リアルタイムデータベースを使用した不正の検出と財務データの保護
リアルタイムデータプラットフォームを使用した金融詐欺との戦い 、金融詐欺の最新トレンド、企業が効果的に反撃する方法、およびRedisが企業がこれらの目標を達成するのをどのように支援しているかにスポットライトを当てた重要なホワイトペーパー。以下から無料でダウンロードしてください。
詐欺の蔓延は現実のものであり、金融機関はサイバー犯罪者の進行中の猛攻撃と変化する戦術に追いつくのに苦労しています。世界的な金融サービスの状況が進化するにつれて、詐欺師はデジタルバンキングの変革と並行して動き、顧客のIDを盗んだり偽造したり、詐欺を犯したりする革新的な方法を見つけています。
パンデミック以来、リテールバンキングの顧客の約35%がオンラインバンキングの利用を増やし(デロイト、2020年)、その採用に飛躍的な進歩をもたらしました。さらに、世界の人口の約53%が2026年までにデジタルバンキングを使用すると予想されています(Juniper Green、2021年)。
消費者がデジタルバンキングに移行するにつれて、オンライン詐欺が増加し、状況は悪化しています。最近の調査によると、企業の47%が過去数年間に不正を経験しており(PwC、2020)、推定420億ドルを奪っています。
銀行と支払い処理業者は、不正が発生する前にそれを検出するために懸命に取り組んでいますが、犯罪者の進化する戦術に追いつくのに苦労しています。これは、静的な知識ベースのID検証、ルールベースのシステムに加えて、他のチャネルに接続せずに1つのチャネルを介して不正を発生させる低速のサイロ化されたシステムに継続的に依存しているためです。
ルールのみのシステムは、ブラックリストやユーザーの購入プロファイル履歴の検証など、単純で変化のない既知のパターンを効果的に検出します。ただし、リスクと通常の行動を区別するのに苦労しています。
個人情報の盗難、アカウントの乗っ取り、およびレガシーシステムの硬直性により、進化する現実のシナリオに適応できなくなります。銀行や金融サービス機関は、デジタルIDを活用し、AI / MLトランザクションのリスクスコアリング、統計分析、異常検出などの補完的なメカニズムを追加することで、ルールベースの不正検出システムを強化する多層アプローチに移行する必要があります。
機械学習(ML)アルゴリズムと人工知能(AI)予測モデルは、履歴およびリアルタイムのトランザクション情報に基づいて不正を分析および検出するときに進化し、学習することができます。ただし、データパイプラインのサイズと複雑さのため、AI / MLの実装の成功は、正確なモデルだけでなく、周囲のデータインフラストラクチャのパフォーマンスと復元力にも依存します。
取引詐欺

オンラインバンキングへの急激な変化により、あらゆる種類のオンライン詐欺が急増しています。最近の調査では、状況の深刻さが強調されており、2021年の米国銀行の不正費用の33%がオンラインバンキングによるものであり、2020年から26%増加しています(ABA Banking Journal、2022)。
また、2021年の第1四半期には、オンラインバンキングがすべての銀行取引の96%を占め、詐欺の試みの93%を占めました(セキュリティ、2021年)。
多くの金融サービス組織は、不正と戦い、データセキュリティを強化するためにMLおよびAIテクノロジーに目を向けています。 AI / MLモデルは、高度な数学的および統計的アルゴリズムを使用してパターンと導出された推論を活用してリスクを特定し、特定の結果が発生する相対的な可能性のランク順とスコアをすばやく決定します。これらのアルゴリズムは、トランザクションの個々のコンポーネントを分析し、それが不正、不正、または盗まれたクレジットカードからのものである可能性を判断するために使用されます。
AI / MLモデルアルゴリズムは、以前のトランザクションから導出された推論を保存することにより、反復ごとに学習できます。これにより、時間の経過とともに、リスク評価とスコアリングの精度が向上します。彼らは、新しい不正シナリオを処理するために、変化する生体認証の動作とトランザクションパターンに適応できます。
AI / MLを使用すると、金融機関は自動化されたトランザクションスコアリングシステムを活用して、トランザクションを予測し、クレジットスコアを調整し、高効率で不正を検出できます。リアルタイムのトランザクションスコアリングアルゴリズムは、トランザクションの詳細、ユーザープロファイル、行動バイオメトリクス、ジオロケーション、IP /デバイスメタデータ、ユーザーの財務情報などを考慮します。
ただし、AI / MLモデルの有効性は、トランザクションデータにアクセスできる速度に依存します。機械学習アルゴリズムは、オフラインとオンラインの特徴ストアから得られたデータの組み合わせから予測を行います。どちらもデータパイプラインアーキテクチャで重要な役割を果たします。
不正検出システムのオフライン機能ストアには、たとえば、各ユーザーが銀行口座をどのように操作したかに関する履歴データが含まれています。ユーザーによる各トランザクションは、数百の異なる機能に分割され、その個人の通常の行動の個人ログが作成されます。このログには、同様のトランザクションの頻度、要求された金額、場所のIPアドレスなどの重要なデータが含まれます。
パターンが識別され、各ユーザーがアカウントをどのように操作するかを表すデジタルプロファイルが作成されます。ただし、これは静的データであり、定期的に更新されるため、機械学習モデルがリアルタイムで発生しているトランザクションの不正予測を行うには不十分です。
ここで、オンライン機能ストアが役立ちます。ユーザーがトランザクションを行うと、オンライン機能ストアはさまざまなストリーミングソース間でリアルタイムデータを収集し、履歴データと比較します。
機械学習アルゴリズムは、何百もの異なる機能間のこれらの比較を使用して、不整合があるかどうかを判断します。たとえば、ベンがスペインにいて、5分後にドイツでもう一度購入した場合、機械学習アルゴリズムはこれを不正の可能性のあるケースとしてフラグを立てます。
しかし、これらの計算の全体的な有効性は、リアルタイムデータを提供するオンライン機能ストアに依存しています。トランザクションを承認または拒否する決定は、不正行為を遮断するために正確かつ瞬時に行う必要があります。
オンライン機能ストアを活用すると、次のようなさまざまな支払いメカニズムでの不正行為を防ぐことができます。
- クレジットカードとデビットカードの支払い
- 人から人への転送
- 銀行口座の貸方と借方
- モバイルウォレットと電子決済
顧客を知る

銀行は、しばらくの間、KYC(Know-Your-Customer)規制に従わなければなりませんでしたが、これらは依然として金融詐欺と戦うための好ましい方法です。ただし、それらの多くは依然としてナレッジベース認証(KBA)に依存しているため、使用するデータは静的であり、信頼性や安全性を確保するのに十分な頻度で更新されません。 EquifaxとCapitalOneでの最近のデータ侵害は、IDデータが盗まれ、詐欺やアカウントの乗っ取りに使用される可能性があることを示しています。
銀行は機敏であり、不正行為を迅速に払拭できる迅速な意思決定を行うスピードを備えている必要があります。名前、住所、社会保障などのKBA基準に基づいてこれらの決定を行うことで、犯罪者は銀行のデータセキュリティシステムを巧みに操る余地があります。
より強力な形態のサイバーセキュリティを作成し、データセキュリティシステムを強化し、データ侵害のリスクを軽減するには、より高度なテクノロジーが必要です。そのため、多くの銀行が動的なデジタルIDに目を向けています。これらの最新のアプローチにより、ドキュメントの検証と生体認証の記録を複雑な行動パターンと組み合わせて、各ユーザーのデジタルIDを作成できます。
これにより、アカウントに強力な南京錠がかけられ、犯罪者がデジタルIDを偽造または模倣することがはるかに困難になります。しかし、繰り返しになりますが、速度が重要な要素です。デジタルIDは複雑で、さまざまなソースとデータタイプで構成されています。難しいのは、銀行がユーザーエクスペリエンスを妨げることなく、犯罪者の一歩先を行くのに十分な速さですべてを更新できることです。
犯罪の地下世界が銀行と一致して進化しているという事実を考えると、これはさらに困難です。合成デジタルIDを作成することにより、詐欺を実行するための賢明な方法を発見します。これは、実際の顧客情報と偽の顧客情報を新しいIDにブレンドするプロセスです。これは、たとえば、社会保障番号を盗み、それを使用して偽の誕生日や自宅の住所を作成する場合があります。金融界は、合成詐欺の脅威を十分に認識しており、これは2020年だけで米国の銀行に200億ドルの損失をもたらしました(ABA Banking Journal、2021)。
詐欺師は、すべての支払いが時間どおりに支払われるようにし、リスク要因を示さないように信用履歴を構築することで、検出されないようにする方法を知っています。これにより、銀行にとって合成詐欺の検出はほぼ不可能になります。このタイプのID詐欺に対する最善の防御策は、アカウントの作成時または初期のトランザクション/支払いプロセス中にそれを検出することです。
これらの犯罪者に十分な時間が与えられた場合、偽の情報を変更して追加のデジタルIDを作成することにより、詐欺サイクルの次のステップに進むため、これは重要です。つまり、偽のIDのネットワークを構築して作成し、最終的には銀行口座、電話番号、社会保障番号などの1つ以上の情報と接続して共有します。
これは、銀行がユーザーの個人情報間のこれらの接続を識別することにより、不正行為を検出する機会を提供します。
解決策は、データポイント間の関係をモデル化する一連のノードおよびエッジとしてデータを表現および格納するグラフデータベースを使用することです。不正およびデータセキュリティアナリストは、顧客(デジタルID)および/またはトランザクション属性のグラフを、できればリアルタイムでトラバースすることにより、疑わしい接続またはパターンを検出できます。
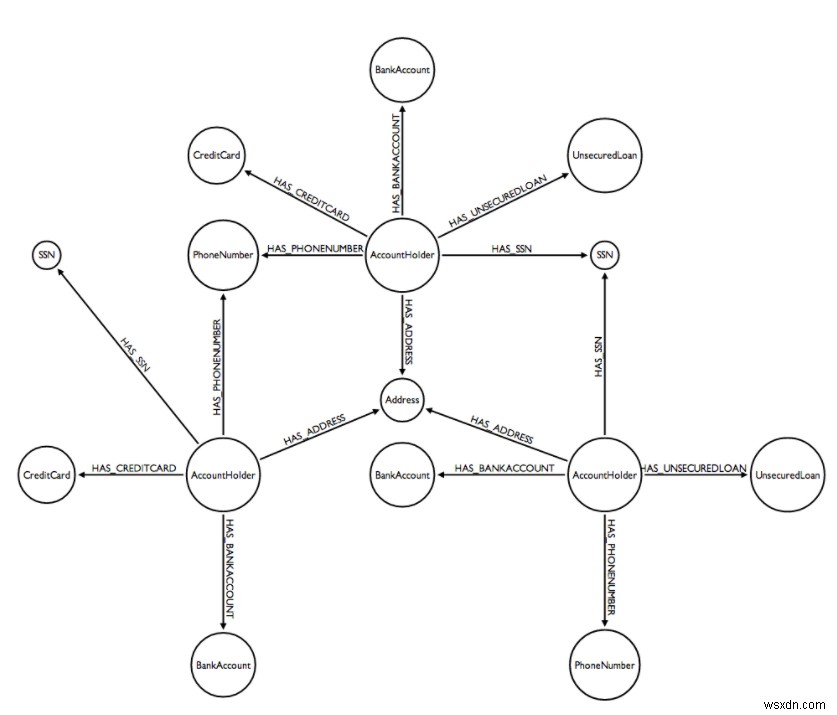
これらの犯罪者の先を行くために、銀行は、デジタルIDを最新の状態に保ち、IDグラフを作成してリアルタイムで合成詐欺を検出するために必要な高スループットを実現できる、低遅延のメモリ内マルチモデルデータベースを活用する必要があります。
このリアルタイムデータベースは、従来のリレーショナルデータベースよりも高速で柔軟性があり、銀行が顧客を正しく識別し、疑わしいトランザクションにフラグを立てる最高の機会を提供します。
マネーロンダリング防止(AML)

汚いお金はロンダリングされる必要があり、銀行は不法に富を蓄積するために詐欺師によって利用される好まれたチャネルの1つです。現実には、マネーロンダリングは問題があるのと同じくらい普及しています。この疫病との闘いは依然として最上位の課題ですが、犯罪者は依然としてシステムを混乱させる方法を模索しています。
推定2兆ドルが毎年世界中でロンダリングされており(Deloitte、2020)、マネーロンダリングの50%が業界全体で検出されていません(Renolon、2022)。政府は、より厳格なAML規制の導入を通じて、より警戒し、取引を検証するために銀行への圧迫を強化しています。
AML関連の罰金は近年高くなっており、2020年末までに世界中で総額104億ドルに達し(コンプライアンスウィーク、2020年)、金融機関がマネーロンダリング法を遵守していないことを浮き彫りにしています。しかし、コンプライアンス担当者の62%が、犯罪行為を見つけるのが難しくなっていると述べているため(Renolon、2022)、銀行はマネーロンダリングを抑制してサイバーセキュリティを強化するための新しく革新的な方法を見つける必要があります。
多くの銀行は、AIとデジタルIDテクノロジーを活用して、トランザクション監視システムを強化し、マネーロンダラーを排除しています。たとえば、ネットワーク分析は、従来の方法では見落とされる可能性が高いエンティティ間の隠れたリンクを特定するのに役立ちます。
それでも、AMLコンプライアンスプログラムの要は、リアルタイムで多くの変数にわたるトランザクションスコアリングを提供できる監視システムです。分析する必要のあるデータは膨大であり、すべてを処理できる速度によって、銀行が疑わしい取引をどの程度うまく特定できるかが決まります。
銀行は不正を取り締まるためにリアルタイムデータベースを必要としています
私たちは、犯罪者が進化し、詐欺を犯すために偽のIDを盗んで作成するための賢明な方法を発見した、ペースの速い環境に住んでいます。銀行はデジタル時代に適応し、最新のAI/MLベースの不正検出と動的なデジタルIDをサポートできない厳格で低速なレガシーRDBMSシステムから離れる必要があります。
その結果、多くの銀行は、より機敏で応答性が高く、不正への取り組みに熟達するために、リアルタイムデータベースに目を向けています。ネイティブモジュールを備えたRedisEnterpriseRedisJSON、RediSearch、RedisGraph、RedisTimeSeries、およびRedisBloomは、複数のデータモデルを効率的に処理し、疑わしいパターンを特定できるため、多くの金融サービス会社で活用されています。
トランザクションのパターンを迅速に分析し、デジタルID用の新しいツールでKYCプログラムを強化するために必要なリアルタイムアクセスを不正検出プラットフォームに提供することで、銀行に力を与えます。 Redis Enterpriseは、金融サービス企業に、ミリ秒未満のパフォーマンス、グローバルスケーラビリティ、99.999%の稼働時間、マルチクラウドサポートなどを備えたミッションクリティカルなインメモリデータベースを提供します。
Redis Enterpriseがリアルタイムの不正検出を強化する方法の詳細については、このホワイトペーパーをお読みください。
-
DBAとデータアーキテクトの進化
企業の顧客、従業員、およびパートナーがユーザーフレンドリーなシステムを介してデータに簡単にアクセスできる場合、データベース管理者とデータアーキテクトの2人に感謝します。十分に構築されたデータベースが潜在的に数千または数百万のユーザーに対して確実かつ安全に機能することを保証することは大きな責任であり、あらゆる業界の企業は、データアーキテクトとDBAに依存して、それらを使用するすべてのユーザーのニーズを満たすデータネットワークを設計および監視します。 ビジネスコミュニティのデータニーズが急増するにつれて、最新のデータベーステクノロジーに対応するために必要なスキルも拡大しています。これらの役割の
-
Nuxt3とサーバーレスRedisの使用を開始する
はじめに アプリケーションの使用状況を追跡したり、リソースの使用率を制限したり、キャッシュからデータをフェッチしてアプリのパフォーマンスを向上させたりする必要がある場合は、Redisがこれらの要件に対する答えであることがわかります。 Redisは、メモリ内のKey-Valueデータベースです。これはオープンソースであり、RemoteDictionaryServerの略です。 この記事では、Upstash、Redisデータベース、およびVueSSRフレームワークの最近のベータリリースであるNuxt3について説明します。これは、Redisデータベースについて説明する初心者向けの記事で、 Nux