RubyでのAWSLambda関数の構築、テスト、デプロイ
ソフトウェアの開発は難しい場合がありますが、それを維持することははるかに困難です。メンテナンスには、ソフトウェアパッチとサーバーメンテナンスが含まれます。この投稿では、サーバーの管理と保守に焦点を当てます。
従来、サーバーはオンプレミスでした。つまり、物理ハードウェアを購入して保守していました。クラウドコンピューティングでは、これらのサーバーを物理的に所有する必要がなくなりました。 2006年にAmazonがAWSを開始し、EC2サービスを導入したとき、現代のクラウドコンピューティングの時代が始まりました。このタイプのサービスでは、物理サーバーを保守したり、物理ハードウェアをアップグレードしたりする必要がなくなりました。これで多くの問題が解決しましたが、サーバーのメンテナンスとリソース管理はまだ私たち次第です。これらの開発を次のレベルに引き上げることで、サーバーレステクノロジーが実現しました。
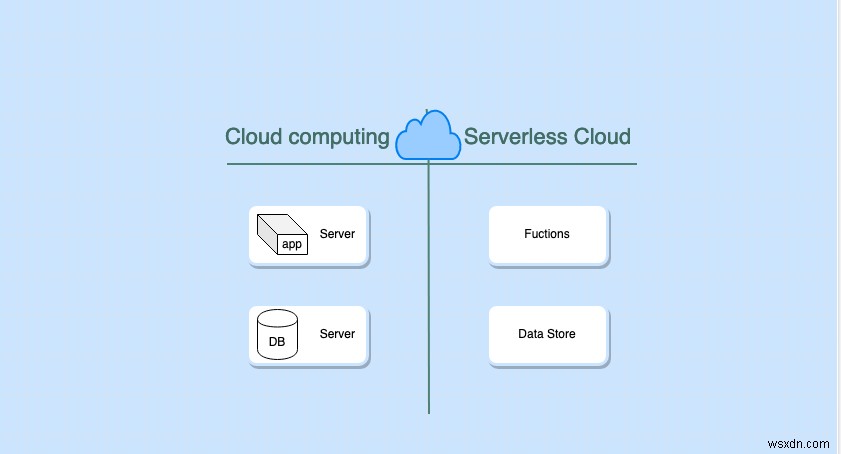
サーバーレステクノロジーは、サーバーの管理とプロビジョニングの作業をクラウドプロバイダーに任せるのに役立ちます。この投稿では、AWSについて説明します。
サーバーレスという用語は、サーバーがまったくないことを意味するものではありません。サーバーはありますが、クラウドプロバイダーによって完全に管理されています。ある意味で、サーバーレステクノロジーのユーザーにとって、目に見えるサーバーはありません。サーバーは私たちには直接見えず、サーバーを管理する仕事はクラウドプロバイダーによって自動化されています。サーバーレスにする特徴のいくつかを次に示します。
- 運用管理なし-サーバーにパッチを適用したり、高可用性を実現するためにサーバーを管理したりする必要はありません。
- 必要に応じて拡張-少数のユーザーのみにサービスを提供することから、数百万のユーザーにサービスを提供することまで。
- 従量課金制-費用は使用量に基づいて管理されます。
サーバーレステクノロジーは、次のように分類できます。
- 計算 (例:ラムダとファーゲート)
- ストレージ (例:S3)
- データストア (例:DynamoDBとAurora)
- 統合 (例:APIゲートウェイ、SNS、SQS)
- 分析 (例:キネシスとアテナ)
サーバーレステクノロジーを使用する主な利点の1つは、従量課金制です。トラフィック量に予測できない変化がある場合は、使用パターンに基づいてサーバーをスケールアップまたはスケールダウンする必要がありますが、自己管理型の自動スケーリングを使用したスケーリングは困難で非効率的です。 AWS Lambdaなどのサーバーレスコンピューティングは、アイドル時に支払う必要がないため、コストを簡単に節約できます。
サーバーレスコンピューティングとは、クラウドプロバイダーが提供するフルマネージドサービスを指すため、開発者がサーバーをプロビジョニングしたり、サーバーアプリケーションを開発したりする必要はありません。開発者は、サーバーを管理しなくても、すぐにコーディングを開始できます。このアプローチにより、サーバーにパッチを適用したり、自動スケーリングを管理したりする必要もなくなります。この時間をすべて節約することで、開発者の生産性を向上させることができます。
サーバーレスコンピューティングは非常に弾力性があり、使用状況に応じてスケールアップまたはスケールダウンできます。ユーザーの急増は簡単に処理できます。これは大きな利点であり、開発者の時間を大幅に節約するのに役立ちます。
コンピューティングがサーバーレスでクラウドプロバイダーによって管理されており、サーバーの稼働時間が長い場合、フェイルオーバーは自動的に処理されます。この種の問題を管理するには、専門的なスキルが必要です。サーバーレスアプローチを使用すると、運用担当者と開発者の作業を1人で行うことができます。
Rubyでサーバーレス機能を実装する方法
AWSによると、RubyはAWSで最も広く使用されている言語の1つです。 Lambdaは2018年11月にRubyのサポートを開始しました。AWSが提供するサーバーレステクノロジーのみを使用して、RubyでWebAPIを構築します。
AWSでサーバーレスインフラストラクチャを作成するには、AWSコンソールにログインして作成を開始するだけです。ただし、簡単にテストでき、災害復旧を容易にするものを開発したいと考えています。サーバーレス機能をコードとして記述します。そのために、AWSはサーバーレスアプリケーションモデル(SAM)を提供しています。 SAMは、AWSでサーバーレスアプリケーションを構築するために使用されるフレームワークです。 Lambda、データベース、APIを設計するためのYAMLベースの構文を提供します。 AWS SAMアプリケーションは、このリンクからダウンロードできるAWSSAM-CLIを使用して構築できます。
AWS SAM CLIは、AWSCloudformationの上に構築されています。 CoudFormationを使用したIaCの記述に精通している場合、これは非常に簡単です。または、サーバーレスフレームワークを使用することもできます。この投稿では、AWSSAMを使用します。
SAM CLIを使用する前に、次のものがあることを確認してください。
- AWSプロファイルの設定
- Dockerがインストールされています
- SAMCLIがインストールされています
サーバーレスアプリケーションを開発します。まず、アプリケーションでDynamoDBやLambdaなどのサーバーレスインフラストラクチャをいくつか作成します。データベースから始めましょう:
DynamoDB
DynamoDBは、サーバーレスのAWS管理データベースサービスです。サーバーレスであるため、セットアップが非常に迅速で簡単です。 DynamoDBを作成するには、SAMテンプレートを次のように定義します。
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
UsersTable:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: id
Type: String
TableName: users
SAM CLIと上記のテンプレートを使用して、基本的なDynamoDBテーブルを作成できます。最初に、サーバーレスアプリのパッケージを構築する必要があります。このために、次のコマンドを実行します。これにより、パッケージがビルドされ、s3にプッシュされます。 serverless-users-bucketという名前のs3バケットを作成したことを確認してください コマンドを実行する前に:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
これで、s3がサーバーレスアプリのテンプレートとコードのソースになります。これについては、Lambda関数を作成するときに説明します。
これで、このテンプレートをデプロイしてDynamoDBを作成できます:
$ sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
これで、DynamoDBのセットアップが完了しました。次に、このテーブルが使用されるLambdaを作成します。
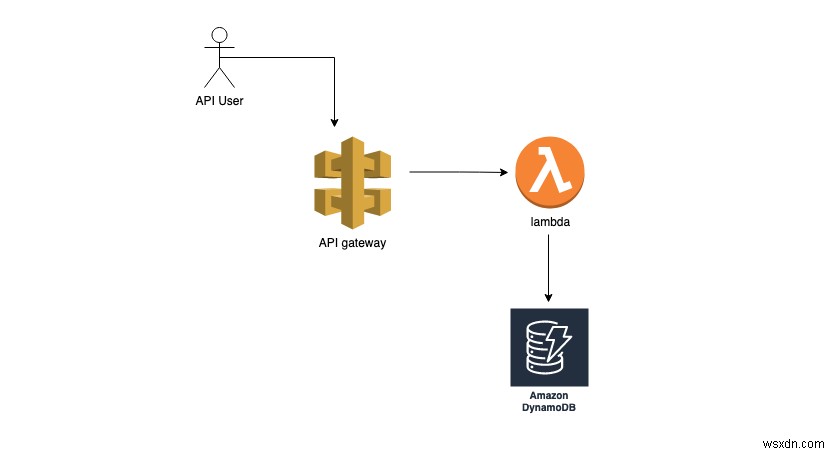
Lambdaは、AWSが提供するサーバーレスコンピューティングサービスです。コードが実行される実際のサーバー管理を必要とせずに、必要に応じてコードを実行するために使用できます。 Lambdaを使用して、非同期プロセス、REST API、またはスケジュールされたジョブを実行できます。 ハンドラー関数を作成するだけです。 関数をAWSLambdaにプッシュします。 Lambdaは、イベントに基づいてタスクを実行する役割を果たします。 。イベントは、APIゲートウェイ、SQS、S3などのさまざまなソースによってトリガーできます。別のコードベースによってトリガーすることもできます。トリガーされると、このLambda関数はイベントとコンテキストパラメーターを受け取ります。これらのパラメーターの値は、トリガーのソースによって異なります。これらのイベントをハンドラーに渡すことで、手動またはプログラムでLambda関数をトリガーすることもできます。ハンドラーは2つの引数を取ります:
イベント -イベントは通常、トリガーのソースから渡されるKey-Valueハッシュです。これらの値は、SQS、Kinesis、APIゲートウェイなどのさまざまなソースによってトリガーされると自動的に渡されます。手動でトリガーする場合、ここでイベントを渡すことができます。イベントには、Lambda関数ハンドラーの入力データが含まれています。たとえば、APIゲートウェイでは、リクエストの本文はこのイベント内に含まれています。
コンテキスト -コンテキストは、ハンドラー関数の2番目の引数です。これには、トリガーのソース、Lambda関数名、バージョン、request-idなどの特定の詳細が含まれます。
ハンドラーの出力は、Lambda関数をトリガーしたサービスに戻されます。 Lambda関数の出力は、ハンドラー関数の戻り値です。
AWS Lambdaは、Rubyを含む7つの異なる言語をサポートしています。ここでは、AWSRuby-sdkを使用してDynamoDBに接続します。
コードを書く前に、SAMテンプレートを使用してLambdaのインフラストラクチャを作成しましょう:
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: "Serverless users app"
Resources:
CreateUserFunction:
Type: AWS::Serverless::Function
Properties:
Handler: users.create
Runtime: ruby2.7
Policies:
- DynamoDBWritePolicy:
TableName: !Ref UsersTable
Environment:
Variables:
USERS_TABLE: !Ref UsersTable
ハンドラーには、実行する関数への参照をHandler: <filename>.<method_name>として記述します。 。
使用するリソースに基づいてLambdaにアタッチできるポリシーについては、サーバーレスポリシーテンプレートを参照してください。 Lambda関数はDynamoDBに書き込むため、DynamoDBWritePolicyを使用しました ポリシーセクションで。
また、指定されたデータベースにリクエストを送信できるように、環境変数USERS_TABLEをLambda関数に提供しています。
だから、それは私たちが以下のラムダに必要なものです。それでは、Lambda関数が実行するDynamoDBでユーザーを作成するコードを記述しましょう。
AWSレコードをGemfileに追加します:
# Gemfile
source 'https://rubygems.org' do
gem 'aws-record', '~> 2'
end
DynamoDBに入力を書き込むコードを追加します:
# users.rb
require 'aws-record'
class UsersTable
include Aws::Record
set_table_name ENV['USERS_TABLE']
string_attr :id, hash_key: true
string_attr :body
end
def create(event:,context:)
body = event["body"]
id = SecureRandom.uuid
user = UsersTable.new(id: id, body: body)
user.save!
user.to_h
end
とても速くて簡単です。 AWSはaws-recordを提供しています Railsのactiverecordに非常によく似たDynamoDBにアクセスするためのgem 。
次に、次のコマンドを実行して依存関係をインストールします。
注:Lambdaで定義されているものと同じバージョンのRubyを使用していることを確認してください。この例では、マシンにRuby2.7をインストールする必要があります。
# install dependencies
$ bundle install
$ bundle install --deployment
変更をパッケージ化します:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
デプロイ:
sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
このコードで、Lambdaが実行され、データベースに入力を書き込むことができます。 Lambdaの前にAPIゲートウェイを追加して、HTTP呼び出しを介してアクセスできるようにすることができます。 APIゲートウェイは、レート制限や認証など、多くのAPI管理機能を提供します。ただし、使用法によっては高額になる可能性があります。 API管理なしでHTTPAPIのみを使用するより安価なオプションがあります。ユースケースに基づいて、最も適切なものを選択できます。
AWSLambdaにはいくつかの制限があります。それらのいくつかは変更できますが、他は修正されています:
- メモリ -デフォルトでは、Lambdaの実行時に128MBのメモリがあります。これは、64MB刻みで最大3,008MBまで増やすことができます。
- タイムアウト -Lambda関数には、コードを実行するための時間制限があります。デフォルトの制限は3秒です。これは最大900秒まで増やすことができます。
- ストレージ -Lambdaは
/tmpを提供します ストレージ用のディレクトリ。このストレージの制限は512MBです。 - リクエストとレスポンスのサイズ -同期トリガーの場合は最大6MB、非同期トリガーの場合は最大256MB。
- 環境変数 -最大4KB
Lambdaにはこれらの制限のいくつかがあるため、これらの制限内に収まるコードを作成することをお勧めします。そうでない場合は、コードを分割して、あるLambdaが別のLambdaをトリガーするようにすることができます。 AWSが提供するステップ関数もあり、これを使用して複数のLambda関数をシーケンスできます。
サーバーレスアプリケーションをローカルでテストするにはどうすればよいですか?
サーバーレスアプリケーションの場合、マネージドサーバーレスサービスを提供するベンダーが必要です。アプリケーションのテストはAWSに依存しています。アプリケーションをテストするために、AWSが提供するいくつかのローカルオプションがあります。 AWSサーバーレステクノロジーと互換性のある一部のオープンソースツールを使用して、アプリケーションをローカルでテストすることもできます。
Lambda関数とDynamoDBをテストしてみましょう。そのためには、これらをローカルで実行する必要があります。
まず、Dockerネットワークを作成します。ネットワークは、Lambda関数とDynamoDB間の通信に役立ちます。
$ docker network create lambda-local --docker-network lambda-local
DynamoDB localは、AWSが提供するDynamoDBのローカルバージョンであり、ローカルでテストするために使用できます。次のDockerイメージを実行して、DynamoDBローカルを実行します。
$ docker run -p 8000:8000 --network lambda-local --name dynamodb amazon/dynamodb-local
user.rbに次の行を追加します ファイル。これにより、LambdaがローカルのDynamoDBに接続されます:
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'https://dynamodb:8000'
)
UsersTable.configure_client(client: local_client)
input.jsonを追加します Lambdaの入力を含むファイル:
{
"name": "Milap Neupane",
"location": "Global"
}
Lambdaを実行する前に、ローカルのDynamoDBにテーブルを追加する必要があります。そのために、aws-migrateが提供する移行機能を使用します。ファイルmigrate.rbを作成し、次の移行を追加しましょう:
require 'aws-record'
require './users.rb'
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'https://localhost:8000'
)
migration = Aws::Record::TableMigration.new(UsersTable, client: local_client)
migration.create!(
provisioned_throughput: {
read_capacity_units: 5,
write_capacity_units: 5
}
)
migration.wait_until_available
最後に、次のコマンドを使用してローカルでLambdaを実行します。
$ sam local invoke "CreateUserFunction" -t sam.yaml \
-e input.json \
--docker-network lambda-local
これにより、DynamoDBテーブルにユーザーのデータが作成されます。
AWSスタックをローカルで実行するためのlocalstackなどのオプションがあります。
サーバーレスコンピューティングを使用するかどうかを決定するときは、その長所と短所の両方に注意する必要があります。次の特性に基づいて、サーバーレスアプローチをいつ使用するかを決定できます。
費用
- アプリケーションにアイドル時間があり、トラフィックに一貫性がない場合、ラムダはコストの削減に役立つため、優れています。
- アプリケーションのトラフィック量が一定の場合、AWSLambdaの使用にはコストがかかる可能性があります。
パフォーマンス
- アプリケーションがパフォーマンスに敏感でない場合は、AWSLambdaを使用することをお勧めします。
- ラムダの起動時間はコールドブートであるため、コールドブート中の応答時間が遅くなる可能性があります。
バックグラウンド処理
- ラムダは、バックグラウンド処理に使用するのに適しています。 Sidekiqなどの一部のオープンソースツールには、サーバーのスケーリングとメンテナンスのオーバーヘッドがあります。 AWSLambdaとAWSSQSキューを組み合わせて、サーバーのメンテナンスの手間をかけずにバックグラウンドジョブを処理できます。
並行処理
- ご存知のように、Rubyでの並行性は簡単にできることではありません。 Lambdaを使用すると、プログラミング言語のサポートを必要とせずに並行性を実現できます。 Lambdaは同時に実行でき、パフォーマンスの向上に役立ちます。
定期的または1回限りのスクリプトの実行
- cronジョブを使用してRubyコードを実行しますが、大規模なアプリケーションではcronジョブのサーバーメンテナンスが難しい場合があります。イベントベースのLambdaを使用すると、アプリケーションのスケーリングに役立ちます。
これらは、サーバーレスアプリケーションでのLambda関数のいくつかのユースケースです。すべてをサーバーレスで構築する必要はありません。上記のユースケースのハイブリッドモデルを構築できます。これは、アプリケーションのスケーリングに役立ち、開発者の生産性を向上させます。サーバーレステクノロジーは進化し、改善されています。 AWSFatgateやGoogleCloudRunなど、AWSLambdaの制限がない他のサーバーレステクノロジーがあります。
-
NetlifyEdge関数とサーバーレスRedisの使用を開始する
最近、Netlifyは、グローバルに低レイテンシでDenoランタイムのエッジ位置でコードを実行できるエッジ関数を発表しました。この投稿では、Netlify Edgefunctionsを実行し、データストアとしてUpstashRedisにアクセスする簡単なアプリを作成します。 Upstash Redisは、次の理由でNetlifyEdge関数に完全に一致します。 Upstash Redisには、Redisレプリカが世界中に配布されるグローバルデータベースタイプがあります。したがって、エッジ関数は低レイテンシで最も近い領域にアクセスします。 UpstashRedisにはRESTAPIとSDK
-
AWSLambdaとサーバーレスRedisに裏打ちされたReactネイティブアプリの構築
この投稿では、React Native、サーバーレスフレームワーク、およびUpstashを使用して、リーダーボードを表示および更新するためのモバイルアプリケーションを開発します。 React Nativeを使用して、AWSLambdaで実行されるPython関数で構成されるサーバーレスフレームワークに基づくモバイルアプリケーションを開発します。 1-UpstashRedisの使用 一般的なリーダーボードアプリでは、ユーザー情報とユーザーに属するスコアを保存する必要があります。これらのデータはすべてスコアで並べ替える必要があるため、Redisを使用することが最善の解決策の1つです。 R