RAG システムが本番環境で失敗する原因となる一般的な落とし穴
検索拡張生成は、大規模な言語モデルを外部の知識で拡張すると考えられています。デモでは見事に機能します。厳選された小規模なデータセット、クリーンなクエリ、制約のないレイテンシ バジェットにより、ユーザーが正しいと信じる知識に基づいた根拠のある回答が得られます。ただし、多くのチームは、RAG アプリケーションをユーザーにデプロイすると、パフォーマンスが低下することに気づきました。クエリがあいまいになり、コーパスが拡大し、検索品質が低下し、待ち時間が膨張し、システムの精度は静かに低下し始めます。さらに悪いことに、評価手法が貧弱であると、ユーザーから苦情が出るまでシステムが実際にどこで障害を起こし始めるのかが隠れてしまいます。この記事では、多くの RAG システムが実稼働環境で失敗する理由を探ります。最近の研究と業界のガイドラインに基づいています。私たちは、取得品質、レイテンシのトレードオフ、埋め込みドリフト、および評価ギャップを中心とした問題を、一連の障害モードのリンクとして整理します。堅牢な本番 RAG システムを構築するには、このチェーン内の各リンクを考慮する必要があります。
重要なポイント
- ほとんどの RAG 障害は、生成ではなく取得で始まります。 システムが不完全、無関係、またはランク付けが不十分な証拠を取得すると、たとえ強力な LLM であっても、弱い答えが生成されます。
- より良い検索には、より良いエンジニアリングの選択が必要です。 ドメインを意識したチャンキング、ハイブリッド検索、再ランキングは、関連性を向上させ、サイレント検索の失敗を減らすための中核的な手法として紹介されています。
- レイテンシはすぐに本番環境のボトルネックになります。 より大きな top_k、リランカー、長いコンテキスト、追加の取得ステップを追加すると、再現率が向上する可能性がありますが、実際のユーザーにとってシステムが遅くなりすぎる可能性もあります。
- ドリフトを埋め込むと、時間の経過とともにパフォーマンスが静かに低下します。 埋め込みモデル、ドキュメント コレクション、ユーザー語彙の変更はすべて、検索動作を変化させる可能性があるため、バージョン管理と可観測性が必要です。
- 最終回答の質だけでは評価には不十分です。 チームには、個別の取得指標と生成指標、現実的なテストセット、継続的なモニタリング、証拠が弱いか欠落している場合にシステムが棄権する機能が必要です。
低い取得品質による失敗
取得品質の低さは、RAG システムを運用環境に導入した場合に障害が発生する最も一般的な原因の 1 つです。開発者は、間違った/不適切な答えについて LLM を非難することがよくあります。ただし、通常、障害はパイプラインの早い段階で発生します。システムが完全な証拠や関連する証拠を取得できない場合、または証拠のランク付けが不十分な場合は、最良のモデルであっても信頼できる応答が生成される可能性は低くなります。取得品質は、バックグラウンド ステップではなく、エンジニアリング上の最重要事項として扱う必要があります。
ほとんどの失敗は、LLM がクエリを認識する前に発生します
標準パイプラインはユーザー クエリを埋め込み、ベクター ストアから上位 k のドキュメントを取得して、LLM に送信します。そのパイプライン内のすべての矢印は、潜在的な障害点となります。
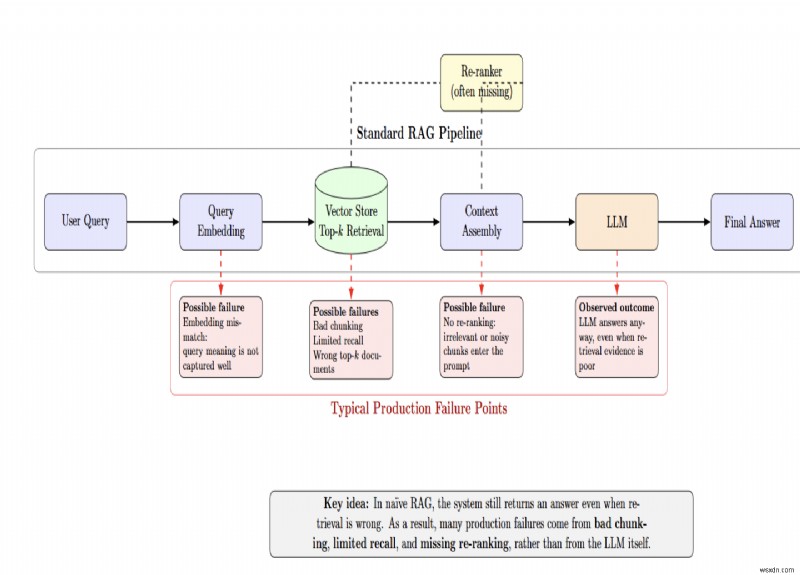
Naïve RAG は、検索が間違っているかどうかに関係なく、システムが答えを提供するため、これらの失敗を隠します。制作上の問題の多くは、LLM の欠点ではなく、不適切なチャンキング戦略、リコールの制限、再ランキングの欠落によって発生します。
チャンクミスによりサイレントエラーが発生する
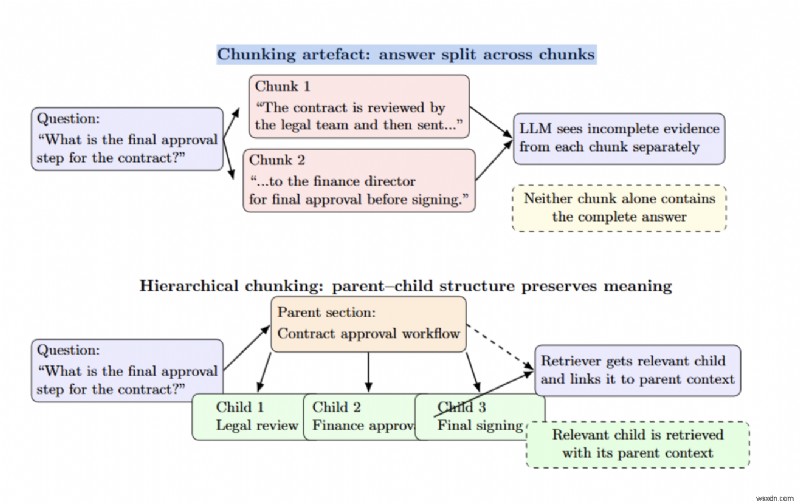
チャンク サイズは精度と再現率に影響します。チャンクが大きいほど関連性は低くなりますが、より多くのコンテキストが提供されます。一方、チャンクが小さいほど精度は高くなりますが、周囲の情報が失われます。階層 (親-子) チャンク化は、セクション全体を親チャンクとして保存し、より小さな関連する子チャンクのみを取得することで、このトレードオフを解決します。
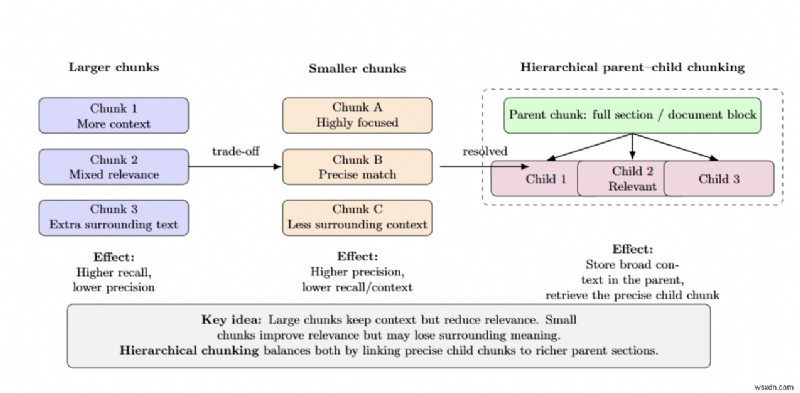
大学のプレゼンテーション資料に対する NVIDIA の内部テストでは、階層チャンクにより解答精度が固定サイズ チャンクの 61% から 89% に向上することがわかりました。構造上の境界を尊重し、可能な場合はドメインを意識した分割を適用しながら、適切なチャンク サイズを選択することが重要です。
ハイブリッド検索と再ランキング
純粋な密な検索は、意味上の類似性には優れていますが、正確な識別子を見逃します。純粋なキーワード検索は、正確な用語には敏感ですが、意味上の言い換えには失敗します。ハイブリッド検索システムは、密 (ベクトル) 検索と疎 (BM25/キーワード) 検索を同時に実行し、その結果を相互ランク融合で融合します。
ハイブリッド検索システムは、意味的類似性信号と語彙一致信号を組み合わせることにより、語彙の不一致を解決します。融合後に再ランカー (クロスエンコーダー) を使用して候補ペアを再スコアリングすると、再現率が向上します。基本的に、リランカーは取得したドキュメントを並べ替えて、最も関連性の高いドキュメントのみが LLM がレビューするコンテキストに含まれるようにします。これにより、トークンの制限が節約され、コンテキストの詰め込みが回避され、LLM の再現率が向上します。
取得指標は個別に監視する必要がある
チームはエンドツーエンドの回答品質のみを測定する傾向があります。取得自体には、precision@k (取得したチャンクのどの部分が関連していますか?)、recall@k (関連するチャンクのどの部分を取得しましたか?)、平均逆順位 (最初の関連チャンクの高さはどれくらいですか?)、および正規化割引累積ゲイン (全体のランキングはどの程度優れていますか?) など、使用できるメトリクスがあります。

これらを測定しないと、障害の原因が不正な取得にあるのか、不正なジェネレーターにあるのかわかりません。テスト クエリとゴールデン データセットを使用すると、オフラインで評価できます。実際のクエリでこれらのメトリクスを追跡すると、本番環境の回帰を明らかにすることができます。
例を使用した取得失敗の診断
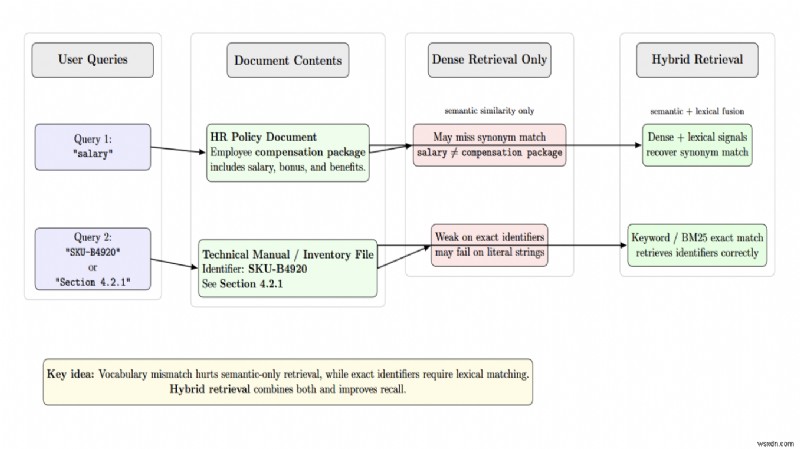
あいまいなクエリや語彙の不一致により、多くの場合、不正確な検索が発生します。ユーザーは、ドキュメントで「報酬パッケージ」について言及しているときに「給与」を検索する可能性があります。密な埋め込みは同義語を認識できない可能性がありますが、ハイブリッド検索はこれを修正します。もう 1 つのケースは、識別子などの完全一致の場合です。 「SKU‑B4920」または「セクション 4.2.1」のクエリには、正確な字句一致が必要です。
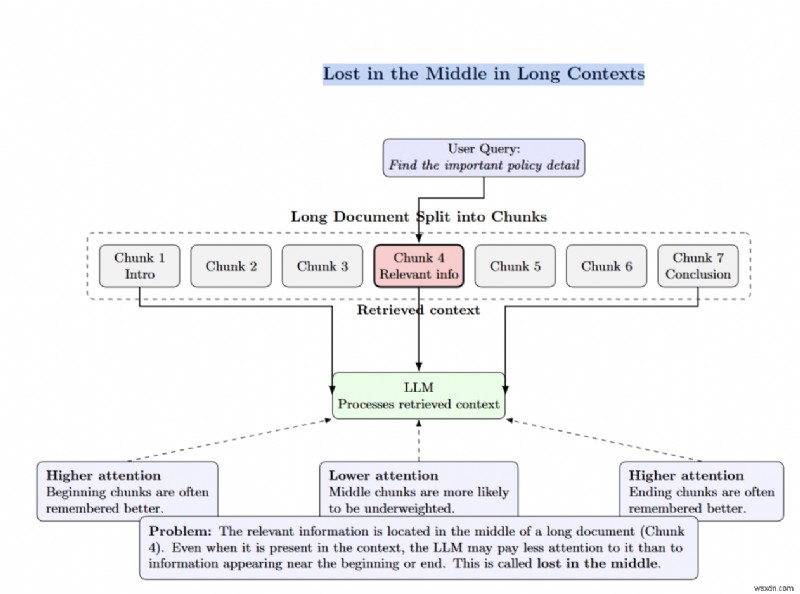
「途中で紛失」は、関連情報が長い文書の奥深くに埋もれているときに発生します。 LLM は、中間のチャンク内のトークンの重みを小さくします。
チャンク化アーチファクトは、回答が 2 つのチャンクに分割されている場合に発生するため、どちらのチャンクにも完全な回答が含まれていません。階層チャンクは、親ノードと子ノードを接続することでこの問題を軽減します。
実際のシステムにおける遅延の爆発による障害
レイテンシーは、デモでは動作する RAG システムが実稼働環境で動作しない主な理由の 1 つです。検索パイプラインがより洗練されると、応答時間が急速に増加する可能性があり、チームは回答の品質と使いやすさを引き換えにする必要があります。
取得と遅延のトレードオフ
制作チームは多くの場合、取得品質とレイテンシ バジェットのバランスを取る必要があります。応答時間を増加させるすべてのこと (top_k の拡大、ハイブリッド取得の追加、再ランキングの実行、またはロングコンテキスト モデルの実行) は、これらの予算を削減します。ユーザーは応答性の高い回答を期待しており、エンタープライズ統合には厳格なレイテンシ バジェットが伴うため、このトレードオフは特に困難です。ただし、Cornell と NVIDIA による最近の研究が示しているように、RAG では大幅なレイテンシ オーバーヘッドが発生します。取得を頻繁に実行すると精度は向上しますが、エンドツーエンドのレイテンシが 30 秒近くまで増加し、実稼働環境で使用するには長すぎます。
通常は世代が優先しますが、検索も重要です
RAGPerf を使用したベンチマークでは、生成がテキストのみの RAG パイプラインの主要な部分であることが多いことがわかります。 。より小さい LLM を選択すると、取得品質が維持されていれば、応答品質を犠牲にすることなく待ち時間を大幅に短縮できます。マルチモーダル パイプライン (PDF および画像検索) では、再ランキングと関連するクロスモーダル モデルのせいで、大量のコンピューティング要求が発生します。ベクトル データベースが遅い場合、または同時検索が許可されていない場合、取得遅延が増加する可能性があります。ただし、高速ルックアップであっても、再ランキングが多くの RAG ワークロードの合計レイテンシを支配する可能性があります。
レイテンシ、コスト、コンテキスト ウィンドウ
一部のチームは、top_k を増やすか、LLM のコンテキストにさらに多くのドキュメントを詰め込むことでリコールを解決しようとします。研究によると、これは逆効果です。プロンプトに追加するドキュメントが増えるほど、LLM が正しい情報を呼び出すことができなくなります。取得再ランキングは、多くのドキュメントを取得し、LLM に最適なものだけを選択することでこの問題を解決します。コンテキスト ウィンドウが長いと、「途中で失われ」、天文学的な計算コストが発生します。
レイテンシーの最適化
RAG システムのレイテンシーに対処するには、パイプライン全体にわたる意図的なオーケストレーションが必要です。
ドリフトと知識の変化の埋め込みによる失敗
エンベディングは、テキストを、互いに近い同様の意味を持つ高次元ベクトルとして表現します。チームは、インデックスを適切にバージョン管理したり、関連性の変更をベンチマークしたりせずに、別の埋め込みモデルでドキュメントを再埋め込んだり、クエリ エンコーダーを交換したりすることが頻繁にあります。新しいモデルは客観的には強力である可能性がありますが、予期せぬ方法で近隣構造を変更し、ランキング、再現率、さらにはドメイン固有の言語に影響を与える可能性があります。一般化されたベンチマークで優れたモデルでも、現実世界の企業用語ではパフォーマンスが著しく低下する可能性があります。
ドリフトの 3 つの原因
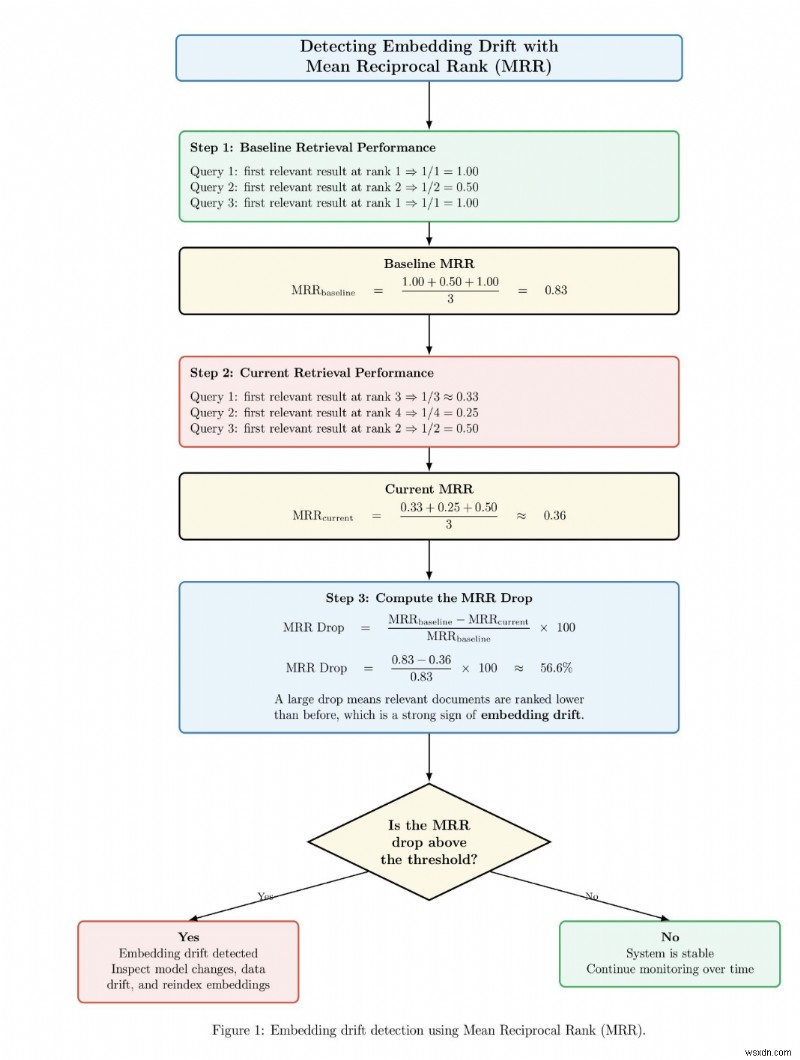
<オル>平均逆数ランクによる埋め込みドリフトの検出
以下は、システム変更の前後または経時的な取得パフォーマンスの変化を監視することによって、埋め込みドリフトがどのように検出されるかを示す図例です。この図では、まず、関連するドキュメントがランキングの上位付近に表示されるベースライン MRR スコアを計算します。次に、関連するドキュメントがランキングの下位にランク付けされる現在の MRR スコアを計算します。次に、システムはベースライン MRR と現在の MRR の間の低下率を計算します。 MRR の低下が事前に選択されたしきい値を超えている場合、システムは埋め込みドリフトに対するアラートを生成し、埋め込みモデル、データ分布、およびインデックスを見直すことを提案します。それ以外の場合、低下がしきい値を下回っている場合、システムは取得システムが安定していると判断し、監視を継続します。
このため、運用 RAG システムは明示的にバージョン管理され、監視可能である必要があります。埋め込みはバージョン管理する必要があります。インデックスの構築は追跡可能である必要があります。チャンク化ポリシーは文書化され、再現可能である必要があります。品質が低下し始めた場合は、次のような質問に答えることができなければなりません:どの埋め込みモデルがこのインデックスを生成したか?このコンテンツのチャンクはどのようなチャンキング ルールによって作成されましたか?この文書が最後にシステムに再取り込まれたのはいつですか?このリクエストを処理したレトリバーとリランカーは何ですか?
パイプラインを可視化できない場合、ドリフトはランダムに見えるでしょう。これにより、診断可能になります。
評価ギャップによる失敗:本当のボトルネックが隠れている
評価が弱いことは、チームが RAG システムを実稼働環境に導入できない最も一般的な理由の 4 番目です。私たちは最終的な答えだけを評価する傾向があります。それだけでは十分ではありません。
実稼働グレードの RAG はパイプラインです。どの層の数であっても、入力が不十分だと最終出力が不良になる可能性があります。取得者が正しい文書を取得できなかった可能性があります。ランカーが最良の証拠を低すぎるランクに付けた可能性があります。コンテキスト アセンブラにノイズが多すぎる可能性があります。発電機は最も強力な部分をごまかしている可能性があります。答えは、広範なレベルでは正しいものの、回収された証拠には完全に忠実ではない可能性があります。最終出力テキストのみをスコアリングした場合、弱いステージを特定することはできません。
取得指標は個別に評価する必要がある
このため、RAG 評価には、生成メトリックとは別の取得メトリックを含める必要があります。取得指標には、コンテキストの精度とコンテキストの再現率が含まれる必要があります。
- コンテキストの想起 :コンテキスト想起は、取得した文章に質問に答えるために必要な情報が含まれているかどうかをチェックします。
- コンテキストの精度 :コンテキストの精度は、取得されたセットがほとんど関連性があるか、それともノイズで汚染されているかを測定します。
- ランキングの品質: ランク 1 の関連する文章は、ランク 10 の同じ関連する文章よりも役立つため、ランキングの品質も重要です。
世代指標も同様に重要
取得が測定されたら、生成層を独自の条件で評価する必要があります。 2 つの重要な指標は、根拠と忠実さです。
- 根拠: グラウンディングでは、検索されたコンテキストで提供された情報が回答に反映されているかどうかを尋ねます。
- 忠実さ: 忠実度では、モデルがそのコンテキストを正確に表現しているかどうかが問われます。この指標が重要なのは、システムがソース素材を偽りながらももっともらしく聞こえる可能性があるためです。
非現実的なテスト データにより実際の失敗が隠蔽される
非現実的なテスト データも大きな問題です。多くのチームは、社内チームが慎重に精選したクリーンで総合的な質問やプロンプトに基づいて評価を行っています。これにより、根本的に実際の障害表面が隠蔽されてしまいます。本番環境での評価条件には、曖昧な質問、矛盾したドキュメント、部分的なユーザー入力、古いコンテンツ、およびまったく答えないことが正解である状況が含まれる必要があります。データセットが実際のユーザーの行動を反映していない場合、評価は診断ツールではなく快適なメカニズムになります。
展開後も評価を継続する必要がある
最初の実行が完了した後でも評価を停止すべきではありません。実稼働 RAG が変更されます。書類が変わります。埋め込みが交換されます。ランキングロジックが進化。プロンプトテンプレートが切り替わります。 CI/CD の一部としての評価や、導入後の本番環境のトレースを行わないと、ユーザー自身のモニタリングからではなく、不満を抱いたユーザーからのリグレッションについて知ることになります。
ベンチマークが良好に見えても本番 RAG が失敗する理由
ここで多くのチームが混乱します。ベンチマークは改善されましたが、ライブ システムは依然として期待外れです。
生産の失敗は通常、インセンティブの不整合によって引き起こされます。チームは、レイテンシ バジェットを考慮せずに取得リコールを最適化するか、取得精度を追跡せずに、より高い LLM スコアを目指して最適化しようとします。生成品質を犠牲にして取得が過剰に調整され、ノイズが発生する可能性があります。生成は、取得の改善とは関係なく、過剰に調整される可能性があります。取得精度と生成精度の適切な比率はアプリケーションによって異なります。コンプライアンス、法律、その他のリスクの高いユースケースでは、可能な限り忠実さとコンテキストの正確さが必要です。創造的なユースケースでは、スピードと引き換えにノイズを許容することができます。
本番環境は単一の指標に基づいて最適化されるわけではありません。取得の品質、待ち時間、鮮度、根拠、操作の単純さの間にはトレードオフがあります。デモの成功が誤解を招きやすいのはこのためです。 「正しく聞こえる」デモの報酬システム。生産は信頼性に報います。
本番 RAG システムを修正する方法
今後の道は、RAG を放棄しないことです。それは、規律ある検索システムとして扱うことです。
よくある質問セクション
RAG での取得品質はどのように測定しますか?
私たちは、コンテキストの精度、コンテキストの想起、ランク付けの品質などの検索指標を使用し、また、取得した証拠が実際に回答生成をサポートしているかどうかもチェックします。
本番環境で RAG システムが失敗する原因は何ですか?
本番環境の障害は、取得品質の低下、遅延のクリープ、埋め込み/コーパス ドリフト、および問題の始まりを隠す間違った評価慣行によって最も一般的に引き起こされます。
RAG パイプラインへのドリフトの埋め込みとは何ですか?
埋め込みドリフトは、明らかに壊れたシステム動作を引き起こすことなく、埋め込みモデル、コーパス、またはライブ クエリ動作の更新によって取得動作が徐々に変化する (関連性が低下する) 場合に発生します。
大規模になると RAG レイテンシが増加するのはなぜですか?
実稼働システムではクエリの書き換え、複数の取得パス、再ランキング、追加のモデル呼び出し、大規模なコーパスが追加されることが多く、これらすべてにより処理時間と運用の複雑さが増加するため、レイテンシが増加します。
RAG における根拠と忠実さをどのように評価しますか?
生成された回答を取得した証拠と比較し、主張が情報源によって裏付けられているかどうか、また文言が創作や歪曲なしにそれらの情報源を正確に反映しているかどうかを確認します。
結論
ほとんどの RAG システムにおける本番環境の障害は、単一点障害の結果ではありません。むしろ、責任あるエンジニアは、ほとんどの故障が接続チェーン内の弱いリンクから始まることに気づくでしょう。ほとんどの場合、最初に失敗するのは取得の品質です。エンジニアは、より多くの検索、より多くのコンテキスト、より多くのオーケストレーション層を活用することで、この問題を「解決」します。これを行うと、遅延が増加します。埋め込み、コーパス、およびユーザーの行動はすべて時間の経過とともに変動するため、評価指標が弱いと、システムが実際に失敗している箇所が隠れてしまいます。管理者が問題の存在に気づく前に、ユーザーは気づき始め、信頼を失い始めます。その頃には、パターンの崩壊が神秘的に感じられます。しかし、問題は最初から明らかでした。
RAG が大規模に失敗するのは、パターンが間違っているからではなく、実稼働 RAG システムの構築には強力な取得エンジニアリング、レイテンシ管理、ドリフト緩和、および継続的な評価が必要なためです。彼らは、ランキングの向上、チャンキングの向上、可観測性の向上、根拠と忠実さの測定を要求しています。最も重要なことは、チームは RAG を、一度設定すれば後は忘れるというデモ アーキテクチャではなく、生きたシステムとしてアプローチする必要があるということです。
リファレンス
- 本番環境の RAG システム:失敗する理由と修正方法
- 2026 年の RAG (および LLM) に最適なチャンキング戦略
- RAG 評価とは何ですか?検索の品質と回答の根拠を測定する
- 検索拡張生成モデル推論におけるシステム トレードオフの理解に向けて
- RAGPerf:検索拡張生成システムのためのエンドツーエンドのベンチマーク フレームワーク
- リランカーと 2 段階の取得
- RAG からコンテキストへ - RAG の 2025 年末レビュー
 この作品は、クリエイティブ コモンズ 表示 - 非営利 - 継承 4.0 国際ライセンスに基づいてライセンスされています。
この作品は、クリエイティブ コモンズ 表示 - 非営利 - 継承 4.0 国際ライセンスに基づいてライセンスされています。
-
情報セキュリティにおける最新のブロック暗号のコンポーネントは何ですか?
最新のブロック暗号は、平文のmビットブロックを暗号化し、暗号文のmビットブロックを復号化する暗号です。暗号化または復号化の場合、最新のブロック暗号はKビットキーを容易にし、復号化アルゴリズムは暗号化アルゴリズムの逆である必要があり、暗号化と復号化の両方で同様のキーが使用されます。 ブロック暗号は、nビットの平文ブロックで機能し、nビットの暗号文ブロックを作成します。複数の平文ブロックが存在する可能性があり、暗号化を可逆的にするために(つまり、復号化を適用するために)、それぞれが一意の暗号文ブロックを作成する必要があります。このような変換は、リバーシブルまたは非特異として知られています。 ブ
-
蛇と梯子の問題
有名なゲーム「蛇と梯子」について知っています。このゲームでは、いくつかの部屋が部屋番号とともにボード上に存在します。一部の客室ははしごやヘビでつながっています。はしごを手に入れると、順番に移動することなく、目的地の近くに到達するためにいくつかの部屋に登ることができます。同様に、ヘビを捕まえると、下の部屋に送られ、その部屋から旅を再開します。 この問題では、開始から目的地に到達するために必要なサイコロの投げの最小数を見つける必要があります。 入力と出力 Input: The starting and ending location of the snake and ladders. Sn