Rubyを使用してRSSから電子メールへのダイジェストスクリプトを作成しましょう
 このようなものが欲しい
このようなものが欲しい
ニュースレターの設定は、あまりにも長い間私のやることリストに載っていました。今日はそれを実現する日です。サインアップをご希望の場合は、こちらからお申し込みいただけます。
ロングコピーのニュースレターはあまり好きではありません。私が好きなのは、興味深いコンテンツの厳選されたダイジェストです。 RubyWeeklyが気になります。 Wistiaのブログダイジェストもそうです。
これらのダイジェストを手動でまとめるには時間がかかりすぎます。しかし、フルオートになるのは非人格的すぎます。だから私が欲しいのは半自動化されたプロセスです。最新のブログ投稿を取得し、パーソナライズできるHTMLメールを出力するスクリプトが必要です。
それでは、それを構築しましょう!たった1人のユーザーで幸せになる楽しい小さなプロジェクトになります-私!
スクリプトはいくつかのことを行う必要があります:
-
HoneybadgerブログのRSSフィードを取得して解析します
-
カテゴリ別に適切な記事を選択してください
-
ERBテンプレートを介して記事のコレクションをレンダリングする
コマンドラインから実行し、その結果をSTDOUTに出力します。
Rubyでのフィードの取得と解析
Rubyの標準ライブラリには、RSSおよびATOMフィードを生成および消費するためのモジュールが付属していることをご存知ですか?私たちのユースケースでは、これ以上簡単にすることはできません。仕組みは次のとおりです。
require 'rss'
feed = RSS::Parser.parse('https://www.honeybadger.io/blog/feed/')
feed.items.each do |item|
puts item.title
end
モジュールはフィードを取得します。サービスについて話してください!
興味のないリンクを購読者に送信したくないので、カテゴリで記事をフィルタリングします。 RubyのRSSライブラリにはcategoriesがありますが メソッドでは、XMLノードオブジェクトの配列を返します。カテゴリ名が必要なので、RSSアイテムをArticleというデコレータクラスでラップします。 。
これで、「ハウツー」カテゴリの記事のみを簡単に選択できるようになりました。
require 'rss'
require 'delegate'
class Article < SimpleDelegator
def category_names
categories.map &:content
end
end
feed = RSS::Parser.parse('https://www.honeybadger.io/blog/feed/')
articles = feed.items.map { |o| Article.new(o) }.select { |a| a.category_names.include?("How To") }
これはマークアップの少ないメールになるので、テンプレートにはERBを使用します。以下に示すように、テンプレートとレンダリングコードをDigestViewというクラスにまとめました。このような小さな単一目的のテンプレートの場合、それを別のファイルに分割するのはやり過ぎのように見えました。
最終出力はSTDOUTに出力されます。これにより、出力をOSX pbcopyにパイプできます。 コマンドを実行し、出力をクリップボードにコピーして、メールシステムに貼り付けます。
require 'rss'
require 'delegate'
require 'erb'
class Article < SimpleDelegator
def category_names
categories.map &:content
end
end
class DigestView
attr_accessor :articles
def initialize(articles)
@articles = articles
end
def render
ERB.new(template, 0, '>').result(binding)
end
def template
%{<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "https://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="https://www.w3.org/1999/xhtml">
<head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /></head>
<body>
<h1>Headline: Replace me</h1>
<p>Intro paragraph: Replace me.</p>
<ul>
<% for article in @articles %>
<li>
<a href="<%= article.link %>">
</li>
<% end %>
</ul>
</body>
</html>}
end
end
feed = RSS::Parser.parse('https://www.honeybadger.io/blog/feed/')
articles = feed.items.map { |o| Article.new(o) }.select { |a| a.category_names.include?("How To") }
printf DigestView.new(articles).render
出力は次のようになります:
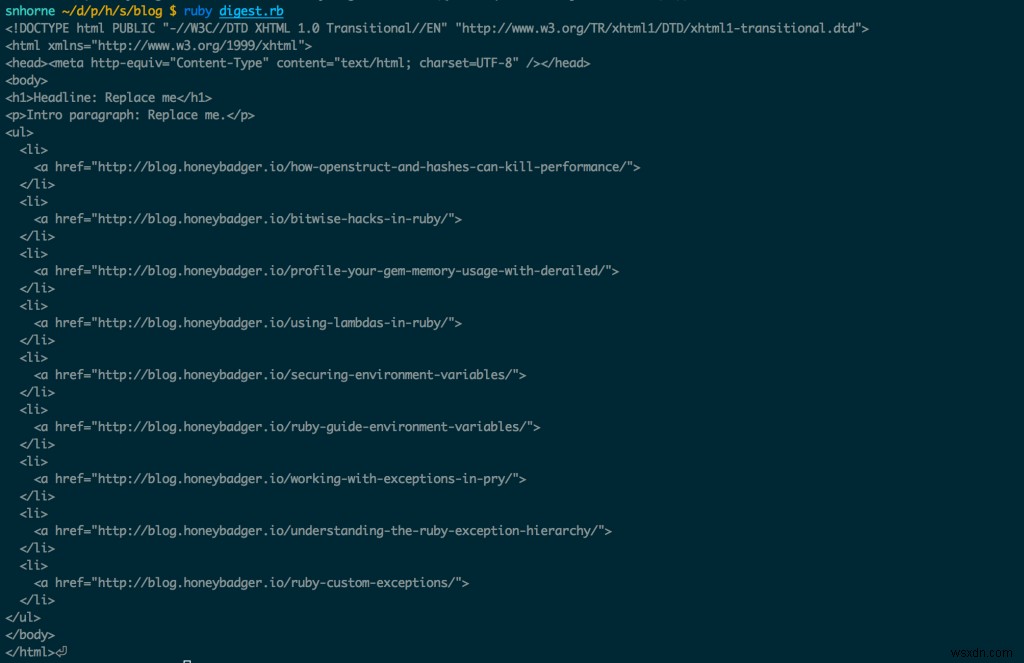 ブログダイジェストジェネレーターの出力。
ブログダイジェストジェネレーターの出力。
これを本番環境に移行する前に、もう少し行う必要があります。しかし、これらは主にHoneybadgerに固有のカスタマイズであり、それ以外の場合はあまり役に立ちません。これがその日の残りの私のストライキリストです:
-
テンプレートをきれいにして、メールプロバイダーでテストしてください
-
リンクにGoogleAnalyticsのトラッキングパラメータを追加する
-
テンプレートに投稿の説明を追加する
-
TCmallocを使用したRubyのメモリ割り当てのプロファイリング
Rubyではメモリ割り当てはどのように機能しますか? Rubyはページと呼ばれるチャンクでメモリを取得し、新しいオブジェクトはここに保存されます。 次に… これらのページがいっぱいになると、より多くのメモリが必要になります。 Rubyは、mallocを使用してオペレーティングシステムからより多くのメモリを要求します 機能。 このmalloc 関数はオペレーティングシステム自体の一部ですが、使用できる代替の実装があります。 それらの実装の1つは、Googleのtcmallocです。 TCmallocはGoogleパフォーマンスツールスイートの一部です。 これらのツールを使用し
-
Rubyでパーサーを構築する方法
構文解析は、一連の文字列を理解し、それらを理解できるものに変換する技術です。正規表現を使用することもできますが、必ずしもその仕事に適しているとは限りません。 たとえば、HTMLを正規表現で解析することはおそらく良い考えではないことは一般的な知識です。 Rubyには、この作業を実行できるnokogiriがありますが、独自のパーサーを作成することで多くのことを学ぶことができます。始めましょう! Rubyでの解析 パーサーの中核はStringScannerです クラス。 このクラスは、文字列のコピーと位置ポインタを保持します。ポインタを使用すると、特定のトークンを検索するために文字列をトラバ