Redisを使ったごちそうの開始:機械学習機能ストアのクイックスタートチュートリアル
このチュートリアルでは、ステップバイステップのFeastforRedisクイックスタートを提供します これは、機械学習のオンライン機能ストアとしてFeastwithRedisを使用するエンドツーエンドの例を示しています。これはFeastQuickstartチュートリアルに基づいていますが、デフォルトのオンラインストアを使用する代わりに、Redisオンラインストアを使用して大規模なリアルタイム予測を提供します。 FeastまたはRedisに慣れていない場合は、Redisを使用してFeastを開始する最も簡単な方法は、このチュートリアルを使用することです。高レベルの紹介については、このFeature Stores and FeastusingRedisブログ記事を参照してください。このチュートリアルの最後に、RedisとFeastの詳細情報、および追加のリソースがあります。
このチュートリアルでは、次のことを行います。
- ParquetファイルオフラインストアとRedisオンラインストアを使用してローカル機能ストアをデプロイします。
- Parquetファイルのデモ時系列機能を使用してトレーニングデータセットを構築します。
- 機能値をオフラインストアからRedisオンラインストアにマテリアライズ(ロード)します。
- Redisオンラインストアの最新機能を読んで推論してください。
以下のガイド手順に従って、GoogleColabまたはローカルホストでチュートリアルを実行できます。

饗宴(フィー ture st ore)はオープンソースの機能ストアであり、Linux Foundation AI&DataFoundationの一部です。低レイテンシのオンラインストア(リアルタイムサービスの場合)またはオフラインストア(モデルトレーニングまたはバッチサービスの場合)からモデルに機能データを提供できます。また、中央レジストリを提供するため、機械学習エンジニア およびデータサイエンティスト MLのユースケースに関連する機能を見つけることができます。以下は、Feastの高レベルのアーキテクチャです:
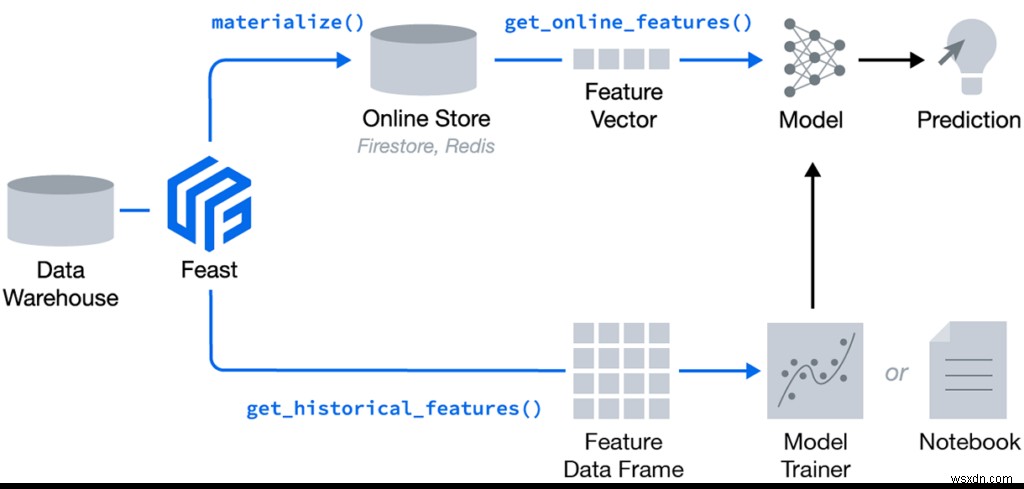
FeastはPythonライブラリ+オプションのCLIです。このチュートリアルですぐに説明するように、pipを使用してFeastをインストールできます。
Feast with Redisは、このフローのいくつかの一般的な問題を解決します:
- トレーニング-スキューと複雑なデータ結合の提供 :機能値は、多くの場合、複数のテーブルにまたがって存在します。これらのデータセットの結合は、複雑で時間がかかり、エラーが発生しやすい可能性があります。
- Feastは、将来の機能値がモデルに漏れないように、特定の時点での正確性を保証する、戦闘でテストされたロジックとこれらのテーブルを結合します。
- Feastは、将来の機能値がモデルに漏れないように、特定の時点での正確性を保証する、戦闘でテストされたロジックとこれらのテーブルを結合します。
- 低レイテンシで大規模なオンライン機能の可用性: 推論時に、モデルは多くの場合、すぐには利用できない機能にアクセスする必要があり、他のデータソースからリアルタイムで事前計算する必要があります。
- Feast with Redisをデプロイすることで、必要な機能が一貫して利用可能になり、推論時に新たに計算され、低レイテンシと高スループットが実現します。
- Feast with Redisをデプロイすることで、必要な機能が一貫して利用可能になり、推論時に新たに計算され、低レイテンシと高スループットが実現します。
- 機能の再利用性とモデルのバージョン管理: 組織内のさまざまなチームがプロジェクト間で機能を再利用できないことが多く、その結果、機能作成ロジックが重複します。モデルには、モデルバージョンでA / Bテストを実行する場合のように、バージョン管理が必要なデータ依存関係があります。
- Feastを使用すると、以前に使用した機能の検出とコラボレーションが可能になり、機能セットのバージョン管理が可能になります(機能サービスを介して)。
- Feastは機能の変換を可能にするため、ユーザーはオンライン/オフラインのユースケースやモデル全体で変換ロジックを再利用できます。
Redisチュートリアルの概要をごちそう
このチュートリアルでは、機能ストアを使用してトレーニングデータを生成し、ライドシェアリングドライバーの満足度予測モデルのオンラインモデル推論を強化します。デモデータシナリオの場合:
- 一部のドライバーを調査して、ライドシェアリングアプリの使用経験にどの程度満足しているかを判断しました。
- 残りのユーザーのドライバー満足度の予測を生成して、潜在的に不満のあるユーザーに連絡できるようにします。
チュートリアルの手順:
- Redisをインストールし、Redis-Serverをバックグラウンドで実行します
- RedisでFeastをインストールする
- 機能リポジトリを作成し、Redisをオンラインストアとして定義します
- 機能定義を登録し、機能ストアをデプロイします
- トレーニングデータを生成する
- Redisオンラインストアに機能をロードする
- 推論のために特徴ベクトルを取得する
ステップ1:Redisをインストールし、Redisサーバーをバックグラウンドで実行します
Redisをインストールするには、以下のいずれかの方法に従ってください:
Ubuntu:
$ sudo snap install redisDocker:
$ docker run --name redis --rm -p 6379:6379 -d redis
Mac(自作):
$ brew install redis
Redisをインストールする別の方法の詳細については、こちらをご覧ください。追加の構成情報は、Redisクイックスタートガイドに記載されています。
ステップ2:Redisを使用してFeastをインストールする
pipを使用してFeastSDKとCLIをインストールします:
$ pip install 'feast[redis]'
ステップ3:機能リポジトリを作成し、Redisをオンラインストアとして構成します
機能リポジトリは、機能ストアと個々の機能の構成を含むディレクトリです。
ステップ3a:機能リポジトリを作成する
新しい機能リポジトリを作成する最も簡単な方法は、feastinitコマンドを使用することです。これにより、初期デモデータを含む足場が作成されます。
$ feast init feature_repo $ cd feature_repo
出力:
Creating a new Feast repository in /Users/nl/dev_fs/feast/feature_repo
結果のデモリポジトリ自体を見てみましょう。次のように分類されます:
- feature_store.yamlには、データソースとオンラインストアを構成するデモセットアップが含まれています
-
example.py
デモ機能の定義が含まれています - data/には生のデモ寄木細工のデータが含まれています
ステップ3b:YAML構成ファイルでRedisをオンラインストアとして構成します
Redisをオンラインストアとして設定するには、 feature_store.yamlでonline_storeのtypeとconnection_stringの値を設定する必要があります 次のように:
project: my_project |
プロバイダーは、このデモのどこに生データが存在するか(トレーニングデータと提供する機能値を生成するため)をローカルで定義します。 online_store オンラインストアデータベース(サービス提供用)の機能値をマテリアライズ(ロード)する場所を定義します。
上記の構成は、代わりにデフォルトのオンラインストアを使用するチュートリアル用に提供されているデフォルトのYAMLファイルとは異なることに注意してください:
project: my_project |
したがって、
online_storeにこれらの2行を追加することによって (
type: redis, connection_string: localhost:6379)上記のYAMLファイルで、FeastはオンラインストアとしてRedisから読み取りと書き込みを行うことができます。 RedisオンラインストアはFeastコアコードの一部であるため、FeastはRedisをすぐに使用する方法を知っています。
ステップ3c:example.pyでデモ機能の定義を調べる
example.pyのデモ機能の定義を見てみましょう。 (ターミナルで表示するには、
catを実行できます。
example。
py。
Example.py
ステップ3d:生データを検査する
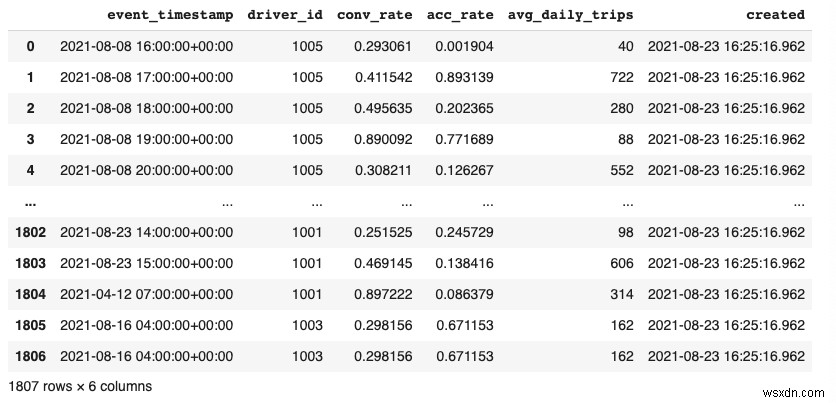
最後に、生データを調べてみましょう。このデモにある生データは、ローカルの寄木細工のファイルに保存されています。データセットは、ライドシェアリングアプリでドライバーの1時間ごとの統計をキャプチャします。
ステップ4:機能定義を登録して機能ストアをデプロイする
次に、
feast applyを実行します example.pyで定義されたフィーチャビューとエンティティを登録します 。 applyコマンドは、現在のディレクトリ内のPythonファイルをスキャンして機能ビュー/エンティティ定義を探し、オブジェクトを登録して、インフラストラクチャを展開します。この例では、 example.pyと表示されます。 (上に表示)そしてRedisオンラインストアをセットアップします。
$ feast apply
出力:
Registered entity driver_id |
ステップ5:トレーニングデータの生成
モデルをトレーニングするには、機能とラベルが必要です。多くの場合、このラベルデータは別々に保存されます(たとえば、ユーザー調査結果を保存する1つのテーブルと、特徴値を含む別のテーブルのセットがあります)。
ユーザーは、タイムスタンプを使用してラベルのテーブルをクエリし、それをトレーニングデータ生成用のエンティティデータフレームとしてFeastに渡すことができます。多くの場合、Feastは関連するテーブルをインテリジェントに結合して、関連する特徴ベクトルを作成します。
- さまざまなタイムスタンプで同じドライバーの機能をモデルで使用する必要があるため、タイムスタンプを含めることに注意してください。
Python
(以下のコードをファイル gen_train_data.pyにコピーします そしてそれを実行します):
出力:
----- Feature schema ----- |
ステップ6:機能をRedisオンラインストアにロードする
これで、機能データをRedisオンラインストアにロードまたはマテリアライズして、オンライン予測のモデルに最新の機能を提供できるようになります。
materializeコマンドを使用すると、ユーザーは特定の過去の時間範囲の機能をオンラインストアに組み込むことができます。提供された時間範囲にわたるすべての機能ビューのバッチソースを照会し、構成されたオンラインストアに最新の機能値をロードします。
materialize–
incrementalコマンドは、最後のマテリアライズ呼び出し以降にオフラインストアに到着した新しいデータのみを取り込みます。
$ CURRENT_TIME=$(date -u +"%Y-%m-%dT%H:%M:%S")
$ feast materialize-incremental $CURRENT_TIME
出力:
Materializing 1 feature views to 2021-08-23 16:25:46+00:00 into the redis online store. |
ステップ7:推論のための特徴ベクトルのフェッチ
推論時に、
get_online_features()を使用して、Redisオンライン機能ストアからさまざまなドライバー(バッチソースにのみ存在していた可能性があります)の最新の機能値をすばやく読み取る必要があります。 。これらの特徴ベクトルは、モデルに供給することができます。
Python
(以下のコードをファイル get_feature_vectors.pyにコピーします そしてそれを実行します):
出力
{ |
おめでとう!チュートリアルは終了です。バックグラウンドで実行されているRedisサーバーをシャットダウンするには、
redis-cli shutdownを使用できます。 コマンド。
チュートリアルの要約:
このチュートリアルでは、ParquetファイルオフラインストアとRedisオンラインストアを備えたローカル機能ストアをデプロイしました。次に、Parquetファイルの時系列機能を使用してトレーニングデータセットを作成しました。次に、オフラインストアからRedisオンラインストアに機能値を具体化しました。最後に、Redisオンラインストアから最新の機能を読んで推論します。オンラインストアとしてRedisを使用すると、リアルタイムのMLユースケースで最新の機能をすばやく読み取ることができ、レイテンシが低く、スループットが大規模になります。
次は?
- 「FeastConcepts」ページを読んでFeastデータモデルを理解し、「FeastArchitecture」ページを読んでください。
- Feast with Redisの完全な構成ガイドと、Redisに機能値を保存するために使用されるデータモデルをお読みください。
- ケーススタディ–同僚から学ぶ:企業がRedisをオンラインストアとして使用しているFeatures Stores(Wix、Swiggy、Comcast、Zomato、AT&T、DoorDash、iFood)をどのように使用しているか、具体的にはFeastwithRedisをどのように使用しているかを確認します。彼らのオンラインストア(Gojek、Udaan、Robinhood)。
- FeastとRedisを使用したAzureManagedFeature Storeについて読み、FeastonAzureチュートリアルおよびその他のFeastチュートリアルの概要に従ってください
- FeastとRedisの一般的な製品紹介ページで、それぞれFeastとRedisの詳細を確認することもできます。
Slackの他のFeastユーザーや貢献者に参加して、コミュニティの一員になりましょう!
-
ウェブ用の Android メッセージの使用を開始する
Google は 1 つの巨大なプラットフォームであり、疑いの余地はありません。しかし、最高の検索エンジンの 1 つであるだけでなく、日常生活を楽にするさまざまなサービスも提供しています。 Google は最近、どの Web ブラウザからでもテキスト メッセージを送受信できる Android メッセージ アプリのアップデートをリリースしました。このサービスを使用すると、Android ユーザーは任意の PC または Mac に簡単にメッセージを送信できます。 開始するには、Android メッセージ アプリの更新バージョンが必要です。それが終わったら、Web サービスで Android メッ
-
Xen 仮想化の開始
Zで綴られるZenは、8時間保持した後、雪の中でおしっこをしているときに頭頂部にある典型的な感覚です. Xen は X で綴られており、KVM と同様に、企業市場を対象としていますが、家庭でもビジネスでもセットアップを検討できるオープンソースの仮想化テクノロジです。 KVM に関するいくつかのチュートリアルがあり、導入記事、ストレージとネットワーク (ブリッジ ネットワークを含む) のセットアップと構成の方法、および VirtualBox との競合の解決方法をカバーしています。ここで、Xen についてもう少し学びましょう。同様に、仮想マシンをインストールして実行するために必要な最初の手順、