サーバーレスデータベース間のレイテンシーの比較:DynamoDBとFaunaDBとUpstash
この記事では、一般的なWebユースケースについて、3つのサーバーレスデータベースDynamoDB、FaunaDB、Upstash(Redis)のレイテンシーを比較します。
サンプルのニュースWebサイトを作成し、Webサイトへのリクエストごとにデータベース関連のレイテンシーを記録しています。ウェブサイトとソースコードを確認してください。
7001のNYTimesの記事を各データベースに挿入しました。記事はNewYorkTimes Archive API(2021年1月のすべての記事)から収集されます。私は各記事をランダムに採点しました。各ページリクエストで、Worldの下の上位10件の記事をクエリします 各データベースのセクション。
サーバーレス関数(AWS Lambda)を使用して、各データベースから記事を読み込みます。 10個の記事をフェッチする応答時間は、ラムダ関数内のレイテンシーとして記録されています。記録されたレイテンシーはラムダ関数とデータベースの間のみであることに注意してください。ブラウザとサーバー間の遅延ではありません。
各読み取り要求の後、動的データをシミュレートするためにスコアをランダムに更新します。ただし、この部分はレイテンシの計算から除外します。
最初にアプリケーションを調べ、次に結果を確認します。
AWSLambdaのセットアップ
地域:US-West-1
メモリ:1024Mb
ランタイム:nodejs14.x
DynamoDBセットアップ
US-West-1で読み取りおよび書き込み容量が50(デフォルト値は5)のDynamoDBテーブルを作成しました。
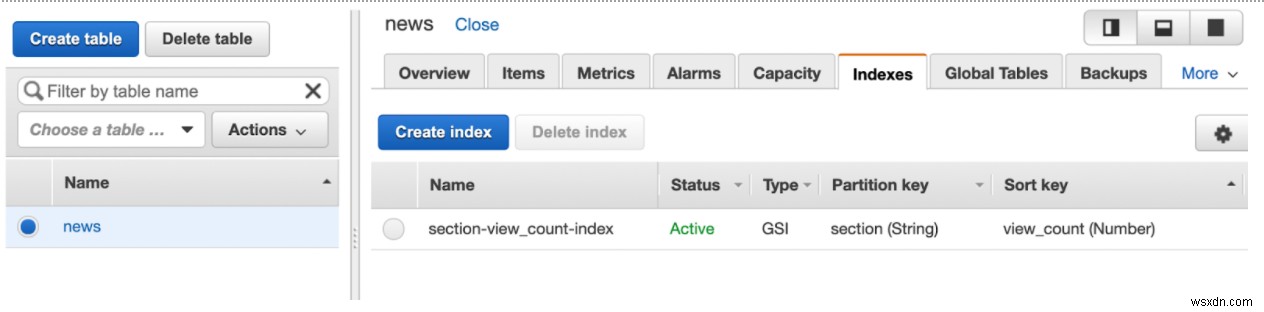
私のインデックスは、パーティションキーsection (String)を持つGSIです。 キーview_count (Number)を並べ替えます 。
FaunaDBのセットアップ
FaunaDBはグローバルに複製されたデータベースであり、リージョンを選択する方法はありません。 GraphQL APIにオーバーヘッドがある可能性があると想定して、FQLを使用しました。
以下のように、用語セクションと値refを使用してインデックスを作成しました。パフォーマンスを向上させるために、シリアル化されていないものにしました。
CreateIndex({
name: "section_by_view_count",
unique: false,
serialized: false,
source: Collection("news"),
terms: [
{ field: ["data", "section"] }
],
values: [
{ field: ["data", "view_count"], reverse: true },
{ field: ["ref"] }
]
})
Redisのセットアップ
UpstashのUS-West-1リージョンに標準タイプのデータベースを作成しました。ニュースカテゴリごとに並べ替えセットを使用しました。つまり、すべてのWorld ニュース記事は、キーWorldで並べ替えられたセットに含まれます 。
7001のニュース記事をNYTimesAPIサイトからJSONファイルとしてダウンロードし、データベースごとにNodeJSスクリプトを作成しました。このスクリプトは、JSONを読み取り、ニュースレコードをデータベースに挿入します。次のファイルを参照してください:initDynamo.js、initFauna.js、initRedis.js
AWSSDKを使用してDynamoDBに接続しました。レイテンシーを最小限に抑えるために、DynamoDB接続を維持しています。 perf_hooksを使用しました 応答時間を測定するためのライブラリ。 DynamoDBに上位10件の記事を照会する直前の現在時刻を記録します。 DynamoDBから応答を受け取ったらすぐに、レイテンシーを計算しました。次に、記事をランダムにスコアリングし、レイテンシー番号をRedisでソートされたセットに挿入しますが、これらの部分はレイテンシー計算部分の外にあります。以下のコードを参照してください:
var AWS = require("aws-sdk");
AWS.config.update({
region: "us-west-1",
});
const https = require("https");
const agent = new https.Agent({
keepAlive: true,
maxSockets: Infinity,
});
AWS.config.update({
httpOptions: {
agent,
},
});
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const tableName = "news";
var params = {
TableName: tableName,
IndexName: "section-view_count-index",
KeyConditionExpression: "#sect = :section",
ExpressionAttributeNames: {
"#sect": "section",
},
ExpressionAttributeValues: {
":section": process.env.SECTION,
},
Limit: 10,
ScanIndexForward: false,
};
const docClient = new AWS.DynamoDB.DocumentClient();
module.exports.load = (event, context, callback) => {
let start = performance.now();
docClient.query(params, (err, result) => {
if (err) {
console.error(
"Unable to scan the table. Error JSON:",
JSON.stringify(err, null, 2)
);
} else {
// response is ready so we can set the latency
let latency = performance.now() - start;
let response = {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: result,
}),
};
// we are setting random score to top-10 items to simulate real time dynamic data
result.Items.forEach((item) => {
let view_count = Math.floor(Math.random() * 1000);
var params2 = {
TableName: tableName,
Key: {
id: item.id,
},
UpdateExpression: "set view_count = :r",
ExpressionAttributeValues: {
":r": view_count,
},
};
docClient.update(params2, function (err, data) {
if (err) {
console.error(
"Unable to update item. Error JSON:",
JSON.stringify(err, null, 2)
);
}
});
});
// pushing the latency to the histogram
const client = new Redis(process.env.LATENCY_REDIS_URL);
client.lpush("histogram-dynamo", latency, (resp) => {
client.quit();
callback(null, response);
});
}
});
};
faunadbを使用しました FaunaDBに接続してクエリを実行するライブラリ。残りの部分はDynamoDBコードと非常によく似ています。待ち時間を最小限に抑えるために、接続を維持しています。 perf_hooksを使用しました 応答時間を測定するためのライブラリ。 FaunaDBに上位10件の記事を照会する直前の現在時刻を記録します。 FaunaDBから応答を受け取ったらすぐに、レイテンシーを計算しました。次に、記事をランダムにスコアリングし、レイテンシー番号をRedisでソートされたセットに送信しますが、これらの部分はレイテンシー計算部分の外にあります。以下のコードを参照してください:
const faunadb = require("faunadb");
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const q = faunadb.query;
const client = new faunadb.Client({
secret: process.env.FAUNA_SECRET,
keepAlive: true,
});
const section = process.env.SECTION;
module.exports.load = async (event) => {
let start = performance.now();
let ret = await client
.query(
// the below is Fauna API for "select from news where section = 'world' order by view_count limit 10"
q.Map(
q.Paginate(q.Match(q.Index("section_by_view_count"), section), {
size: 10,
}),
q.Lambda(["view_count", "X"], q.Get(q.Var("X")))
)
)
.catch((err) => console.error("Error: %s", err));
console.log(ret);
// response is ready so we can set the latency
let latency = performance.now() - start;
const rclient = new Redis(process.env.LATENCY_REDIS_URL);
await rclient.lpush("histogram-fauna", latency);
await rclient.quit();
let result = [];
for (let i = 0; i < ret.data.length; i++) {
result.push(ret.data[i].data);
}
// we are setting random scores to top-10 items asynchronously to simulate real time dynamic data
ret.data.forEach((item) => {
let view_count = Math.floor(Math.random() * 1000);
client
.query(
q.Update(q.Ref(q.Collection("news"), item["ref"].id), {
data: { view_count },
})
)
.catch((err) => console.error("Error: %s", err));
});
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: {
Items: result,
},
}),
};
};
ioredisを使用しました UpstashのRedisに接続して読み取るためのライブラリ。 ZREVRANGEコマンドを使用して、ソート済みセットからデータをロードしました。待ち時間を最小限に抑えるために、接続を再利用して、関数の外部にRedisクライアントを作成しました。 DynamoDBやFaunaDBと同様に、スコアを更新し、ヒストグラム計算のためにレイテンシー番号を別のRedisDBに送信しています。コードを参照してください:
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const client = new Redis(process.env.REDIS_URL);
module.exports.load = async (event) => {
let section = process.env.SECTION;
let start = performance.now();
let data = await client.zrevrange(section, 0, 9);
let items = [];
for (let i = 0; i < data.length; i++) {
items.push(JSON.parse(data[i]));
}
// response is ready so we can set the latency
let latency = performance.now() - start;
// we are setting random scores to top-10 items to simulate real time dynamic data
for (let i = 0; i < data.length; i++) {
let view_count = Math.floor(Math.random() * 1000);
await client.zadd(section, view_count, data[i]);
}
// await client.quit();
// pushing the latency to the histogram
const client2 = new Redis(process.env.LATENCY_REDIS_URL);
await client2.lpush("histogram-redis", latency);
await client2.quit();
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: {
Items: items,
},
}),
};
};
hdr-histogram-jsを使用しました ヒストグラムを計算するためのライブラリ。これは、GilTeneのhdr-histogramライブラリのjs実装です。レイテンシーの数値を受け取り、ヒストグラムを計算するラムダ関数のコードを参照してください。
const Redis = require("ioredis");
const hdr = require("hdr-histogram-js");
module.exports.load = async (event) => {
const client = new Redis(process.env.LATENCY_REDIS_URL);
let dataRedis = await client.lrange("histogram-redis", 0, 10000);
let dataDynamo = await client.lrange("histogram-dynamo", 0, 10000);
let dataFauna = await client.lrange("histogram-fauna", 0, 10000);
const hredis = hdr.build();
const hdynamo = hdr.build();
const hfauna = hdr.build();
dataRedis.forEach((item) => {
hredis.recordValue(item);
});
dataDynamo.forEach((item) => {
hdynamo.recordValue(item);
});
dataFauna.forEach((item) => {
hfauna.recordValue(item);
});
await client.quit();
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify(
{
redis_min: hredis.minNonZeroValue,
dynamo_min: hdynamo.minNonZeroValue,
fauna_min: hfauna.minNonZeroValue,
redis_mean: hredis.mean,
dynamo_mean: hdynamo.mean,
fauna_mean: hfauna.mean,
redis_histogram: hredis,
dynamo_histogram: hdynamo,
fauna_histogram: hfauna,
},
null,
2
),
};
};
最新の結果については、Webサイトを確認してください。最新のヒストグラムデータにアクセスすることもできます。ウェブサイトが稼働している限り、データの収集とヒストグラムの更新を継続します。今日(2021年4月12日)の結果は、Upstashのレイテンシーが最も低く(99パーセンタイルで約50ms)、FaunaDBのレイテンシーが最も高い(99パーセンタイルで約900ms)ことを示しています。 DynamoDBには(99パーセンタイルで約200ms)
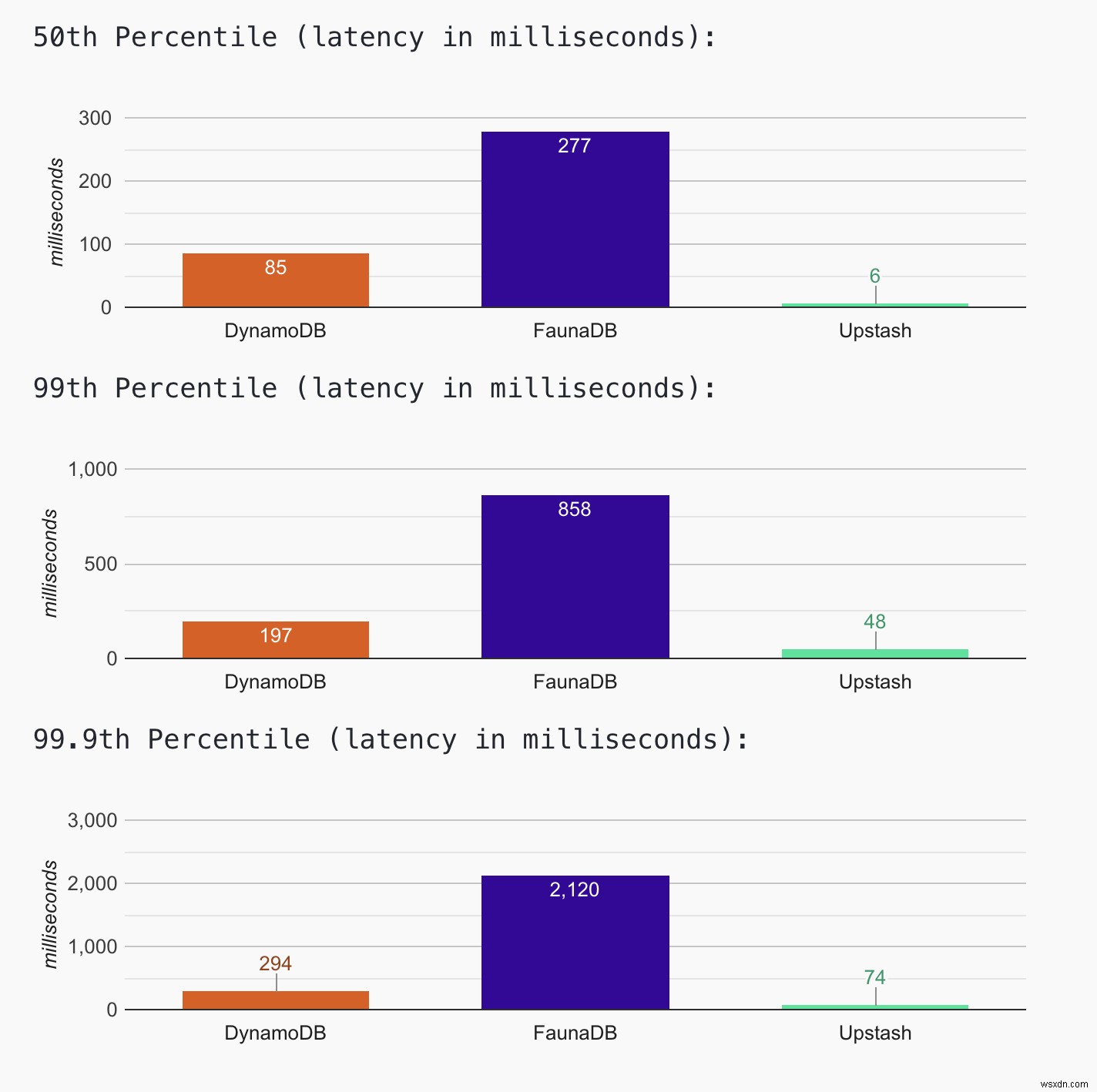
クエリ部分のレイテンシーのみを測定しますが、コールドスタートは依然として効果があります。クライアント接続を再利用することでコードを最適化します。 Lambdaコンテナが熱く、実行されている限り、これはメリットがあります。 AWSがコンテナを強制終了すると(コールドスタート)、コードはクライアントを再作成します。これはオーバーヘッドです。アプリケーションのWebサイトで、ページを更新すると、 Upstashのレイテンシーの数値は約1msまで減少します。 DynamoDBの場合は最大7ミリ秒。
なぜFaunaDBが遅いのですか(このベンチマークでは)?
FaunaDBのステータスページには、数百のレイテンシ数が表示されます。したがって、私の構成には大きな欠陥はないと思います。このレイテンシの違いの背後には2つの理由が考えられます:
強い一貫性: デフォルトでは、DynamoDBとUpstashの両方が結果整合性を提供します。 FaunaDBは、Calvinベースの強力な一貫性と分離を提供します。強一貫性にはパフォーマンスのオーバーヘッドが伴います。
グローバルレプリケーション: UpstashとDynamoDBの両方で、データベースとラムダ関数を同じAWSリージョンに配置するように設定できます。 FaunaDBでは、データは世界中に複製されます。そのため、地域を選択するオプションはありません。データベースクライアントが世界中にある場合、これは利点になる可能性があります。ただし、バックエンドを特定のリージョンにデプロイすると、余分なレイテンシが発生します。
Redisはサブミリ秒のレイテンシを提供します。ここではそうではないのはなぜですか?
AWS Lambda関数で新しいRedis接続を作成すると、顕著なオーバーヘッドが発生します。アプリケーションは安定したトラフィックを取得しないため、AWS Lambdaはほとんどの場合接続を再作成します(コールドスタート)。したがって、ヒストグラムの遅延数の大部分には、接続の作成時間が含まれます。 15秒ごとにWebサイトをフェッチするジョブを実行します。 Upstashのレイテンシーが約1msに減少したことがわかりました。ページを更新すると、同様の効果が見られます。サーバーレスアプリケーションを低レイテンシーに最適化する方法については、ブログ投稿をご覧ください。
Upstashは、データが複数のアベイラビリティーゾーンに複製されるプレミアム製品をまもなくリリースします。ゾーンレプリケーションの効果を確認するために追加します。
TwitterまたはDiscordでフィードバックをお寄せください。
私のベンチマークと動物相のパフォーマンスについて、HackerNewsで活発な議論がありました。提案を適用し、FaunaDBアプリケーションを再起動しました。そのため、ヒストグラム内のFaunaDBレコードの数は他のレコードよりも少なくなっています。
-
サーバーレスとエッジのグローバルデータベース
近年、サーバーレスアーキテクチャとエッジコンピューティングは、アプリケーションの展開で非常に人気が高まっています。ただし、アプリケーションの状態とデータをサーバーレス関数やエッジ関数内に保存することは別の話です。データベースへの接続の管理、複数の場所からの高速アクセスにデータを利用できるようにするなど、多くの問題があります。サーバーレスアクセスをサポートするデータベースサービスはごくわずかであり、エッジ機能にも適しているものはごくわずかです。(ここで詳細な分析を読むことができます。 ) Upstashでは、初日から、低レイテンシでリクエストごとの価格設定モデルを備えたサーバーレスRedis互
-
サーバーレスバトルグラウンド-DynamoDBvsFirestore vs MongoDB vs Cassandra vs Redis vs FaunaDB
これは、2021年4月に公開されたブログ投稿の続きです。 一般的なWebユースケースとサーバーレス機能を使用して、主要なサーバーレスデータベースのパフォーマンスを比較するサンプルアプリケーションを構築しました。データベースは、DynamoDB、MongoDB(Atlas)、Firestore、Cassandra(Datastax Astra)、FaunaDB、Redis(Upstash)です アプリケーションとソースコードを確認してください。 比較したのは、データベースごとに上位10件のニュース記事を取得するまでの待ち時間です。全体のデータは、New YorkTimesAPIから収集