LangChain、Faiss、Next.js を使用してカスタム AI チャットボットを構築する – 実践ガイド
この投稿では、Upstash、Next.js、LangChain、Fly.io を使用してオープンソースのカスタム コンテンツ AI チャットボットを構築した方法について説明します。 Upstash は、モデル トレーニングのスケジュールを立てるのに役立ち、寛大なレート制限と OpenAI API 応答のキャッシュの方法を提供してくれました。
使用するもの
- Next.js(フロントエンドとバックエンド)
- LangChain (言語モデルを利用したアプリケーション開発用フレームワーク)
- Upstash(QStash によるトレーニング モデルのスケジュール設定、レート制限と OpenAI 応答のキャッシュ)
- Tailwind CSS(スタイリング)
- Fly.io(導入)
必要なもの
- Node.js 18
- Upstash アカウント
- OpenAI アカウント (OpenAI API キー用)
Upstash Redis のセットアップ
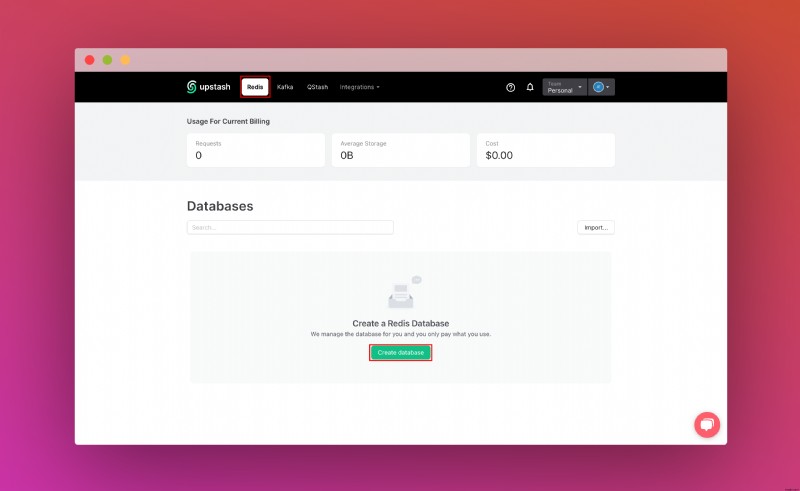
Upstash アカウントを作成してログインしたら、[Redis] タブに移動してデータベースを作成します。
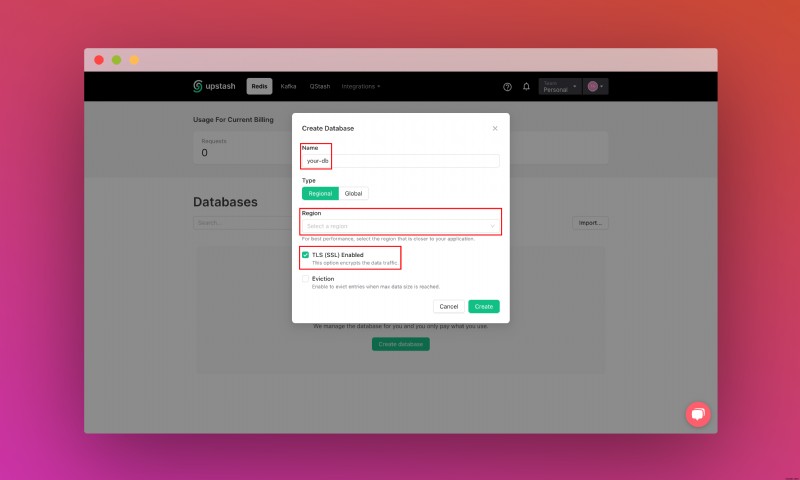
データベースを作成したら、「詳細」タブに移動します。 「データベースに接続する」セクションが見つかるまで下にスクロールします。コンテンツをコピーし、安全な場所に保存します。
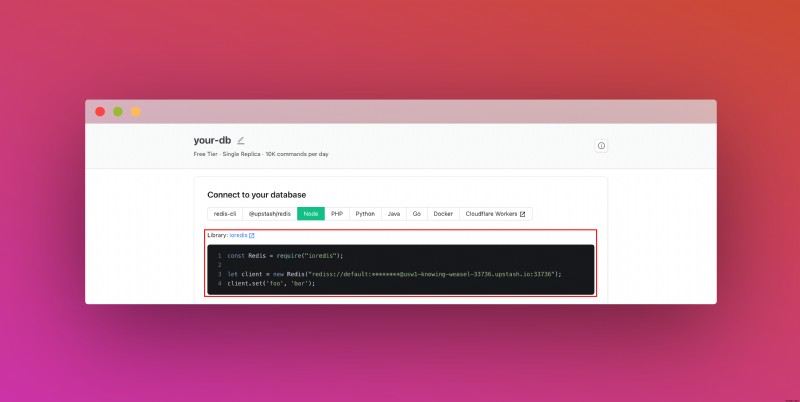
また、REST API セクションが見つかるまで下にスクロールし、.env ボタンを選択します。コンテンツをコピーし、安全な場所に保存します。
Upstash QStash のセットアップ
ログインしたら、QStash タブに移動し、QSTASH_URL を取得します。 、QSTASH_TOKEN 、QSTASH_CURRENT_SIGNING_KEY 、QSTASH_NEXT_SIGNING_KEY 。コンテンツをコピーし、安全な場所に保存します。
プロジェクトのセットアップ
セットアップするには、アプリ リポジトリのクローンを作成し、このチュートリアルに従ってそこに含まれる内容をすべて学習するだけです。プロジェクトをフォークするには、次を実行します。
git clone https://github.com/rishi-raj-jain/custom-content-ai-chatbot
cd custom-content-ai-chatbot
npm installリポジトリのクローンを作成したら、.env ファイルを作成します。上記のセクションで保存したアイテムを追加します。
次のようになります:
# .env
# Obtained from the steps as above
# Upstash Redis Secrets
UPSTASH_REDIS_REST_URL="https://....upstash.io"
UPSTASH_REDIS_REST_TOKEN="..."
# Upstash QStash Secrets
QSTASH_URL="https://qstash.upstash.io/v1/publish/"
QSTASH_TOKEN="..."
QSTASH_CURRENT_SIGNING_KEY="sig_..."
QSTASH_NEXT_SIGNING_KEY="sig_..."
# OpenAI Key
OPENAI_API_KEY="sk-..."
# Admin Access Key
# Used to verify a training request as to be done only by an admin
ADMIN_KEY="..."これらの手順を完了すると、次のコマンドを使用してローカル環境を起動できるようになります。
npm run devリポジトリ構造
これはプロジェクトのメイン フォルダー構造です。この投稿でさらに説明するファイルを赤でマークしました。このファイルでは、ベクター ストアの管理、カスタム コンテンツでトレーニングされた AI とチャットするための API ルートの作成 (応答のキャッシュを含む)、およびモデル トレーニング プロセスのスケジュール設定について説明します。
高レベルのデータ フローと操作
これは、データの流れと実行される操作の概要図です 👇🏻
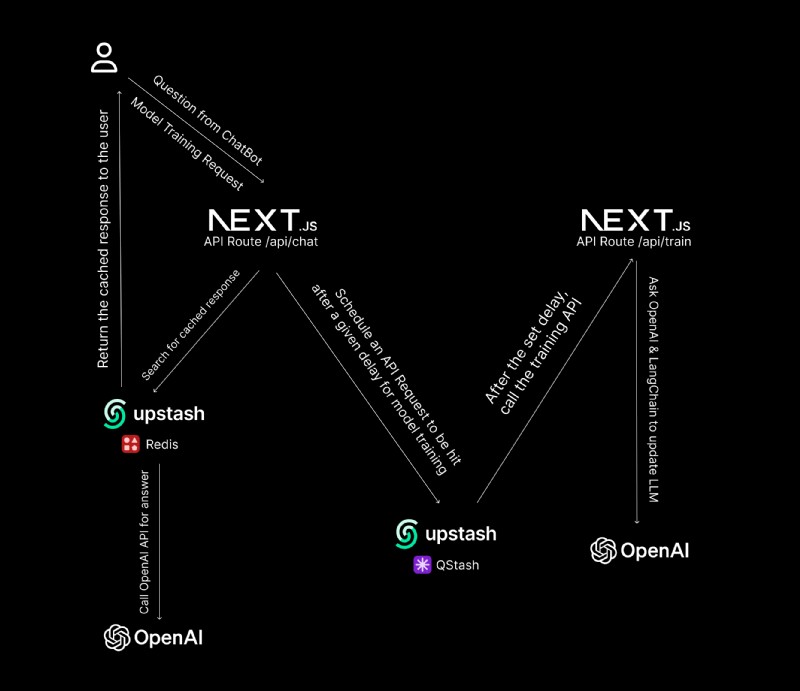
- ユーザーがチャットボット経由で質問すると、ユーザーの IP がレート制限に対してチェックされ、Upstash Redis 経由でキャッシュされていない場合は、OpenAI API から応答が検索され(その後キャッシュされ)、ユーザーにストリーミングされます
- 管理者が指定された URL セットで既存のモデルのトレーニングをリクエストすると、Upstash の QStash を利用して、指定された遅延の後にサーバーレスで POST リクエストが行われ、指定された URL のコンテンツを取得し、(バックグラウンドで)モデルを更新します
Next.js でチャットとトレーニング API ルートをセットアップする
このセクションでは、ルート pages/api/chat.js を設定する方法について説明します。 クロスオリジンリクエストを有効にし、チャット API 呼び出しのレート制限を行い、ユーザーへのレスポンスをキャッシュしてストリーミングし、特定の URL でコンテンツトレーニングをスケジュールするメソッドを公開します。pages/api/train.js 指定された URL に対してのみ、バックグラウンドでトレーニングを実行します。
1. CORS を有効にする
cors を使用する パッケージでは、アプリケーションの CORS を有効にして、チャットボットを複数の場所 (Web サイト上のボットなど) で使用できるようにしました。 API ルートが初期化されるとすぐに、以下のように cors セットアップを実行します 👇🏻
// File: pages/api/chat.js
// Reference Function to cors
import { runMiddleware } from '@/lib/cors'
export default async function (req, res) {
try {
// Run the middleware
await runMiddleware(req, res)
// ...
catch (e) {
console.log(e.message || e.toString())
}
return res.end()
}
// Cors Function
// File: lib/cors.js
import Cors from 'cors'
// Initializing the cors middleware
// You can read more about the available options here: https://github.com/expressjs/cors#configuration-options
const cors = Cors({
methods: ['POST', 'OPTIONS', 'HEAD'],
})
// Helper method to wait for a middleware to execute before continuing
// And to throw an error when an error happens in a middleware
export function runMiddleware(req, res, fn = cors) {
return new Promise((resolve, reject) => {
fn(req, res, (result) => {
if (result instanceof Error) return reject(result)
return resolve(result)
})
})
}2.指定された URL でコンテンツ トレーニング リクエストをスケジュールする
Upstash QStash を使用すると、Fire and Forget のような API を作成できます。応答を取得するために main 関数が完了するのを積極的に待つ必要はなく、むしろバックグラウンドで (オプションで一定の遅延の後) 実行します。これは cron ジョブに似ていますが、スケジュールされた間隔で定期的に実行されるのではなく、リクエストごとに実行されます。
同じチャット API ルートで、admin-key を持つリクエストを受け入れます。 ヘッダーとそれがサーバー側の秘密 (ADMIN_KEY) と一致するかどうか )、ある程度の遅延の後に、リクエスト本文で渡された一連の URL に対するコンテンツ トレーニングをスケジュールします (ここでは 10s) )。設定された遅延後のコンテンツ トレーニング リクエストは、指定されたエンドポイント (ここでは https://custom-content-ai-chatbot.fly.dev/api/train) に対して行われます。 )
// File: pages/api/chat.js
// If the headers contain an `admin-key` header
if (req.headers['admin-key'] === process.env.ADMIN_KEY) {
// If `urls` is not in body, return with `Bad Request`
if (!req.body.urls) return res.status(400).send('No urls to train on.')
// Hit QStash API to train on this set of URLs after 10 seconds from now
await qstashClient.publishJSON({
delay: 10,
body: { urls: req.body.urls },
url: 'https://custom-content-ai-chatbot.fly.dev/api/train'
})
return res.status(200).end()
}
ここで、train API ルート (pages/api/train.js) の内容を詳しく見てみましょう。 ) 👇🏻
// File: pages/api/train.js
import train from '@/lib/train'
import * as dotenv from 'dotenv'
import { redis } from '@/lib/redis'
import { runMiddleware } from '@/lib/cors'
import { verifySignature } from '@upstash/qstash/nextjs'
dotenv.config()
// Disabling converting request body to JSON directly
// More on https://nextjs.org/docs/pages/building-your-application/routing/api-routes#custom-config
export const config = {
api: {
bodyParser: false,
},
}
async function handler(req, res) {
try {
// Run the middleware
await runMiddleware(req, res)
// If method is not POST, return with `Forbidden Access`
if (req.method !== 'POST') return res.status(403).send('No other methods allowed.')
// If `urls` is not in body, return with `Bad Request`
if (!req.body.urls) return res.status(400).send('No urls to train on.')
// Train on the particular URLs
await train(req.body.urls)
// Once saved, clear all the responses in Upstash
let allKeys = await redis.keys('*')
if (allKeys) {
// Filter out the keys to not have the ratelimiter ones
allKeys = allKeys.filter((i) => !i.includes('@upstash/ratelimit:'))
const p = redis.pipeline()
// Create a pipeline to clear out all the keys
allKeys.forEach((i) => p.del(i))
// Execute the pipeline commands in a transaction
await p.exec()
console.log('Cleaned cached responses in Upstash.')
}
return res.status(200).end()
} catch (e) {
console.log(e.message || e.toString())
}
return res.end()
}
// Verify the incoming request to be a valid
// QStash Scheduled POST request with Upstash-Signature
export default verifySignature(handler)上記のコードでは、3 つの重要なアクションを実行しています。
- QStash の
verifySignatureを使用して受信リクエストの検証を実行する 方法。以下はUpstash-Signatureを探します。 ヘッダーを検証し、受け取った生の本文で検証します。 trainに電話します。 URL コンテンツの取得と既存のベクター ストアへの追加 (および保存) を行う関数。- Redis トランザクションを介したレート制限の実装に関連するキーをフィルタリングした後、Upstash Redis でキャッシュされた応答をクリアします。
3.レート制限
レート制限を実装するには、Upstash Redis データベース クライアントと @upstash/ratelimit というレート リミッター ライブラリを使用します。 .
// File: lib/redis.js
// Reference Function to ratelimiting
import * as dotenv from 'dotenv'
import { Redis } from '@upstash/redis'
import { Ratelimit } from '@upstash/ratelimit'
// Load environment variables
dotenv.config()
// Initialize Upstash Redis
export const redis = new Redis({
url: process.env.UPSTASH_REDIS_REST_URL,
token: process.env.UPSTASH_REDIS_REST_TOKEN,
})
// Initialize Upstash Rate Limiter
export const ratelimit = {
chat: new Ratelimit({
redis,
// Limit requests to 30 questions per day per IP Address
limiter: Ratelimit.slidingWindow(30, '86400s'),
}),
}
レート制限を使用すると、完全に無料で公開されたサービスを利用できるようになりました。 これにより、システムの利点、つまりチャットの応答を紹介することができました。文字通り、誰でもウェブサイトから 1 日に 30 件の質問をすることができます。 IP address に基づいて、1 日あたり 30 件の質問のレート制限を適用できます。
// File: pages/api/chat.js
import requestIp from 'request-ip'
import { ratelimit } from '@/lib/redis'
// ...
// Get the client IP
const detectedIp = requestIp.getClientIp(req)
// If no IP detected, return with a `Bad Request`
if (!detectedIp) return res.status(400).send('Bad request.')
// Check the Rate Limit
const result = await ratelimit.chat.limit(detectedIp)
// If rate limited, return with the same
if (!result.success) return res.status(400).send('Rate limit exceeded.')
// Continue with serving the chat responses4.保存されたインデックス付きベクトル ストアをロードし、OpenAI に応答を要求します
すべてのチェックが完了したら、カスタム コンテンツを使用して OpenAI API を呼び出し、ユーザーに応答を送信するという主要な作業に進みます。話を単純化するために、これをさらに複数の部分に分割します。
- 3.1:保存されたベクター ストアの取得
// File: pages/api/chat.js
// Reference Function to loadVectorStore
import { loadVectorStore } from '@/lib/vectorStore'
// Load the trained model
const vectorStore = await loadVectorStore()
// ...
// Vectore Store Function
// File: lib/vectorStore.js
import { join } from 'path'
import { existsSync } from 'fs'
import { Document } from 'langchain/document'
import { FaissStore } from 'langchain/vectorstores/faiss'
import { OpenAIEmbeddings } from 'langchain/embeddings/openai'
export async function loadVectorStore() {
const directory = join(process.cwd(), 'loadedVectorStore')
const docStoreJSON = join(process.cwd(), 'loadedVectorStore', 'docstore.json')
if (existsSync(docStoreJSON)) {
// If the directory is found, load the vector store saved by Faiss integration
return await FaissStore.load(directory, new OpenAIEmbeddings())
} else {
// If no content is there, load the vector store with just `Hey` for starters
return await FaissStore.fromDocuments([new Document({ pageContent: 'Hey' })], new OpenAIEmbeddings())
}
}- 3.2:ユーザーのクエリにプロンプト ガイドラインを追加する
LangChain の PromptTemplate を使用して、ユーザー クエリとともに、AI が質問に答える方法と方法についての指示を渡します。
// File: pages/api/chat.js
import { z } from 'zod'
import { PromptTemplate } from 'langchain/prompts'
import { RetrievalQAChain } from 'langchain/chains'
import { OutputFixingParser, StructuredOutputParser } from 'langchain/output_parsers'
// Load the trained model
// ...
// Create a prompt specifying for OpenAI what to write
const outputParser = StructuredOutputParser.fromZodSchema(
z.object({
answer: z.string().describe('answer to question in HTML friendly format, use all of the tags wherever possible and including reference links'),
}),
)
// ...
// Create an instance of output parser class to help refine the response of OpenAI
const outputFixingParser = OutputFixingParser.fromLLM(model, outputParser)
// Create a prompt specifying for OpenAI how to process on the input
const prompt = new PromptTemplate({
template: `Answer the user's question as best and be as detailed as possible:\n{format_instructions}\n{query}`,
inputVariables: ['query'],
partialVariables: {
format_instructions: outputFixingParser.getFormatInstructions(),
},
})
// Pass the prompt to the query with the model to OpenAI API
const chain = RetrievalQAChain.fromLLM(model, vectorStore.asRetriever(), prompt)- 3.3:応答のストリーミングとキャッシュ
Upstash Redis で応答をキャッシュするには、UpstashRedisCache を使用します。 LangChainによるキャッシュライブラリ。既存の Redis インスタンスをクライアントとして渡し、キャッシュ ハンドラーを ChatOpenAI に渡します。 応答が配信された後にそれをキャッシュするために使用するラッパー:
// File: pages/api/chat.js
import { redis } from '@/lib/redis'
import { ChatOpenAI } from 'langchain/chat_models/openai'
import { UpstashRedisCache } from 'langchain/cache/upstash_redis'
// Load the trained model
// ...
// Create Upstash caching
const upstashRedisCache = new UpstashRedisCache({ client: redis })
// A flag to detect if response was not cached
let doesToken = false
const model = new ChatOpenAI({
// Enable streaming to return responses to user as quickly possible
streaming: true,
// Cache responses using Upstash Redis cache client
cache: upstashRedisCache,
callbacks: [
{
handleLLMNewToken(token) {
// Set the flag to true if we receive stream from OpenAI
doesToken = true
// Stream the token to the user
res.write(token)
},
},
],
})
// Create a LLM QA Chain
// ...
// Store the output to refer to in case cached
const chainOutput = await chain.call({ query: req.body.input })
// If no tokens received implies that the content is cached
// Return the cached response as is
if (!doesToken) return res.status(200).send(chainOutput.text)とても勉強になりました!これですべて完了です。
Fly.io に展開
リポジトリには、特に以下に関連する Fly.io の組み込みセットアップが付属しています。
- Dockerfile
- fly.toml
- .dockerignore
デプロイには Fly.io のアカウントが必要です。 アカウントを取得したら、プロジェクトのルート フォルダーで次のコマンドを実行して、Fly.io でアプリを作成できます。
# Create an app based on the baked-in configuration in your account
# This will result only in the change of app name in existing fly.toml
fly launchそして 👇🏻
経由でデプロイします# Deploy the app based on the configuration created above
fly deployこれで展開は完了です。はい、それだけです。
結論
結論として、このプロジェクトは、ニーズに合わせて拡張できるサービス (Upstash など) を使用しながら、OpenAI 応答キャッシュ、レート制限、スケジュールされた API リクエストを実装してモデルをトレーニングするという貴重な経験を提供しました。
Next.js 、Redis 、TailwindCSS 、LangChain 、Serverless Scheduling
-
負荷分散セットアップで Redis キャッシュを使用した Azure App Service での効率的なセッション管理
従来のロード バランシング環境でのセッション 一般に、すべての Web アプリケーションではインメモリ セッション (RAM に保存されたデータ) を使用します。これは、専用 VM または共有ホスティング プランでアプリケーションをホストする従来のホスティング環境のほとんどでうまく機能します。 ただし、トラフィックが増加した場合は、複数の Web サーバーを作成し、ロード バランサーを使用してトラフィックを制御することで負荷分散を計画します。これらのシナリオでは、リクエスト (単一セッションに関連する) が複数のサーバーによって処理されるため、セッションは機能しません (同じサーバーで単一
-
RedisとApacheKafkaを使用した時系列データの処理
RedisTimeSeriesは、ネイティブの時系列データ構造をRedisにもたらすRedisモジュールです。以前に並べ替えられたセット(またはRedisストリーム)の上に構築された時系列ソリューションは、大量の挿入、低レイテンシの読み取り、柔軟なクエリ言語、ダウンサンプリングなどのRedisTimeSeries機能の恩恵を受けることができます! 一般的に、時系列データは(比較的)単純です。そうは言っても、他の特性も考慮する必要があります。 データ速度:例: 1秒あたり数千のデバイスからの数百のメトリックを考えてください ボリューム(ビッグデータ):数か月(さらには数年)にわたるデータの蓄