Rubyの線形回帰で未来を予測する
私たちが行う多くの選択は、数値的な関係を中心に展開します。
- 科学がコレステロールを下げると言っているので、私たちは特定の食品を食べます
- 給与が上がる可能性が高いため、教育をさらに進めています。
- 私たちは、最も価値が高くなると信じている近所の家を購入します
どうすればこれらの結論に達することができますか?ほとんどの場合、誰かが大量のデータを収集し、それを使用して結論を出しました。一般的な手法の1つは、教師あり学習の形式である線形回帰です。教師あり学習の詳細と、それがよく使用される例については、このシリーズのパート1をご覧ください。
2つの値の場合—それらをxと呼びます およびy —線形関係にあり、xを変更することを意味します 1を指定すると、常にyが発生します 一定量変更します。例を挙げたほうが簡単です:
- 10個のピザの価格は1個のピザの10倍です。
- 高さ10フィートの壁には、5フィートの壁の2倍の塗料が必要です
数学的には、この種の関係は直線の方程式を使用して記述されます。
y = mx + b
数学はひどく混乱する可能性がありますが、私にはしばしば魔法のように思えます。直線の方程式を最初に学んだとき、たった1つの数式で直線上の距離や傾きなどの点を計算できるのは、どれほど美しいことかと思ったのを覚えています。
しかし、データポイントしか持っていない場合、この式をどのように取得しますか?答えは線形回帰です—非常に人気のある機械学習ツールです。
この投稿では、曲の1分あたりのビート数(BPM)がSpotifyでの人気を予測するかどうかを調べます。
線形回帰は、2つの変数間の関係をモデル化します。 1つは「説明変数」と呼ばれ、もう1つは「従属変数」と呼ばれます。
この例では、BPMが人気を「説明」できるかどうかを確認したいと思います。したがって、BPMが説明変数になります。そのため、人気は従属変数になります。
モデルは最小二乗回帰を利用して、フォームの最適な線を見つけます。ご想像のとおり、y = mx + b 。
複数の説明変数が存在する可能性がありますが、この例では、1つしかない単純な線形回帰を実行します。
最小二乗何?
線形回帰を行うにはいくつかの方法があります。それらの1つは「最小二乗」と呼ばれます。各データポイントからラインまでの垂直偏差の2乗の合計を最小化することにより、最適なラインを計算します。
紛らわしいように聞こえますが、基本的には「線とデータポイントの間のスペースを最小限に抑える線を作成してください」と言っているだけです。
二乗と合計の理由は、正の値と負の値の間にキャンセルがないようにするためです。
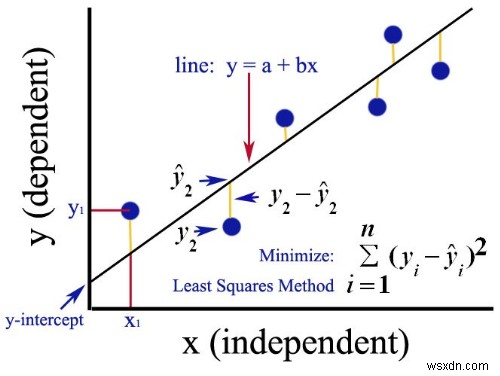
これは、Quoraで見つけた画像で、説明に非常に役立ちます。
Kaggleのこのデータセットを使用します:https://www.kaggle.com/leonardopena/top50spotify2019CSVとしてダウンロードできます。
データセットには16列あります。ただし、気にするのは「トラック名」、「1分あたりのビート数」、「人気度」の3つだけです。機械学習の最も重要なステップの1つは、データを適切にフォーマットすることです。これは、「マング」と呼ばれることがよくあります。前述の3つの列を除くすべてのデータを削除できます。
CSVは次のようになります。 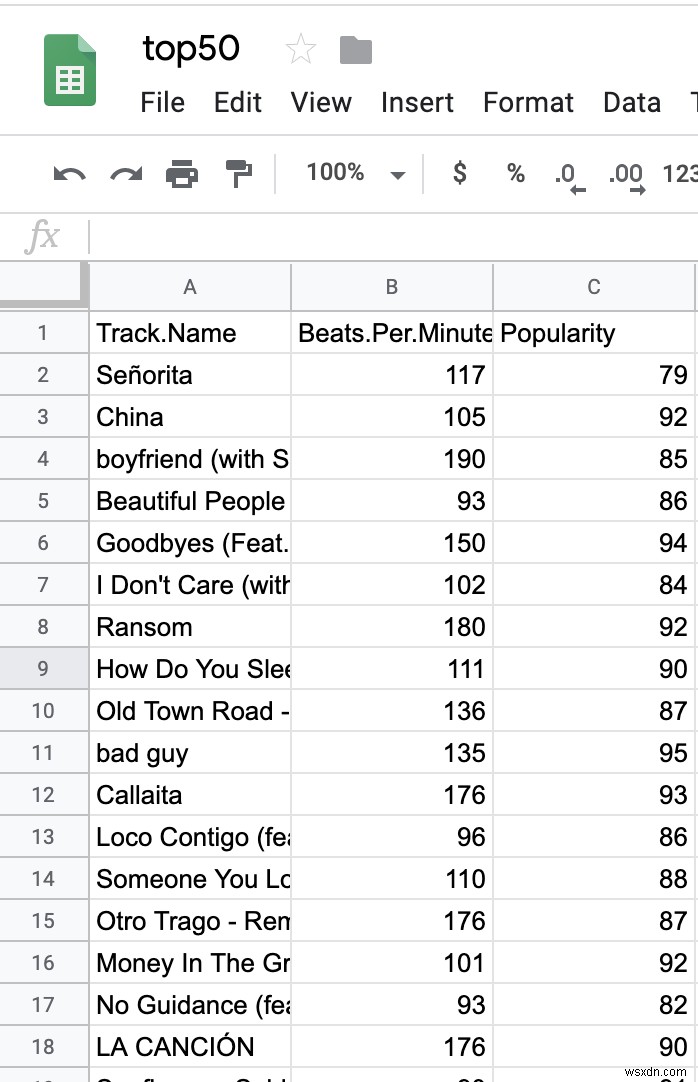
Rubyを使用して回帰を行う
この例では、ruby_linear_regressionを利用します。 宝石。インストールするには、次を実行します:
gem install ruby_linear_regression
OK、コーディングを開始する準備ができました!新しいRubyファイルを作成し、次の要件を追加します。
require "ruby_linear_regression"
require "csv"
次に、CSVデータを読み取り、#shiftを呼び出します。 、ヘッダー行を破棄します。または、CSVファイルから最初の行を削除することもできます。
csv = CSV.read("top50.csv")
csv.shift
xデータポイントとyデータポイントを保持する2つの空の配列を作成しましょう。
x_data = []
y_data = []
...そして.eachを使用して繰り返します Beats Per Minuteを追加するメソッド x配列へのデータとPopularity y配列へのデータ。
ここで実際に何が起こっているのか知りたい場合は、
rowをログに記録して実験できます。putsのいずれかを使用します またはp。例:puts row
csv.each do |row|
x_data.push( [row[1].to_i] )
y_data.push( row[2].to_i )
end
次に、ruby_linear_regressionを使用します。 宝石。回帰モデルの新しいインスタンスを作成し、データを読み込み、モデルをトレーニングします。
linear_regression = RubyLinearRegression.new
linear_regression.load_training_data(x_data, y_data)
linear_regression.train_normal_equation
次に、平均二乗誤差(MSE)を出力します。これは、観測値と予測値の差の尺度です。負の値と正の値が互いに打ち消し合わないように、差は2乗されます。予測値と実際の値の間の距離を大きくしたくないため、MSEを最小化する必要があります。
puts "Trained model with the following cost fit #{linear_regression.compute_cost}"
最後に、コンピューターにモデルを使用して予測を行わせましょう。具体的には、250 BPMの曲はどれくらい人気がありますか? prediction_dataのさまざまな値を自由に試してみてください 配列。
prediction_data = [250]
predicted_popularity = linear_regression.predict(prediction_data)
puts "Predicted popularity: #{predicted_popularity.round}"
コンソールでプログラムを実行して、何が得られるか見てみましょう!
➜ ~ ruby spotify_regression.rb
Trained model with the following cost fit 9.504882197447587
Predicted popularity: 91
涼しい! 「250」を「50」に変更して、モデルが何を予測するかを見てみましょう。
➜ ~ ruby spotify_regression.rb
Trained model with the following cost fit 9.504882197447587
Predicted popularity: 86
1分あたりのビート数が多い曲の方が人気があるようです。
ファイル全体は次のようになります。
require 'csv'
require 'ruby_linear_regression'
x_data = []
y_data = []
csv = CSV.read("top50.csv")
csv.shift
# Load data from CSV file into two arrays -- one for independent variables X (x_data) and one for the dependent variable y (y_data)
# Row[0] = title
# Row[1] = BPM
# Row[2] = Popularity
csv.each do |row|
x_data.push( [row[1].to_i] )
y_data.push( row[2].to_i )
end
# Create regression model
linear_regression = RubyLinearRegression.new
# Load training data
linear_regression.load_training_data(x_data, y_data)
# Train the model using the normal equation
linear_regression.train_normal_equation
# Output the cost
puts "Trained model with the following cost fit #{linear_regression.compute_cost}"
# Predict the popularity of a song with 250 BPM
prediction_data = [250]
predicted_popularity = linear_regression.predict(prediction_data)
puts "Predicted popularity: #{predicted_popularity.round}"
これは非常に単純な例ですが、それでも、機械学習に使用される重要な手法である最初の線形回帰を実行しただけです。もっと知りたい場合は、次にできることがいくつかあります。-内部で行われている計算を確認するために使用していたRuby gemのソースコードを確認します-元のデータセットに戻って、試してください。モデルに変数を追加し、多変数線形回帰を実行して、MSEを減らすことができるかどうかを確認します。たとえば、「価数」(曲がどれだけポジティブか)も人気に影響を与えます。 -勾配降下モデルを試してください。これは、ruby_linear_regressionを使用して実行することもできます。 宝石。
-
RubyでN-Queensの問題を解決する
N-Queensは、 N*NボードにN個のクイーンを配置する必要がある興味深いコーディングチャレンジです。 。 次のようになります: 女王はすべての方向に移動できます: 垂直 水平 対角線 解決策(多くの場合があります)は、すべてのクイーンをボードに配置する必要があります。 &すべての女王は他のすべての女王の手の届かないところにいる必要があります。 この記事では、私がどのようにして解決策を思いついたのかを学びます。 計画 この種の課題を解決するときは、まず、計画を平易な英語で書き留めることから始めるのがよいでしょう。 これは、問題が何であるか、およびそれを解決するための手
-
Ruby転置法を使用して行を列に変換する
今日は、Ruby転置法を使用してRubyでグリッドを処理する方法を学習します。 多次元配列の形をした完璧なグリッド、たとえば3×3の正方形があると想像してみてください。 そして、行を取得して列に変換する 。 なぜあなたはそれをしたいのですか? 1つの用途は、古典的なゲームであるtic-tac-toeです。 ボードをグリッドとして保存します。次に、勝利の動きを見つけるには、行を確認する必要があります 、列 &対角線 。 問題は、グリッドを配列として格納している場合、行に直接アクセスすることしかできないことです。 コラムズザハードウェイ 「直接アクセス」とは、配列を(eachで)調べ