データ構造におけるキャッシュミスのカウント
アルゴリズム分析では、操作とステップをカウントします。これは基本的に、コンピューターが操作に必要なデータをフェッチするのにかかる時間よりも操作の実行に時間がかかる場合に正当化されます。現在、操作を実行するコストは、メモリからデータをフェッチするコストよりも大幅に低くなっています。
多くのアルゴリズムの実行時間は、操作の数ではなく、メモリ参照の数(キャッシュミスの数)によって支配されます。したがって、いくつかのアルゴリズムを設計しようとするときは、操作の数だけでなく、メモリアクセスの数も減らすことに焦点を当てる必要があります。また、メモリの待ち時間を隠すアルゴリズムの設計にも焦点を当てる必要があります。
コンピュータのメモリがL1キャッシュ、L2キャッシュ、およびメインメモリで構成されている単純なコンピュータモデルがあるとします。レジスタ(R)に常駐するデータに対してALUを使用して、算術演算と論理演算を実行します
これはそのブロック図です-
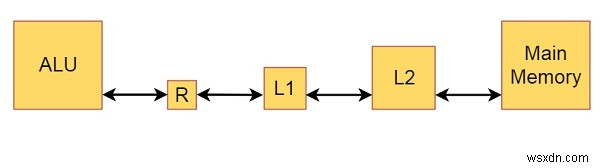
この図から、メモリとキャッシュのサイズに関する知識も得られます。メインメモリは基本的に数百または数千MBです。ここで、L2キャッシュはMBの一部であり、L1キャッシュはKBです。レジスタサイズは数ビットです。プログラムを実行すると、メモリ内のすべてのデータ。 ADDなどの演算を追加すると、最初の数値がレジスタに格納され、レジスタ内のデータが追加されてから、結果がメモリに書き込まれます。
1サイクルを、すでにレジスタにあるデータを追加するために必要な時間の長さとします。 L1キャッシュからレジスタにデータをロードするために必要な時間は、このモデルでは2サイクルと想定されています。必要なデータがL1キャッシュになく、L2キャッシュに存在する場合、L1キャッシュミスが発生し、必要なデータがL2キャッシュからL1キャッシュ、およびレジスタに10サイクルで取得されます。必要なデータがL2キャッシュにもない場合、L2キャッシュミスが発生し、必要なデータがメインメモリからL2キャッシュ、L1キャッシュ、およびレジスタに100サイクルで取り込まれます。その後、データがメインメモリに書き込まれている場合でも、書き込み操作は1サイクルとしてカウントされます。これは、次の操作に進む前に完全な書き込みを待たないためです。
-
データ構造のB+ツリー
ここでは、B+ツリーとは何かを確認します。 B +ツリーは、Bツリーの拡張バージョンです。このツリーは、Bツリーのより良い挿入、削除、および検索をサポートします。 Bツリー、キー、およびレコード値は、内部ノードとリーフノードに格納されます。 B +ツリーレコードでは、リーフノードに保存できます。内部ノードはキー値のみを保存します。 B+ツリーのリーフノードもリンクリストのようにリンクされています B+ツリーの例 − これは、検索、挿入、削除などの基本的な操作をサポートします。各ノードで、アイテムが並べ替えられます。位置iの要素には、その前後に子があります。したがって、以前に痛んだ
-
ハーフエッジデータ構造
はじめに テンプレートパラメータまたはハーフエッジデータ構造(HalfedgeDSと略記)のHDSは、平面マップ、多面体、またはその他の方向付け可能な2次元など、頂点、エッジ、および面の入射情報を維持できるエッジ中心のデータ構造として定義されます。ランダムな次元に埋め込まれたサーフェス。各エッジは、反対方向の2つのハーフエッジに分割されます。各ハーフエッジには、1つの入射面と1つの入射頂点が格納されます。各面と各頂点に1つの入射ハーフエッジが格納されます。ハーフエッジデータ構造のバリエーションを減らすと、面のハーフエッジポインタや面の保存など、この情報の一部を削除できます。 ハーフエッジデ