Redis ソート セットを使用してインテリジェント オートコンプリートを構築する
入力中に検索ボックスがどのように単語を提案するかに気づいたことがありますか?結局のところ、これらの提案のほとんどは単純なアルファベット順に表示されており、あまり役に立ちません。
しかし、検索ボックスが時間の経過とともにより賢くなる可能性があるとしたらどうでしょうか?
ユーザーが実際にクリックした内容から学び、最も人気のある結果を最初に表示しますか?
これから構築するものは次のとおりです:
Redis Sorted Sets が、ユーザーの行動から学習し、時間の経過とともにより正確になる (人気のある結果を最初に表示する) インテリジェントなオートコンプリート システムを強化する方法を見ていきます。
スマート オートコンプリート システムのアイデア
基本的な検索ボックスは、プレフィックス マッチングと呼ばれる方法を使用して、どの結果を最初に表示するかを決定します。
入力すると、一致するものが A-Z の順に表示されます。実際には、人々が実際にどの結果を最も多くクリックしたかは気にしません。
よりスマートにしていきます。私たちの検索ボックスはユーザーの選択から学習します。 。ユーザーが検索結果をクリックすると、次回からはその結果が最初に表示されます。
これは、最も人気のある結果を自動的に上部に表示することで、検索が時間の経過とともにさらに改善され、より便利になることを意味します。
これが検索アプリケーションにとって重要な理由
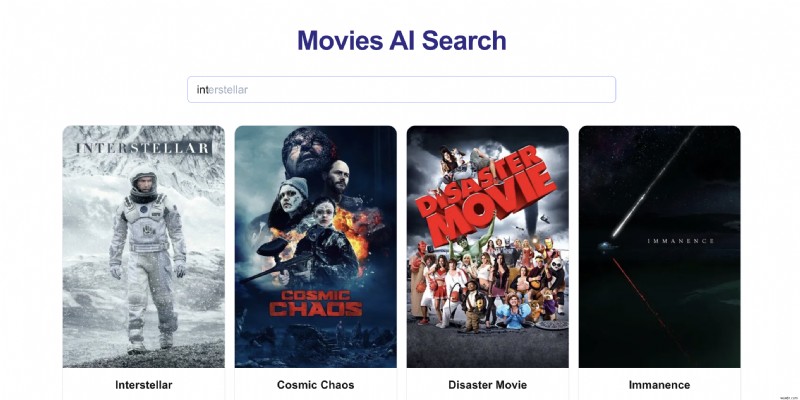
映画検索アプリケーションを考えてみましょう。ユーザーが「int」と入力したときです。彼らは次のことを目にするかもしれません:
- 「インターセプター」
- 「州間高速道路 60 号線」
- 「インターステラー」
「従来の」システムでは、これらはアルファベット順に表示されます。ただし、ユーザーが一貫して「Interstellar」をクリックする場合は、それをオートコンプリート候補の最上位に昇格させたいと考えます。
このスマートなランキング システムは、以下の場合に非常に効果的です。
- ストリーミング サービス Netflix や YouTube など、人々が最も見ているものを表示する
- オンライン ストア 検索時に人気の商品を最初に表示する
- ヘルプセンター 人々から寄せられる最も一般的な質問を表示する
- 検索機能のあるウェブサイト ほとんどの人が最初にクリックするものを表示する
Redis のソート セットについて
Redis ソート セットがオートコンプリート システムの構築に最適である理由を理解しましょう。
Redis ソート セットは、次のようなスマート リストのようなものです。
- 各項目は(セットのように)固有です
- 各アイテムにはスコアがあります(注文用)
- アイテムをスコアに基づいてすばやく並べ替えることができます
オートコンプリート システムでは、2 つのソート セットを使用します。
<オル>これら 2 つのセットは連携して、ユーザーの入力時に最も関連性の高い結果を提案します。
財団:アルファベット順
Redis ソート セットは、すべてのメンバーが同じスコアを持つ場合、アルファベット順を維持します。これは、次のことが可能になるため、検索候補を作成するのに最適です。
<オル>ZRANK を使用します O(log N) 時間で任意のプレフィックスの開始位置を見つけるZSCAN を使用します その位置から始まるすべての一致を効率的に取得するZMSCORE を使用します 各試合の人気スコアを取得するZINCRBY を使用します 各試合の人気スコアを増加させる簡単な例を見てみましょう。映画「INTERSTELLAR」を検索システムに追加すると、次のように分類されます。
- スコア:0、メンバー:"I"
- スコア:0、メンバー:"IN"
- スコア:0、メンバー:"INT"
- スコア:0、メンバー:"INTE"
- スコア:0、メンバー:「INTER」
- スコア:0、メンバー:"INTERSTELLAR$Interstellar" (表示形式付きの完全なエントリ)
$ の使用方法をご覧ください。 検索バージョンと表示バージョンを分割するには?こうすることで、ユーザーは大文字か小文字かを気にせずに検索できますが、映画のタイトルは正確に表示されます。
データの保存方法
オートコンプリートを機能させるために、2 つの Redis ソート セットを使用します。
1.映画タイトルリスト
movies というソートされたセットを追跡しましょう。 。これは、映画をすばやく見つけるのに役立つ辞書のようなものだと考えてください。誰かが「int」と入力すると、その文字で始まるすべての映画を即座に見つけることができます。
「int」の最初の出現は ZRANK によって検出されます。 そして、その位置からワイルドカード INT*$* を使用して完全なムービー名を開始します。
2.人気の映画リスト
movie-popularity というソートされたセットも追跡しましょう。 。これは私たちの「トレンド映画」リストです。
検索結果で映画をクリックするたびに、ZINCRBY を使用してスコアが増加し、その映画の人気が高まります。 。最もクリックされた映画が、今後の検索で最初に表示されます。
これは、Netflix がトレンドの映画を表示するのと同じです。視聴する人が増えるほど、おすすめの上位に表示されます。
私たちの場合、INT*$* の完全一致を見つけた後、 movie-popularity でスコアを確認します。 最も人気のあるものを取得します。
アルゴリズム フロー
graph TD
A[User types 'int'] --> B[ZRANK: Find lexicographic position of 'INT']
B --> C[ZSCAN: Retrieve matches starting from position (movies set)]
C --> D[Filter: Extract complete terms containing '$']
D --> E[ZMSCORE: Get popularity scores for all matches (movie-popularity set)]
E --> F[Rank: Return highest-scored suggestion]
G[User selects suggestion] --> H[ZINCRBY: Increment popularity score]
H --> I[Future searches: Higher scored items rank first]
I --> Aユーザーが検索して候補をクリックすると、システムが学習して改善します。より多くの人が使用するほど、最も関連性の高い提案が最初に表示されるようになります。
オートコンプリート システムを構築してみましょう
このオートコンプリート システムを構築する方法を段階的に見てみましょう。非常にシンプルにしていきます。
ステップ 1:映画のタイトルを Redis に追加する
まず、後で検索できるように、映画のタイトルを Redis に追加する必要があります。データベースやテキスト ファイルなど、どこからでも映画の単純なリストを作成して始めることができます。それらを追加する方法は次のとおりです。
import { Redis } from "@upstash/redis";
const redis = new Redis({
url: process.env.UPSTASH_REDIS_URL!,
token: process.env.UPSTASH_REDIS_TOKEN!,
});
// Example: your list of titles
const titles = [
"Interceptor",
"Interstate 60",
"Interstellar",
// ... more titles
];
async function populateAutocomplete() {
// Insert prefixes and full titles into the 'movies' sorted set
for (const title of titles) {
let term = title.toUpperCase();
let terms = [];
for (let i = 1; i < term.length; i++) {
terms.push({ score: 0, member: term.substring(0, i) });
}
terms.push({ score: 0, member: term });
terms.push({ score: 0, member: term + "$" + title });
await redis.zadd("movies", ...terms);
}
// Insert all titles into the 'movie-popularity' sorted set for popularity tracking
await redis.zadd(
"movie-popularity",
...titles.map((title) => ({
score: 0,
member: title.toUpperCase(),
})),
);
}
populateAutocomplete();上記のコードの動作を詳しく見てみましょう。
<オル>映画のタイトルごとに、以下を保存します。
- すべての可能な部分一致 (「Interstellar」の「INT」、「INTE」、「INTER」など)
- 完全なタイトル自体
- 表示用にフォーマットされたバージョン
また、再生回数ゼロから始まる各映画の人気を追跡する別のリストも作成します。
これにより、ユーザーが入力したときにスマートな提案を表示し、クリック内容から学習するために必要なすべてが得られます。
ステップ 2:最適な一致を見つける
次に、これらの映画タイトルを検索して一致するものを見つける方法を見ていきます。私たちの matchQuery 関数は面倒な作業をすべて実行します。
export const matchQuery = async (query: string): Promise<string | null> => {
const upperQuery = query.toUpperCase();
// Step 1: Find starting position using lexicographic ordering
let rank = await redis.zrank("movies", upperQuery);
if (rank === null) return null;
// Step 2: Efficiently scan for matches from that position
const scanResult = await redis.zscan("movies", rank, {
match: `${upperQuery}*$*`,
count: 1000,
});
// Step 3: Extract complete entries and get their popularity scores
const completeTitles = scanResult[1].filter(
(el, idx) => idx % 2 === 0 && el.includes("$"),
);
const baseNames = completeTitles.map((title) => title.split("$")[0]);
const scores = await redis.zmscore("movie-popularity", baseNames);
// Step 4: Return the highest-scored (most popular) match
const maxScore = Math.max(...scores);
const bestMatchIndex = scores.indexOf(maxScore);
return completeTitles[bestMatchIndex].split("$")[1];
};ユーザーの選択から学ぶ
誰かが映画のタイトルを選択すると、そのスコアに 1 ポイントが追加されます。ポイントが多い映画ほど、候補リストの上位に表示されます。とても簡単です!
このシステムは、ユーザーが実際に何を選択したかを追跡することで、時間の経過とともに賢くなっていきます。
const onSubmit = async (title: string) => {
// Handle submit logic here
await redis.zincrby("movie-popularity", 1, title.toUpperCase());
};どれくらい速いですか?
各操作にかかる時間を分析して、このソリューションの速度を見てみましょう。
- Zランク :O(log N) - 対数検索時間
- ZSCAN :O(log N + M) - ここで、M は返される要素の数です
- ZMS スコア :O(N) - ここで、N はデータセットの合計サイズではなく、一致した結果の数です
- ジンクラビー :O(log N) - 対数複雑度を伴うアトミック増分
さらに映画タイトルを追加しても、パフォーマンスは安定します。
結論:私たちが一緒に構築したもの
AI を使用せずに、時間の経過とともに改善されるスマート検索ボックスを構築する方法を学習しました。
私たちのオートコンプリートは人々が何を選択したかから学習し、その情報を使用してより良い提案を表示します。
高速かつシンプルで、使用する人が増えれば増えるほど便利になります。
Redis の最適化戦略について話したり、独自の実装を共有したりしたいですか? Discord に参加してください!
-
Redis Cache をインストールおよび構成する方法:包括的なガイド
Redis Cache と、それをインストールおよび構成するさまざまな方法について説明します。 議題 概要 キャッシュとは何ですか? Redis キャッシュ Redis キャッシュ サーバーのインストール Docker を使用した Redis キャッシュ イメージ 概要 キャッシュはアプリケーションのパフォーマンスとスケーラビリティを向上させるため、現在ソフトウェア業界で非常に人気があります。私たちは Gmail や Facebook などの多くの Web アプリケーションを使用しており、それらの応答性と優れたユーザー エクスペリエンスを確認しています。インターネットを使用するユーザーは
-
Redis Jedis pubsub-jedisライブラリを使用してpub/subシステムを実装する方法
このチュートリアルでは、Jedisライブラリを使用してredispubサブシステムを実装する方法について学習します。 ジェダイライブラリ Jedisは、redisデータストア用のJavaクライアントライブラリです。小さくて非常に使いやすく、redis 2.8.x、3.x.x以降のデータストアと完全に互換性があります。 jedisライブラリの詳細についてはこちらをご覧ください。 Redis Pub / Sub System Redisは、パブリッシュ/サブスクライブメッセージングパラダイムを実装します。このメッセージングパラダイムによれば、メッセージの送信者(発行者)は、メッセージ