーンは、インデックスがデータと同期し続ける方法の再構築を示しています。インデックスを介してデータを書き込む代わりに( FT.ADD を使用) コマンド)、RediSearchはハッシュで書き込まれたデータを追跡し、自動的にインデックスを作成します。
ここでの大きな利点は、アプリケーションコードを更新しなくても、既存のRedisインスタンスにRediSearchを追加して、セカンダリインデックスを作成できることです。これにより、RediSearchモジュールをロードしてスキーマを定義するだけで、既存のデータでRediSearchの使用をすぐに開始できます。この秋、RediSearch2.0の一般提供が予定されています。
(注: この新機能により、APIにいくつかの変更が加えられます(以下にリストされています)。可能な限り下位互換性を維持しようとしていますが、この場合は不可能でした。今後、お客様からのフィードバックを収集しながら、調整と修正を行う予定です。)
APIの変更
上記のように、このRediSearch 2.0マイルストーンには、APIに対するいくつかの変更が含まれています。
- インデックスはキースペースに存在しなくなりました。 たとえば、インデックスキー(idx:<インデックス名>)を使用してデータベース内のインデックスを一覧表示した場合、これは機能しなくなります。ただし、コマンド FT._LISTを導入しました データベース内のすべてのインデックスを返します。
- インデックスはプレフィックス/フィルターを使用して作成する必要があります。 これらは、RediSearchによって自動的にインデックスが作成されるドキュメントを指定します。単純なプレフィックスや複雑なフィルター式を指定できます。
- アップグレードはできません。 古いバージョンのRediSearchで作成されたRDBがある場合、RediSearch2.0はそれを読み取ることができません。現在、データセット全体のインデックスを再作成する必要があります。ただし、GAリリースのアップグレードプロセスに取り組んでいます。
- Redis6以降でのみ機能します。
- FTコマンドはRedisと同等のコマンドにマップされました。 これにより、既存のアプリケーションを引き続きRediSearch2.0で動作させることができます。マッピングは次のとおりです。
- FT.ADD => HSET
- FT.DEL => DEL (デフォルトではDD)
- FT.GET => HGETALL
- FT.MGET => HGETALL
- 転置インデックス自体はRDBに保存されなくなりました 。これは、永続性がサポートされていないことを意味するものではありません。 RediSearchは、インデックス定義をRDBに保存し、Redisの開始後にバックグラウンドでデータにインデックスを付けます。 FT.INFO を使用してインデックスのステータスを確認すると、インデックスの再作成がいつ終了したかを確認できます。 コマンド。
新しいAPI
APIの最大の更新は、インデックスの作成方法です。 RediSearch 2.0では、コマンド FT.CREATE インデックスを作成するために使用されます。 APIへの追加は、ここで黄色で強調表示されています:
FT.CREATE {index}
ON {structure}
[PREFIX {count} {prefix} [{prefix} ..]
[FILTER {filter}]
[LANGUAGE_FIELD {lang_field}]
[LANGUAGE {lang}]
[SCORE_FIELD {score_field}]
[SCORE {score}]
[PAYLOAD_FIELD {payload_field}]
[TEMPORARY {seconds}]
[MAXTEXTFIELDS]
[NOOFFSETS] [NOHL] [NOFIELDS] [NOFREQS]
[STOPWORDS {num} {stopword} ...]
SCHEMA {field} [TEXT [NOSTEM] [WEIGHT {weight}] [PHONETIC {matcher}] | NUMERIC | GEO | TAG [SEPARATOR {sep}] ] [SORTABLE][NOINDEX] ... 詳細をいくつか掘り下げてみましょう:
- ON{構造} 現在、 HASHのみをサポートしています
- PREFIX {count} {prefix} インデックスを作成するキーをインデックスに指示します。インデックスにいくつかのプレフィックスを追加できます。引数はオプションであるため、デフォルトは * (すべてのキー)
- FILTER {filter} は、完全なRediSearch集約式言語を使用したフィルター式です。 @__ keyを使用して、追加/変更されたばかりのキーにアクセスすることができます
- 言語 およびSCORE インデックスに登録されているすべてのドキュメントのデフォルトの言語とスコアを上書きできます
- LANGUAGE_FIELD 、 SCORE_FIELD 、および PAYLOAD_FIELD ドキュメント固有の言語とスコアリングを使用し、ペイロードをドキュメント内のフィールドとして使用できるようにします。
その他の制限と変更
RediSearch 2.0-M01マイルストーンには、他にもいくつかの更新があります。
- NOSAVE サポートされなくなりました。
- ハッシュを更新すると、ドキュメント全体にインデックスが付けられます(キースペース通知では、変更されたフィールドはアドレス指定されません)。そのため、部分的な更新は遅くなります。これらの状況でパフォーマンスを改善するためのオプションをまだ調査中であることに注意してください。
- フィールド名では大文字と小文字が区別されるようになったため、フィールド「FOO」を宣言して「foo」としてインデックスを付けることはできません。
- FT.ADD コマンドはhsetにマップされます ここに示すように:
FT.ADD idx doc1 1.0 LANGUAGE eng PAYLOAD payload FIELDS f1 v1 f2 v2
にマッピングされています
HSET doc1 __score 1.0 __language eng __payload payload f1 v1 f2 v2
つまり、マッピングが期待どおりに機能するためには、インデックスのスコア、言語、およびペイロードのフィールドを__score、__ language、__payloadと呼ぶ必要があります。
- FT.ADDHASH はサポートされなくなりました。 HSETを使用する 。
- FT.OPTIMIZE はサポートされなくなりました。RediSearchガベージコレクション機能は、インデックスの最適化を担当します。
結論
これらのドキュメントを操作するときにアプリケーションロジックを更新しなくても、RediSearchを既存のRedisデータベースにロードし、ハッシュに存在する既存のデータにインデックスを付けることができるため、これらの変更に非常に興奮しています。このマイルストーンリリースを試すには、GitHubからソースコードを取得するか、 1:99:1を使用します。 RedisSarchDockerイメージ。このバージョンはまだ本番環境に対応していませんが、フィードバックを収集するために今すぐ共有したいと思います。 GitHubリポジトリまたはRedisコミュニティフォーラムでコメントや問題を共有してください。
-
RediSearch2.0の紹介
Redisの全文検索機能を備えたリアルタイムのセカンダリインデックスであるRediSearchは、最も成熟した機能豊富なRedisモジュールの1つです。また、毎日さらに人気が高まっています。過去数か月で、RediSearch Dockerのプルは500%急増しました。その人気の急上昇により、顧客はリアルタイムの在庫管理から一時的な検索に至るまで、さまざまな興味深いユースケースを思い付くようになりました。 その勢いを伸ばすために、開発者エクスペリエンスを向上させるように設計されたRediSearch2.0のパブリックプレビューを導入します。 Redisearchの最もスケーラブルなバージョンに
-
動作中のRediSearch
Redisには、単純な文字列からRedis Streamsなどの強力な抽象化まで、さまざまなデータ構造のセットがあります。ネイティブデータ型には長い時間がかかる場合がありますが、回避策が必要になる可能性のある特定のユースケースがあります。 1つの例は、キーベースの検索/ルックアップを超えてより豊富なクエリ機能を実現するために、Redisでセカンダリインデックスを使用する必要があることです。並べ替えられたセットやリストなどを使用して作業を完了することはできますが、いくつかのトレードオフを考慮する必要があります。 RediSearchを入力してください! Redisモジュールとして利用可能なR