Redisを使用したJSONドキュメントのインデックス作成、クエリ、および全文検索
RedisJSONとRediSearchは、クラウドで最も人気のあるRedisモジュールです。 (図1を参照)RedisJSONとRediSearch(Redisにバンドルされている)のDockerイメージは、毎日2000回以上プルされています。これが、RedisのテクノロジーエバンジェリストであるItamar Haberが、4年前に最初のバージョンを書いたときの先見の明があると考える理由です。 4月に、RedisConfで、JSON、インデックス作成、全文検索機能に関連するいくつかの発表を行いました。本日、これらの機能のプライベートプレビューを発表できることをうれしく思います。
このブログでは、現在のRedisJSON機能の概要を説明します。その後、このプライベートプレビューの新機能のセクションに飛び込みます。 RediSearchを使用してJSONドキュメントのインデックス作成、クエリ、および全文検索を使用する機能は、このリリースの最も優れた新機能です。最後に、すばやく開始する方法を説明します。
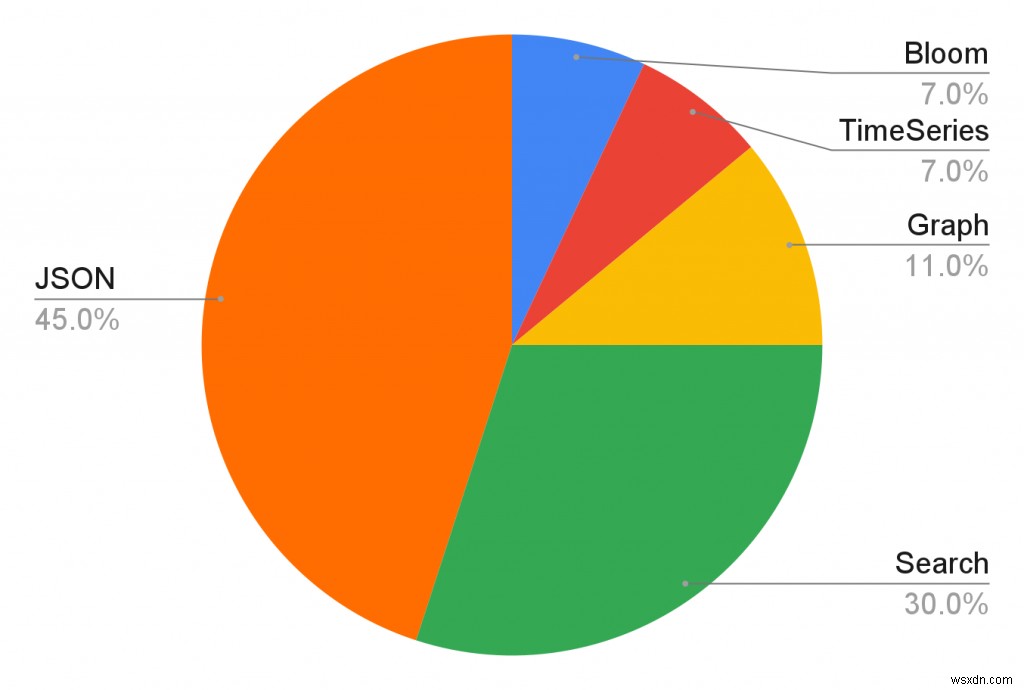
JSON機能
RedisJSONがない場合は、文字列データ構造を使用して、Redisでネストされたドキュメントをモデル化します。
しかし、ドキュメントのサブパートを更新する必要がある場合はどうなりますか?
操作の原子性を維持するには、次のことを行う必要があります。
- ドキュメントを見る
- 以前のバージョンを読んで逆シリアル化する
- Redisトランザクションに更新を埋め込みます
- JSONにシリアル化してドキュメントを更新する
- トランザクションを実行します
このプロセス中に別のクライアントがドキュメントを更新した場合は、これらすべての手順を再試行する必要がある場合があります。
ただし、RedisJSONを使用すると、この更新を単一のアトミックトランザクションで実行できます。 :
別の例を見てみましょう。大きなJSONがありますが、アプリケーションでそのドキュメントのサブパートのみが必要です。
RedisJSONなし:
次のことを行う必要があります:
- 文字列としてシリアル化されたjson文字列全体を取得します
- JSONを逆シリアル化する
- 必要なサブパートを抽出します
RedisJSONを使用すると、1つのコマンドで必要なデータのみを取得できるため、CPUサイクル、ネットワークオーバーヘッド、そして最も重要なこととして、遅延を最小限に抑えることができます。
ご覧のとおり、RedisJSONはJSONドキュメントの操作を簡素化します。 RedisJSON(v1.0)の現在のGAバージョンは、コミュニティがすでに広く使用しているバージョンであり、文字列データ構造を使用してネストされた構造をモデル化する際の欠点を正確に解決します。主な機能の概要は次のとおりです。
Redisのキーに関連付けられたJSONドキュメントを保存(または更新)する
サブパーツ(キーの文字列値など)を置き換えます
コレクションまたはマップにアイテムを追加する
ドキュメント全体を抽出する
JSONPathのサブセットを使用してその一部を抽出します
RedisJSON 2.0:プライベートプレビューリリース
このバージョンはRedisConf2021で発表しました。本日、Redis Enterpriseのお客様の一部のグループのプライベートプレビューとして、またコミュニティへのリリース候補として利用できることをお知らせします。このバージョンには、JSONPath式の完全なサポート、Active-Active(Redis Enterpriseを使用)のサポート、およびRediSearchを使用したJSONドキュメントのインデックス作成、クエリ、および全文検索の使用という3つの主要な機能があります。しかし、もっとあります!新しいグッズに飛び込みましょう。
RUSTで書き直されました
システムプログラミング言語は、効率を重視した言語のファミリーです。これらの言語で書かれたプログラムは通常軽量で、最高のパフォーマンスを提供します。これが、Redisが歴史的にCで記述されてきた理由です。また、Redisが非常に低いレイテンシと高スループットを実現できる理由も説明しています。ほとんどのRedisモジュールは、同じファミリの言語であるC、C ++、またはRustで記述されています。
JSONは、非常に高速で効率的なJSONシリアル化やJSONPath実装など、Rustコミュニティによって特によく提供されています。これらの実装のメリットをRedisユーザーに提供することは明らかであり、RedisモジュールAPIとRustの間のマッピングが必要でした。
JSONPathの完全サポート
そして、これがこのRUST書き換えの利点です。この新しいバージョンには、JSONPathの包括的なサポートが含まれています。 JSONPath式の表現力をすべて使用できるようになりました。
JSONドキュメントを指定
ワイルドカード(以前は最初のアイテムに限定されていました)
スライスを抽出する
フィルター式を使用したより高度な例
アクティブ-アクティブのサポート
アクティブ-アクティブは、RedisEnterpriseによって提供される機能です。 Active-Activeを使用すると、データベースを地理的に分散した複数のRedisEnterpriseクラスターに複製できます。ユーザーは、ローカルの読み取りおよび書き込みレイテンシーで最も近いクラスターに接続できます。
実装は、競合のないレプリケートされたデータ型(CRDT)テクノロジに基づいています。 Redisでサポートされているほとんどのコアデータ構造に実装する一方で、Redisは、JSON用に作成されたこの新しい実装によって確認された強力な知識と経験を開発しました。
アプリケーション開発者は、これを利用して、JSONドキュメントを使用して地理分散型アプリケーションを構築できるようになりました。次に、2つのクラスターを持つアクティブ-アクティブ環境での一連の操作の例を示します。
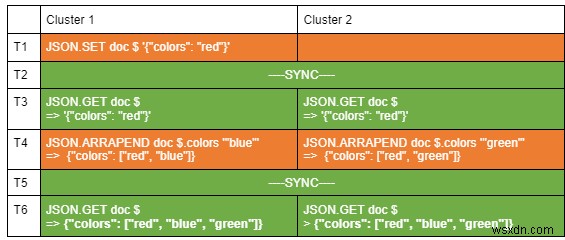
各操作の詳細を見てみましょう:
- T1:クライアントがクラスター1にJSONドキュメントを設定します。
- T2:同期プロセスは、クラスター2にドキュメントを複製します。
- T3:両方のクラスターに同じドキュメントが含まれています。
- T4:クライアントがクラスター1のcolors配列に青色を追加し、同時に、別のクライアントがクラスター2の同じ配列に緑色を追加しています。
- T5:同期プロセスは操作をマージし、両方のクラスターのドキュメントを更新します。
- T6:両方のクラスターに同じドキュメントが含まれています。
この機能がパブリックプレビューにある場合のすべての同期フローについて詳しく説明しますが、この機能に興味がある場合は、support@redis.comまでお気軽にご連絡ください。
RediSearch 2.2:プライベートプレビューリリース
このブログでは、RediSearch 2.2のプライベートプレビューが利用可能になったことも発表しています(Redis Enterpriseのお客様の一部のグループのプライベートプレビューとして、またコミュニティのリリース候補として)。
このセクションでは、RediSearchのこの新しいリリースによって提供される新機能について説明します。しかし、最初に、これら2つの人気のあるモジュールを一緒にリリースする理由は次のとおりです。
JSONドキュメントのインデックス作成、クエリ、全文検索
この特定の新機能により、RedisのJSON機能がまったく新しいレベルになります。これまで、RediSearchは、Key-Valueストアであるだけでなく、ハッシュのインデックス作成および検索機能を提供してきました。内部的には、RedisJSON2.0は内部パブリックAPIを公開しています。内部。このAPIは、Redisノード内で実行されている他のモジュールに公開されているためです。すべてのモジュールがこのAPIを使用できるため、パブリック。 RediSearch 2.2もそうです!
RedisJSONは、その機能を他のモジュールに公開することで、RediSearchにJSONドキュメントのインデックスを作成する機能を提供し、ユーザーがコンテンツのインデックスとクエリによってドキュメントを検索できるようにします。これらの組み合わされたモジュールは、強力で低レイテンシのJSON指向のドキュメントデータベースを提供します !
これがどのようになるか見てみましょう。
まず、JSON.SETコマンドを使用してデータベースにJSONドキュメントを入力する必要があります。
新しいインデックスを作成するには、FT.CREATEコマンドを使用します。インデックスのスキーマがJSONPath式を受け入れるようになりました。式の結果はインデックス付けされ、属性(ここではタイトル)に関連付けられます。
これで、検索クエリを実行し、FT.SEARCHを使用してJSONドキュメントを見つけることができます:
JSONドキュメントの集計
集計はRediSearchの強力な機能であり、分析レポートの作成やファセット検索スタイルのクエリの実行に使用できます。 RediSearchがJSONドキュメントにアクセスできるようになったため、JSONPath式を使用してJSONドキュメントから任意の値を読み込み、値がインデックス付けされているかどうかに関係なく、パイプラインで使用できます。
インデックスを作成しましょう:
JSONドキュメントをデータベースに追加します:
そして、JSONドキュメントから抽出された2つの数値を使用して簡単な計算を行います。
インデックス作成戦略の柔軟性の向上
新しいバージョンのRediSearchでは、同じ値(ハッシュのフィールド、またはJSONドキュメントのJSON値)に異なるパラメーターでインデックスを付けることができるようになりました。この新機能によって解決される典型的なユースケースは次のとおりです。
カテゴリに属するドキュメントを含むデータベースを作成しましょう。
TAGタイプを使用すると、任意のカテゴリで検索結果を簡単にフィルタリングできます。
しかし、カテゴリで全文検索も実行できるようにしたい場合はどうでしょうか。
これまで、ハッシュを使用すると、値を2つのフィールドに複製する必要があり、メモリを2倍消費していました。
ここでFT.CREATE…ASが便利になりました。素晴らしくシンプルなドキュメントに戻りましょう:
…そして新しいAS機能を使用します:
…そして…
ビンゴ!これで、タグでフィルタリングし、データを複製することなく同じフィールドで全文検索を実行できます。
クエリプロファイリング
ほとんどのRedisコマンドの時間計算量は十分に文書化されています。例として、HMGETにはO(N)の複雑さがあります。ここで、Nは要求されているフィールドの数です。 RediSearchを使用すると、高度なクエリを作成できます。ただし、FT.SEARCHコマンドとFT.AGGREGATEコマンドの複雑さは、クエリの複雑さに依存します。
クエリが実行されたときに内部で何が起こっているかを理解し、時間が消費される場所と、クエリを最適化する方法を理解するためのツールを提供したいと考えました。新しいFT.PROFILEコマンドは、RediSearchがクエリを実行するために使用する主な手順を示すツリーを返します。ステップごとに、時間情報が提供されます。
では、あいまい検索でクエリを実行すると、RediSearch内で何が起こりますか?
例を見てみましょう:
クエリのプロファイルを作成する準備ができました。プロファイリングを実行して、プロファイリング結果を分解しましょう。
redis.cloud:6379> FT.PROFILE idx SEARCH LIMITED QUERY "%hello%"
まず、結果を取得します。プロファイリングクエリが期待どおりのものを返すことを確認するのに役立ちます。
これは、プロファイル情報の収集に費やされた時間を含むため、「プロファイル時間」と呼ばれる合計時間です。
クエリの解析と実行プランの作成に費やされた時間:
辞書であいまい一致を見つけるのに費やした時間は次のとおりです。
そして最後に、検索結果を作成することの意味を疑問に思ったことはありませんか?各ドキュメントのフルテキストスコアを計算し、スコアで並べ替えて、最後にフィールドをロードする必要があります。この情報を使用して、ボトルネックを特定し、クエリを高速化し、サーバーのパフォーマンスを向上させることができます。
開始方法
これらの新機能は、アプリケーション開発者とRedisコミュニティにとってゲームチェンジャーであると信じています。開始方法は次のとおりです。
プレビューのDockerイメージを使用する
開始するには、:previewタグを使用して次のDockerイメージをプルできます:
docker run -p 6379:6379 redis/redismod:previewまたは、両方のリポジトリでRC1リリースタグ(RediSearchの場合はv2.2.0、RedisJSONの場合はv2.0.0)からコンパイルして、Redisにロードすることもできます。
起動して実行したら、上記のすべてのコマンドまたはこのクイックスタートガイドを試すことができます。 RedisMartに関する一連のブログも立ち上げます。 、RedisConf 2021の基調講演で紹介したオンライン小売アプリケーション。RedisMartは、地理的に分散した方法で展開されたRediSearchとRedisJSONを活用して、最高のオンライン小売体験を提供します。このシリーズでは、このアプリケーションの構築方法を段階的に説明します。
互換性のあるクライアントの最新バージョンを使用して開発する
次のクライアントのリストは現在アップグレードされているため、優れた開発者エクスペリエンスで新機能を使用できます。最新のリリースやプルリクエストを確認してください(現時点では、それらのほとんどがマスターブランチのプレビューバージョンをサポートしています)。
| RedisJSON | RediSearch | |
| Node.js | redis-modules-sdk | redis-modules-sdk |
| Java | JredisJSON | JRediSearch |
| .NET | NRedisJSON | NRediSearch |
| Python | redisjson-py | redisearch-py |
コミュニティに参加する
一般提供に向けて取り組んでいる間、フィードバック、バグレポート、機能リクエストを歓迎します。ドキュメントのWebサイト、またはRediSearch(Github上)またはRedisJSON(Github上)のgithubリポジトリにフィードバックを残すか、Discordでご連絡ください。
-
Flutter、サーバーレスフレームワーク、Upstash(REDIS)を備えたフルスタックサーバーレスアプリ-パート2
このチュートリアルシリーズのパート2へようこそ。最初のパートでは、Upstash、Serverless Framework、およびRedisを使用してRESTAPIを構築する方法を説明しました。 このパートでは、Flutterを使用してモバイルアプリケーションを構築し、RESTAPIエンドポイントを使用します。 始めましょう🙃 まず、フラッターをコンピューターにインストールして実行する必要があります フラッター IDEで新しいフラッタープロジェクトを作成し、任意の名前を付けます。 pubspec.yamlを開きます flutterプロジェクトのルートディレクトリにあるファイルを
-
Flutter、サーバーレスフレームワーク、Upstash(REDIS)を備えたフルスタックサーバーレスアプリ-パート1
この投稿では、データを保存するためのFlutter、Serverless Framework、Upstash、Redisを使用してサーバーレスモバイルアプリケーションを構築します。 Upstashとは? Upstashは、Redis用のサーバーレスデータベースです。 Upstashを使用すると、リクエストごとに支払います。これは、データベースが使用されていないときに課金されないことを意味します。 Upstashはデータベースを構成および管理します。これは、DynamoDBやFaunaなどの他のデータベースの強力な代替手段であり、などの利点があります。 低レイテンシ REDISAPIと同