Mastra と Upstash を使用して AI 論文リサーチ アシスタントを構築する
AI 研究エージェントの概要
学術研究は急速に進み、arXiv やその他のプレプリント サーバーに新しい論文が毎日掲載されます。手動で追い続けるのは大変な場合があります。このガイドではAI 研究アシスタントを構築します。 それ:
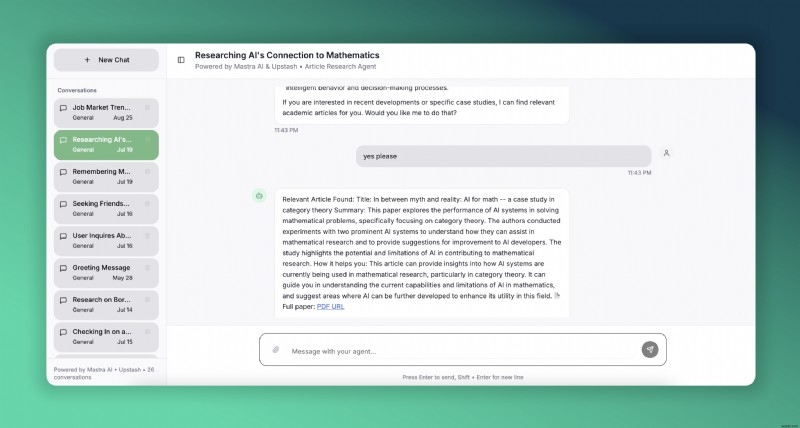
<オル>これをマストラで実現します。 AI エージェントを構築するためのオープンソースの TypeScript フレームワーク、およびUpstash サーバーレス Redis および Vector ストレージ用。こちらは、AI 研究に焦点を当てた記事エージェントのライブ デモです。これは Vercel にデプロイされているので、試してみることができます。
マストラとは何ですか?
Mastra は、実稼働グレードの AI エージェントを簡単に作成できるバッテリー内蔵のフレームワークです。
- エージェントとワークフロー — エージェント、ツール、複数ステップのワークフローを作成する
- 検索拡張生成 (RAG) - 内蔵メモリとベクター ストア
- マルチ LLM - OpenAI、Claude などと連携します。
メモリに Upstash Redis を使用するエージェントを作成します。また、事前に Upstash Vector データベースに埋め込んだ、関連する研究論文を検索するツールも備えています。
さらに詳しく知りたい場合は、Mastra のドキュメントをご覧ください。
プロジェクトの技術スタック
- マストラ フレームワーク AI エージェントとツールを作成する
- Upstash Redis エージェントに会話の記憶を与える
- アップスタッシュベクター 研究論文の要約の埋め込みを保存する
- Next.js と Vercel Web アプリケーションを構築してデプロイする
また、Upstash Ratelimit を使用して、デモ アプリケーションのリクエストを制限します。
実装のチュートリアル
このアプリケーションの構築には、Mastra サーバーと Web アプリケーションという 2 つの主要コンポーネントの作成が含まれます。これらを同じプロジェクト内に含めることもできますが、別々にしておいたほうがすっきりします。 Mastra サーバーから始めましょう。
Mastra プロジェクトの作成
新しい Mastra プロジェクトを作成するには、ターミナルで次のコマンドを実行します。
npm create mastra@latestいくつかの質問が表示されます。このプロジェクトでは、デフォルト設定で問題ありません。
エージェントとツールの作成
エージェントを構成する最初のステップは、エージェントの名前、目的、ツールを定義することです。特定のタスクで適切に機能する言語モデルを選択することも重要です。このプロジェクトでは、エージェントとツールを 1 つずつ使用します。
export const articleAgent = new Agent({
name: "articleAgent",
instructions: instruction,
model: openai('gpt-4o'),
tools: { articleQueryTool },
memory: memory
});
エージェントの構成は上に示したように簡単です。 articleAgent を定義します。 instruction の場合 (システム プロンプトとして機能します)、専用の tools 、model 、もう 1 つの重要なコンポーネント:memory .
エージェントの記憶
Mastra は、エージェントにチャット履歴とセマンティック リコール機能の両方を提供します。メモリをストレージに保持することで、エージェントはよりパーソナライズされた正確な回答を提供できます。エージェントのメモリ構成を見てみましょう。
export const memory = new Memory({
storage: myUpstashStore,
options: {
lastMessages: 10,
semanticRecall: false,
threads: {
generateTitle: true
}
}
});
チャット履歴を有効にするために、ストレージ オプションとして Upstash Redis を使用します。 UpstashStore として初期化します。 MastraStorage を拡張するオブジェクト これにより、Mastra エージェントとシームレスに連携できるようになります。
export const myUpstashStore = new UpstashStore({
url: process.env.UPSTASH_REDIS_REST_URL!,
token: process.env.UPSTASH_REDIS_REST_TOKEN!,
});以前、エージェントにセマンティック リコール機能を追加することについて説明しました。これにより、現在のコンテキストに関連する以前のメッセージを考慮できるようになります。そのために、エージェントにはメッセージを処理するためのベクトル データベースとエンベッダーが必要です。私たちの公開デモは個人使用を目的としたものではなく、異なるスレッド間のメッセージを記憶する必要がないため、この機能は使用しませんが、次のように実装できます。
export const myUpstashVector = new UpstashVector({
url: process.env.UPSTASH_VECTOR_REST_URL!,
token: process.env.UPSTASH_VECTOR_REST_TOKEN!,
});
export const memory = new Memory({
storage: myUpstashStore,
vector: myUpstashVector,
embedder: openai.embedding("text-embedding-3-small"),
options: {
lastMessages: 10,
semanticRecall: {
topK: 3,
messageRange: 2,
scope: 'resource'
},
threads: {
generateTitle: true
}
}
});セマンティック リコール設定では、topK 取得する類似メッセージの数を指定します (messageRange)。 各一致に周囲のコンテキストをどの程度含めるかを定義し、範囲を設定します。 「resource」にすると、エージェントは「resource」という名前のユーザーに関連付けられたすべてのスレッドを検索します。このクロススレッド メモリは、Upstash で利用できる強力な機能です。
ツール
ツールの作成は、エージェントの作成とほぼ同じくらい簡単です。名前、説明、入出力スキーマ、エージェントがツールの機能を必要とするときに実行する関数を提供します。
export const articleQueryTool = createTool({
id: 'get-relevant-article',
description: 'Get relevant article information',
inputSchema: z.object({
question: z.string().describe('the question about the field'),
}),
outputSchema: z.object({
bestOption: z.object({
abstract: z.string().describe('the abstract of the article'),
title: z.string().describe('the title of the article'),
pdfUrl: z.string().describe('the PDF URL of the article')
})
}),
execute: async ({ context }) => {
return await querySimilar(context.question);
},
});Zod を使用して入力スキーマと出力スキーマを検証します。これにより、一貫した応答が維持され、LLM による潜在的なエラーが最小限に抑えられます。ツールが使用する関数も定義します。私たちのツールは、arXiv API を介して定期的に更新され、Upstash Vector データベースに埋め込まれている研究論文の大規模なコレクションをクエリします。
const querySimilar = async (query: string) => {
const { embedding } = await embed({
value: query,
model: openai.embedding("text-embedding-3-small"),
});
const results = await myMastraUpstashVector.query({
indexName: "arxiv",
queryVector: embedding,
topK: 3,
});
if (results && results.length > 0) {
const bestMatch = results[0];
const metadata = bestMatch.metadata as ArxivPaper;
return {
bestOption: {
abstract: metadata.abstract,
title: metadata.title,
pdfUrl: metadata.pdfUrl
}
};
}
throw new Error("No relevant information found");
}
UpstashVector を介してベクトル データベースで簡単な操作を実行できます。 MastraVector を拡張するインスタンス 。上記では、事前に埋め込んだ同様の記事要約をクエリし、最良の結果をツールに返します。記事の場合と同じ埋め込みモデルをクエリにも使用することに注意してください。記事の埋め込みについては後ほど詳しく説明します。
マストラ インスタンス
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
deployer: new VercelDeployer()
});
使用するエージェントと Mastra を指定するだけです。 オブジェクトの準備ができました。インメモリ ストレージを超えてデータを永続化するためのストレージも提供します。利用可能な展開構成から選択することもできます。 Vercel を使用してデプロイします。
create-mastra-app からのデフォルトのオプションを使用 、必要なファイル構造はすでにあります。
.
└── mastra
├── agents
│ └── index.ts
├── tools
│ └── index.ts
└── index.ts
デプロイ前に残っているステップは 1 つだけです。それは環境変数です。
OPENAI_API_KEY=
UPSTASH_VECTOR_REST_URL=
UPSTASH_VECTOR_REST_TOKEN=
UPSTASH_REDIS_REST_URL=
UPSTASH_REDIS_REST_TOKEN=
これらを .env.local に入れてください。 ローカル開発用のファイルを作成し、デプロイメント環境に追加します。
これで、Mastra サーバーを構築してデプロイする準備が整いました。
npm run build && vercel --prod導入方法については、Vercel のドキュメントを参照してください。
開発中に、Mastra Playground を使用してサーバーの出力を確認できます。次のコマンドを実行します。
npm run devこれにより、エージェントとチャットしたり、ツールを明示的に実行したり、サーバーの機能を探索したりできるウェブ インターフェースへのリンクが提供されます。
ここで、アプリケーションの他の部分について説明します。
Next.js サーバー
Mastra サーバーがセットアップされたら、UI、Mastra サーバーとの通信、arXiv API と通信して要約を Upstash Vector に埋め込む記事サービスの 3 つを処理する必要があります。 Mastra には、サーバーの機能を公開するためのクライアント SDK があります。これを通じて、エージェント、ツール、メモリなどにアクセスできます。使い方は簡単ですが、いくつか例を紹介します。詳細については、ここでドキュメントを確認してください。 Next.js プロジェクトでは、クライアント SDK をインストールして使用するだけです。
npm install @mastra/client-js@latest
コード内で、MastraClient のインスタンスを作成します。 プロジェクトで使用するには。
import { MastraClient } from "@mastra/client-js";
export const mastra_sdk = new MastraClient({
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API!,
retries: 3,
});
NEXT_PUBLIC_MASTRA_API を設定する必要があります Mastra サーバーのアドレスに送信します。ローカルで開発している場合、これは localhost になります。 住所。おそらく 3000 でポートの競合が発生する可能性があるため、 、Mastra サーバーをローカルで実行するときに、次のように構成を変更できます。
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
server: {
port: 4111,
timeout: 10000,
}
});
ここで、npm run dev を使用してローカルで Mastra サーバーを実行すると、 、ポート 4111 で提供されます。 。 NEXT_PUBLIC_MASTRA_API を設定できます http://localhost:4111 へ Next.js プロジェクトをローカルで実行するとき。
Mastra のクライアント SDK を使用する方法を見てみましょう。
export const MASTRA_CONFIG = {
resourceId: process.env.NEXT_PUBLIC_RESOURCE_ID || "articleAgent",
agentId: "articleAgent",
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API || "http://localhost:4111",
retries: 3,
}; // this is exported in another file so that we can use it anywhere in the codebase.
// Get your agent and simply stream your response through your agent object.
const agent = mastra_sdk.getAgent(MASTRA_CONFIG.agentId);
const response = await agent.stream({
messages: [message],
resourceId: MASTRA_CONFIG.resourceId,
threadId: threadId
});ツールとエージェントを入手でき、それらを入手すると、クライアント SDK を通じて実際のオブジェクトに対して実行できるほぼすべてのことを実行できるようになります。
このデモ プロジェクトは公開するため、エージェントに大きな負荷がかからないようにすることが重要です。ここで Upstash Ratelimit が登場します。すべてのストリーム リクエストの前に、ユーザーがレート制限されているかどうかを確認します。レート リミッターを構成するには、Upstash Redis が必要です。 Mastra エージェント用と同じ Redis データベースを使用できます。
import { Ratelimit } from '@upstash/ratelimit';
import { Redis } from '@upstash/redis';
// Using the same Redis DB across the project
export const rateLimit = new Ratelimit({
redis: new Redis({
url: process.env.UPSTASH_REDIS_MEMORY_URL!,
token: process.env.UPSTASH_REDIS_MEMORY_TOKEN!
}),
limiter: Ratelimit.slidingWindow(10, '10s'),
prefix: 'upstash-ratelimit',
});
// Fetch the below function before every stream.
export async function isRateLimited(id: string): Promise<boolean> {
const { success } = await rateLimit.limit(id);
return !success;
}このようにして、エンドポイントに大きな負荷がかからないようにすることができます。
Mastra を使用してチャット エージェントを作成する場合、Mastra のスレッド生成の機能をいくつか知っておくと役立ちます。エージェントのメモリを構成したときに、generateTitle を設定したことを思い出してください。 true へ threads 内 オブジェクト。これにより、Mastra は新しく作成されたスレッドに対してタイトルを自動的に生成します。ただし、ここに問題があります。スレッドを明示的に作成することは可能ですが、その方法ではタイトルの自動生成はトリガーされません。通常、新しいスレッドを作成する方法は次のとおりです。
const thread = await mastraClient.createMemoryThread({
title: "New Conversation",
metadata: { category: "support" },
resourceId: "resource-1",
agentId: "agent-1",
});
ただし、タイトルを手動で設定しているため、エージェントが自動的にタイトルを生成する機能が失われます。 title から離れる フィールドが空の場合も機能しません。この場合、Playground が何を行うかを確認できます。開発中にサーバーの機能を体験するために Mastra が提供する Playground を覚えていますか?ブラウザの開発者ツールでネットワーク タブを調べると、新しいスレッドが作成されるときに、スレッドを作成するための API リクエストが実際には送信されていないことがわかります。代わりに、最初のメッセージが送信されるのを待ちます。その後、新しく生成されたスレッド ID を使用してストリーム リクエストを送信します。これにより、この ID のスレッドは存在しないため、スレッドを作成する必要があることが Mastra に伝えられます。generateTitle の場合 true の場合、最初のメッセージに基づいてタイトルを生成します。
プロジェクトの最後のコンポーネントである arXiv 記事に進みましょう。
arXiv の記事
arXiv は、さまざまな分野の約 240 万件の研究論文のオープンアクセス アーカイブです。 articleQueryTool Upstash Vector データベースにクエリを実行します。このデータベースには、arXiv API 経由でフェッチされた記事が供給されます。 API の使い方は簡単です。詳細については、こちらをご覧ください。
私たちのプロジェクトでは、毎日記事を取得して保存します。サーバーを初めて実行すると、指定されたカテゴリから約 30,000 件の記事が取得されます。その後、前日に公開された新しい記事を取得します。記事のカテゴリを指定し、最初の大きなバッチを取得するかどうかを指定するには、対応する環境変数を設定します。 arXiv の分類法を使用して、目的の記事カテゴリをカンマで区切って指定する必要があります。ここでカテゴリを検索できます。
CATEGORIES=cs.AI
RUN_BEGINNING_STACK=falseより包括的なデータベースが必要な場合は、arXiv の一括データ アクセスを使用できます。これがなければ、API クエリごとに記事の数が 30,000 に制限されますが、これは私たちの目的には十分です。
arXiv への簡単なクエリは次のようになります。
const categories = process.env.CATEGORIES?.split(',') || []; // Get the desired categories and split them for the query.
const searchQuery = categories.length === 1 ? `cat:${categories[0]}` : `(${categories.map(c => `cat:${c}`).join(" OR ")})`;
const query = `search_query=${searchQuery}&sortBy=submittedDate&sortOrder=descending`;
const url = `http://export.arxiv.org/api/query?${query}`;
const response = await axios.get(url); // Make the API call with the constructed URL.同様の呼び出しを行って、毎日最新の記事を取得し、初期スタックを取得します。
記事を取得した後、それらを正規化し、Upstash Vector に保存するために埋め込みます。これは、Mastra ツールが使用するものと同じベクトル データベースである必要があります。 「正規化」とは、取得した記事を標準の ArxivPaper に解析することを意味します。 タイプ。コードベース全体で使用します。
export interface ArxivPaper {
id: string;
title: string;
abstract: string;
authors: string[];
published: string;
pdfUrl: string;
category: string;
}// The type for our articles, across our codebase.
async function storeAbstracts(papers: ArxivPaper[]) {
const embeddingModel = openai.embedding("text-embedding-3-small"); // The same model used to query on the Mastra side.
const embeddings = await embedArticles(papers, embeddingModel)
// Put the embeddings into the required form with their metadata.
const vectorsToUpsert = getVectorsToUpsert(embeddings, papers)
for (let j = 0; j < vectorsToUpsert.length; j++) {
await vectorStore.upsert(vectorsToUpsert[j], { namespace: "arxiv" }); // Upsert the embeddings with their metadata to Upstash Vector.
}
}データベースを最新の調査結果に基づいて最新の状態に保つために、スケジュールされたタスクの実行のために Upstash QStash を実装しています。 Vercel 上でのデプロイメントを考慮すると、処理間隔の延長によって発生する可能性のある関数のタイムアウトを防ぐ必要があります。私たちは、サーバー上でパブリック API エンドポイントを公開し、QStash インスタンスが毎日のデータベース更新機能を確実にトリガーできるようにすることで、この問題に対処しています。
// src/app/api/arxiv_reneval/route.ts
import { verifySignatureAppRouter } from "@upstash/qstash/nextjs"
import { fetchAndUpsertYesterday} from "@/services/arxiv"
async function handler(request: Request) {
console.log("Fetching and upserting yesterday's papers...")
await fetchAndUpsertYesterday()
console.log("Fetching and upserting yesterday's papers completed")
return Response.json({ success: true })
}
export const POST = verifySignatureAppRouter(handler)Upstash コンソールを介してスケジューラを設定して、毎日午前 6:00 UTC にこのエンドポイントへのリクエストを自動的にトリガーできます。
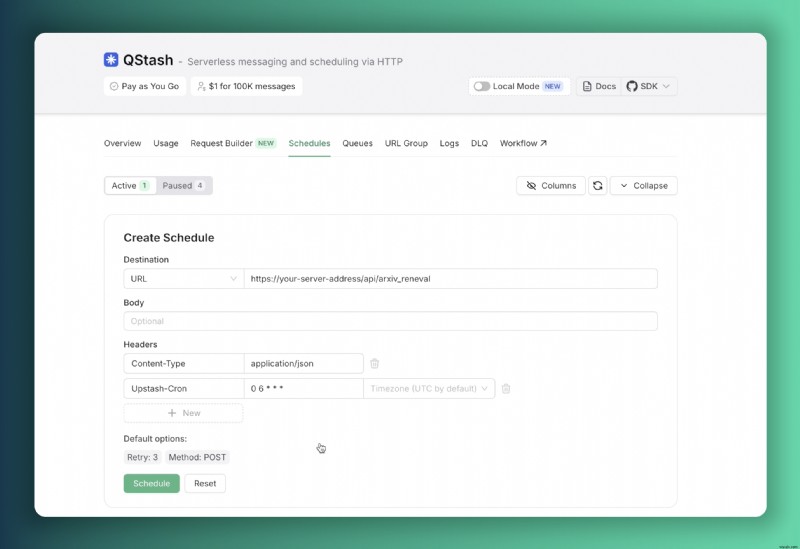
このスケジューラ構成を導入すると、サーバーは毎朝自動データベース更新を実行し、継続的なデータの鮮度を確保します。
また、QStash インスタンスの認証情報も提供する必要があります。必要なすべての環境変数は、サンプル環境ファイルに示されています。
それだけです。必要に応じて、コードを試してみることができます。リポジトリをフォークして開発を開始するだけです。 Mastra パーツのリポジトリにはここから、他のリポジトリにはここからアクセスできます。フォークした後:
- ローカル マシンにクローンを作成します。
- 環境変数を入力します (例
.env) ファイルが提供されます)。 - 別々のターミナルで両方のプロジェクトのルート ディレクトリに移動します。
- 次のコマンドを実行します。
npm install
npm run devこれで、http://localhost:3000 でアプリケーションを確認できるようになります。
Mastra を使用すると、RAG、ワークフロー、ネットワークなどの他のテンプレートを利用して、より複雑なものを構築できます。これらすべての目的において、メモリとストレージが重要な役割を果たしているようです。ここが Upstash の強みです。
-
サーバーレスとエッジのグローバルデータベース
近年、サーバーレスアーキテクチャとエッジコンピューティングは、アプリケーションの展開で非常に人気が高まっています。ただし、アプリケーションの状態とデータをサーバーレス関数やエッジ関数内に保存することは別の話です。データベースへの接続の管理、複数の場所からの高速アクセスにデータを利用できるようにするなど、多くの問題があります。サーバーレスアクセスをサポートするデータベースサービスはごくわずかであり、エッジ機能にも適しているものはごくわずかです。(ここで詳細な分析を読むことができます。 ) Upstashでは、初日から、低レイテンシでリクエストごとの価格設定モデルを備えたサーバーレスRedis互
-
Redisを使用して献血者と患者をつなぐアプリを構築する方法
血を与えることは命を救うための簡単で安全な方法です。それでも、ドナーと正しい血液型の患者を一致させることには、依然として合併症が存在します。献血に関しては時間は限られた商品であり、ドナーを適切な患者に合わせることが絶対に必要です。 このプロセスが効率的であるほど、より多くの命が救われます。この課題に取り組んだのは、献血者を理想的な患者と照合することで献血プロセス全体をスピードアップする驚異的なアプリケーション、Zindagiを作成したBhanuKorthiwadaでした。 このアプリケーションの中心は、ユーザーにリアルタイムで更新を提供するために、データを最大の効率で送信するという基本