スタックとヒープの違い
この投稿では、スタックとヒープの違いを理解します
スタック
-
これは線形データ構造です。
-
メモリは連続した(連続した)ブロックに割り当てられます。
-
スタックのメモリは、コンパイラの指示を使用して自動的に割り当ておよび割り当て解除されます。
-
スタックの構築と維持にかかる費用は少なくて済みます。
-
実装は簡単です。
-
サイズは固定されています。したがって、柔軟性はありません。
-
その唯一の欠点は、サイズが固定されているため、メモリが不足していることです。
-
すべてのブロックが占有されていない場合、メモリも無駄になります。
-
スタックの要素にアクセスするのにかかる時間は短くなります。
-
参照の局所性に優れています。
ヒープ
-
これは階層的なデータ構造です。
-
メモリはランダムに割り当てられます。
-
メモリは、プログラマーによって手動で割り当ておよび割り当て解除されます。
-
ヒープの構築と維持にはコストがかかります。
-
ヒープ構造を実装するのは困難です。
-
ヒープの要素にアクセスするには、さらに時間がかかります。
-
ヒープの欠点は、メモリの断片化です。
-
ヒープ内でサイズ変更が可能です。
-
したがって、メモリが無駄になることはありません。
-
十分な参照の局所性があります。
メインメモリ内のプロセス-
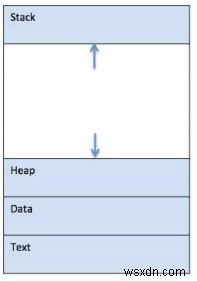
-
アルゴリズムとフローチャートの違い
この投稿では、フローチャートとアルゴリズムの違いを理解しましょう。 アルゴリズム これは、明確に定義された一連のステップとして定義されます。 これらの手順は、手元にある問題を解決する/解決する方法を提供します。 これは体系的で論理的なアプローチであり、手順は段階的に定義されます。 特定の問題の解決策を提供します。 このソリューションはマシンコードに変換され、システムによって実行されて関連する出力が得られます。 多くの単純な操作を組み合わせて、より複雑な操作を形成します。これは、コンピューターによって簡単に実行されます。 アルゴリズムは、自然言語、フローチャートなどを使用して表すことができます
-
BFSとDFSの違い
BFSとDFSはグラフ走査アルゴリズムです。 BFS 幅優先探索(BFS)アルゴリズムは、グラフを横方向に移動し、キューを使用して、反復で行き止まりが発生したときに、次の頂点を取得して検索を開始することを忘れないようにします。 DFS 深さ優先探索(DFS)アルゴリズムは、グラフを深さ方向に移動し、スタックを使用して、反復で行き止まりが発生したときに、次の頂点を取得して検索を開始することを忘れないようにします。 以下は、BFSとDFSの重要な違いです。 Sr。いいえ。 キー BFS DFS 1 定義 BFS、幅優先探索の略です。 DFS、