FilebeatおよびElasticsearchIngestPipelinesを使用したcsvファイルの解析

Elasticsearch 5の最も優れた新機能の1つは、ElasticsearchクラスターにLogstashスタイルの処理を追加する取り込みノードです。これにより、別のサービスやインフラストラクチャを必要とせずに、インデックスを作成する前にデータを変換できます。しばらく前に、Logstashを使用してcsvファイルを解析する方法について簡単なブログを投稿したので、比較のために、その取り込みパイプラインバージョンを提供したいと思います。
ここで紹介するのは、Filebeatを使用してデータを取り込みパイプラインに送信し、インデックスを作成し、Kibanaで視覚化する例です。
データ
無料のデータを提供する優れたソースはたくさんありますが、ObjectRocketのほとんどはテキサス州オースティンにいるため、data.austintexas.govのデータを使用します。レストラン検査データセットは、実際の例を示すのに十分な関連情報を備えた適切なサイズのデータセットです。
以下は、データの構造を理解するための、このデータセットの数行です。
Restaurant Name,Zip Code,Inspection Date,Score,Address,Facility ID,Process Description
Westminster Manor,78731,07/21/2015,96,"4100 JACKSON AVE
AUSTIN, TX 78731
(30.314499, -97.755166)",2800365,Routine Inspection
Wieland Elementary,78660,10/02/2014,100,"900 TUDOR HOUSE RD
AUSTIN, TX 78660
(30.422862, -97.640183)",10051637,Routine Inspection
DOH…これは、エントリケースごとに1行の使い勝手が良いとは言えませんが、問題ありません。これから説明するように、Filebeatには、複数行のエントリを処理し、データに埋め込まれた改行を回避する機能が組み込まれています。
編集者注:「ヒッチ」が少ない簡単な例を計画していましたが、最終的には、ElasticStackがこれらのシナリオを回避するために提供するツールのいくつかを見るのは面白いかもしれないと思いました。
Filebeatのセットアップ
最初のステップは、FilebeatがElasticsearchクラスターへのデータの送信を開始できるようにすることです。 Filebeatをダウンロードして(ESクラスターと同じバージョンを使用してみてください)、解凍したら、付属のfilebeat.yml構成ファイルを使用してセットアップするのは非常に簡単です。このシナリオでは、これが私が使用している構成です。
filebeat.prospectors:
- input_type: log
paths:
- /Path/To/logs/*.csv
# Ignore the first line with column headings
exclude_lines: ["^Restaurant Name,"]
# Identifies the last two columns as the end of an entry and then prepends the previous lines to it
multiline.pattern: ',\d+,[^\",]+$'
multiline.negate: true
multiline.match: before
#================================ Outputs =====================================
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["https://dfw-xxxxx-0.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-1.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-2.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-3.es.objectrocket.com:xxxxx"]
pipeline: "inspectioncsvs"
# Optional protocol and basic auth credentials.
username: "esuser"
password: "supersecretpassword"
ここではすべてが非常に簡単です。入力ファイルを取得する場所と方法を指定するセクションと、データを送信する場所を指定するセクションがあります。具体的に説明するのは、マルチラインビットとElasticsearch構成ピースだけです。
このデータセットのフォーマットはそれほど厳密ではなく、二重引用符の使用に一貫性がなく、改行が散在しているため、数値IDとそれに続く検査タイプで構成されるエントリの終わりを探すのが最善のオプションでした。多くのバリエーションや二重引用符/改行なし。そこから、Filebeatは一致しない行をキューに入れ、パターンに一致する最後の行の前に追加します。データがよりクリーンで、エントリ形式ごとに単純な行に固執している場合は、複数行の設定をほとんど無視できます。
Elasticsearchの出力セクションを見ると、これは標準のElasticsearch設定であり、pipeline:ディレクティブで使用するパイプラインの名前が少し追加されています。 ObjectRocketサービスを使用している場合は、UIの[接続]タブから出力スニペットを取得します。このスニペットには、適切なすべてのホストが事前に入力されており、パイプライン行を追加してユーザーとパスワードを入力するだけです。 。また、まだ追加していない場合は、システムのIPがクラスターのACLに追加されていることを確認してください。
取り込みパイプラインの作成
入力データとFilebeatの準備ができたので、取り込みパイプラインを作成して微調整できます。パイプラインが実行する必要のある主なタスクは次のとおりです。
- csvコンテンツを正しいフィールドに分割します
- 検査スコアを整数に変換します
-
@timestampを設定します フィールド - 他のデータフォーマットをクリーンアップする
これらすべてを実行できるパイプラインは次のとおりです。
PUT _ingest/pipeline/inspectioncsvs
{
"description" : "Convert Restaurant inspections csv data to indexed data",
"processors" : [
{
"grok": {
"field": "message",
"patterns": ["%{REST_NAME:RestaurantName},%{REST_ZIP:ZipCode},%{MONTHNUM2:InspectionMonth}/%{MONTHDAY:InspectionDay}/%{YEAR:InspectionYear},%{NUMBER:Score},\"%{DATA:StreetAddress}\n%{DATA:City},?\\s+%{WORD:State}\\s*%{NUMBER:ZipCode2}\\s*\n\\(?%{DATA:Location}\\)?\",%{NUMBER:FacilityID},%{DATA:InspectionType}$"],
"pattern_definitions": {
"REST_NAME": "%{DATA}|%{QUOTEDSTRING}",
"REST_ZIP": "%{QUOTEDSTRING}|%{NUMBER}"
}
}
},
{
"grok": {
"field": "ZipCode",
"patterns": [".*%{ZIP:ZipCode}\"?$"],
"pattern_definitions": {
"ZIP": "\\d{5}"
}
}
},
{
"convert": {
"field" : "Score",
"type": "integer"
}
},
{
"set": {
"field" : "@timestamp",
"value" : "//"
}
},
{
"date" : {
"field" : "@timestamp",
"formats" : ["yyyy/MM/dd"]
}
}
],
"on_failure" : [
{
"set" : {
"field" : "error",
"value" : " - Error processing message - "
}
}
]
}
Logstashとは異なり、取り込みパイプラインには(この記事の執筆時点では)csvプロセッサ/プラグインがないため、csvを自分で変換する必要があります。各行には数列しかないため、grokプロセッサを使用して手間のかかる作業を行いました。より多くの列を持つデータの場合、grokプロセッサはかなり厄介になる可能性があるため、別のオプションは、分割プロセッサといくつかの簡単なスクリプトを使用して、より反復的な方法で行を処理することです。また、このデータセットに郵便番号が入力された2つの異なる方法を処理するためにある2番目のgrokプロセッサに気付くかもしれません。
デバッグの目的で、すべてのエラーをキャッチし、失敗したプロセッサのタイプとパイプラインを壊したメッセージを出力する一般的なon_failureセクションを含めました。これにより、デバッグが容易になります。エラーが設定されているドキュメントのインデックスをクエリするだけで、simulateAPIを使用してデバッグできます。詳細は今すぐ…
パイプラインのテスト
取り込みパイプラインが構成されたので、simulateAPIを使用してテストして実行しましょう。まず、サンプルドキュメントが必要です。これはいくつかの方法で行うことができます。パイプライン設定なしでFilebeatを実行してから、Elasticsearchから未処理のドキュメントを取得するか、Elasticsearchセクションをコメントアウトしてymlファイルに以下を追加することにより、コンソール出力を有効にしてFilebeatを実行できます。
output.console:
pretty: true
これが私の環境から取得したサンプルドキュメントです:
POST _ingest/pipeline/inspectioncsvs/_simulate
{
"docs" : [
{
"_index": "inspections",
"_type": "log",
"_id": "AVpsUYR_du9kwoEnKsSA",
"_score": 1,
"_source": {
"@timestamp": "2017-03-31T18:22:25.981Z",
"beat": {
"hostname": "systemx",
"name": "RestReviews",
"version": "5.1.1"
},
"input_type": "log",
"message": "Wieland Elementary,78660,10/02/2014,100,\"900 TUDOR HOUSE RD\nAUSTIN, TX 78660\n(30.422862, -97.640183)\",10051637,Routine Inspection",
"offset": 2109798,
"source": "/Path/to/my/logs/Restaurant_Inspection_Scores.csv",
"tags": [
"debug",
"reviews"
],
"type": "log"
}
}
]
}
そして、応答(設定しようとしたフィールドに切り詰めました):
{
"docs": [
{
"doc": {
"_id": "AVpsUYR_du9kwoEnKsSA",
"_type": "log",
"_index": "inspections",
"_source": {
"InspectionType": "Routine Inspection",
"ZipCode": "78660",
"InspectionMonth": "10",
"City": "AUSTIN",
"message": "Wieland Elementary,78660,10/02/2014,100,\"900 TUDOR HOUSE RD\nAUSTIN, TX 78660\n(30.422862, -97.640183)\",10051637,Routine Inspection",
"RestaurantName": "Wieland Elementary",
"FacilityID": "10051637",
"Score": 100,
"StreetAddress": "900 TUDOR HOUSE RD",
"State": "TX",
"InspectionDay": "02",
"InspectionYear": "2014",
"ZipCode2": "78660",
"Location": "30.422862, -97.640183"
},
"_ingest": {
"timestamp": "2017-03-31T20:36:59.574+0000"
}
}
}
]
}
パイプラインは間違いなく成功しましたが、最も重要なことは、すべてのデータが適切な場所にあるように見えることです。
ファイルビートの実行
Filebeatを実行する前に、最後にもう1つ行います。取り込みパイプラインに慣れたい場合、この部分は完全にオプションですが、grokプロセッサでジオポイントとして設定した場所フィールドを使用する場合は、filebeatにマッピングを追加する必要があります。 template.jsonファイル、プロパティセクションに以下を追加します:
"Location": {
"type": "geo_point"
},
これで邪魔にならないので、。/ filebeat -e -c filebeat.yml -d“elasticsearch”を実行してFilebeatを起動できます。
データの使用
GET /filebeat-*/_count
{}
{
"count": 25081,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
}
}
それは良い兆候です!エラーが発生したかどうかを確認しましょう:
GET /filebeat-*/_search
{
"query": {
"exists" : { "field" : "error" }
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
もう一つの良い兆候!
これで、Kibanaでデータを視覚化して表示する準備が整いました。 Kibanaダッシュボードの作成については別の機会に説明することもできますが、日付、レストラン名、スコア、場所がわかっているので、クールな視覚化を自由に作成できます。
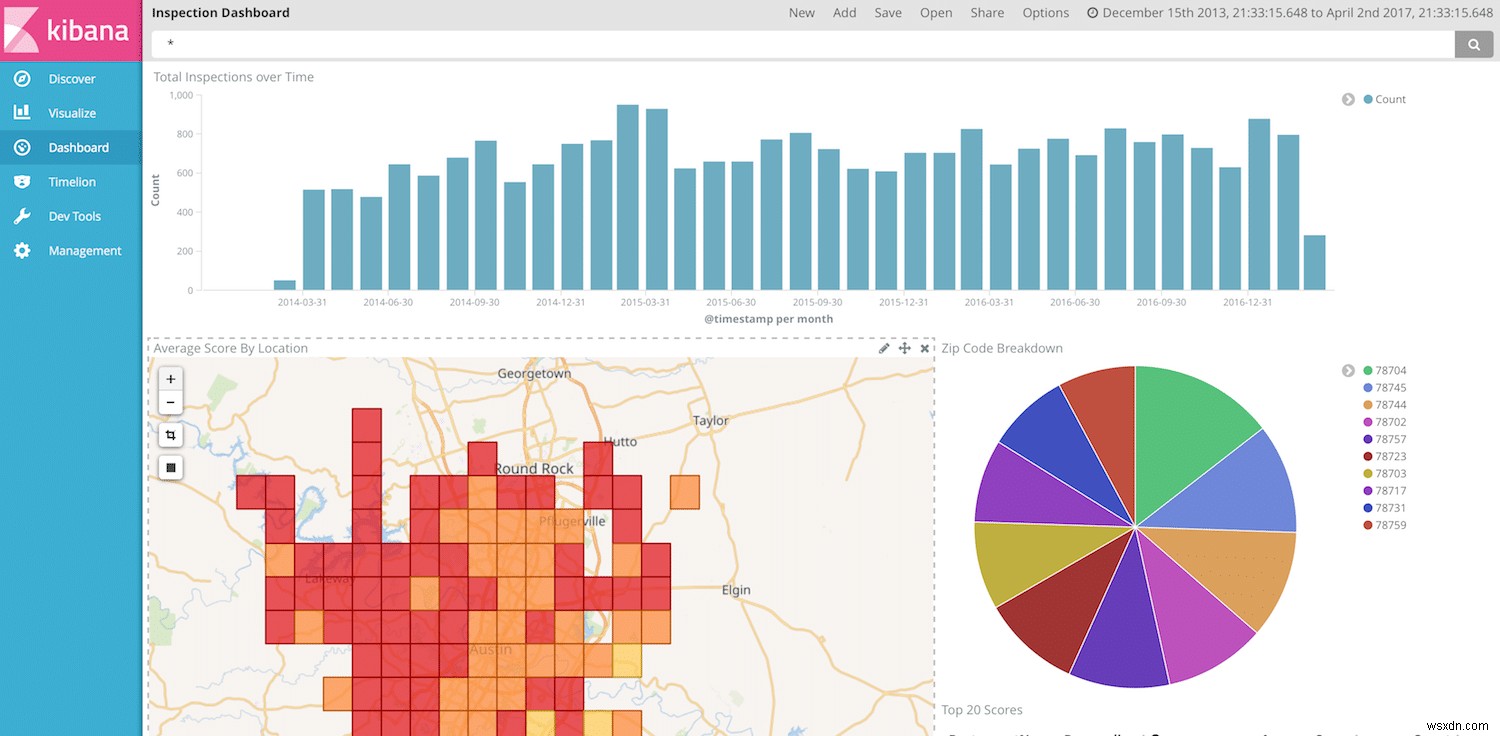
最終メモ
繰り返しになりますが、取り込みパイプラインは非常に強力であり、変換を非常に簡単に処理できます。パイプラインのどこかにLogstashを必要とせずに、すべての処理をElasticsearchに移動し、ホストで軽量のBeatsのみを使用できます。ただし、Logstashと比較すると、取り込みノードにはまだいくつかのギャップがあります。たとえば、取り込みパイプラインで使用できるプロセッサの数はまだ制限されているため、CSVの解析などの単純なタスクはLogstashの場合ほど簡単ではありません。 Elasticsearchチームは定期的に新しいプロセッサを展開しているようです。そのため、違いのリストがどんどん小さくなっていくことを期待しています。
-
Windows 10 でファイル履歴を使用してデータを保存および復元する方法
ハードドライブの故障、停電、その他の問題などの予期しない状況から重要なファイルやドキュメントを保存することがいかに重要であるかを理解しています.できれば、データを定期的にバックアップする必要があります。ただし、Windows OS について言えば、すべての重要なファイルを USB ドライブ (少量のデータの場合) やハード ドライブ (大量のデータの場合) などの外部ストレージ デバイスに定期的にコピーできます。気楽な人は、毎日 (または好みに応じて) クラウド ストレージにデータを自動的にバックアップできるソフトウェアを購入できます。一方、「ファイル履歴」と呼ばれる Windows 10 の
-
Disk Analyzer Pro でデータ ストレージとスペース消費を管理する
小さなハードディスクに全世界を保存できるようになり、すべてがデジタル化されると、人々は自分のファイルやフォルダーを見失い始めました。無数の本、ビデオ、写真、音楽ファイルがあると、小さなハードディスクはすぐに過負荷になり、写真を 1 枚も保存する余地がなくなります。私たちのほとんどはフラッシュ ドライブを購入しましたが、他の人は 2 台目の外付けハード ドライブを購入したり、すべてをクラウド ストレージに転送したりしました。ただし、新しいストレージ ソースを見つけることは長期的な解決策ではありません。なぜなら、私たちのほとんどは、ハードディスクやペン ドライブに何が含まれているかを知らないからで