Rubyでのマージソートの調査
これは、Rubyを使用したさまざまなソートアルゴリズムの実装を検討するシリーズのパート3です。パート1ではバブルソートについて説明し、パート2では選択ソートについて説明しました。
このシリーズの以前の投稿で説明したように、データの並べ替え方法を理解することは、ソフトウェアエンジニアのツールキットの不可欠な部分です。幸い、Rubyのようなほとんどの高級言語には、配列のソートに効率的な組み込みメソッドがすでに組み込まれています。たとえば、.sortを呼び出す場合 アレイでは、内部でクイックソートを使用しています。この投稿では、クイックソートと同様のアルゴリズム(マージソート)を学習します。これらのアルゴリズムは両方とも「分割統治アプローチ」を利用しています。マージソートは、1945年にジョンフォンノイマンによって発明されました。フォンノイマンは、マンハッタン計画、「ミニマックス」定理、モンテカルロ法などに取り組んだことでも知られる有名なコンピューター科学者および物理学者でした。
大まかに言えば、マージソートアルゴリズムは、1つの要素だけが残るまで、配列を2つのサブ配列に何度も分割します(再帰を利用します)。そこから、要素が「マージ」されて、最終的なソートされた配列が形成されます。バブルソートや他の同様のアルゴリズムとは異なり、マージソートは視覚化なしでは理解するのが困難です。次の図は、マージソートがどのように機能するかを示すウィキペディアの段階的な図です。ただし、何が起こっているのかまだ少し曖昧であっても心配しないでください。次にコードを処理します。
以前に説明したアルゴリズム(つまり、バブルと選択)とは異なり、実際のタスクでは基本的に実用的ではありませんでしたが、マージソートはBig-O表記の点ではるかに優れています。 Big-O表記に慣れていない場合は、さまざまなアルゴリズムの最悪の場合のパフォーマンスを表しています。これにより、Big-Oに基づいてアルゴリズムを簡単に比較できます。たとえば、Big-OがO(1)のアルゴリズムは、最悪の場合の実行時間が要素数 "n"の増加に伴って一定であることを意味しますが、Big-O表記がO(1)のアルゴリズムはn)は、nが大きくなるにつれて、最悪の場合の実行時間が直線的に増加することを意味します。つまり、100個の要素を持つ配列があり、O(n)とO(1)の並べ替えアルゴリズムを選択する必要がある場合、O(1)はO(100)よりも確実に優れているため、O(1)アルゴリズムを選択します。バブルと選択ソートのアルゴリズムはどちらも最悪の場合O(n ^ 2)です。これは、要素の数が増えるとアルゴリズムの実行が非常に遅くなることを意味するため、あまり役に立ちません。対照的に、マージソートはn log(n)で実行されます。これは、アルゴリズムがバブルソートや選択ソートほど効率を犠牲にしないことを意味します。
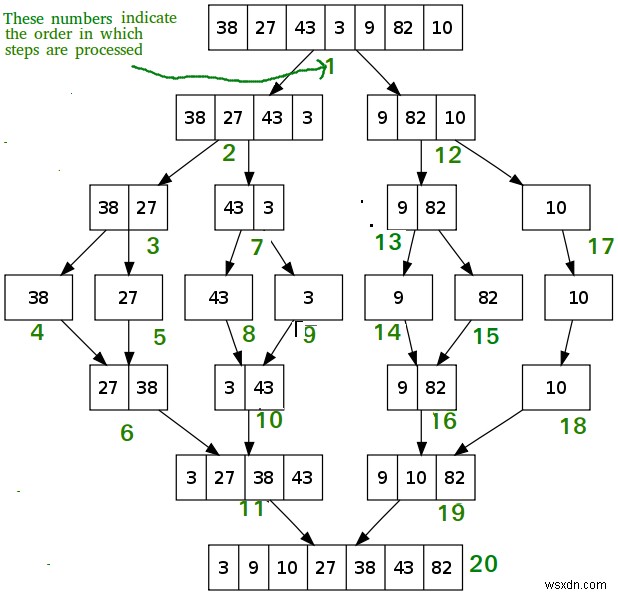
図の例を見ていきましょう。 [38, 27, 43, 3, 9, 82, 10]の配列から始めます 次に、単一の要素が残るまで配列を半分に分割します。
- 開始配列を2つに分割します:
[38, 27, 43, 3]および[9, 82, 10]。 - 前半をもう一度分割します:
[38, 27]および[43, 3]。 - 前半を単一の要素に分割します:
[38]、[27]、[43]、および[3]。 - 38と27を並べ替えて
[27, 38]を作成します[3, 43]を作成するための48と3 。 - これらをまとめると、
[3, 27, 38, 43]があります。 。 - 次に、元の配列の後半である
[9, 82, 10]に移動します。 。半分に分割して[9, 82]を取得します および[10]。 -
[9, 82]を分割します[9]に および[82]、そして[10]、これはすでに特異です。 -
[9, 82]を並べ替えます 一緒に戻ってから、[10]をマージします 戻って、[9, 10, 82]になります 。 - 最後に、
[3, 27, 38, 43]をマージします および[9, 10, 82][3, 9, 10, 27, 38, 43, 82]を取得するには 。
以下は、Rubyで記述されたマージソートアルゴリズムです。
class MergeSort
def sort(numbers)
num_elements = numbers.length
if num_elements <= 1
return numbers
end
half_of_elements = (num_elements / 2).round
left = numbers.take(half_of_elements)
right = numbers.drop(half_of_elements)
sorted_left = sort(left)
sorted_right = sort(right)
merge(sorted_left, sorted_right)
end
def merge(left_array, right_array)
if right_array.empty?
return left_array
end
if left_array.empty?
return right_array
end
smallest_number = if left_array.first <= right_array.first
left_array.shift
else
right_array.shift
end
recursive = merge(left_array, right_array)
[smallest_number].concat(recursive)
end
end
ここで何が起こっているのかを見ていきましょう。まず、sortに焦点を当てます 上部のメソッド。
def sort(numbers)
num_elements = numbers.length
if num_elements <= 1
return numbers
end
half_of_elements = (num_elements / 2).round
left = numbers.take(half_of_elements)
right = numbers.drop(half_of_elements)
sorted_left = sort(left)
sorted_right = sort(right)
merge(sorted_left, sorted_right)
end
コードのこの部分の目標は、それぞれに1つのアイテムだけが残るまで、指定された数値を半分に分割することです。実際の動作を確認するには、最後の行(merge(sorted_left、sorted_right))をコメントアウトし、代わりにsorted_leftを出力します。 およびsorted_right 。サンプル配列を渡してプログラムを実行すると、ターミナルに次のように表示されます。
merge_sort = MergeSort.new
puts merge_sort.sort([38, 27, 43, 3, 9, 82, 10])
ruby ruby-merge-sort.rb
27
43
38
3
9
82
10
すごい!私たちのコードは最初の配列を取り、それを半分に分割しました。 mergeを見てみましょう 次のコードの一部。
def merge(left_array, right_array)
if right_array.empty?
return left_array
end
if left_array.empty?
return right_array
end
smallest_number = if left_array.first <= right_array.first
left_array.shift
else
right_array.shift
end
recursive = merge(left_array, right_array)
[smallest_number].concat(recursive)
end
まず、いずれかのサブ配列が空かどうかを確認します。もしそうなら、私たちは単にもう一方を返すことができます。それ以外の場合は、両方のサブ配列が空でない場合、各配列の最初の要素の値を比較してから、比較した値をシフトして、無限ループが作成されないようにします。次に、2つの配列を最終的に接続して適切にソートできるようになるまで、元の配列で再帰を利用します(これについては後ほど詳しく説明します)。
私たちのコードに奇妙に見えるものがある場合、それは次の行だと思います:recursive = merge(left_array, right_array) mergeと呼んでいます それ自体の中でからのメソッド 。うわあ!これは、再帰と呼ばれるものです。これは、指定された条件が満たされるまで、関数がそれ自体を1回以上呼び出す手法です。この場合、merge 左または右の配列が空になるまで呼び出され続けます。再帰について詳しく知りたい場合は、Rubyと再帰を利用してフィボナッチ数列の関数を作成する例を次に示します。
マージソートについてもっと楽しく学んでいただければ幸いです。それがどのように高レベルで機能するか、そしてなぜそれがバブルや選択ソートよりも効率的な選択であるかを理解することは、就職の面接やあなたの日常の仕事に役立つでしょう。また、興味があれば、ウィキペディアで詳細を読むことができるマージソートのバリエーションがいくつかあります。次回まで...ハッピーソーティング!
-
TCmallocを使用したRubyのメモリ割り当てのプロファイリング
Rubyではメモリ割り当てはどのように機能しますか? Rubyはページと呼ばれるチャンクでメモリを取得し、新しいオブジェクトはここに保存されます。 次に… これらのページがいっぱいになると、より多くのメモリが必要になります。 Rubyは、mallocを使用してオペレーティングシステムからより多くのメモリを要求します 機能。 このmalloc 関数はオペレーティングシステム自体の一部ですが、使用できる代替の実装があります。 それらの実装の1つは、Googleのtcmallocです。 TCmallocはGoogleパフォーマンスツールスイートの一部です。 これらのツールを使用し
-
Rubyでパーサーを構築する方法
構文解析は、一連の文字列を理解し、それらを理解できるものに変換する技術です。正規表現を使用することもできますが、必ずしもその仕事に適しているとは限りません。 たとえば、HTMLを正規表現で解析することはおそらく良い考えではないことは一般的な知識です。 Rubyには、この作業を実行できるnokogiriがありますが、独自のパーサーを作成することで多くのことを学ぶことができます。始めましょう! Rubyでの解析 パーサーの中核はStringScannerです クラス。 このクラスは、文字列のコピーと位置ポインタを保持します。ポインタを使用すると、特定のトークンを検索するために文字列をトラバ