RediSearch2.0の紹介
Redisの全文検索機能を備えたリアルタイムのセカンダリインデックスであるRediSearchは、最も成熟した機能豊富なRedisモジュールの1つです。また、毎日さらに人気が高まっています。過去数か月で、RediSearch Dockerのプルは500%急増しました。その人気の急上昇により、顧客はリアルタイムの在庫管理から一時的な検索に至るまで、さまざまな興味深いユースケースを思い付くようになりました。
その勢いを伸ばすために、開発者エクスペリエンスを向上させるように設計されたRediSearch2.0のパブリックプレビューを導入します。 Redisearchの最もスケーラブルなバージョンになります 。 RediSearch 2.0は、Redisのアクティブ-アクティブ地理的分散テクノロジーをサポートし、ダウンタイムなしでスケーラブルであり、Redis on Flashサポート(現在はプライベートプレビュー)を備えています。パフォーマンスに悪影響を与えることなくこれらの目標を達成するために、RediSearch 2.0のまったく新しいアーキテクチャを作成し、それが機能しました。RediSearch2.0は2.4倍高速です RediSearch1.6より。
RediSearch2.0の新しいアーキテクチャの内部
Redisデータベースに豊富なクエリと集計エンジンがあると、キャッシングをはるかに超えたさまざまな新しいユースケースが可能になります。 RediSearchを使用すると、複雑なクエリを使用してデータにアクセスする必要がある状況で、Redisをプライマリデータベースとして使用できます。さらに良いことに、Redisのワールドクラスの速度、信頼性、スケーラビリティを維持し、データを更新してインデックスを作成するためにコードを複雑にする必要がありません。
RediSearch 2.0では、インデックスがデータと同期する方法を再設計しました。 (FT.ADDコマンドを使用して)インデックスを介してデータを書き込む代わりに、RediSearchはハッシュで書き込まれたデータを追跡し、同期的にインデックスを作成するようになりました。この再アーキテクチャには、APIにいくつかの変更が加えられています。これは、以前の投稿でRediSearch2.0が最初のマイルストーンに到達したときに説明しました。
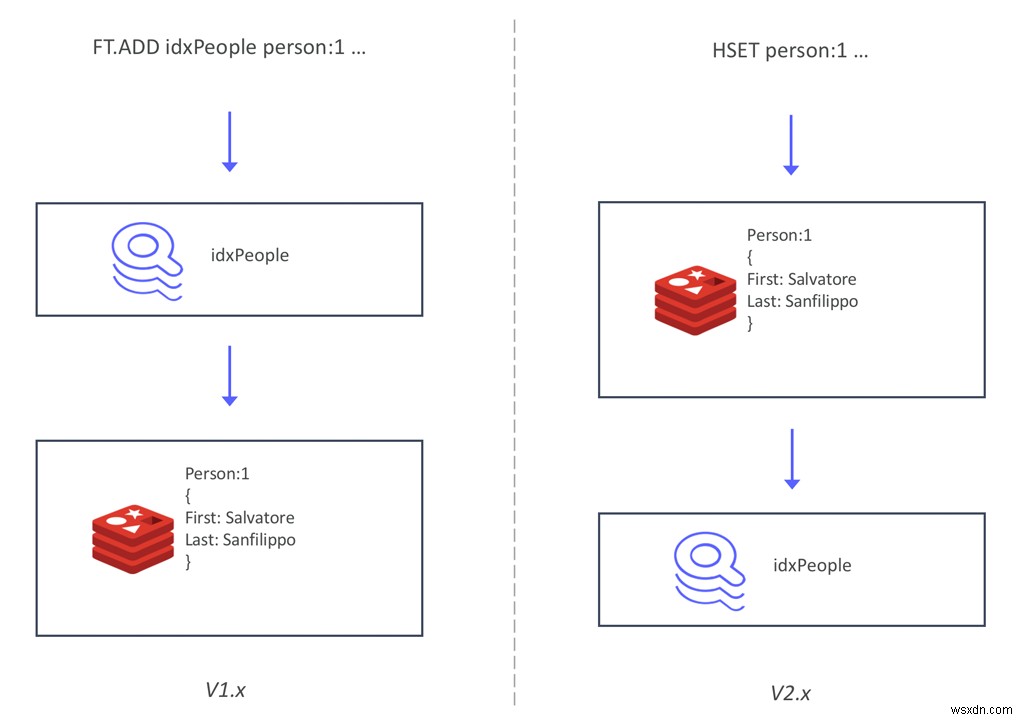
この新しいアーキテクチャには、2つの主な利点があります。まず、既存のデータの上にセカンダリインデックスを作成することがこれまでになく簡単になりました。 既存のRedisデータベースにRediSearchを追加し、インデックスを作成して、クエリを開始するだけです 、データを移行したり、インデックスにデータを追加するための新しいコマンドを使用したりする必要はありません。これにより、新しいRediSearchユーザーの学習曲線が大幅に短縮され、既存のRedisデータベースにインデックスを作成できます。再起動する必要もありません。
データにインデックスを付ける新しい方法を実装することに加えて、キースペースからインデックスを削除しました。これにより、競合のないレプリケートされたデータ型(CRDT)に基づくRedisEnterpriseのアクティブ-アクティブテクノロジーが可能になります。 2つの転置インデックスを競合なしでマージすることは困難ですが、Redisにはすでにハッシュの実証済みのCRDT実装があります。したがって、この新しいアーキテクチャの2番目の大きな利点は、RediSearch2.0をさらにスケーラブルにすることです 。 RediSearchはハッシュに従い、インデックスはキースペースから移動されたため、アクティブ-アクティブ地理分散データベースでRediSearchを実行できるようになりました。
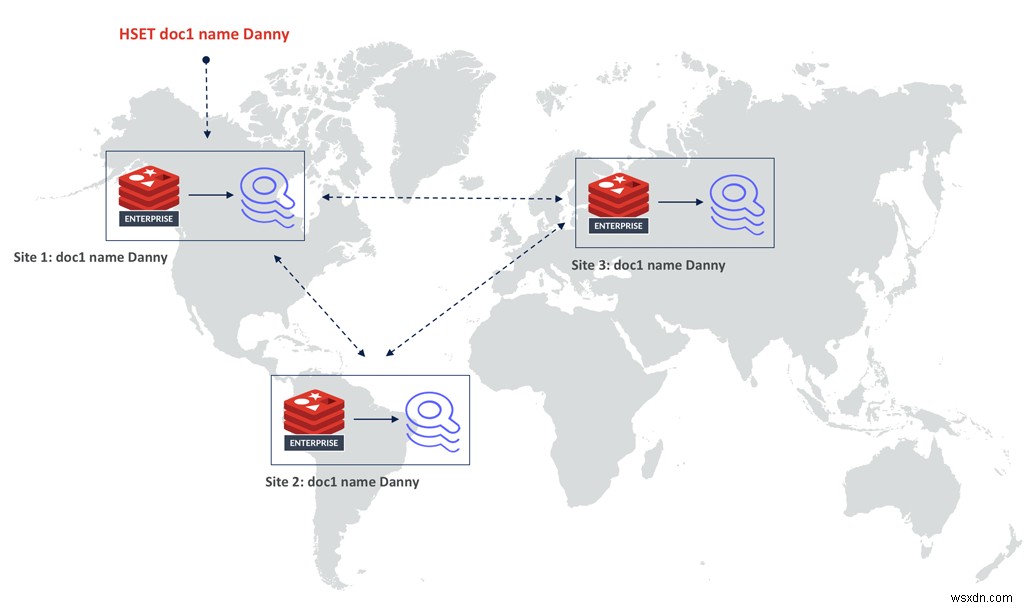
ドキュメントは、結果整合性の高い方法で、レプリケーションセット内のすべてのデータベースにレプリケートされます。各レプリカで、RediSearchはハッシュのすべての更新を追跡するだけです。つまり、すべてのインデックスは結果整合性も強くなります。
オープンソースRedisのOSSクラスターサポート
スケーラビリティ機能の拡張をRedisEnterpriseユーザーのみに制限したくなかったため、オープンソースのRedisクラスターAPIを使用して単一のインデックスを複数のシャードにスケーリングするためのサポートを追加しました。以前は、単一のRediSearchインデックスとそのドキュメントは、単一のシャードに存在する必要がありました。これは、OSS Redisのデータセットサイズとスループットが、単一のRedisプロセスで処理できるものにバインドされていることを意味します。 Redis Enterpriseは、クラスター化されたデータベースでドキュメントを配布し、クエリ時に結果を集約する機能を提供しました。このファンアウトと集約は、「コーディネーター」と呼ばれるコンポーネントによって処理されます。このコンポーネントは、Redis Source Available Licenseの下で公開されているため、オープンソースのRedisクラスターおよびRedisEnterpriseで動作します。その結果、RediSearchのこれまでで最もスケーラブルなバージョンになります。
番号を見せてください!
RediSearch 2.0の取り込みパフォーマンスを評価するために、公開されているNYCタクシーデータセットを使用して全文検索ベンチマーク(FTSB)スイートを拡張しました。このデータセットは、豊富なデータタイプ(テキスト、タグ、地理、数値)と多数のドキュメントにより、業界全体で使用されています。
このベンチマークは、ニューヨーク市のイエローキャブでの乗車のトリップレコードデータを使用して、書き込みパフォーマンスに焦点を当てています。特にこのベンチマークでは、2015年1月のデータセットを使用しました。このデータセットは、ドキュメントあたり平均500バイトのサイズで1200万を超えるドキュメントを読み込みます。完全なベンチマーク仕様については、GitHubのFTSBを参照してください。
すべてのベンチマークバリエーションは、ベンチマークテストインフラストラクチャを通じてプロビジョニングされたアマゾンウェブサービスインスタンスで実行されました。テストは、RediSearch Enterpriseバージョン1.6および2.0を使用して、15個のシャードを備えた3ノードクラスターで実行されました。ベンチマーククライアントと、RediSearchが有効になっているデータベースを構成する3つのノードの両方が、別々のc5.9xlargeインスタンスで実行されていました。
RediSearch 2.0には、Redisのハッシュの変更を追跡し、それらに自動的にインデックスを付ける機能が備わっているため、FT.ADDコマンドとHSETコマンドのバリアントを追加しました。アップグレードを簡単にするために、廃止されたFT.ADDコマンドをRediSearch2.0のHSETコマンドに再マップしました。以下の2つのグラフは、ミリ秒未満のレイテンシを維持しながら、RediSearch1.6とRediSearch2.0の両方の全体的な取り込み率とレイテンシを示しています。
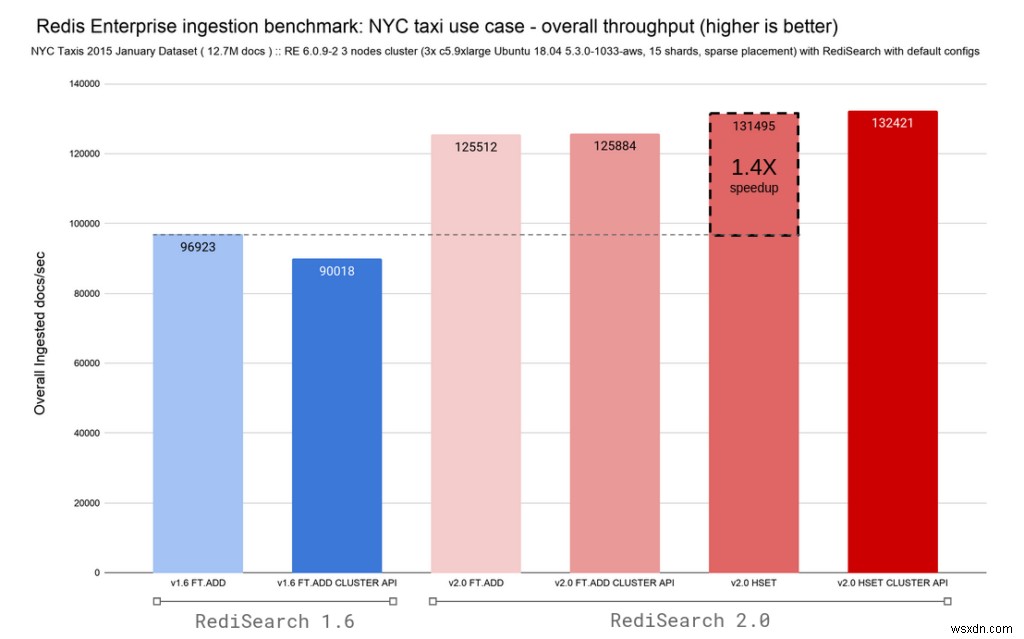
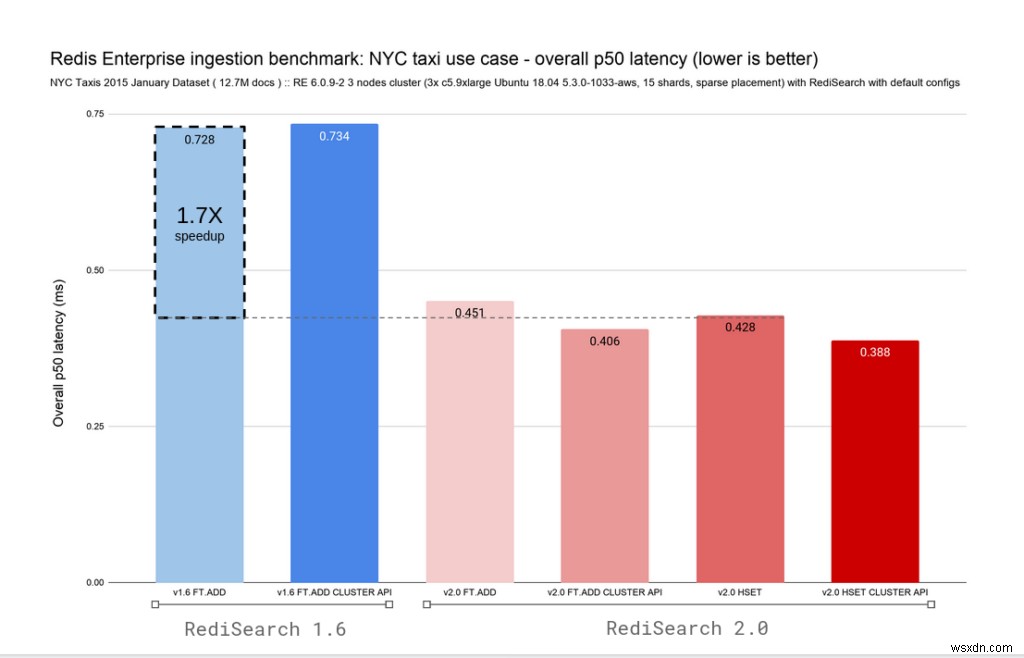
RediSearchは常に高速でしたが、このアーキテクチャの変更により、p50の全体的な取り込みレイテンシが0.4ミリ秒で、毎秒96Kドキュメントのインデックス作成から132Kドキュメント/秒に移行し、書き込みのスケーリングが大幅に向上しました。
スループットの向上の恩恵を受けるだけでなく、各取り込みも高速になります。アーキテクチャの変更による全体的な取り込みの改善とは別に、OSS Redis Cluster API機能を利用して、検索データベースの取り込みを線形にスケーリングできるようになりました。
スループットとレイテンシーの改善を組み合わせることで、RediSearch2.0は最大2.4倍のスピードアップを実現します RediSearch1.6と比較。
RediSearch2.0の次のステップ
要約すると、 RediSearch 2.0は、これまでにリリースしたすべてのRedisユーザーにとって最速かつ最もスケーラブルなバージョンです。 さらに、RediSearch 2.0の新しいアーキテクチャにより、Redis内の既存のデータのインデックスをシームレスに作成する開発者エクスペリエンスが向上し、Redisデータを別のRediSearch対応データベースに移行する必要がなくなります。この新しいアーキテクチャにより、RediSearchは、ストリームや文字列などの他のデータ構造を追跡し、自動インデックスを作成できます。今後のリリースでは、RedisJSONのネストされたデータ構造などの追加のデータ構造を操作できるようになります。
今後も機能を追加して、開発者のエクスペリエンスをさらに向上させる予定です。次に、検索クエリのプロファイルを作成して、クエリの実行中にパフォーマンスのボトルネックが発生する場所をよりよく理解できる新しいコマンドを探します。
始める準備はできましたか? TugGrallのブログをチェックしてください…RediSearch2.0入門!次に、GitHubでこのチュートリアルの手順に従うか、Redis EnterpriseCloudEssentialsで無料のデータベースを作成します。 (RediSearch 2.0のパブリックプレビューは、ムンバイとオレゴンの2つのRedis Enterprise Cloud Essentialsリージョンで利用できることに注意してください。)
-
MongoDBコンパスの紹介
この投稿では、MongoDBコンパスと呼ばれるMongoDB®のGUIを紹介します。 概要 Compassを使用すると、MongoDBクエリ構文を正式に知らなくても、MongoDBデータを分析して理解できます。 Compassを使用すると、視覚的な環境でデータを探索するだけでなく、クエリのパフォーマンスを最適化し、インデックスを管理し、ドキュメントの検証を実装できます。 コンパスエディション Compassには3つの主要なエディションがあります: コンパス :すべての機能を備えたフルバージョン。 コンパス読み取り専用 :すべての書き込みおよび削除機能が削除された、読み取り操作に
-
FastlyComputeでRedisを使用する
この例では、古いバージョンのFastlyCLIを使用しています。最新バージョンについては、この記事を確認してください。 この投稿では、Fastly Compute@Edgeで実行される簡単なアプリケーションを作成します。アプリケーションはUpstashRedisにアクセスして、ページビューを追跡します。 モチベーション エッジコンピューティングは、近年最もエキサイティングなトレンドの1つです。 CloudflareやFastlyなどのCDNサービスは、ユーザーがエッジインフラストラクチャでアプリケーションを実行できるようにするために開始されました。これは、開発者がグローバルに分散された高