階層型データベースモデル
階層モデルは、レコードごとに1つの親が存在するツリーのような構造でデータを表します。順序を維持するために、兄弟ノードを記録された方法で保持するソートフィールドがあります。これらのタイプのモデルは、基本的に、IBMのInformation Management System(IMS)などの初期のメインフレームデータベース管理システム用に設計されています。
このモデル構造により、2つ/さまざまなタイプのデータ間で1対1および1対多の関係が可能になります。この構造は、現実の世界で多くの関係を説明するのに非常に役立ちます。目次、ネストおよびソートされた情報。
階層構造は、ストレージ内のレコードの物理的な順序として使用されます。シーケンシャルアクセスと組み合わせたポインタを使用してデータ構造をナビゲートすることにより、レコードにアクセスできます。したがって、各レコードにフルパスも含まれていない場合、階層構造は特定のデータベース操作には適していません。
このタイプのデータベースのデータは階層的に構造化されており、通常は逆ツリーとして開発されます。構造内の「ルート」はデータベース内の単一のテーブルであり、他のテーブルはルートから流れるブランチとして機能します。次の図は、典型的な階層型データベース構造を示しています。
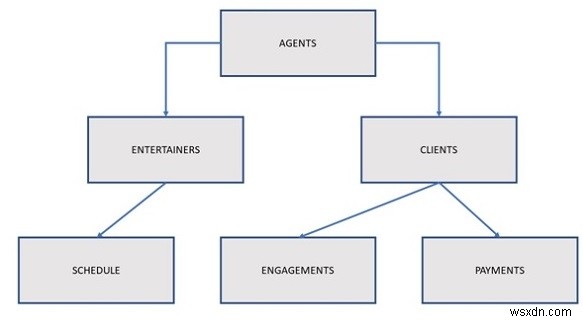
上の図では、エージェントが複数のエンターテイナーを予約し、各エンターテイナーは自分のスケジュールを持っています。エンターテインメントのニーズを満たす必要のある複数のクライアントを維持することは、エージェントの義務です。クライアントはエージェントを通じてエンゲージメントを予約し、エージェントにサービスの支払いを行います。
このデータベースモデルの関係は、親/子という用語で表されます。親テーブルは、このタイプの関係で1つ以上の子テーブルにリンクできますが、単一の子テーブルは1つの親テーブルにのみリンクできます。テーブルは、ポインタ/インデックスを介して、またはテーブル内のレコードの物理的な配置によって明示的にリンクされます。
ユーザーは、ルートテーブルから開始し、ツリーを下ってターゲットデータに到達することで、データにアクセスできます。ユーザーは、複雑さを伴わずにデータにアクセスするには、データベースの構造に精通している必要があります。
- テーブル構造間に明示的なリンクが存在するため、ユーザーは非常に迅速にデータを取得できます。
- 参照整合性が組み込まれており、自動的に適用されます。これにより、子テーブルのレコードを親テーブルの既存のレコードにリンクする必要があります。また、親テーブルでレコードが削除された場合は、すべての関連付けが行われます。子テーブルのレコードも削除されます。
- ユーザーが現在親テーブルのレコードとは関係のない子テーブルにレコードを保存する必要がある場合、記録が困難になり、ユーザーは親テーブルに追加のエントリを記録する必要があります。
- このタイプのデータベースは複雑な関係をサポートできません。また、冗長性の問題もあり、さまざまなサイトでのデータの記録に一貫性がないため、不正確な情報が生成される可能性があります。
- スケジュールテーブルには、クライアント名、住所、電話番号などの情報を含むクライアントデータが含まれ、各エンターテイナーが誰のためにどこで演奏しているかが示されます。このデータは現在Clientsテーブルにも保存されているため、冗長です。
- Engagementsテーブルには、エンターテイナーに関するデータが含まれるようになります。このデータには、エンターテイナーの名前、電話番号、エンターテイナーのタイプなどの情報が含まれ、特定のクライアントに対してどのエンターテイナーがパフォーマンスを行っているかを示します。このデータは、現在Entertainersテーブルに保存されているため、冗長です。
この冗長性の問題は、ユーザーが単一のデータを一貫して入力できない可能性があるため、不正確な情報が生成される可能性があることです。
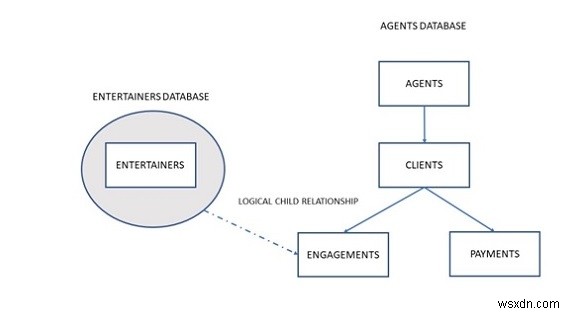
この問題は、エンターテイナー専用の階層型データベースとエージェント専用の階層型データベースを作成することで解決できます。 Entertainersデータベースには、Entertainersテーブルに記録されたデータのみが含まれ、改訂されたAgentsデータベースには、Agents、Clients、Payments、およびEngagementsテーブルに記録されたデータが含まれます。 AgentsデータベースのEngagementsテーブルとEntertainersデータベースのEntertainersテーブルの間に論理的な子関係を定義できるため、必要はありません。この関係が整っていると、特定のクライアントの予約済みエンターテイナーのリストや特定のエンターテイナーのパフォーマンススケジュールなど、さまざまな情報を取得できます。次の図は全体像を示しています。
階層型データベースは、1970年代にメインフレームで使用されていたテープストレージシステムに最適であり、データベースがこれらのシステムに基づいている組織で非常に人気がありました。ただし、階層型データベースはデータへの高速で直接的なアクセスを提供し、いくつかの状況で役立ちましたが、データの冗長性とデータ間の複雑な関係の増大する問題に対処するには、新しいデータベースモデルが必要であることは明らかでした。
このデータベースモデルの背後にある考え方は、特定の種類のデータストレージに役立ちますが、非常に用途が広く、特定の用途に限定されています。
たとえば、会社の各個人が特定の部門に報告する場合、その部門を親レコードとして使用でき、個々の従業員は二次レコードを表し、それぞれがその部門にリンクします。階層構造の親レコード。
-
ピボット テーブル データ モデルで計算フィールドを作成する方法
ピボット テーブル データ モデルで計算フィールドを作成する方法を探している場合 、この記事はこの目的に役立ちます。それでは、この仕事を行うための詳細な手順を知るために、メインの記事から始めましょう. ワークブックをダウンロード 計算フィールドとは 計算フィールド ピボットテーブルの不可欠なプロパティです または ピボット チャート . メジャーとも呼ばれます . 計算フィールド または測定 DAX を使用して作成されたフィールドです 方式。 PivotTable の完了後にデータセットの追加プロパティを計算する場合 計算フィールド を作成して数式を簡単に適用できます。 ここ。この 計算
-
Excel でデータ モデルを作成する方法 (3 つの便利な方法)
データ モデルは、データ分析に不可欠な機能です。データ モデルを使用して、データ (テーブルなど) を Excel にロードできます。 メモリー。次に、Excel に伝えることができます 共通の列を使用してデータを接続します。各テーブル間の関係は、「モデル」という言葉で表されます データモデルで。 エクセル は、データ モデルを作成する複数の方法を提供します。この記事では、Excel でデータ モデルを作成する方法について説明します。 Excel でデータ モデルを作成する 3 つの便利な方法 この記事では、 3 について説明します Excel でデータ モデルを作成する