マスター IPv4:プロトコルの基礎とパケット処理に関する開発者ガイド

インターネット プロトコル バージョン 4 (IPv4) は、インターネットおよびその他のパケット交換ネットワークにおける標準ベースのインターネットワーキング方式のコア プロトコルの 1 つです。 IPv4 は、依然として最も広く導入されているインターネット プロトコルです。 Google の IPv6 統計によると、2025 年 4 月 24 日の Google サービスへのトラフィックの 44.29% が IPv6 経由であり、55.71% が IPv4 経由であることを意味します。
このハンドブックでは、IP アドレスの理解からパケット ヘッダーやフラグメンテーションの調査まで、IPv4 のあらゆる側面を説明します。次のことを学びます:
-
IP アドレスの仕組みとそのさまざまな形式
-
固定長から CIDR までのネットワーク アドレッシング スキーム
-
特別な IPv4 アドレスとその用途
-
IPv4 ヘッダーの各フィールドの構造と目的
-
IPv4 が異なるネットワーク間でのパケットの断片化をどのように処理するか
ネットワーク エンジニア、ソフトウェア開発者、IT プロフェッショナルのいずれであっても、最新のコンピュータ ネットワークを扱うには IPv4 を理解することが重要です。
説明する内容:
<オル>背景
IP アドレスについて
ネットワーク ID とホスト ID
ネットワーク部分とホスト部分を決定する方法
-
固定長アプローチ
-
ここでのデメリットは何でしょうか? 🤔
クラスフルなアドレッシング
-
IP アドレスの割り当て
-
ここでのデメリットは何でしょうか? 🤔
CIDR:クラスレスドメイン間ルーティング
- 実際の例
サブネットマスク
中間概要 – IPv4 アドレス
自分自身をテストしてください
-
プレフィックス表記とサブネット マスク間の変換
-
サブネット マスクを逆方向に使用する
-
バイトアラインされていないプレフィックス
-
ネットワーク メンバーシップの決定
特別な IPv4 アドレス
-
「このホスト」アドレス:0.0.0.0
-
「このネットワーク」アドレス
-
ブロードキャストアドレス
-
ループバック アドレス:127.0.0.0/8
-
特別な IPv4 アドレスの概要
IPv4 ヘッダー
-
ヘッダー構造
-
IPv4 ヘッダー – 中間概要
IPv4 フラグメンテーション
-
断片化が必要な理由
-
IP におけるフラグメンテーションの仕組み
-
識別フィールド
-
フラグメント オフセット
-
さらにフラグメントを作成し、フラグをフラグメント化しないでください
-
断片化の例
-
IPv4 フラグメンテーション – 概要
概要 – IPv4
-
アドレス指定とネットワーク構造
-
IPv4 ヘッダー構造
-
断片化
-
最後の言葉
著者について
追加の参考資料
始める前の簡単なメモ
<オル>コンピュータ ネットワークに関するその他のコンテンツは、私の YouTube チャンネル「コンピュータ ネットワーク プレイリスト」
で見つけることができます。私はコンピューター ネットワークに関する本を執筆中です。初期バージョンを読んでフィードバックを提供することに興味がありますか?メールを送ってください:gtting.things@gmail.com
背景
IP は「インターネット プロトコル」の略なので、IPv4 はインターネット プロトコル バージョン 4 です。IPv4 は、1981 年 9 月に発行された IETF の RFC 791 で説明され、1982 年にインターネットの初期セグメントを形成した初期の衛星ネットワークである SATNET (Atlantic Packet Satellite Network) 上で運用用に初めて展開されました。
IPv4 はコネクションレスであり、ベストエフォート配信モデルで動作します。これは、配信、パケットの正しい順序、またはデータの有効性を保証しないことを意味します。高速かつ柔軟になるように設計されています。
IP アドレスについて
IP アドレスは、今日のほとんどのインターネット接続を強化する階層的な論理アドレスです。それぞれは 4 で構成されます。 バイト、または 32 ビット。これらは通常、次のようにドット付き 10 進表記で書かれます。

自分でテストしてください – 次のアドレスは有効な IP アドレスを表していますか?

いいえ。ドットは異なるバイトを区切るため、各値は 0 の間にある必要があります。 および 255 。番号 392 なので 255 より大きいです 、単一バイトで表すことはできません。

ネットワーク ID とホスト ID
IP アドレスには、ネットワーク識別子という 2 つの部分があります。 ネットワーク内のすべてのホストに属する (またはネットワーク ID) とホスト識別子 このネットワーク内の特定のホストを識別する (またはホスト ID)。
ネットワーク識別子はネットワーク内のすべてのホストで同じであり、「プレフィックス」とも呼ばれます。たとえば、ネットワーク識別子が 201.22.3 であると考えてみましょう。 。これがネットワーク プレフィックスである場合、アドレスは次のとおりです。
201.22.3.15
201.22.3.91
同じプレフィックスを共有しているため、同じネットワークの一部です。最初のアドレスはホスト番号 15 に属します このネットワーク内にあり、2 番目はホスト番号 20 に属します。 .
このアドレスには別のプレフィックスまたは別のネットワーク識別子が付いているため、別のネットワークに属しています。
201.22.14.50
上の例では、ネットワーク識別子は 3 バイト、つまり 24 ビットで構成され、ホスト識別子は 1 バイト、つまり 8 ビットで構成されています。

ネットワーク部分とホスト部分を決定する方法
どのビットがネットワーク ID の一部であり、どのビットがホスト ID の一部であるかをどのようにして知ることができるのでしょうか?この課題に対処するために、時間の経過とともにいくつかのアプローチが進化してきました。
固定長アプローチ
次の解決策を考えてみましょう。すべての IP アドレスについて、最初の最上位バイトはネットワーク ID を表し、残りの 3 つの最下位バイトはホスト ID を表します。このようにすると、IP アドレスを読み取るのが非常に簡単になります。たとえば、このアドレスの場合:
20.12.1.92
ネットワーク 20 について説明していることがわかります。 、ホスト 12.1.92 そのネットワークの中で。 20 で始まらない IP アドレス 、22.1.2.3 など 、別のネットワークに存在し、20 で始まる IP アドレスになります。 、20.1.2.3 など 、同じネットワーク内にあります。

この場合のデメリットは何ですか? 🤔
ネットワーク ID を表すのに 1 バイト (8 ビット) だけを使用すると、2^8、つまり 127 のみになります。 、異なるネットワーク。もちろん、現実の世界よりもはるかに多くのネットワークが存在します。インターネットの初期であっても、大学と大企業はそれぞれ独自のネットワーク ID を必要としていました。
一般に、ネットワーク ID に固定長を使用し、ホスト ID に固定長を使用するのは十分な柔軟性がありません。最上位 2 バイトがネットワーク ID を表し、最下位 2 バイトがホスト ID を表すと決定した場合は、最大 2^16、つまり 65,536 を表すことができます。 ネットワーク、これも十分ではありません。さらに、大企業などの一部のネットワークでは、65,536 を超えるネットワークが必要になる場合があります。 ホスト ID。
クラスフル アドレッシング
解決策は、ある程度の柔軟性を提供することにあります。 「クラスフル アドレッシング」と呼ばれる別のアプローチを考えてみましょう。このアプローチでは、ネットワーク ID 専用のビット数がアドレスごとに変わり、アドレスの最初の最上位バイトを見ることでネットワーク ID を知ることができます。
-
1の間の数字で始まる任意のアドレス と127これは、ネットワーク ID が 1 バイトで構成され、残りの 3 バイトがホスト ID であることを意味します。 -
128の間の数字で始まる任意のアドレス と191は「クラス B」に属します。これは、そのネットワーク ID の長さが 2 バイトであり、そのホスト ID も 2 バイトの長さであることを意味します。 -
192の間の数字で始まる任意のアドレス および223「クラス C」に属しているため、3 バイトのネットワーク ID と 1 バイトのホスト ID があります。
このアプローチの完全な表現は、以下の表で確認できます。
ClassFirst Byte Rangeネットワーク ID サイズホスト ID サイズ A1 - 127 1バイト3バイトB128 - 191 2 バイト2 バイトC192 - 223 3 バイト 1 バイト D224 - 239 (マルチキャスト)E240 - 255 (予約済み)

たとえば、このアドレスはどのクラスに属しますか?
(1) 130.12.204.5
130で始まるので 、128 の間です。 と 191 、「クラスB」に属します。これは、ネットワーク ID が 130.12 であることを意味します。 、そのホスト ID は 204.5 です。 。これを「アドレス番号 1」としてマークしましょう。
このアドレスと次のアドレス (2) は同じネットワークに属しますか?
(2) 130.90.2.40
いいえ、異なるネットワーク識別子を持っているため、同じネットワーク内にありません。
次のアドレスはどのクラスに属しますか?
(3) 200.1.1.9
最初のバイトの値 200 はクラス C に属します。 、192 の間にあります と 223 。これは、ネットワーク識別子が 200.1.1 であることを意味します。 、このプレフィックスで始まるアドレスはすべて同じネットワーク内に存在します。この特定のアドレスはホスト 9 を表します。 このネットワーク内で。
画像を完成させるには、224 の間の値で始まるアドレスを指定します。 と 239 「クラス D」、つまりマルチキャスト アドレス、つまり複数のデバイスに属するアドレスに属します。 240 の間の値で始まるアドレス および 255 将来の使用のために予約されていました。 0 で始まるアドレス 特別なアドレスです。
IP アドレスの割り当て
初期のインターネットでは、IPv4 アドレスは Internet Assigned Numbers Authority (IANA) によって組織に割り当てられていました。インターネットが成長するにつれて、この責任は、さまざまな地理的地域へのアドレス割り当てを処理する 5 つの地域インターネット レジストリ (RIR) に分散されました。大規模な組織は、ニーズに基づいてアドレス ブロックを受け取り、アドレス クラスによってこれらのブロックのサイズが決まります。
この場合のデメリットは何ですか? 🤔
クラスフル アドレス指定では、固定長のアプローチに比べて柔軟性が高くなりますが、このアプローチでも柔軟性が十分ではありません。
次のシナリオを考えてみましょう。創設者が 2 人だけの小規模な新興企業には、ネットワーク ID が必要です。どのクラスが必要でしょうか?
クラス A またはクラス B を取得するのは過剰になるため、クラス C を取得する可能性があります – 256 を許可します アドレス。これは現在必要な量を超えていますが、ある程度の拡張は可能です。スタートアップが 256 を超えるとどうなるか 従業員 (およびデバイス)?
この時点で、65,536 以上のクラス B アドレスを取得する必要があります。 必要なのは 256 を少し超えるアドレスだけである場合 アドレス。これは、60,000 以上を無駄にすることを意味します アドレス。
インターネットが急速に成長していた 1990 年代初頭に、これは現実的な問題になりました。より多くの IP アドレスの必要性が明らかになり、IPv4 アドレス空間の枯渇が差し迫っています。 60,000 の場合 アドレスが無駄になることはもはや容認できません。
CIDR:クラスレスドメイン間ルーティング
このアドレス不足に対処する手段の 1 つは、1993 年にクラスフル アドレス指定を放棄し、CIDR (クラスレス ドメイン間ルーティング) と呼ばれる別のアプローチに切り替えることでした。このアプローチは現在でも使用されています。
CIDR を使用すると、ネットワーク ID とホスト ID を選択する際に柔軟性が得られます。これにより、ネットワーク管理者は、クラス A、B、または C に限定されるのではなく、正確に適切なサイズのサブネットを作成できるようになります。
簡単な例から始めましょう。 CIDR 表記では、ネットワーク部分に使用されるビット数を示すサフィックスを追加します。
(4) 200.8.3.1/16
このスラッシュ表記は、ネットワーク ID を表すビット数を指定します。上記の例 (4) では、最初の 16 ビット (または 2 バイト)がネットワーク ID に使用されます。したがって、この場合、200.8 はネットワーク識別子、3.1 ホスト識別子です。 200.8 という事実 ネットワーク ID は、200.8.0.0 からのすべてのアドレスを意味します 200.8.255.255 まで はこのネットワーク内にあります。

次の追加アドレスを検討してください。
(5) 200.2.13.5
(6) 200.8.21.6
このアドレスのプレフィックスが 16 であるとします。 ビット、または 2 バイト、これらのアドレスのうち、例 (4) (200.8.3.1/16) と同じネットワークに属するものはどれですか? )?
最初のアドレス (5) (200.2.13.5) ) は、最初の 16 であるため、このネットワークに属していません。 ビット – 200.2 、最初の 16 とは異なります。 アドレス例のビット。
2 番目のアドレス (6) (200.8.21.6) ) は、例のアドレスと同じネットワークに属しています。

実際の例
実際には、ISP は 104.16.0.0/12 のような大きなブロックを受け取る可能性があります。 RIRから。これにより、104.16.0.0 からのすべてのアドレスを制御できるようになります。 104.31.255.255 へ 。 ISP は、中小企業に /24 を与えるなど、より小さなサブネットを顧客に割り当てることができます。 256 のサブネット 住所、または大企業の場合は /20 4,096 のサブネット アドレス。
サブネットマスク
ネットワーク プレフィックスを表現するもう 1 つの方法は、次のようにサブネット マスクを使用することです。
255.255.0.0
バイナリに変換すると、255 10 進数で 8 1 に相当します s はバイナリです。つまり、すべてのビットがオンになります。したがって、このマスクをバイナリに変換すると、次のようになります。
11111111 11111111 00000000 00000000
つまり、16 ビットがオンになっている場合、ネットワーク プレフィックス 16 を意味します。 ビット。どちらの規則 (CIDR 表記とサブネット マスク) も非常に頻繁に使用されます。

CIDR を使用すると、異なるネットワーク プレフィックスまたはサブネット マスクを指定して、アドレスを異なるネットワークに存在させることができます。異なるプレフィックスを持つ同じアドレスの例を検討する場合は、8 のようにします。 ビット – 両方の追加アドレスは最初の 8 を共有するため、同じネットワークに属します。 ビット – 200 .
8 というネットワーク プレフィックスをどのように表示しますか? ビットをサブネットマスクとして使用しますか?最初の 8 が必要です ビットがオンになるため、255 を意味します 10 進数で、残りのビットはオフになり、次のサブネット マスクになります。
255.0.0.0

24 のネットワーク プレフィックスを使用するとどうなるか ビット?まず、それをサブネットマスクとしてどのように表現しますか? 24 が必要です オンになるビット数なので、オンになる 8 ビットの 3 倍となり、次のようになります。
255.255.255.0

ここで、追加のアドレスはいずれも、ネットワーク ID 200.8.3 を共有していないため、例のアドレスと同じネットワーク内に存在しません。 .

ネットワーク プレフィックスはフルバイトを表す必要はないことに注意してください。たとえば、ネットワーク プレフィックス 12 を使用できます。 ビット、または 11 ビット、または 22 ビット。プレフィックス長が 8 の倍数ではない場合 、サブネット マスクは 0 以外の値になります。 または 255
これにより、スタートアップ企業に関する問題が解決されます。スタートアップに 300 がある場合 従業員は 23 を取得する必要があります。 -bits ネットワーク ID、9 のまま ネットワーク内のホストのビット。これは 2^9、つまり 512 を意味します。 アドレスはこれで十分です。
中間概要 – IPv4 アドレス
このセクションでは、IPv4 アドレスについて学習しました。 IP アドレスは、4 で構成される階層的な論理アドレスです。 バイト。 IP アドレスには、ネットワーク内のすべてのホストに属するネットワーク識別子と、ネットワーク内の特定のホストを識別するホスト識別子の 2 つの部分があります。
ネットワーク識別子とホスト識別子を決定するためのさまざまなオプションを検討しました。
<オル>固定長のアプローチ – 厳格すぎて制限がある
クラスフルなアドレス指定アプローチ – 優れていますが、それでも無駄です
CIDR (クラスレスドメイン間ルーティング) – 柔軟かつ効率的
CIDR は柔軟性が大幅に向上し、IPv4 アドレス不足という重大な問題の解決に役立ちます。ただし、CIDR は IPv4 アドレス不足への対処の一部にすぎず、NAT (ネットワーク アドレス変換)、そして最終的には IPv6 などの他のソリューションが使用されます。
次のセクションでは、特別な IPv4 アドレスを調べてから、IPv4 パケットのヘッダーを調べます。
自分自身をテストしてください
ここで、学んだ概念を実践して、それらに慣れるようにしてください。
答えを確認する前に、少し時間を取って次の質問に答えてみてください。
プレフィックス表記とサブネット マスク間の変換
16 というネットワーク プレフィックスをどのように表現しますか? ビット、次のように記述されます /16 、サブネットマスクとして?
16 が必要です オンになっているビット。 8 の場合 ビットがオンの場合、255 が返されます 10 進数で表すと次のようになります。
255.255.0.0

このネットワーク プレフィックスを考慮すると、これらのアドレスは同じネットワークに属しますか?

はい、同じ最も重要な 16 を共有しているため、そうです。 ビット、または 2 バイト

このアドレスは前のアドレスと同じネットワークに属していますか?

はい、そうです。繰り返しますが、同じ 2 つの最上位バイトを共有します。

これはどうでしょうか?前のアドレスと同じネットワークに属していますか?
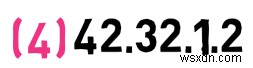
いいえ、最初の 2 バイトは 42.31 ではないためです。 – これは別のネットワークです。したがって、このアドレスはホスト 1.2 を表します。 、ネットワーク 42.32 内 .

サブネット マスクを逆方向に使用する
逆に試してみましょう。次のサブネット マスクがあります:
255.255.255.0
ネットワーク プレフィックスを使用してそれをどのように表現しますか?
255 が 3 回発生しました 、これは 8 の 3 倍を意味します オンになっているビットがあるため、全体では 24 になります。 オンになっているビット。したがって、/24 と書くこともできます。 。これは 3 を意味します バイト。

このサブネット マスクを考慮すると、上記のアドレス (1) と (3) は同じネットワークに属しますか?

どちらも同じ最上位 3 バイト (ネットワーク 42.31.93) を持っているため、これらは可能です。 .

アドレス (1) と (2) はどうでしょうか?

このネットワーク プレフィックスを考慮すると、これらは同じネットワークに属していません。最初のアドレスはネットワーク 42.31.93 に属します 、2 番目のアドレスはネットワーク 42.31.1 に属します。 .

バイトアライメントされていないプレフィックス
ネットワーク プレフィックスは 8 に合わせる必要はありません ビット、またはフルバイト。ネットワーク プレフィックスが 14 であるとします。 ビット。これをサブネット マスクに変換するにはどうすればよいでしょうか?
最初のバイトは明らかです。8 です。 ビットがオンなので、最初のバイトは 255 になります。 。次はどうでしょうか?
バイナリでは、さらに 6 つの 1 が必要で、その後 2 つの 0 が必要です。したがって、バイナリでは次のように書きます。
11111100
10 進数に変換すると、この 2 進数は 252 を表します。 。したがって、サブネット マスクは次のようになります。
255.252.0.0
この変換を行う別の方法:バイナリの 8 つの 1 は 255 を表すことがわかります。 10進数で。 11 ということもご存知でしょう。 バイナリでは 3 です。 したがって、単純に 3 を減算することができます。 255 から 252 を取得します .

次に、その逆を試してください。次のサブネット マスクがあります:
255.255.224.0
ネットワーク プレフィックスは何ビットで表されますか?
最初の 2 バイトは明らかです。16 です。 ビット。 3 バイト目をバイナリに変換:224 10 進数では 11100000 です。 バイナリで。これは、さらに 3 つの 1 があることを意味するため、上記のサブネット マスクを /19 のプレフィックスとして記述できます。 ビット – 16 2 つの 255 のビット バイト、および 3 224 の追加ビット バイト。

ネットワーク メンバーシップの決定
次のアドレスを考えてみましょう。

それらは同じネットワークの一部ですか? 🤔
それはサブネット マスクによって異なります。
ネットワークプレフィックスが /8 の場合 の場合、同じネットワーク ID を共有するため、それらは同じネットワークの一部になります。

一方、ネットワーク プレフィックスが /16 の場合は、 の場合、それらは異なるネットワーク ID を持つため、同じネットワークに属しません。しかし、間に接頭辞がある場合はどうなるのでしょうか?これらは、プレフィックス /9 の同じネットワーク内に存在しますか? ? /14 ?
この質問にアプローチする方法は、これらのアドレスの 2 番目のバイトをバイナリに変換することです。最初のアドレスの場合、このバイトは 24 です。 、バイナリでは次のようになります。
00011000
2 番目のアドレスの 2 番目のバイトは 23 です。 、バイナリでは次のようになります。
00010111
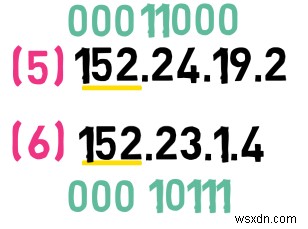
最も重要な 4 が 2 番目のバイト内のビットは同一です。最初の 8 を追加すると、 アドレスのビットを見ると、最上位の 12 がわかります。 これらのアドレスのビットは同じです。
したがって、ネットワーク プレフィックスが /11 である場合、 、これらのアドレスは同じネットワークに属していますか?
はい、そうです。最も重要な 11 ビットは同一です。
/13 はどうでしょうか ?
いいえ、このネットワーク プレフィックスでは、13 と同じネットワーク識別子を共有しません。 番目のビットが異なります。
これを実践すると、サブネット マスクとネットワーク プレフィックスを快適に扱えるようになります。次のセクションでは、特別な IP アドレスについて学習し、IP パケットのヘッダーを調べます。
特別な IPv4 アドレス
IP アドレスとサブネット マスクについては理解できたので、特別な意味を持つ IP アドレスをいくつか見てみましょう。
「このホスト」アドレス:0.0.0.0
アドレス 0.0.0.0 「このホスト」を意味し、次の 2 つのシナリオで使用されます。
まず、マシンが起動し、まだ IP アドレスを持っていないときです。 IP アドレスは、マシンに割り当てる必要がある論理アドレスです。この割り当てが行われる前は、デバイスには IP アドレスがまったくありません。この段階でデバイスが通信する必要がある場合、この特別なアドレス 0.0.0.0 を使用する可能性があります。 .
2 番目は、すべてのネットワーク インターフェイスで受信接続をリッスンする必要があるネットワーク アプリケーションを作成する場合です。たとえば、マシンに 2 つのインターフェイスがある場合、1 つは IP アドレス 1.1.1.1 です。 、もう 1 つはアドレス 2.2.2.2 です – アドレス 0.0.0.0 でリッスンします これは、どのネットワーク インターフェイスが接続を受信するかに関係なく、接続を受け入れることを意味します。
「このネットワーク」アドレス
特別なアドレスの別のクラスは、ゼロで始まるもので、ゼロは「このネットワーク」を意味します。
たとえば、次のアドレスを持つマシンがあるとします。
12.34.55.55
ネットワーク プレフィックス 16 このマシンは、完全なアドレス (12.34.66.66 など) を使用してネットワーク上の別のデバイスにパケットを送信できます。 または、特殊なゼロ表記を使用してパケットを次の宛先に送信します。
0.0.66.66
これは、「ホスト 66.66 にパケットを送信する」ことを意味します。 このネットワーク上で。」もちろん、このアドレスを正しく解釈するには、受信者も関連するネットワーク プレフィックスを知っている必要があります。
ブロードキャスト アドレス
アドレス 255.255.255.255 、すべてのビットは 1 に設定されます。 、ローカル ネットワーク内のすべてのホストのアドレス、つまりブロードキャスト アドレスです。これは、イーサネットのブロードキャスト アドレス (FF:FF:FF:FF:FF:FF) に似ています。 )。どちらの場合も、すべてのビットは 1 に設定されます。 .
ホスト識別子がすべて 1 に設定されている適切なネットワーク識別子を使用すると、ブロードキャスト パケットをリモート ネットワークに送信できます。たとえば、ネットワーク 12.34.0.0/16 について考えてみましょう。 ネットワーク ID 12.35.0.0/16 を持つ別のネットワーク 。マシンが 12.34.55.55 の場合 他のネットワーク内のすべてのデバイスにパケットを送信したい場合は、宛先アドレス 12.35.255.255 を使用できます。 .
これは IP 仕様 (RFC) に従って許可されていますが、実際には、セキュリティ上の脆弱性が生じる可能性があるため、この機能は無効にされることがよくあります。
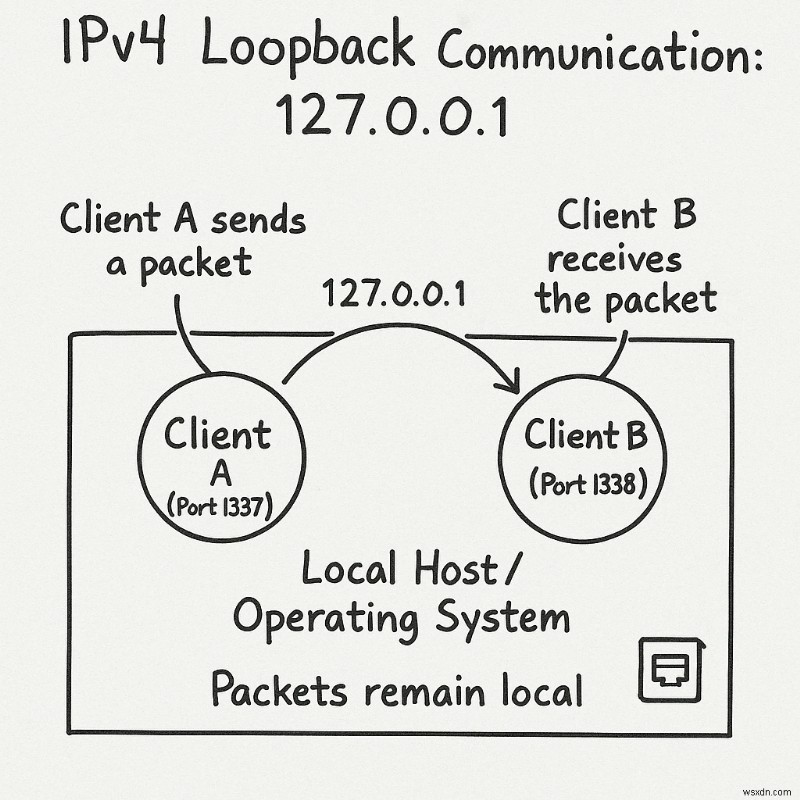
ループバック アドレス:127.0.0.0/8
ネットワーク内のすべてのアドレス 127.0.0.0/8 (つまり、127 で始まるすべてのアドレス ) はループバック アドレスです。これらのアドレスに送信されたパケットは物理ネットワーク上には置かれず、オペレーティング システム内でローカルに処理されます。これは開発とデバッグに非常に役立ちます。
たとえば、単純なチャット プログラムを開発する場合、データを交換する 2 つのクライアントが必要です。 1 つのアプローチは、2 台の異なる物理コンピューターを使用することですが、これは面倒です。1 台のコンピューターでメッセージを書き込み、もう 1 台のコンピューターで受信したかどうかを確認し、次に 2 台目のコンピューターでメッセージを書き込み、最初のコンピューターに戻って受信を検証する必要があります。
はるかに簡単なアプローチは、ループバック アドレスを使用することです。どちらのクライアントも同じマシン上で実行でき、相互に接続できます。同じ物理コンピュータ上で 2 つの異なるクライアント プログラムを実行し、追加のマシンを必要とせずにそれらの間でメッセージを交換できます。
たとえば、アドレス 127.0.0.1 を使用できます。 、1 つのクライアントがポート 1337 でリッスンする もう 1 つはポート 1338 上です 。クライアント A がクライアント B にパケットを送信すると、このパケットはネットワーク カードから離れることはなく、オペレーティング システム内に残ります。クライアント B は、物理ネットワークから受信したかのように、ループバック インターフェイスからパケットを受信します。
デバッグが完了した後、クライアント コードを変更する必要はありません。唯一の違いは、ループバック アドレスではなく実際の IP アドレスを使用して通信することです。
特別な IPv4 アドレスの概要
これまでに学んだ特別な IPv4 アドレスを要約すると、次のようになります。
特別なアドレスの意味0.0.0.0 「このホスト」は起動中、またはすべてのインターフェイスでリッスンするために使用されます。0 で始まるアドレス 「このネットワーク」ローカル ネットワーク上のホストに送信255.255.255.255 ブロードキャストローカル ネットワーク上のすべてのホストに送信ホスト部分がすべて 1 のネットワーク IDダイレクト ブロードキャスト特定のネットワーク上のすべてのホストに送信127.0.0.0/8 ループバック物理ネットワークを使用しないテストとデバッグ 次のセクションでは、IPv4 ヘッダーの構造について学習します。
IP アドレス、サブネット、特別なアドレスを理解したところで、IPv4 ヘッダー構造を詳しく調べてみましょう。

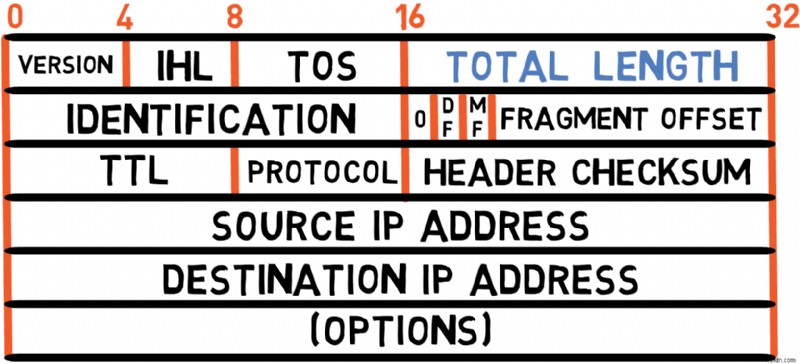
上の図は、RFC 791 で定義されている IPv4 のヘッダーを示しています。各フィールドを調べてみましょう。
バージョン (4 ビット)
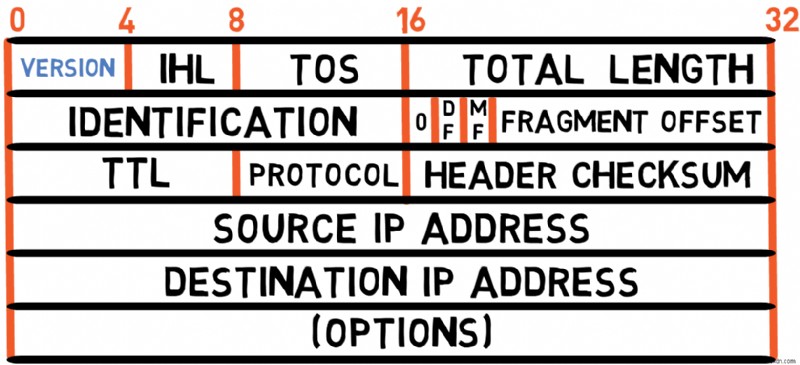
ヘッダーは、4 ビットで構成される Version フィールドで始まります。 IPv4 パケットの場合、バージョンは 4 です。 したがって、このフィールドには常に 4 の値が含まれます。 (または 0100 バイナリ)。
❓ ヘッダーが Version フィールドで始まるのはなぜですか? 🤔
(注 – 文の先頭に ❓ マークを付けた場合、それはあなたに宛てた質問なので、読み続ける前に答えてみることをお勧めします)。
その理由は、残りのフィールドがバージョンによって異なる可能性があるためです。ネットワーク デバイスが IP パケットを読み取り、バージョン フィールドの値が 4 である場合 の場合、パケットの残りの部分が IPv4 構造に従うことが期待されます。 6 などの別の値が含まれる場合 、残りのフィールドは、IPv6 と同様に異なります。

このフィールドはヘッダー自体の長さを示します。
❓ なぜ長さを指定する必要があるのですか? 🤔
ヘッダー サイズが固定されているイーサネットとは異なり、IPv4 ヘッダーの長さは、オプションのフィールドによって異なる場合があります。特別なオプションのない IP パケットの場合、ヘッダーは 20 で構成されます。 バイト。これが最も一般的なケースです。
IHL フィールドは長さをバイト単位で直接指定するのではなく、4 バイトのワード単位で指定します。したがって、20 の長さを指定するには バイトの場合、値は 5 になります。 (5 × 4 =20)。このエンコーディングでは、ヘッダー長を 60 まで指定しながら、フィールドで使用できるのは 4 ビットだけです。 バイト (IHL =15 の場合) ).
したがって、一般的な IPv4 パケットはバイト 0x45 で始まります。 16 進数で、バージョン 4 を意味します。 IP プロトコルのヘッダーは 20 です。 バイト長。
サービスタイプ (TOS) (8 ビット)

このフィールドの背後にある考え方は、すべてのパケットが同じように重要であるわけではないということです。一部のパケットを他のパケットよりも優先したい場合があります。
たとえば、リアルタイム データを運ぶパケット (音声会議やビデオ会議など) は、電子メールやファイルのダウンロードを運ぶパケットよりも時間に敏感です。ルーターで現在高負荷が発生している場合は、時間に敏感なパケットを優先するのが理想的です。
Type of Service フィールドを使用すると、送信者はパケットの優先順位を示すことができます。ただし、公共のインターネットでは、送信者が任意の優先値を設定できるため、このフィールドはルーターによって無視されることがよくあります。ほとんどの場合、このフィールドには 0 の値が入ります。 .
全長 (16 ビット)
このフィールドは、ヘッダーとペイロード (データ) の両方を含む IP パケットの全長を指定します。
❓ Why is this needed to specify the length? 🤔
Unfortunately, the IP layer doesn’t necessarily know if some of the bytes in the packet are actually a padding of the second layer. I described this in detail in a previous post, where I showed that in Ethernet protocol, in some cases, the receiving Ethernet entity cannot tell which bytes belong to the payload and which bytes are simply padding. The IP layer needs to know precisely which bytes belong to the actual packet, hence the Total Length field.
❓What is the maximum size of an IPv4 packet? 🤔
Since this field is 16 bits long, an IPv4 packet may contain a maximum of 2^16-1 bytes, or 65,535 bytes, including the header. The minimum size is 20 bytes, consisting of just the header without options or payload.
Fragmentation Fields (32 bits)
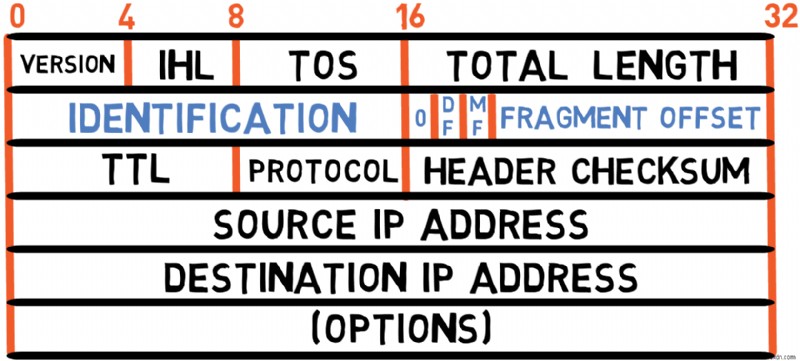
The next four bytes are dedicated to fragmentation control. I’ll cover these fields in a separate section, as they involve a complex topic deserving special attention.
Time to Live (8 bits)

Despite its name, this field doesn't actually measure time but rather the maximum number of routing hops a packet can traverse before being discarded.
To understand its purpose, consider this scenario:If Machine A sends a packet to Machine B through a series of routers, but there's a routing loop where Router 2 sends to Router 3, which sends to Router 4, which sends back to Router 2, the packet could circulate indefinitely, consuming bandwidth and never reaching its destination.
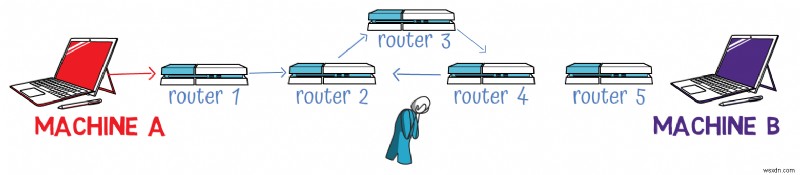
The TTL field prevents this by setting a limit on how many hops a packet can take:
<オル>
The sender sets an initial TTL value (often 64 or 128 )
Each router that handles the packet decrements the TTL by 1
If a router receives a packet with TTL =1 , it decrements it to 0 and discards the packet
The router then sends an ICMP "Time Exceeded" message back to the original sender
This doesn't solve the underlying problem of routing loops, but it prevents packets from circulating forever.
In IPv6, this field is renamed "Hop Limit," which more accurately describes its function.
Protocol (8 bits)

This field describes the payload of the IPv4 packet.例:
-
A value of
6means the payload is TCP -
A value of
17means the payload is UDP
This helps the receiving system know which protocol handler should process the packet's contents. It's similar to the Type field in Ethernet, which specifies the protocol of the layer encapsulated within the Ethernet frame.
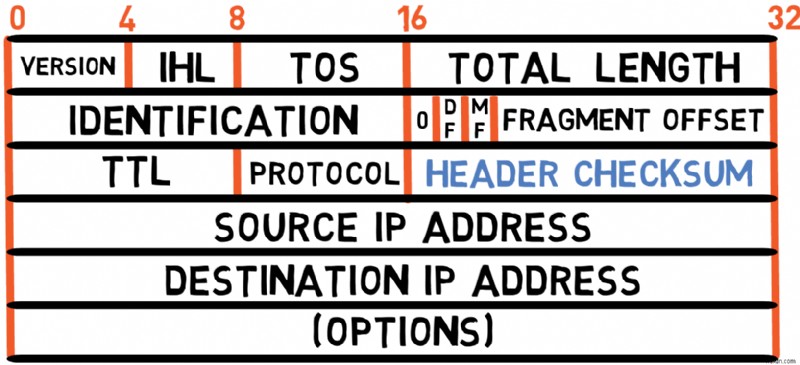
This is a 16-bit checksum used to verify the validity of the header only (that is, excluding the payload). The sender computes this value based on the fields of the header, and the receiver also computes it to validate that the header was received correctly.
❓The checksum must be recalculated by each router.何故ですか? 🤔
Because the TTL field changes at each hop. For example, if a packet starts with TTL =7 , each router will:
Verify the current checksum based on TTL =7
Decrement TTL to 6
Calculate a new checksum based on TTL =6
Forward the packet with the new checksum
If the checksum verification fails, the device drops the packet. This prevents packets with corrupted headers (which might have incorrect destination addresses, for instance) from being forwarded.
Source and Destination Addresses (32 bits each)
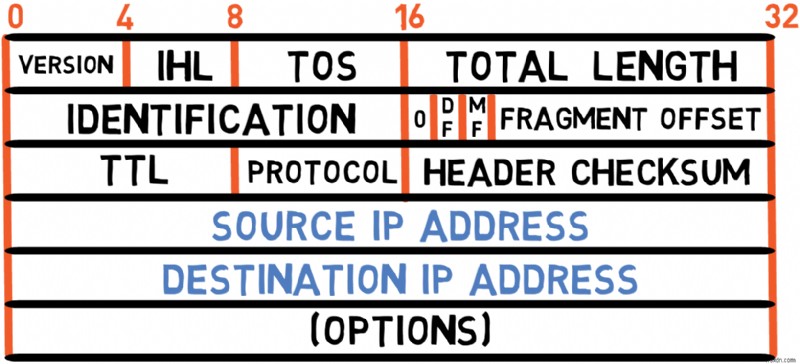
These fields contain the source and destination IPv4 addresses, respectively. Each is 4 bytes (32 bits) long, as you learned in the previous sections on IPv4 addressing.
Options (Variable Length)
Most IPv4 packets don't include options, but when present, they can provide additional functionality:
-
Record Route :Each router that handles the packet adds its own address to this option, creating a trace of the packet's path
-
Source Routing :Allows the sender to specify the route the packet should take:
-
Strict Source Routing:The entire route must be followed exactly
-
Loose Source Routing:Certain routers must be traversed, but the exact path between them is flexible
-
Padding
In some cases, the header ends with padding bytes (usually 0 s).
❓Why does the IPv4 header have padding?🤔
As explained before, the IHL field specifies the header length in 4-byte units, so the total header length must be a multiple of 4 bytes. If options make the header length not divisible by 4, padding bytes (usually 0 ) are added to reach the next multiple of 4.
For example, if you have 3 bytes of options, you would need 1 byte of padding to make the total header length a multiple of 4 bytes.
You've now learned about the structure of the IPv4 header, with the exception of the fragmentation fields which I’ll cover in the next section.
The IPv4 header efficiently packs all the necessary routing and control information into a compact structure, typically 20 bytes long (without options). This design allows for fast processing by routers while providing the flexibility needed for internet communication. It is amazing how prominent IPv4 is, even so many years after its publication.
In the next section, you'll learn about IPv4 fragmentation.
IPv4 Fragmentation
In the previous section, you learned about most of the IPv4 header structure, with the exception of 32 bits dedicated to fragmentation. This topic deserves special attention, as it reveals important aspects of how IP packets travel across different networks.
Why Fragmentation Is Needed
To understand what fragmentation is and why it's needed, consider the following network scenario:
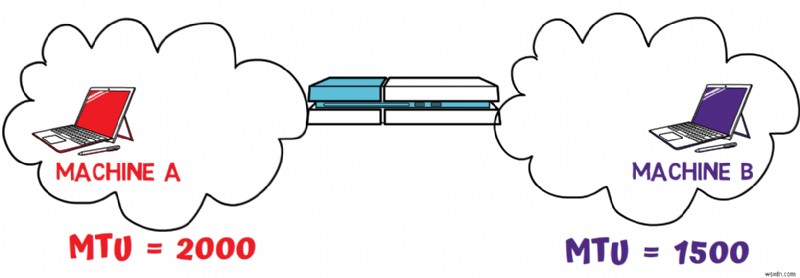
In this diagram, you have two different networks where Machine A resides in one network and Machine B resides in another. A router forwards packets between these two networks.
These two networks have different Maximum Transmission Units (MTUs). MTU refers to the maximum size of a frame that can be transmitted in a network.例:
-
Machine B is connected to an Ethernet network with an MTU of
1500bytes -
Machine A is connected to a different network with an MTU of
2000bytes
Different MTUs stem from the different protocols and hardware that different networks have. Ethernet has an MTU of 1500 bytes. This maximum size was chosen because RAM was expensive back in the late 1970s when Ethernet was planned, and a receiver would need more RAM if a frame could be bigger. Other networks were devised at different times where RAM prices might have been lower, or just have other considerations that affect the MTU.
Now, consider this scenario:Machine A wants to send a packet to Machine B. This packet is 1800 bytes long. From A's perspective, there's no problem since its network supports packets of this size. Machine A transmits the packet.
When the router receives this packet, it faces a problem:it cannot simply forward the packet to B's network because the packet is too big for the network's MTU. The router must fragment the packet – splitting it into smaller chunks of up to 1500 bytes, which will then be reassembled by Machine B.
How Fragmentation Works in IP
Let's examine the scenario further. The router needs to take an IP packet of 1800 bytes and split it into two fragments, each consisting of up to 1500 bytes. If Machine A sends another packet of 1800 bytes to Machine B, the router will have to split that one too – resulting in four different fragments that will be reassembled into two separate packets.

When Machine B receives these fragments, it must ensure that it reassembles fragment #1 together with fragment #2 of packet A, and fragment #1 with fragment #2 of packet B – and not, for instance, fragment #1 of packet A with fragment #2 of packet B. It must also reassemble the fragments in the correct order – so structure a packet that consists of #1#2 and not #2#1.

Identification Field
First, focus on making sure Machine B reassembles fragments of the same packet (for example, fragment #1 and fragment #2 of packet A in the example above, rather than fragment #1 of packet A and fragment #2 of packet B). This is achieved using the identification field of IPv4. Fragments belonging to the same packet will have the same identification value. For example, both fragments of packet A might have identification set to 100 , and both fragments of packet B might have identification of 200 .

It's important to note that sharing identification values isn't sufficient for fragments to belong to the same packet. Fragments of the same packet must also share:
-
The same source IP address
-
The same destination IP address
-
The same protocol value (indicating whether the payload is TCP, UDP, and so on)
Fragment Offset
Since IP is a connectionless protocol, there's no guarantee that fragments will arrive at Machine B in the correct order. Fragment #2 of packet A may arrive before fragment #1. To handle this issue, each fragment carries an Offset field, which denotes the offset from the beginning of the original packet.
The Offset field consists of 13 bits, which means it can carry values from 0 to 8191 (2^13-1). This poses a potential problem, as the maximum size of an IP packet can be 65,535 bytes (since the Total Length field of the IP header consists of 16 bits).
To address this limitation, the value encoded in the Offset field is actually multiplied by 8 (2^3). This means the minimum size of a fragment is 8 bytes, with the exception of the last fragment.
❓Why do IP packets carry an offset in bytes divided by 8, instead of just a sequential fragment number?🤔
While using sequence numbers might seem simpler, it would create problems when packets need to be fragmented multiple times.
For example, if Computer A sends a packet to the first router, which fragments it into pieces of 1480 bytes and 320 bytes, and then these fragments are sent to another router that needs to fragment them again into even smaller pieces, how would you number them?
With byte offsets, the solution is straightforward – if the first fragment has an offset of 0 and the next one has an offset of 1480 , then if we need to split them into maximum 800 -byte fragments, we'd have:
-
First fragment:
800bytes with offset0 -
Second fragment:
680bytes with offset800 -
Third fragment:
320bytes with offset1480
More Fragments and Don't Fragment Flags
When Machine B receives a fragment, it needs to know whether this is an entire packet by itself or if it should expect additional fragments. For this purpose, each IP fragment carries a More Fragments (MF ) bit that is set to 1 for every fragment that is not the last fragment of the packet. For the last fragment, it's set to 0 .
In case the packet consists of a single fragment – the MF bit will be set to 0 , and the offset field will also hold the value 0 (that is, 13 bits of 0 s).
Another bit related to fragmentation is the Don't Fragment (DF ) bit. When this flag is turned on, intermediate devices should not fragment the original packet, even if it exceeds the MTU. Instead, they should drop it and typically send an ICMP "Fragmentation Needed" message back to the source.
In our example, if Machine A sets the Don't Fragment bit to 1 , the router would drop the packet, and notify Machine A about it.
Note that right after the identification field and before the DF flag, there is a reserved bit set to 0 。 This bit was reserved in case it is needed in the future, for a reason unknown to the original authors of IPv4.
Fragmentation Example
Consider again our example above – with Machine A residing in a network where the MTU is 2000 , and Machine B residing in a network where the MTU is 1500 。 Machine A sends a packet which is 1800 bytes long.
❓Can you fill the values in these tables?
First Fragment:
Total Length IdentificationDon’t FragmentMore FragmentsOffsetSecond Fragment:
Total Length IdentificationDon’t FragmentMore FragmentsOffsetFor our example above, the values of the relevant fragmentation fields in IP would be as follows:
First Fragment:
-
Total Length:
1500(including20bytes of IP header, so1480bytes of payload) -
Identification:
1337(arbitrary value) -
Don't Fragment bit:
0(off, to allow further fragmentation if needed) -
More Fragments bit:
1(on, as this is not the last fragment) -
Offset:
0(it's the first fragment)
Second Fragment:
-
Total Length:
340(including20bytes of IP header, so320bytes of payload – together with the first fragment, we get to1800bytes of payload) -
Identification:
1337(same as first fragment, indicating they belong together) -
Don't Fragment bit:
0(off, to allow further fragmentation if needed) -
More Fragments bit:
0(off, as this is the last fragment) -
Offset:
185(1480/8 =185, or0xB9in hexadecimal)
IPv4 Fragmentation – Summary
You've now learned about the final part of the IPv4 Header:fragmentation. Fragmentation is necessary to allow packets to travel across networks with different MTUs. The IPv4 header includes several fields specifically designed to support fragmentation:
-
Identification (16 bits):Identifies which fragments belong together
-
Flags (3 bits):Including the "More Fragments" and "Don't Fragment" flags
-
Fragment Offset (13 bits):Indicates where in the original packet this fragment belongs
With this knowledge, you now understand every bit and byte of the IPv4 header and how IP packets can traverse networks with different characteristics.
Summary – IPv4
In this comprehensive guide to IPv4, you've learned about the fundamental building blocks of Internet communications. Let's recap the key concepts we covered:
Addressing and Network Structure
-
IPv4 addresses are 32-bit numbers typically written in dotted decimal notation
-
Networks can be identified using various methods:
-
Fixed-length approach (historically)
-
Classful addressing (A, B, C, D, E classes)
-
CIDR (modern approach allowing flexible network sizes)
-
-
Special addresses serve specific purposes:
-
0.0.0.0for "this host" -
127.0.0.0/8for loopback -
255.255.255.255for broadcast
-
-
The header contains crucial fields for packet routing and processing:
-
Version and IHL for header interpretation
-
Type of Service for traffic prioritization
-
Total Length for packet size
-
Various fields for fragmentation control
-
TTL to prevent infinite routing loops
-
Protocol to identify the encapsulated protocol
-
Checksum for error detection
-
Source and destination addresses
-
Fragmentation
-
Allows IPv4 packets to traverse networks with different MTUs
-
Uses three key fields:
-
Identification to group fragments
-
Flags to control fragmentation
-
Fragment Offset to reassemble packets
-
Final Words
While IPv4 has limitations, particularly its address space constraints, its elegant design and robust features have allowed it to remain the backbone of the Internet for over four decades. Understanding IPv4 provides essential context for working with modern networks and helps in transitioning to newer protocols like IPv6.
About the Author
Omer Rosenbaum is Swimm’s Chief Technology Officer. He's the author of the Brief YouTube Channel. He's also a cyber training expert and founder of Checkpoint Security Academy. He's the author of Gitting Things Done (in English) and Computer Networks (in Hebrew). You can find him on Twitter.
Additional References
- Computer Networks Playlist - on my Brief channel
無料でコーディングを学びましょう。 freeCodeCamp のオープンソース カリキュラムは、40,000 人以上の人々が開発者としての職に就くのに役立ちました。始めましょう
-
コンピュータネットワークに使用されるポート番号
コンピュータネットワークでは、ポート番号はメッセージの送信者と受信者を識別するために使用されるアドレス情報の一部です。これらはTCP/IPネットワーク接続に関連付けられており、IPアドレスへのアドオンとして説明される場合があります。 ネットワークのポート番号とは何ですか? ポート番号を使用すると、同じコンピューター上のさまざまなアプリケーションでネットワークリソースを同時に共有できます。ホームネットワークルーターとコンピューターソフトウェアはこれらのポートで動作し、ポート番号設定の構成をサポートする場合があります。 ネットワークポートはソフトウェアベースであり、ネットワークデバイスがケー
-
修正:Twitch2000ネットワークエラー
ご存知のように、Twitchは、Amazonが提携しているTwitchInteractiveによって開発されたビデオライブストリーミングプラットフォームです。ユーザーは、Google Chrome、FirefoxなどのさまざまなブラウザのTwitch.tvサイトで、ストリーミングビデオを視聴したり、何百万人ものファンとチャットしたりできます。たとえば、ゲーマーはその上でゲームについて話し合いたいと考えています。しかし、 2000:Twitchのネットワークエラーに遭遇した方もいらっしゃると報告されています。 このプラットフォームに入り、他の人とチャットしようとしたとき。 Twitchで20