RedisGraph 2.8がリリースされました!
本日、RedisGraph2.8の一般提供リリースを発表できることをうれしく思います。このブログ投稿では、現在利用可能な主な新機能について詳しく説明しています。
RedisGraphについて
RedisGraphは、Redis用の高性能でメモリファーストのグラフデータ構造です。 RedisGraphは、グラフのマルチテナンシーをサポートし(多数のグラフを同時に保持できます)、グラフに同時にアクセスする複数のクライアントにサービスを提供できます。 Redisスタックの一部としても利用できるようになりました。
RedisGraph2.8の主な新機能
- より豊富なグラフモデル
- マルチラベルノード
- 強化されたクエリ機能
- 強化された全文検索
- より多くのCypher構造、関数、および演算子をサポートする
- パフォーマンスの向上
- 関係プロパティのインデックス
- デルタ行列
- 制御可能なノード作成バッファー
- ベンチマーク
https://redis.com/blog/redisgraph-2-8-is-generally-available/(新しいタブで開きます)
より豊富なグラフモデル
マルチラベルノード
ラベル付きプロパティグラフ(LPG)データモデルの多くの定義(例:プロパティグラフデータベースモデル– Angles、2018 、およびISO / IEC JTC 1 / SC 32 – GQLドラフト)は、ノードが複数のラベルを持つことができることを指定します。 v2.8まで、RedisGraphは単一のラベルのみをサポートしていました。現在のところ、パフォーマンスの低下やメモリの大幅な増加なしに、各ノードに複数のラベルを追加できます。
複数のラベルを持つノードを作成するには、コロンで区切られたすべてのラベルを一覧表示するだけです。
GRAPH.QUERY g "CREATE (e:Employee:BoardMember {Name: 'Vincent Chan', Title: 'Web marketing lead'}) return e" 複数のラベル(AND条件)を持つノードを照合するには、同じコロン表記も使用する必要があります:
GRAPH.QUERY g "MATCH (e:Employee:BoardMember) return e"
拡張クエリ機能
強化された全文検索
RedisGraphはRedisSearchに組み込まれており、セカンダリインデックス作成に利用されますが、高度なインデックス作成や検索にも使用できます。たとえば、地球上の特定の地点への地理的な近さに基づいてノードを検索したり、関連するアイテムをより高くスコアリングしたりします。
バージョン2.8では、言語とストップワードの構成オプションが追加されています。 languageは、テキストのステミングに使用する言語を定義します。これは、単語の基本形式をインデックスに追加することです。これにより、「going」のクエリで、たとえば「go」や「gone」の結果も返されるようになります。ストップワードは非常に一般的な単語(「is、the、an、…」など)であり、検索に多くの情報を追加することはありませんが、インデックス内で多くのスペースを占有します。これらの単語は索引付けされず、検索時に無視されます。 「inParis」のようにストップワードが含まれるクエリ用語は、「Paris」としてのみ表示されます。
ドイツ語を使用し、Movieというラベルの付いたすべてのノードのカスタムストップワードを使用して、映画のtitleプロパティに全文インデックスを作成するには:
GRAPH.QUERY DEMO_GRAPH "CALL db.idx.fulltext.createNodeIndex({ label: 'Movie', language: 'German', stopwords: ['a', 'ab'] }, 'title')" RediSearchには、次の3つの追加フィールド構成オプションがあります。
- 重み–フィールド内のテキストの重要性
- nostem –テキストのインデックス作成時にステミングをスキップする
- ふりがな–テキストのふりがな検索を有効にします
Movieというラベルの付いたすべてのノードの音声検索を使用してtitleプロパティに全文インデックスを作成するには:
GRAPH.QUERY DEMO_GRAPH "CALL db.idx.fulltext.createNodeIndex('Movie', {field: 'title', phonetic: 'dm:en'})" より多くのCypher構造、関数、および演算子をサポートする
RedisGraph 2.8拡張サイファーサポートカバレッジ:
- パターンの理解
-
allShortestPaths
のサポートを追加します 機能 - 暗号化機能:
keys, reduce, replace, none,
およびsingle
-
SET
内のノード属性セットのコピー 条項 -
WHERE
のノードラベルによるフィルタリング 条項 - 暗号演算子:
XOR
および^
パターンの理解
パターン理解は、Cypherで利用可能な構文構造です。リスト内包表記を使用すると、既存のリストに基づいてリストを作成できますが、パターン内包表記は、パターンのマッチングの結果をリストに入力する方法です。標準の
MATCHのように指定されたパターンに一致します 標準の
WHEREのように述語を含む句 節ですが、指定された射影を生成します。
たとえば、次のクエリは、助成金の金額が$1000を超える男性従業員が受け取ったすべての助成金の種類を含むリストを返します。
GRAPH.QUERY g "CREATE (e:Employee {gender:'Male'})-[:granted]->(g:Grant {type: 'Research', amount: 2000})"
GRAPH.QUERY g "MATCH (e:Employee {gender:'Male'}) RETURN [(e)-[:granted]->(g:Grant) WHERE g.amount > 1000 | g.type] AS grantTypes" サポートを追加 allShortestPaths 機能
allShortestPaths関数は、すべての基準に一致するエンティティのペア間のすべての最短パスを返します。両方のエンティティは、以前の
WITHでバインドする必要があります -境界を定められたスコープ。
GRAPH.QUERY DEMO_GRAPH "MATCH (c:Actor {name: 'Charlie Sheen'}), (k:Actor {name: 'Kevin Bacon'}) WITH c, k MATCH p = allShortestPaths((c)-[:PLAYED_WITH*]->(k)) RETURN nodes(p) as actors" このクエリは、チャーリーシーンを表すアクターノードをケビンベーコンを表すアクターノードに接続する最小長のすべてのパスを生成します。 2つのアクター間にはいくつかの2ホップパスがあり、これらすべてが返されます。 2を超える長さのパスには関心がないため、パスの計算は終了します。
検索の最小長(1でなければなりません)と最大長(少なくとも1でなければなりません)を指定できます。 0個以上の関係タイプを指定できます(例:
[:R|Q*1..3])。パターンにプロパティフィルターを導入することはできません。
サポートを追加 キー サイファー関数
keys関数は、ノード、リレーションシップ、またはマップを入力として受け入れ、入力に含まれるすべてのキーの配列を返します。
MATCH (a) RETURN keys(a)
MATCH ()-[e]->() RETURN keys(e)
RETURN keys({a:1, b:2})
サポートを追加 削減 サイファー関数
reduce関数は開始値とリストを受け入れます。次に、リストの各要素に対して式を評価することにより、値を更新します。
GRAPH.QUERY g "RETURN reduce(sum = 0, n IN range(1,10) | sum + n)"
この関数の出力は55になります–1から10までの整数の合計。
GRAPH.QUERY g "RETURN reduce(arr = [], n IN range(1,10) | arr + [n*n])"
この関数の出力は、1から10までの整数の2乗を含む配列になります。
サイファー文字列関数の置き換えのサポートを追加
指定された部分文字列のすべての出現箇所を別の部分文字列に置き換えます。この関数は、元の文字列、置換するオカレンス、およびそれらを何に置き換えるかという3つのパラメーターを受け取ります。
GRAPH.QUERY g "RETURN replace('abc*efg', '*', 'd')" 戻り値は「abcdefg」になります。
この関数は、サブストリングを空のストリング(‘’)に置き換えることによってサブストリングを削除することもできます。
サポートを追加 なし および シングル サイファー関数
リストを指定すると、述語がどの要素にも当てはまらない場合はnoneがtrueを返し、指定された述語が1つの要素のみに当てはまる場合はsingleがtrueを返します。
GRAPH.QUERY g "RETURN none(x IN range(1,10) WHERE x>10)"
GRAPH.QUERY g "RETURN single(x IN range(1,10) WHERE x>9)"
これらの機能は、すべての機能に似ています。
考えられるユースケースの1つは、パスフィルタリングです。
graph.query DEMO_GRAPH“ MATCH p =(a {name:'Johnny Depp'})-[* 2..5]->(b {name:'Kevin Bacon'})WHERE none(n IN ノード(p)WHERE n.year> 1970)RETURN p”
このクエリは、ジョニーデップからケビンベーコンまでの長さ2〜5のすべてのパスを返します。これには、1970年以降に生まれた俳優は含まれません。
SET
にノード属性セットのコピーのサポートを追加します 条項
SET句を使用して、あるノードのすべてのプロパティ値を別のノードのプロパティ値に置き換えたり、追加したりできます。
次のクエリは2つのエンティティに一致し、すべてのaのプロパティをbのプロパティに置き換えます。
GRAPH.QUERY g "MATCH (a {v: 1}), (b {v: 2}) SET a = b" 次のクエリは2つのエンティティに一致し、aのプロパティをbのプロパティに追加(または値を置き換え)します。
GRAPH.QUERY g "MATCH (a {v: 1}), (b {v: 2}) SET a += b" プロパティを変更せずにリレーションシップのタイプを変更することもできます:
GRAPH.QUERY g "MATCH (a)-[b]->(c) WHERE ID(b)=0 CREATE (a)-[d:bar]->(c) SET d=b DELETE b RETURN d"
ノードラベルによるフィルタリングのサポートを追加 場所 句
WHERE句でもノードラベルまたは関係タイプでフィルタリングできるようになりました:
GRAPH.QUERY g "MATCH (a) WHERE a:L RETURN a"
GRAPH.QUERY g "MATCH (a)-[b]-(c) WHERE b:L RETURN b"
サイファー演算子XORおよび^のサポートを追加します
GRAPH.QUERY g "RETURN true XOR true”
GRAPH.QUERY g "RETURN 2 ^ 3”
結果は
falseおよび
8それぞれ。
パフォーマンスの向上
リレーションシッププロパティのインデックス
ノードの場合、次のコマンドを発行してインデックスを導入できます
GRAPH.QUERY g "CREATE INDEX FOR (n:GRANTS) ON (n.GrantedBy)"
リレーションシップのインデックスも導入できるようになりました:
GRAPH.QUERY g "CREATE INDEX FOR ()-[r:R]-() ON (r.prop)"
次のクエリについて考えてみます。
GRAPH.QUERY g "MATCH (a)-[r:R {prop:5}]-(b) return *" インデックスを作成する前に、実行プランを確認しましょう。
redis:6379> GRAPH.EXPLAIN g "MATCH (a)-[r:R {prop:5}]-(b) return *" 1) "Results" |
そして、これはインデックスを作成した後の同じクエリの実行プランです:
redis:6379> GRAPH.EXPLAIN g "MATCH (a)-[r:R {prop:5}]-(b) return *" 1) "Results" |
デルタ行列
バージョン2.8以降、グラフノードとリレーションシップの追加と削除は、最初に小さなデルタマトリックスで更新されるため、はるかに高速になります。その後、メインマトリックスが一括更新されます。
RedisGraphでは、グラフは隣接行列で表されます。グラフ内のすべてのノードラベルとすべての関係タイプには、独自のマトリックスがあります。以前は、新しいノードがグラフに追加されるたびに、すべての行列のサイズを変更する必要があり、データベースが大きいほど、時間がかかりました。
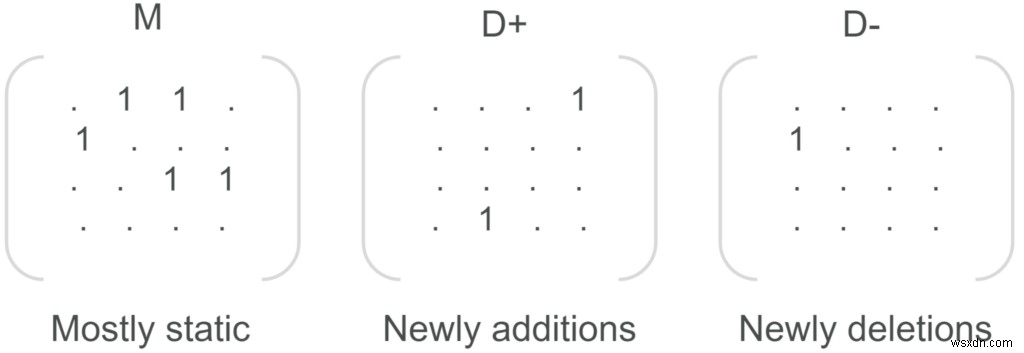
v2.8以降、新しいノードとリレーションシップの挿入にかかる時間は大幅に短縮され、グラフのサイズに依存しなくなりました。この最適化は、グラフ内のすべての行列に2つのデルタ行列を導入することによって達成されました。1つはノードの追加(D +)用で、もう1つはノードの削除(D-)用です。ノードの追加と削除は適切なデルタマトリックスに反映され、デルタマトリックスが10000ノードのしきい値に達すると(
DELTA_MAX_PENDING_CHANGESを介して構成可能) 構成パラメーター)、単一のバルク操作でメインマトリックスと同期され、空になり、同じサイクルを再開できます。
制御可能なノード作成バッファー
新しいロード時構成パラメーターNODE_CREATION_BUFFERは、将来のノード作成のためにマトリックスに予約されているメモリーの量を制御します。たとえば、16,384に設定すると、マトリックスは作成時に16384ノード用の追加スペースを持ちます。余分なスペースがなくなると、マトリックスのサイズは16384増加します。
この値を減らすとメモリ消費量は減りますが、マトリックスの再割り当ての頻度が増えるため、パフォーマンスが低下します。逆に、これを増やすと、書き込みの多いワークロードのパフォーマンスが向上する可能性がありますが、メモリ消費量は増加します。
渡された引数が2の累乗ではなかった場合、メモリのアライメントを改善するために、次に大きい2の累乗に丸められます。
ベンチマーク
また、デルタマトリックスに加えて、他の多くのパフォーマンス拡張機能を追加しました。 LDBC SNBベンチマークを使用して、これらの改善点を以下に示します。
LDBC SNB(Linked Data Benchmark Council – Social Network Benchmarks)は、グラフデータベースの実際の読み取りと書き込みのワークロードを比較するための業界標準のベンチマークです。
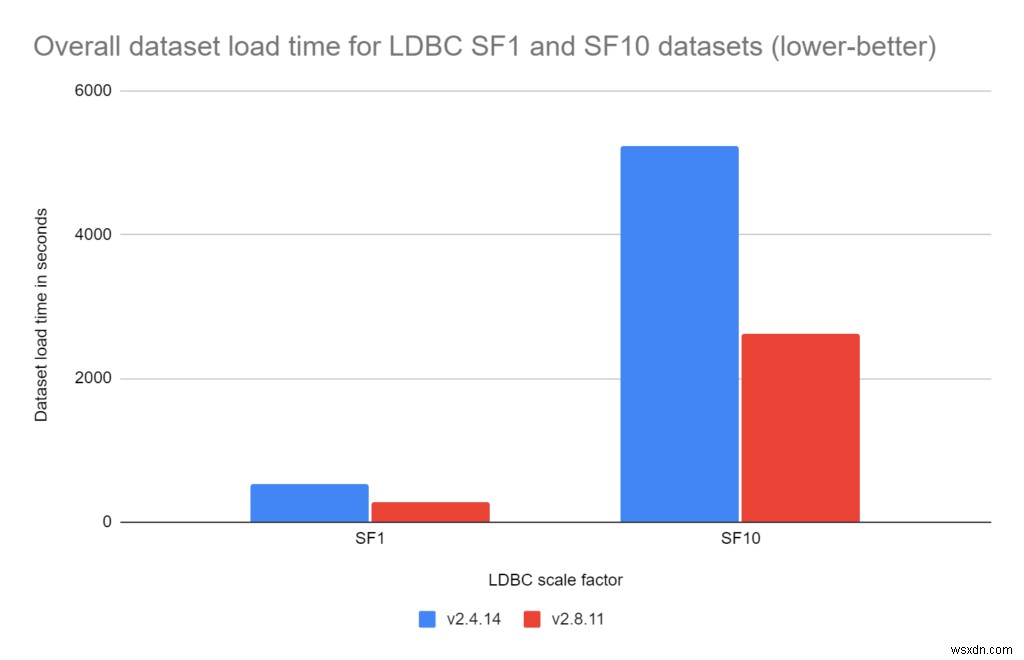
RedisGraph 2.8では、全体的なデータの読み込みがはるかに高速です:
- LDBCスケールファクター1:
RedisGraph2.8はRedisGraph2.4より1.92倍高速です
- LDBCスケールファクター10:
RedisGraph2.8はRedisGraph2.4より2.00倍高速です
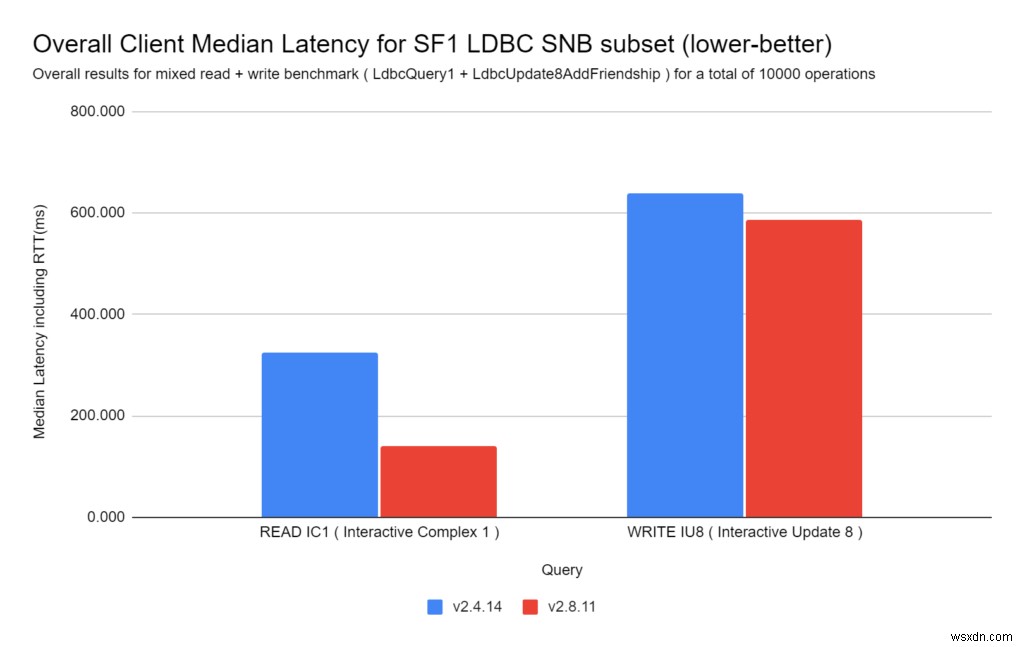
LDBCクエリ(読み取りと書き込みの両方)は、RedisGraph 2.8ではるかに高速に実行されます:
- クエリを読む:
RedisGraph 2,8は、RedisGraph2.4より2.32倍高速です。
- クエリを作成する:
RedisGraph 2,8は、RedisGraph2.4より1.09倍高速です
データ(RDBおよびAOF)の復元と同期もはるかに高速です(状況によっては最大数桁高速です)。
RedisGraphはRedisStackの一部です
RedisGraphはRedisStackの一部になりました。 macOS、Ubuntu、またはRedhat用の最新のRedis Stack Serverバイナリをダウンロードするか、Docker、Homebrew、またはLinuxを使用してインストールできます。
RedisInsightを使用したRedisGraphの体験
RedisInsightは、RedisまたはRedisStackを使用した開発中にRedisTimesからのデータを探索するための優れた方法を提供する開発者向けのビジュアルツールです。
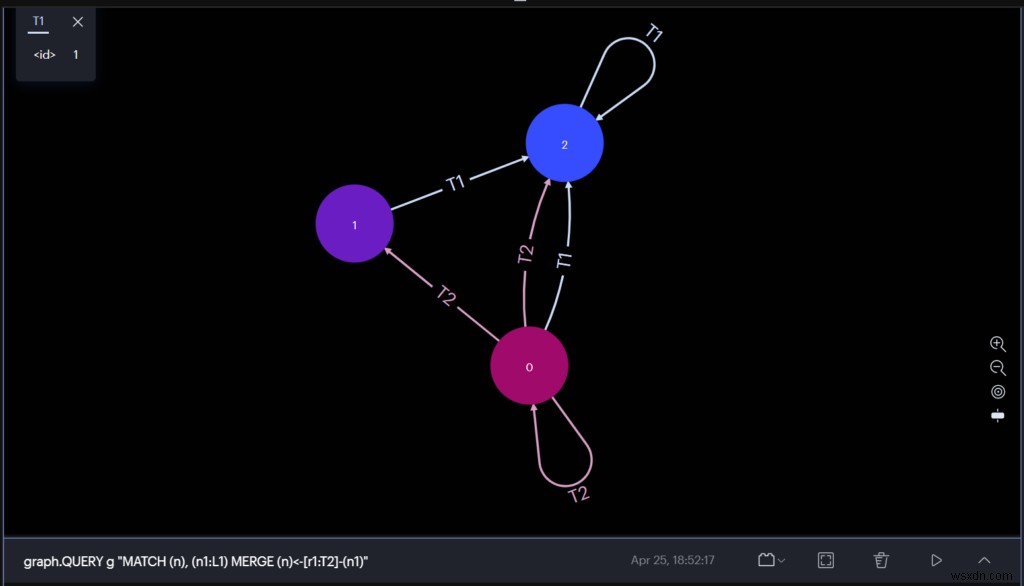
グラフクエリを実行し、グラフィカルユーザーインターフェイスから直接結果を観察できます。 RedisInsightは、RedisGraphクエリの結果を視覚化できるようになりました。
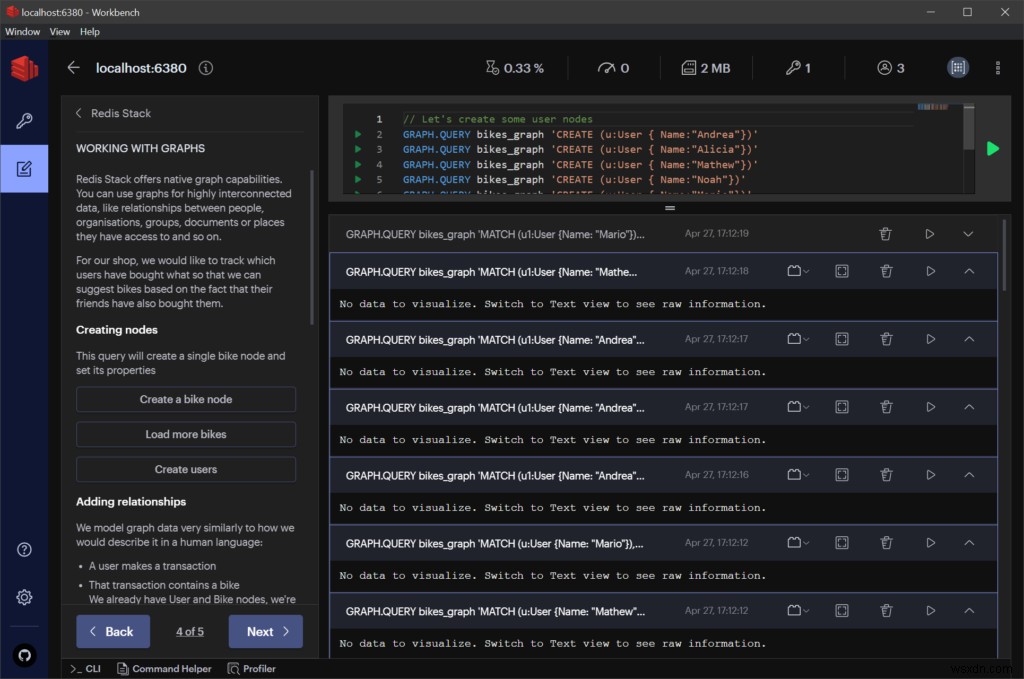
さらに、RedisInsightには、RedisGraphをインタラクティブに学習するためのクイックガイドとチュートリアルが含まれています。
redis.ioおよびdeveloper.redis.comのRedisGraphの詳細をご覧ください。
-
Pythonでのグラフプロット
Pythonには、matplotlibライブラリを使用してグラフを作成する機能があります。さまざまなグラフやプロットを生成する多数のパッケージと関数があります。使い方もとても簡単です。 numpyや他のpython組み込み関数と一緒にそれは目標を達成します。この記事では、生成できるさまざまな種類のグラフをいくつか紹介します。 単純なグラフ ここでは、数学関数を使用してグラフのx座標とY座標を生成します。次に、matplotlibを使用して、その関数のグラフをプロットします。ここでは、以下に示すように、ラベルを適用してグラフのタイトルを表示できます。三角関数-tanのグラフをプロットしています
-
RedisTimeSeries 1.6がリリースされました!
本日、RedisTimeSeries1.6の一般提供を発表できることをうれしく思います。このブログ投稿では、現在利用可能な主な新機能について詳しく説明しています。 RedisTimeSeriesについて RedisTimeSeriesは、Redis用の高性能でメモリファーストの時系列データ構造です。 RedisTimeSeriesは、時系列マルチテナンシー(多数の時系列を同時に保持できます)をサポートし、これらの時系列に同時にアクセスする複数のクライアントにサービスを提供できます。 Redisスタックの一部としても利用できるようになりました。 RedisTimeSeries1.6の主な新機能