DynomiteデータベースをRedisEnterpriseActive-Activeデータベースに移行する理由
2009年の創設以来、RedisOSSには非常に活気のあるオープンソースコミュニティがあります。多くのツールとユーティリティがその周りで開発されており、非分散データストアのピアツーピア地理的分散レイヤーであるDynomiteはその1つです。
Dynomiteは、Netflixのエンジニアのチームによって開発され、オープンソースとしてリリースされました。特定のニーズに対応する優れたソリューションを提供してきましたが、ここ数年は効果的に維持されていません。さらに、Redis OSSの機能、コマンド、データタイプの一部(Pub / SubやStreamsなど)は、DynomiteのRedisOSSインスタンスの配布モデルによって使用できなくなったり制限されたりします。
このため、組織がDynomiteデータベースをRedisEnterpriseクラスターに移行するのを支援してきました。
DynomiteとRedisEnterpriseのアーキテクチャの比較
DynomiteとRedisEnterpriseの両方のアーキテクチャの簡単な説明から比較を始めましょう。
ダイノマイト
典型的なダイノマイトクラスターは次のように説明できます。
- 複数のデータセンターにまたがっています
- 単一のデータセンターはラックのグループです
- ラックはノードのグループです。各ラックはデータセット全体を保持し、そのラック内の複数のノードに分割されます。
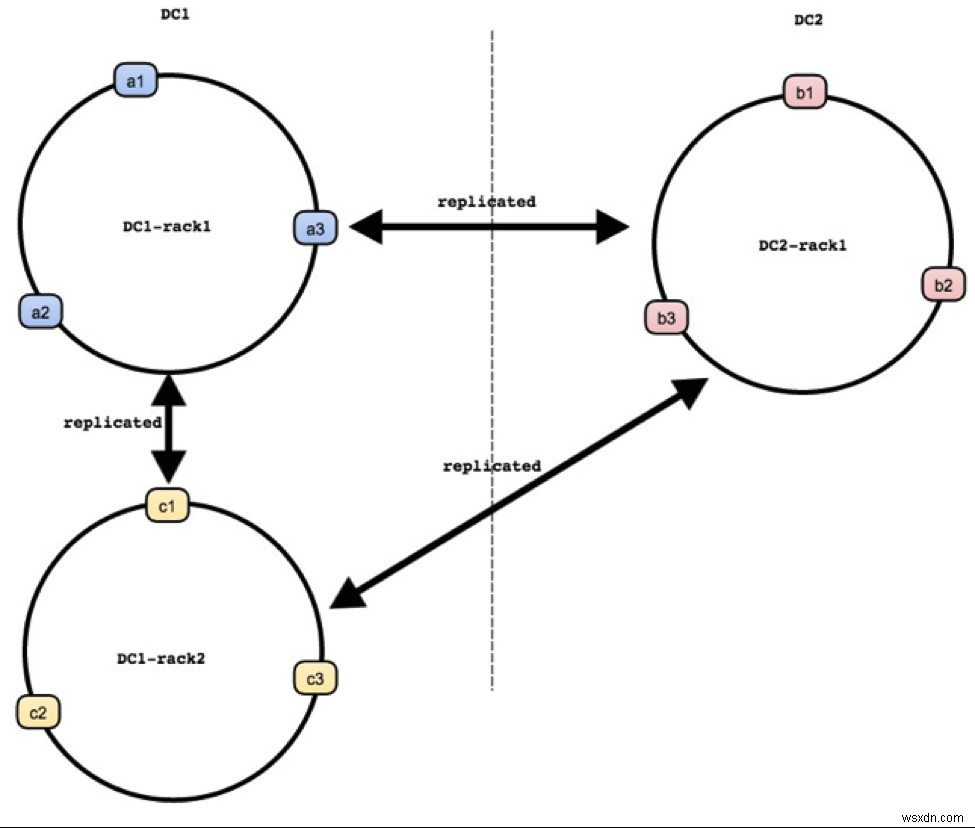
Dynomiteはピアツーピアの分散レイヤーであるため、クライアントは書き込みトラフィックをDynomiteクラスター内の任意のノードに送信できます。ノードがデータの責任者である場合、データはローカルのRedis OSSサーバープロセスに書き込まれ、すべてのデータセンターのクラスター内の他のラックに非同期で複製されます。ノードがデータを所有していない場合、ノードはコーディネーターとして機能し、同じラック内のデータを所有しているノードに書き込みを送信します。また、他のラックやDCの対応するノードへの書き込みを複製します。
Redis Enterprise
Redis Enterpriseクラスターは、異なるRedisインスタンスまたはシャードにもデータを分散しますが、主に2つの違いがあります。
- 1つのノードに複数のシャードが存在する可能性がありますが、高可用性を実現するために、プライマリとレプリカを同じノードに配置することはできません。
- プライマリシャードごとにレプリカは1つだけです。クライアントは、プライマリシャードでデータ操作を実行します。それぞれのレプリカは、プライマリシャードに障害が発生した場合の高可用性のために存在します。
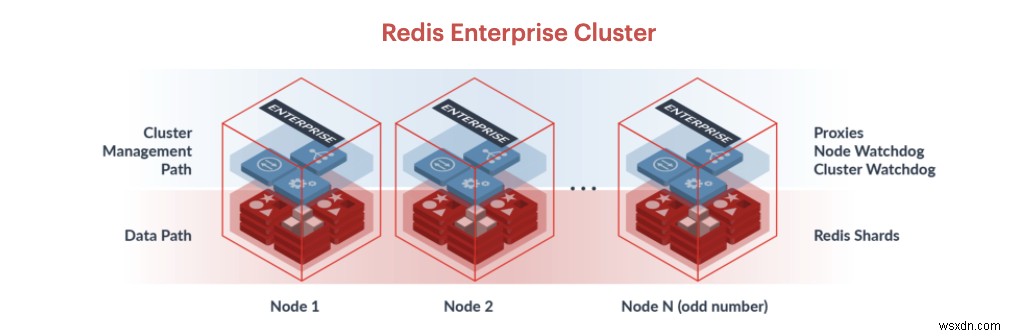
Redis Enterpriseクラスターのもう1つの重要な部分は、いわゆる「管理パス」です。これには、クラスターマネージャー、プロキシ、およびREST API/UIが含まれます。クラスタマネージャは、クラスタの調整、高可用性ノードへのデータベースシャードの配置、および障害の検出を担当します。プロキシは、クラスター内のデータベースごとに単一の変更されないエンドポイントを提供することにより、RedisEnterpriseのクラスタートポロジをアプリケーションから隠します。また、コマンドをシャードに多重化およびパイプライン化することで、クライアント接続を拡張するのにも役立ちます。
これは、典型的なRedisEnterpriseClusterの図です。
Redis Enterpriseのアクティブ-アクティブ機能を使用すると、複数のクラスターにまたがるグローバルデータベースを作成できます。これらのクラスターは通常、世界中のさまざまなデータセンターに存在します。 Active-Activeデータベースに書き込むアプリケーションは、ローカルインスタンスエンドポイントに接続します。アプリケーションによるローカルインスタンスへのすべての書き込みは、結果整合性が高い他のすべてのインスタンスに複製されます。
アクティブ-アクティブレプリケーションは、地理分散ソリューションとして多くの利点を提供します。その1つは、単純および複雑なRedisEnterpriseデータタイプのシームレスな競合解決です。これについては以下で説明します。
DynomiteとRedisEnterpriseのトポロジがわかったので、それらが開発者と組織内のDevOpsに何をもたらすかを見てみましょう。
DynomiteまたはRedisEnterprise:開発者にとってどのような違いがありますか?
Dynomiteが積極的に保守されていないことを除けば、組織が開発者の観点からRedis Enterpriseに移行することを望む主な理由は3つあります:
- Dynomiteを使用する場合、Redisの機能は制限され、より複雑になります
- ダイノマイトには、地理的に分散した書き込みの競合に対処する効果的な方法がありません
- Redisから受けられるサポート
最初の2つを詳しく見てみましょう。
限定的で複雑なRedisOSS
おそらくすでにご存知のように、Redis OSSは、文字列キーを文字列値に関連付けることができるだけではないという意味で、単純なキー値ストアではありません。 Redis OSSは、リスト、セット、ハッシュ、ストリームなどのさまざまな種類の値をサポートするデータ構造サーバーです。これらをRedisOSSの「コアデータ型」と呼びます。
Redis OSSは、「モジュール」と呼ばれるダイナミックライブラリを介して拡張することもできます。モジュールを使用すると、コア自体の内部で実行できるのと同様の機能を備えた新しいRedisコマンドを迅速に実装できます。最も人気のあるモジュールには、クエリ、セカンダリインデックス、全文検索を提供するRediSearchと、RedisOSSを強力なドキュメントストアに変えるRedisJSONがあります。
はじめに説明したように、一部のRedis OSSコマンドとデータ型は、Dynomiteによって使用不可または制限されます。これが網羅的ではない比較です:
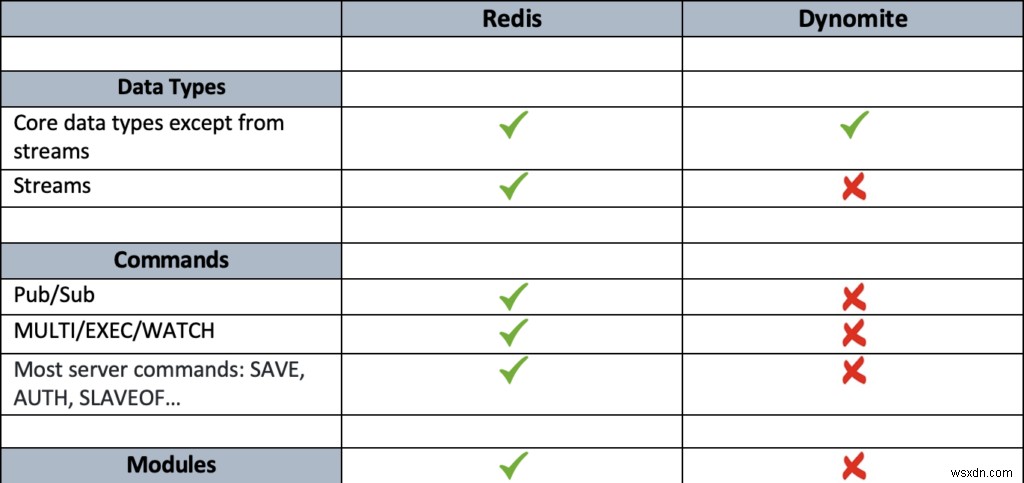
Dynomiteでサポートされているコマンドとサポートされていないコマンドの完全なリストはここにあります。
一方、RedisOSSと一緒に維持されるRedisEnterpriseでは、モジュールを使用したマルチモデル操作と、コアのRedisOSSデータ構造を完全にプログラム可能で分散された方法で実行できます。
紛争解決の欠如
DynomiteはAPシステムであり、一貫性を保つために3つのオプションがあります。どちらのオプションを選択する場合でも、DynomiteはLastWriteWins戦略を適用することで非同期書き込みの競合を解決することに注意することが重要です。これにより、特に地理的に分散された書き込みのコンテキストでは、無関係なタイムスタンプが原因で更新が失われる可能性があります。
一方、Redis Enterpriseのアクティブ-アクティブアーキテクチャは、RedisOSSコマンドとConflict-Free-Replicated-Data-Types(CRDT)と呼ばれるデータ型の代替実装に基づいています。 CRDTは、イベントの順序付けにベクタークロックを使用します。 2つのレプリカが同じ更新セットを受信すると、数学的に適切なルールを採用して状態の収束を保証することにより、決定論的に同じ状態に到達するようにします。さらに、因果整合性を有効にすることもできます。
したがって、Redis Enterpriseの場合:
- 同時書き込みの結果は予測可能であり、一連のルールに基づいています
- アプリケーションは、同時書き込みや書き込みの競合の解決に煩わされる必要はありません
- データセットは最終的に単一の一貫した状態に収束します
気になる場合は、このリンクをたどると、実装されているルールと競合解決の例を見つけることができます。
DynomiteまたはRedisEnterprise:DevOpsにどのような違いがありますか?
次に、次のトピックについて説明することにより、DevOpsの観点からDynomiteとRedisEnterpriseを比較してみましょう。
- 高可用性
- スケーラビリティ
- 展開可能性
高可用性
Dynomiteラック内でノードに障害が発生すると、ラックへの書き込みと読み取りができなくなります。これは、ローカルで書き込みを行うアプリケーションが、別のラックへのフェイルオーバーを単独で処理する必要があることを意味します。アプリケーションがJavaで開発されている場合、NetflixのDynoクライアントは、ローカルのDynomiteノードに障害が発生したときにリモートラックへのフェイルオーバーを処理できることに注意してください。
さらに、ノードが復旧すると、障害時にリモートラックに書き込まれたデータは、障害が発生したノードから失われます。 AWS自動スケーリンググループ内にデプロイする場合は、NetflixのDynomite Managerを使用できます。これは、AWS自動スケーリンググループ内でノードの置き換えとノードのウォームアップを行います。
Redis Enterpriseの高可用性についてはどうですか?
ノードに障害が発生すると、そのノードに存在するすべてのプライマリシャードに対して1桁秒のフェイルオーバーが発生し、それらのレプリカがプライマリにプロモートされます。この自動フェイルオーバーメカニズムにより、データが最小限の中断で提供されることが保証されます。
これに基づく:
- Redis Enterprise Proxyは、データベースのシングルエンドポイントがフェイルオーバーの場合に変更されないことを確認するため、アプリケーションを再構成する必要はありません。
- 「replica_ha」オプションがあり、レプリカがプライマリにプロモートされると、使用可能な他のノードのいずれかに新しい同期レプリカシャードが自動的に作成されます。
これらのメカニズムにより、Redis Enterpriseは、アクティブ-アクティブ展開で99.99%の稼働時間と99.999%の稼働時間を保証できます。
スケーラビリティ
Dynomiteを使用すると、レイテンシーの点で優れたパフォーマンスを維持しながら、RedisOSSをスケーリングできます。ベンチマークを確認することはできますが、Dynomiteを使用している場合は、おそらくすでにそれを知っています。
スケーラビリティに関しては、DynomiteとRedisEnterpriseの主な違いは次のとおりです。
- 管理性
- すぐに使用できる接続管理
- リソースの最適化
管理性
AWS自動スケーリンググループ内でDynomiteManagerを使用していない場合、実行中のDynomiteラックにホストを追加するには、通常、次のものが必要です。
- JavaDynoクライアントを使用した「二重書き込み」手法の活用。アプリケーションは、古い/小さなクラスターと新しい/スケーリングされたクラスターに書き込みます。数日後、トラフィックを新しいクラスターにのみルーティングし、アクティブなクラスターにします。
- データベースを古い/小さなクラスターから新しい/スケーリングされたクラスターに移行する
一方、RedisEnterpriseでは次のことが可能です。
- クラスターにノードを追加せずにデータベースにシャードを追加してスケールアップする:このシナリオは、クラスターに十分に活用されていない容量がある場合に役立ちます。注意:1つのノードは1つのRedisインスタンスと同じではありません。データベースの再シャーディングは、Redis Enterprise UIを介して数回クリックするか、RedisEnterpriseのRESTAPIを利用して実行できます。ダウンタイムやサービスの中断なしに実行されます。また、データベースのエンドポイントは変更されないため、アプリケーションに対して透過的です。
- クラスターにノードを追加してスケールアウトします。このシナリオは、データベースにシャードを追加するためにより多くの物理リソースが必要な場合に役立ちます。フルマネージドDBaaSオファリングであるRedisEnterpriseCloudを使用すると、組織はこのステップについて心配する必要がないことに注意してください。 Redisは、それらのインフラストラクチャとリソースをプロビジョニングおよび管理します。詳細については、この記事の「導入」セクションを参照してください。
これは、Redisが数年前に行ったベンチマークであり、RedisEnterpriseは40のAWSインスタンスで2億回/秒以上をミリ秒未満のレイテンシで提供しました。
接続管理
Redisとの接続管理について話すとき、最初に頭に浮かぶのは、JedisやLettuceなどのRedisクライアントが接続プールとパイプラインをどのように処理するかです。 Netflixも例外ではなく、Dynoクライアントにこれらの機能を実装しました。
Redis Enterpriseは、このような機能をすぐに利用できます。プロキシ自体がクラスター内のシャードへの永続的な接続を確立し、それらの接続はクライアントによって共有されます。また、シャードへの多数の永続的な接続でリクエストをスケジュールし、多重化を実行し、Redis側でパイプライン化することにより、パフォーマンスの最適化を適用します。
さらに、プロキシはマルチスレッドであり、クライアント接続のバーストを処理するために自動的にスケーリングされます。
リソースの最適化
まず、Redis Enterpriseクラスター内では、1台のマシンが1台のRedisインスタンスと等しくなく、各プライマリシャードが持つことができるレプリカは1つまでであることを忘れないでください。
第二に、RedisEnterpriseはマルチテナントです。つまり、単一のRedisEnterpriseクラスターで数百の完全に分離されたデータベースにサービスを提供できます。これは、ダイノマイトを使用して行うのは簡単ではありません。 Redis Enterpriseのマルチテナンシーは、そのマルチモデル機能にうまく適合していることは注目に値します。マイクロサービスのコンテキストでは、それぞれが独自のレプリケーション、スケーリング、永続性、およびモジュール構成を備えた単一のノードセットでさまざまな目的に合ったデータベースを実行することを想像できます。
最後に、Redis Enterpriseには、Redis On Flash(RoF)と呼ばれる機能があります。 RoFを使用すると、データベースでRAMと専用フラッシュメモリ(SSD / NVMe)の両方を使用して、RAMのようなレイテンシとパフォーマンスを備えたはるかに大きなデータセットを処理できますが、全RAMデータベースと比較して70%以上のコストがかかります。
導入オプション
Dynomiteは、Ubuntu、RHEL、およびCentOSを実行しているコンテナーまたはマシンにデプロイできます。クラスタを管理するためのインフラストラクチャとリソースを提供する必要があるという意味で、デプロイメントは常に自己管理されます。さらに、前述のように、Dynomite Managerの機能を利用する場合は、AWS自動スケーリンググループ内にDynomiteをデプロイする必要があります。
一方、Redis Enterpriseには多くの導入オプションがあり、2つのグループに分けることができます。
- Redis Enterpriseソフトウェアを自分でダウンロード、インストール、およびデプロイする自己管理型ソリューション。 Linuxインストーラー(複数のディストリビューション)、Amazon Machine Image(AMI)、Docker Containers、Kubernetes、RedHat OpenShift、Google Kubernetes Engine(GKE)、Azure Kubernetes Service(AKS)、またはAmazon Elastic Kubernetes Service(EKS)を含む多くのオプションがあります。
- マネージドソリューション:Redis Enterprise Cloudは、3つの主要なパブリッククラウドプラットフォーム(Google Cloud、AWS、Azure)すべてでフルマネージドクラウドサービス(DBaaS)として提供されます。 Redisは、アプリケーションが使用するプライベートエンドポイントとパブリックエンドポイントを使用してデータベースを作成できる、必要なリソースを備えた専用の環境をホストします。
-
Nuxt3とサーバーレスRedisの使用を開始する
はじめに アプリケーションの使用状況を追跡したり、リソースの使用率を制限したり、キャッシュからデータをフェッチしてアプリのパフォーマンスを向上させたりする必要がある場合は、Redisがこれらの要件に対する答えであることがわかります。 Redisは、メモリ内のKey-Valueデータベースです。これはオープンソースであり、RemoteDictionaryServerの略です。 この記事では、Upstash、Redisデータベース、およびVueSSRフレームワークの最近のベータリリースであるNuxt3について説明します。これは、Redisデータベースについて説明する初心者向けの記事で、 Nux
-
Redis MOVE –Redisでキーをあるデータベースから別のデータベースに移動する方法
このチュートリアルでは、Redisデータストア内のあるデータベースから別のデータベースにキーを移動する方法について学習します。このために、コマンドを使用します– MOVE redis-cliで。 このコマンドは、現在選択されているデータベースから指定されたキーを削除し、同じキーを宛先に挿入するために使用されます データベース。キーがソースデータベースに存在しない場合、またはキーが宛先データベースにすでに存在する場合、操作は実行されず、0が返されます。 redis MOVEコマンドの構文は次のとおりです:- 構文:- redis host:post> MOVE <key&g