速く、速く! Redisのパフォーマンスを系統的に改善する
Redisは、パフォーマンスに重点を置いて開発されています。非常に安定した高速な製品をお届けできるよう、リリースごとに最善を尽くしています。
それでも、Redisの効率を改善する余地を見つけている場合、またはパフォーマンス回帰の調査を進めている場合は、Redisのパフォーマンスを監視および分析するための簡潔で系統的な方法が必要になります。これは、それらの最適化の1つのストーリーです。
最終的に、ストリームの取り込みパフォーマンスが約20%向上しました。これは、Redisv7.0ですでに利用できる改善です。
標準SPEC
最適化に取り掛かる前に、どのようにして最適化に到達したかについての概要を説明したいと思います。
前に述べたように、Redisのパフォーマンスの低下やCPU上のパフォーマンスの改善の可能性を特定したいと思います。そのためには、パフォーマンスと可観測性の要件と期待に関連するすべての事項について、企業間およびコミュニティ間の一連の基準を育成する必要があると感じました。
一言で言えば、私たちは常にSPECのベンチマークをブランチ/タグごとに分類して実行し、「ゼロタッチ」の完全自動モードでのプロファイリングツール/プローバー出力とクライアント出力を含む結果のパフォーマンスデータを解釈します。
使用されている機器はすべてオープンソースであり、memtier_benchmark、redis-benchmark、Linux perf_events、bcc / BPFトレースツール、BrendanGregのFlameGraphリポジトリなどのツール/人気のあるフレームワークに依存しています。
Redisでのプロファイラーの使用方法の詳細に興味がある場合は、非常に詳細な"をご覧になることをお勧めします。 オンCPUプロファイリングとトレースのパフォーマンスエンジニアリングガイド 。」
パフォーマンスを向上させるために重複計算を避けてください
この最初のステップが実行されるとすぐに、プロファイリングツール/プローバーの出力の解釈を開始しました。興味深いパターンを示したベンチマークの1つは、以下のようなコマンドを使用してデータをストリームに取り込むだけのStreamsの取り込みベンチマークでした。
`XADDキー*フィールド値`。
IDなしでストリームに追加すると、次の2つのパフォーマンスレポートの印刷で詳細に示されているように、CPUサイクルの約10%のコストがかかるSDSの作成/解放/sdslenで重複作業が発生することがわかりました。
>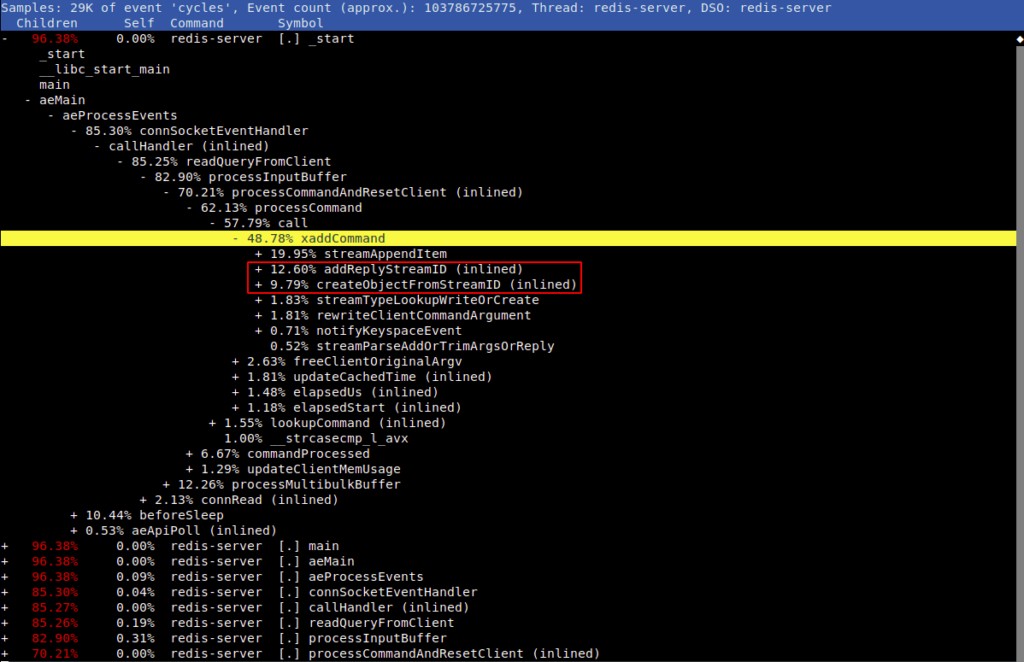
同じ入力に対して、sdscatfmtと_sdsnewlenが2回呼び出されていました:

これにより、ベンチマーク結果に従って確認されたように、Streamsの取り込みを約9〜10%最適化することができました。
不安定なブランチのベースライン( 6b403f5 ):
このPRの最初のコミット(重複作業を避ける):

パフォーマンスを向上させるために重複する割り当てを回避する
このユースケースの改善の最初の焦点は、CPUサイクルのさらに別の浪費に気付いたOran(コアチームメンバーの1人)からのさらなる分析につながります。今回は、同じコードブロック内のメモリ管理が最適ではなかったことが原因でした。空のSDSを割り当ててから、再割り当てしていました。呼び出し回数を減らすと、以下に示すように、さらに速度が向上します。
2番目のコミット(reallocを回避):

測定された改善
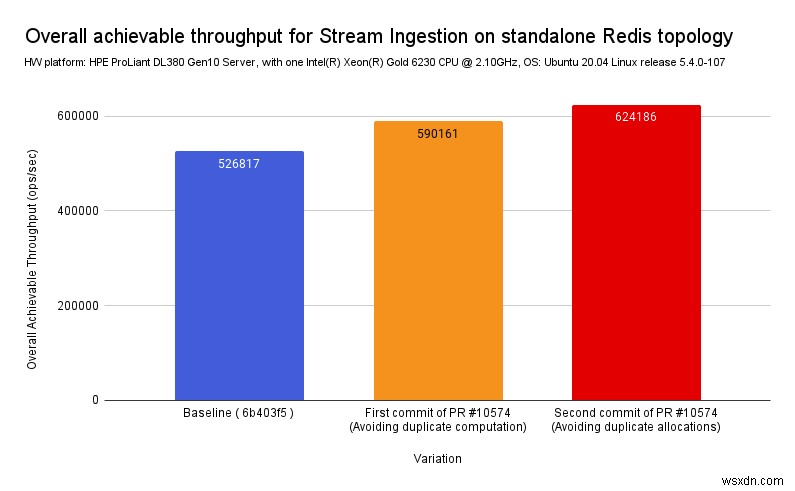
予想どおり、中間計算を再利用し、その結果、内部で呼び出される関数内の冗長な計算と割り当てを削減することで、Redisストリームの約=20%の全体的なCPU時間の削減を測定しました。
これは、Redisのようにすでに深く最適化されたコードであっても、系統だった単純な改善がパフォーマンスの大幅な向上につながる可能性がある例であると考えています。
私たちの目標は、Redisのパフォーマンスの可視性を拡大することであり、組織や個人を含む業界と学界の両方のメンバーが貢献することが奨励されています。測定しないと改善できません。
-
Redis LLEN –Redisデータストアでリストの長さを取得する方法
このチュートリアルでは、キーに格納されているリスト値の長さを取得する方法について学習します。このために、Redis LLENを使用します コマンド。 LLENコマンド このコマンドは、キーに格納されているリスト値の長さ(要素数)を返します。キーがredisデータストアに存在しない場合、そのキーは空のリストとして解釈され、0が返されます。 redis LLENコマンドの構文は次のとおりです:- 構文:- redis host:post> LLEN <key name> 出力:- (integer) value, representing the number of
-
Redis SETRANGE –Redisの文字列値の一部を更新する方法
このチュートリアルでは、redisデータストアの指定されたキーに格納されている文字列値の一部を更新する方法について学習します。このために、Redisの SETRANGEを使用します コマンド。 SETRANGEコマンド このコマンドは、文字列値の更新部分の開始インデックスを決定する開始(両端を含む)オフセットを取ります。開始オフセットが文字列値の長さよりも大きい場合、開始オフセットを適合させるために、文字列値にゼロバイトが埋め込まれます。インデックスはゼロベースであるため、0は最初の要素を意味し、1は2番目の要素を意味します。 キーがredisデータストアに存在しない場合、操作を実行する