13年後– Redisには新しいアーキテクチャが必要ですか?
Redisは基盤技術であるため、代替アーキテクチャを検討している人を時々目にします。数年前、これはKeyDBによって提起され、最近、新しいプロジェクトであるDragonflyが、Redisと互換性のある最速のインメモリデータストアであると主張しました。これらのプロジェクトは、議論や議論に値する多くの興味深い技術やアイデアをもたらすと信じています。ここRedisでは、Redisが最初に設計されたアーキテクチャの原則を再確認する必要があるため、この種の課題が気に入っています(Salvatore Sanfilippo、別名antirezへのヒント)。
Redisのパフォーマンスと機能を革新および向上させる機会を常に模索していますが、Redisのアーキテクチャがインメモリのリアルタイムデータストア(キャッシュ)としてクラス最高であり続ける理由について、私たちの見解と考察を共有したいと思います。 、データベース、およびその間のすべて)。
したがって、次のセクションでは、行われている比較に関連する速度とアーキテクチャの違いについての視点を強調します。この投稿の最後に、ベンチマークとパフォーマンスの比較とDragonflyプロジェクトの詳細も示しました。これについては、以下で説明します。これらを確認して、自分で再現してください。
スピード
Dragonflyベンチマークは、スタンドアロンのシングルプロセスRedisインスタンス(シングルコアのみを利用できる)とマルチスレッドのDragonflyインスタンス(VM /サーバーで利用可能なすべてのコアを利用できる)を比較します。残念ながら、この比較は、Redisが現実の世界でどのように実行されているかを表すものではありません。テクノロジービルダーとして、私たちは自分のテクノロジーが他のテクノロジーとどのように比較されるかを正確に理解するよう努めています。そのため、公正な比較であると信じていることを行い、40シャードのRedis 7.0クラスター(ほとんどのインスタンスコアを利用できる)をDragonflyと比較しました。 Dragonflyチームがベンチマークで使用した最大のインスタンスタイプであるAWSc6gn.16xlargeでのパフォーマンステストのセット。私たちのトライアルでは、64個のvCoreのうち40個しか使用していない場合でも、RedisがDragonflyよりも18%〜40%高いスループットを達成していることがわかりました。
アーキテクチャの違い
いくつかの背景
これらのマルチスレッドプロジェクトの作成者が行ったアーキテクチャ上の決定の多くは、前の作業で経験した問題点に影響されたと考えられます。マルチコアマシンで単一のRedisプロセスを実行すると、場合によっては数十のコアと数百GBのメモリが使用され、明らかに利用可能なリソースを利用できないことに同意します。しかし、これはRedisが使用されるように設計された方法ではありません。これは、サービスを実行するために選択したRedisプロバイダーの数です。
Redisは、単一のクラウドインスタンスのコンテキストでも、(Redisクラスターを使用して)マルチプロセスを実行することで水平方向にスケーリングします。 Redis(会社)では、この概念をさらに発展させ、ユーザーがRedisを大規模に実行できるようにする管理レイヤーを提供する、Redis Enterpriseを構築しました。高可用性、インスタントフェイルオーバー、データ永続性、バックアップがデフォルトで有効になっています。
実稼働環境でRedisを実行するための優れたエンジニアリング手法であると人々が信じていることを人々が理解できるように、舞台裏で使用している原則のいくつかを共有することにしました。
アーキテクチャの原則
VMごとに複数のRedisインスタンスを実行する
VMごとに複数のRedisインスタンスを実行すると、次のことが可能になります。
- 完全にシェアードナッシングアーキテクチャを使用して、垂直方向と水平方向の両方で線形にスケーリングします。これにより、垂直方向にのみ拡張できるマルチスレッドアーキテクチャと比較して、常に柔軟性が向上します。
- レプリケーションは複数のプロセス間で並行して実行されるため、レプリケーションの速度を上げます。
- 新しいVMのRedisインスタンスには、複数の外部Redisインスタンスからのデータが同時に入力されるため、VMの障害からの迅速な復旧。
各Redisプロセスを適切なサイズに制限する
1つのRedisプロセスのサイズが25GB(FlashでRedisを実行している場合は50 GB)を超えることはできません。これにより、次のことが可能になります:
- レプリケーション、スナップショット、およびファイルの追加(AOF)の書き換えのためにRedisをフォークするときに、大きなメモリオーバーヘッドのペナルティを支払うことなく、コピーオンライトの利点を享受できます。そして、あなたがそれをしなければ「はい」、あなた(またはあなたのユーザー)はここに示されているように高い代償を払うでしょう。
- クラスターを簡単に管理するには、Redisのすべてのインスタンスが小さく保たれているため、シャードの移行、リシャード、スケーリング、リバランスをすばやく行うことができます。
水平方向のスケーリングが最も重要です
水平スケーリングでメモリ内データストアを実行する柔軟性は非常に重要です。理由は次のとおりです。
- 回復力の向上 –クラスターで使用するノードが多いほど、クラスターはより堅牢になります。たとえば、データセットを3ノードのクラスターで実行し、1つのノードが劣化している場合、パフォーマンスが低下しているのはクラスターの1/3です。ただし、データセットを9ノードのクラスターで実行し、1つのノードが劣化している場合、クラスターの1/9だけが実行されていません。
- スケーリングが簡単 –より大きなノードを持ってきてデータセット全体をコピーする必要がある垂直方向にスケーリングするよりも、クラスターにノードを追加してデータセットの一部だけをクラスターに移行する方がはるかに簡単です(そしてすべての悪いことを考えてください)これは、この潜在的に長いプロセスの途中で発生する可能性があります…)
- 段階的なスケーリングははるかに費用効果が高い –特にクラウドでは、垂直方向のスケーリングにはコストがかかります。多くの場合、データセットに数GBを追加するだけでよい場合でも、インスタンスサイズを2倍にする必要があります。
- 高スループット – Redisでは、非常に高いネットワーク帯域幅や1秒あたりのパケット数(PPS)の需要が非常に高い、小さなデータセットで高スループットのワークロードを実行している多くのお客様がいます。 100万回以上の運用/秒のユースケースを持つ1GBのデータセットについて考えてみてください。 3ノードのc6gn.xlargeクラスター(8GB。4CPU、最大25Gbps、それぞれ$ 0.1786 / hr)ではなく、シングルノードのc6gn.16xlargeクラスター(128GB、64 CPU、100gbps、$ 2.7684 / hr)で実行するのは理にかなっていますか? )コストの20%未満で、はるかに堅牢な方法で?費用対効果を維持し、復元力を向上させながらスループットを向上させることができることは、この質問に対する簡単な答えのように思えます。
- NUMAの現実 –垂直方向にスケーリングするということは、複数のコアと大きなDRAMを備えた2ソケットサーバーを実行することも意味します。このNUMAベースのアーキテクチャは、より小さなノードのネットワークのように動作するため、Redisのようなマルチプロセッシングアーキテクチャに最適です。ただし、NUMAはマルチスレッドアーキテクチャにとってより困難であり、他のマルチスレッドプロジェクトでの経験から、NUMAはメモリ内データストアのパフォーマンスを最大80%低下させる可能性があります。
- ストレージスループットの制限 – AWS EBSのような外部ディスクは、メモリやCPUほど高速ではありません。実際、使用されているマシンクラスに基づいて、クラウドサービスプロバイダーによって課せられるストレージスループットの制限があります。したがって、クラスターを効果的にスケーリングして、すでに説明した問題を回避し、高いデータ永続性要件を満たす唯一の方法は、水平スケーリングを使用することです。つまり、ノードとネットワーク接続ディスクを追加することです。
- エフェメラルディスク –エフェメラルディスクは、SSDでRedisを実行し(SSDはDRAMの代替として使用されますが、永続ストレージとしては使用されません)、Redisの速度を維持しながらディスクベースのデータベースのコストを享受するための優れた方法です(実行方法を参照してください)。 Redis on Flashを使用)。繰り返しになりますが、エフェメラルディスクが限界に達した場合、最良の方法であり、多くの場合、クラスターをスケーリングする唯一の方法は、ノードとエフェメラルディスクを追加することです。
- コモディティハードウェア –最後に、ローカルデータセンター、プライベートクラウド、さらには小規模なエッジデータセンターで実行されている多くのオンプレミスのお客様がいます。これらの環境では、64GBを超えるメモリと8個のCPUを搭載したマシンを見つけるのは難しい場合があります。また、スケーリングする唯一の方法は水平です。
概要
マルチスレッドプロジェクトの新しい波によって提供される、コミュニティからの新鮮で興味深いアイデアとテクノロジーに感謝します。これらの概念の一部が将来Redisに組み込まれる可能性もあります(すでに調査を開始したio_uring、最新の辞書、スレッドのより戦術的な使用など)。ただし、当面の間、Redisが提供するシェアードナッシングマルチプロセスアーキテクチャの基本原則を放棄することはありません。この設計は、最高のパフォーマンス、スケーリング、および復元力を提供すると同時に、インメモリのリアルタイムデータプラットフォームに必要なさまざまな導入アーキテクチャをサポートします。
付録Redis7.0とDragonflyベンチマークの詳細
ベンチマークの概要
バージョン:
- Redis 7.0.0を使用し、ソースからビルドしました
- Dragonflyは、https://github.com/Dragonfly/dragonfly#building-from-source で推奨されているように、6月3日にソースからビルドされました(hash =e806e6ccd8c79e002f721a1a5ecb847bd7a06489)。
目標:
- Dragonflyの結果が再現可能であることを確認し、それらが取得された完全な条件を特定します(memtier_benchmark、OSバージョンなどにいくつかの構成が欠落している場合)。詳細はこちらをご覧ください
- Dragonflyのベンチマークと一致する、AWSc6gn.16xlargeインスタンスで達成可能な最高のOSSRedis7.0.0クラスターパフォーマンスを決定します
クライアント構成:
- OSS Redis 7.0ソリューションでは、各 memtier_benchmark に応じて、Redisクラスターへのより多くのオープン接続が必要でした。 スレッドはすべてのシャードに接続されています
- OSS Redis 7.0ソリューションは、2つの memtier_benchmarkで最良の結果を提供しました。 ベンチマークを実行しているが、Dragonflyベンチマークと一致する同じクライアントVM上にあるプロセス)
リソース使用率と最適な構成:
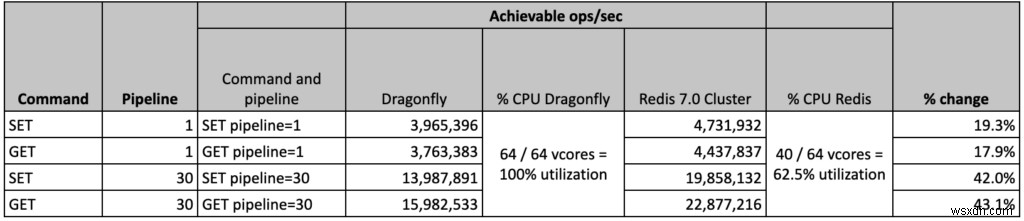
- OSS Redisクラスターは、40個のプライマリシャードで最高の結果を達成しました。つまり、VMには24個のスペアvCPUがあります。マシンは十分に活用されていませんでしたが、シャードの数を増やしても効果がなく、全体的なパフォーマンスが低下することがわかりました。現在、この動作について調査中です。
- 一方、DragonflyソリューションはVMを完全に補充し、64個のVCPUすべてが100%の使用率に達しました。
- どちらのソリューションでも、可能な限り最高の結果を達成するために、クライアント構成を変更しました。以下に示すように、Dragonflyデータの大部分を複製し、30に等しいパイプラインの最良の結果を超えることさえできました。
- これは、Redisで達成した数をさらに増やす可能性があることを意味します。
最後に、RedisとDragonflyの両方がネットワークPPSまたは帯域幅によって制限されていないこともわかりました。これは、2つの使用済みVM(クライアントとサーバーの場合、c6gn.16xlargeを使用するボット)間で>10MPPSに到達できることを確認したためです。ペイロードが約300億のTCPの場合は>30Gbps。
結果の分析
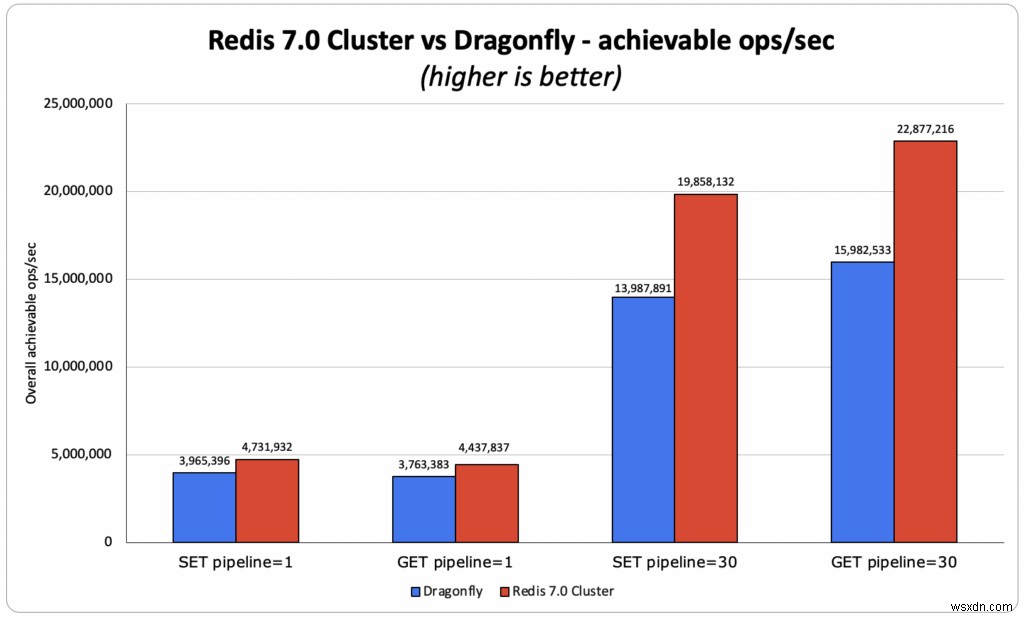
- GETパイプライン1サブミリ秒 :
- OSS Redis:443万ops /秒。平均とp50の両方で、ミリ秒未満の遅延が達成されました。クライアントの平均待機時間は0.383ミリ秒でした
- トンボは4Mops/ secを主張しました:
- クライアントの平均レイテンシは0.390ミリ秒で、380万オペレーション/秒を再現できました。
- RedisとDragonfly–Redisのスループットは10% vs.トンボは結果を主張し、 18% 対トンボの結果、再現できました。
- GETパイプライン30:
- OSS Redis:22.9M ops /秒、平均クライアントレイテンシは2.239ミリ秒
- トンボは1500万回/秒を主張しました:
- クライアントの平均レイテンシが3.99ミリ秒で、15.9M ops/secを再現できました。
- Redis vs Dragonfly –Redisは43%優れています (対Dragonflyは結果を再現しました)そして 52% (対トンボは結果を主張しました)
- SETパイプライン1サブミリ秒 :
- OSS Redis:474万ops /秒、平均とp50の両方でミリ秒未満のレイテンシが達成されました。平均クライアントレイテンシは0.391ミリ秒でした
- トンボは4Mops/ secを主張しました:
- クライアントの平均レイテンシが0.500ミリ秒で、400万オペレーション/秒を再現できました。
- Redis vs Dragonfly –Redisは1 9%優れています (Dragonflyが主張したのと同じ結果を再現しました)
- SETパイプライン30:
- OSS Redis:19.85M ops /秒、平均クライアントレイテンシは2.879ミリ秒
- トンボは1000万回/秒を主張しました:
- クライアントの平均レイテンシは4.203ミリ秒で、1400万オペレーション/秒を再現できました)
- Redis vs Dragonfly –Redisは42%優れています (vs Dragonflyの再現結果)および 99% (対トンボは結果を主張しました)
memtier_benchmark 各バリエーションに使用されるコマンド:
- GETパイプライン1サブミリ秒
- Redis:
- 2X:memtier_benchmark –ratio 0:1 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide -ヒストグラム
- トンボ:
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram
- Redis:
- GETパイプライン30
- Redis:
- 2X:memtier_benchmark –ratio 0:1 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide -ヒストグラム–パイプライン30
- トンボ:
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30
- Redis:
- SETパイプライン1サブミリ秒
- Redis:
- 2X:memtier_benchmark –ratio 1:0 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide -ヒストグラム
- トンボ:
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram
- Redis:
- SETパイプライン30
- Redis:
- 2X:memtier_benchmark –ratio 1:0 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide -ヒストグラム–パイプライン30
- トンボ:
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30
- Redis:
インフラストラクチャの詳細
クライアント(memtier_benchmarkを実行するため)とサーバー(RedisとDragonflyを実行するため)の両方に同じVMタイプを使用しました。仕様は次のとおりです。
- VM :
- AWS c6gn.16xlarge
- aarch64
- ARM Neoverse-N1
- ソケットあたりのコア:64
- コアあたりのスレッド:1
- NUMAノード:1
- AWS c6gn.16xlarge
- カーネル:Arm64カーネル5.10
- インストールされているメモリ: 126GB
-
Android デバイスにクリーニング アプリが必要な理由
Android デバイスにクリーニング アプリが必要な理由も知りたい場合は、この記事を読んでください。ここでは、デバイス用のクリーニングアプリを入手することが不可欠であることを説明します.時間が経つにつれて、携帯電話の動作が遅くなり、ストレージは不要なものでいっぱいになります。これによりパフォーマンスが低下し、不要なアプリやファイルによって携帯電話のストレージがいっぱいになります。キャッシュと一時ファイルを時々クリーニングし続けることはできません。また、クリーニングしたとしても、すべてのファイルとキャッシュを見つけるのは簡単ではありません。そこで、Android 上のジャンクをクリーンアップす
-
Motorola Moto G6 - 3 年後 ...
仕事の丁寧さが自慢です。その自己妄想の一部は、一連の長期的なハードウェア レビューです。つまり、私は一片のキットを手に入れ、それを使い始め、そして時折、2 年、3 年、または 7 年後に進行中の経験について書きます。少し忍耐が必要ですが、かなり興味深い実験になります。また、当然の結論を出すことはできません。 通常、このタイプの書き込みはラップトップに焦点を当てていますが、最近ではスマートフォンでも書き始めました。私はモバイルの世界にあまり熱心ではありませんが、ねえ。チンパンジーはチンパンジー。たまたま、2019 年の初めに、Moto G6 デバイスを手に入れました。これは手頃な価格の携帯電話