切断、更新、クラッシュが発生しても持続する回復力のある LLM ストリームを作成する
私たちが構築しているもの
この記事では、簡単に存続できる非常に耐久性の高い LLM ストリームを構築します。
- ネットワーク障害
- ページが更新されます
- ウェブサイトの閉鎖
- ノートパソコンの蓋を閉める
ボーナス:複数のデバイス (携帯電話やラップトップなど) で同時に同じストリームを表示できます。 .
ストリームを中断しようとしても、接続が切断されている間はバックグラウンドで継続され、戻った後もスムーズに継続されます。これは信じられないほどです。 ユーザーエクスペリエンス。
耐久性のある LLM ストリームのデモ 👇
インスピレーション
AI を使用して構築する場合、AI 応答をリアルタイムでストリーミングすることがベスト プラクティスです。
ユーザーは応答全体を待つ代わりに、生成されたコンテンツをリアルタイムで確認できます。これは UX にとって素晴らしいことです。 Vercel の AI SDK などのツールを使用すると、これが非常に簡単になります。
import { openai } from "@ai-sdk/openai";
import { streamText } from "ai";
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt: "Invent a new holiday and describe its traditions.",
});リアルタイム LLM ストリームを技術レベルで機能させるには、クライアントを API に接続し、Server Sent Events (SSE) などのプロトコルを使用してデータをストリームバックします。
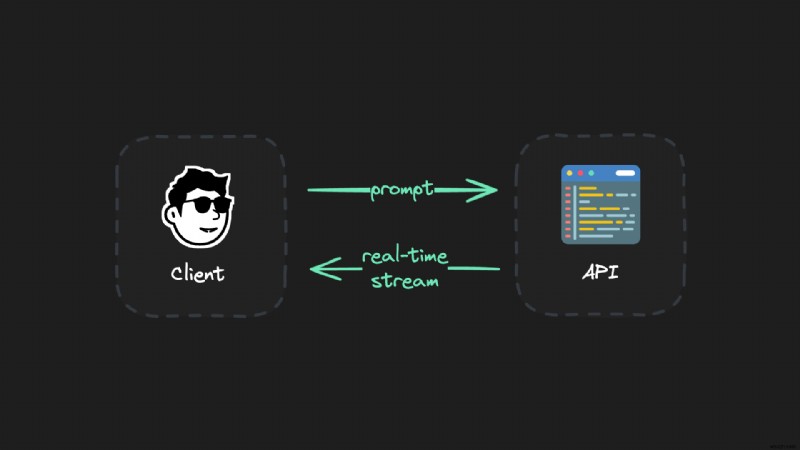
しかし:この設定には問題があります。
ストリーム中にインターネットの切断、ラップトップの蓋を閉めた、ネットワークの障害などの何かが発生すると、世代全体が失われます。もう一度やり直して、世代全体を再度待つ必要があります。これは、世代が長い場合 (O1 などの実行コストの高いモデルなど)、特に迷惑です。
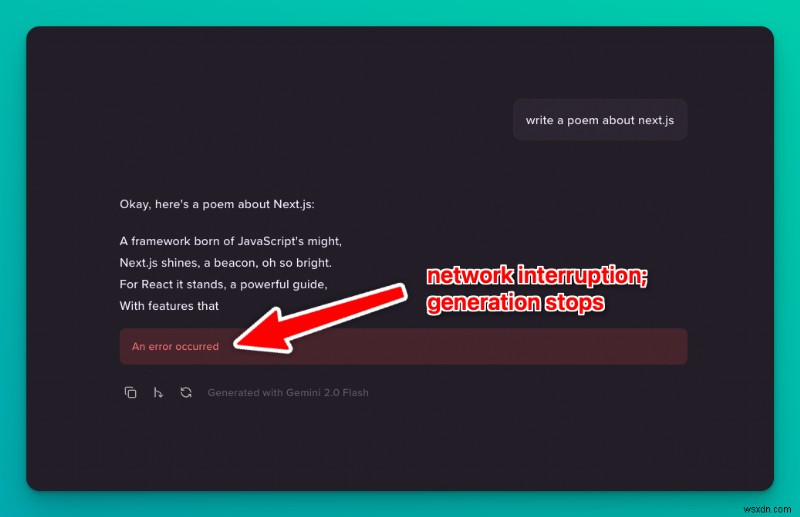
明らかに、この問題は人々の注目を集めています。信頼性の高いリアルタイム LLM ストリーミングに対する実際の需要があり、より多くの開発者がそれを機能させる方法を実験しています。
高耐久性 LLM ストリームの構築
真に耐久性があり、再開可能な LLM ストリームを作成する秘訣は、クライアントを生成環境から分離することです。クライアント接続は不安定で、ラップトップを閉じる、ネットワークの問題、ページを更新するなど、さまざまな理由で切断される可能性があります。
クライアントプロセスと生成プロセスを分離しておくことにより、生成は常に中断されることなく継続されます。クライアントは、進行中の生成を中断することなく、いつでも再接続できます。
悪い考え:永続的な直接接続:
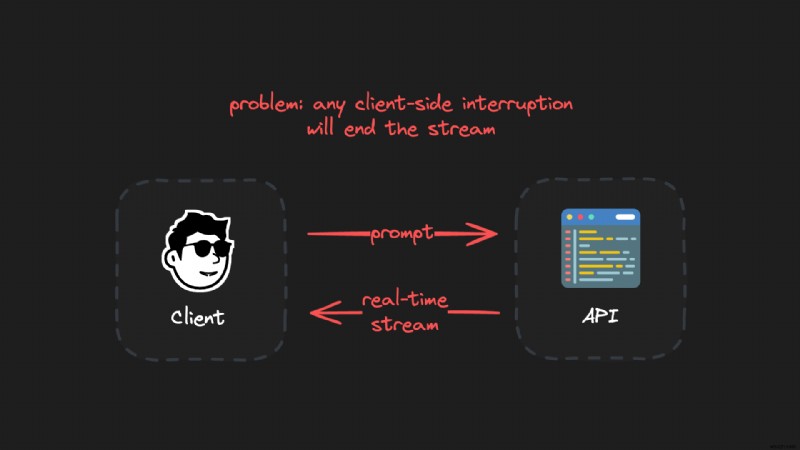
良いアイデア:交換可能で中断可能なストリーム接続:
そしてそうです - このアーキテクチャは、単純な AI ストリームにとってはかなり複雑に見えるかもしれません。ただし、今のコードを見るとわかるように、これはわずか数行のコードであり、実装には数分かかります。
永続ストリームの設定
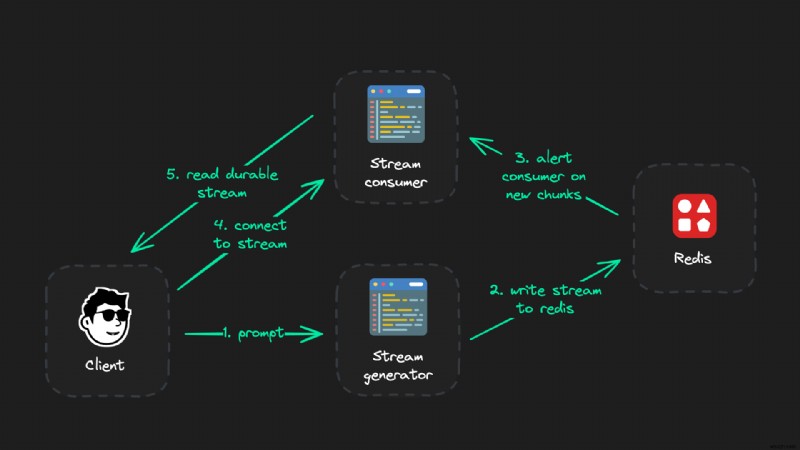
非常に信頼性の高い LLM ストリームのセットアップは 3 つの部分で構成されます。
- クライアント (フロントエンド)
- ストリームジェネレーター (API ルート)
- ストリーム コンシューマ (API ルートでもあります)
クライアントへの直接接続はすべて、いつでも中断または一時停止できます。したがって、LLM 出力ストリームの生成を担当するロジック部分 (ストリーム ジェネレーター) は、クライアントへのアクティブな接続を持たない独立した API である必要があります。
代わりに、コンシューマを介してクライアントに接続します。コンシューマは Redis からデータを読み取るだけで、それ以外の点ではかなり「愚か」です。その唯一の目的は、クライアントがジェネレーターに接続するたびに、ジェネレーターの出力を読み取り、クライアントがまだ見ていないすべての LLM チャンクを提供することです。以上です。
簡単な概要 - 各部分の機能:
- クライアント: ストリーム ジェネレーターをトリガーし (ただし、オープンな接続は維持しません)、リアルタイム ストリームをレンダリングします
- ストリーム ジェネレーター: LLM 出力をリアルタイムで生成し、Redis に公開します
- ストリームコンシューマー: ジェネレーターのストリームを読み取り、チャンクをクライアントにプッシュします
ジェネレーターは、LLM ストリームを読み取り、それをリアルタイムで Redis に公開することのみを担当します。クライアントからストリーム コンシューマへの、終了や再接続などが可能な置換可能な接続を取得します。ストリーム ジェネレータには何も影響しません。
コード例
このセクションでは、コードを見ていきます。原則を明確にするために、最後に実際の完全な製品コードの実装を見ていきます。
現時点では、コード ファイル全体ではなく、コア スニペットとその目的に注目すると、コードを理解しやすくなります。
1.クライアント
クライアントの責任は 3 つだけです。
- セッション ID の生成
- ジェネレーターをトリガーする
- 生成ストリームのレンダリング
それぞれを見てみましょう:
クライアント:セッション ID を生成しています
クライアントがストリームに接続または再接続するとき、クライアントがまだ見ていないすべてのメッセージを送信したいと考えています。つまり、アクティブなストリーム中、各メッセージにはストリーム全体ではなく、クライアントが参照する必要がある正確なデルタのみが含まれます。
再接続すると、現在の生成ポイントまでのストリーム全体が送信され、将来のすべてのイベントへのサブスクリプションは、チャンクが失われることなく完全にシームレスになります。
どうやって
リアルタイム データを効率的に保存および取得する方法である Redis Streams には、コンシューマー グループと呼ばれるものを通じて、このまだ見られない機能が組み込まれています。私たちがしなければならない唯一のことは、各クライアントに一意のセッションがあることを確認することです。つまり、各世代に一意の ID を割り当てます。
コンシューマ グループについては、ストリーム コンシューマを確認するときにさらに詳しく学びます。それらは次のようになります:
await redis.xgroup("redis-key", {
type: "CREATE",
group: "my-group-name",
id: "0",
});どのクライアントがどのストリームをどの時点まで見たのか、 どの部分が欠落しているのかというロジック全体は完全に Redis ストリームによって処理されます。 精度が保証されています。 LLM チャンクが欠落することはなく、常にクライアントが必要とするデータを正確に送信します。
現時点でクライアントが行う必要があるのは、世代ごとに ID を割り当てることだけです。単純に nanoid を使用します。 :
import { customAlphabet } from "nanoid"
const nanoid = customAlphabet("0123456789", 6);クライアント:生成ストリームのトリガー
クライアントが生成エンジンに対して行う唯一の対話は、生成エンジンをトリガーすることです。ただし、技術的には、他の場所 (CRON ジョブ、自動パイプラインなど) から生成をトリガーすることもできます。
最も単純な形式では、これは生成 API ルートへの単なるフェッチ呼び出しです。
// 👇 trigger stream generator
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId }),
});クライアント:生成ストリームの読み取り
生成をトリガーした後、ジェネレーターは、クライアントから完全に分離された集中型 Redis ストアへの LLM 出力のストリーミングを開始します。ストリーム コンシューマに接続して、生成ストリームを読み取りましょう:
// 👇 connect to stream consumer
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
});以上です!
これらはクライアントの 3 つの責任です。もちろん、ID 生成のためのカスタム フック、信頼性を高めるための反応クエリなどを使用して、さらに複雑にすることもできます。これについては、後で完全なコード例で説明します。
2.ストリームジェネレーター
ストリーム ジェネレーターは LLM ストリームを開き、各チャンクを Redis ストリームに書き込みます。書き込まれたチャンクごとにメッセージを発行して、リアルタイム更新の新しいデータについてストリーム コンシューマーに警告します。
注:繰り返しますが、これは意図的に完全なコード例ではありません。最後に完全なコードを見ていきます。これは概念を理解するためです。
import { streamText } from "ai"
import { redis } from "@/utils"
const result = await new Promise(
async (resolve, reject) => {
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
// ...
}),
})
for await (const chunk of textStream) {
if (chunk) {
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
}
// 👇 write chunk to redis stream
await redis.xadd(streamKey, "*", chunkMessage)
// 👇 alert consumer that there's a new chunk
await redis.publish(streamKey, { type: MessageType.CHUNK })
}
}
}
)3.ストリーム コンシューマ
ストリーム コンシューマーは Redis に接続し、Redis pub/sub 経由で新しいチャンク アラートをリッスンします。各クライアントは独自のコンシューマ グループを取得して、表示されたメッセージと未表示のメッセージを追跡します。
注:パブリッシュは実際のチャンクを転送するのではなく、新しいチャンクがストリームで利用可能であることを警告するだけです。
新しいチャンクが利用可能になると、ストリーム コンシューマー API はそれをストリームから読み取り、接続されているすべてのクライアントに転送します。 Redis コンシューマ グループは、各クライアントが確認した内容を追跡して、重複したチャンクや欠落したチャンクが転送されないことを保証します。
コア ストリーム コンシューマは次のようになります。
const streamKey = `llm:stream:${sessionId}`;
const groupName = `sse-group-${nanoid()}`;
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
});
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
// 👇 built-in Redis stream functionality: only send unseen messages
">",
)) as StreamData[];
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0];
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields);
const validatedMessage = validateMessage(rawObj);
if (validatedMessage) {
controller.enqueue(json(validatedMessage));
}
}
}
};
// 👇 initial read
await readStreamMessages();
const subscription = redis.subscribe(streamKey);
subscription.on("message", async () => {
// 👇 read every time a new chunk is written to stream
await readStreamMessages();
});注:すべての接続でコンシューマ グループを作成しています。 Redis はこの操作をべき等に処理するため、これは非常にうまく機能します。グループがすでに存在する場合は何も起こりません。
完全なコード
セッション ID の生成
これまで、クライアントのタスク、ストリーム ジェネレーター、ストリーム コンシューマーを個別に理解するために、個々のコードを検討してきました。ここで、完全な実装を見て、これらの部分がどのように組み合わされるかを見てみましょう。
まず、sessionId を作成すると、単に nanoid() を使用するよりも回復力が高くなります。 。結局のところ、Web サイトが更新されたり閉じられたりしたらどうなるでしょうか?再接続時に、生成された sessionId をどこかに保存しないと失われます。生成が実行されている限り保持しておく必要があります。
幸いなことに localStorage はこれに最適です:
import { customAlphabet } from "nanoid";
import { useRouter } from "next/navigation";
import { useCallback, useEffect, useState } from "react";
export const useLLMSession = () => {
const [sessionId, setSessionId] = useState<string>("");
const router = useRouter();
const nanoid = customAlphabet("0123456789", 6);
const updateUrlWithSessionId = useCallback(
(id: string) => {
const url = new URL(window.location.href);
url.searchParams.set("sessionId", id);
router.replace(url.toString(), { scroll: false });
},
[router],
);
useEffect(() => {
const urlParams = new URLSearchParams(window.location.search);
const urlSessionId = urlParams.get("sessionId");
const storedSessionId = localStorage.getItem("llm-session-id");
if (urlSessionId) {
localStorage.setItem("llm-session-id", urlSessionId);
setSessionId(urlSessionId);
} else if (storedSessionId) {
setSessionId(storedSessionId);
updateUrlWithSessionId(storedSessionId);
} else {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
}
// eslint-disable-next-line react-hooks/exhaustive-deps
}, []);
const clearSessionId = useCallback(() => {
localStorage.removeItem("llm-session-id");
setSessionId("");
const url = new URL(window.location.href);
url.searchParams.delete("sessionId");
router.replace(url.toString(), { scroll: false });
}, [router]);
const regenerateSessionId = () => {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
return newSessionId;
};
return {
sessionId,
regenerateSessionId,
clearSessionId,
};
};クライアント
クライアントの 2 つの最も重要な部分、ストリームの開始とストリームへの接続についてはすでに説明しました。ジェネレーターが実行中であるという API からの確認を取得したら、react-queries refetch を使用してストリームに接続します。 接続クエリを呼び出すユーティリティ。
すべての要素がどのように組み合わされるかは次のとおりです。
app/page.tsx"use client"
import { useLLMSession } from "@/use-llm-session"
import { useMutation, useQuery } from "@tanstack/react-query"
import { FormEvent, useRef, useState, useEffect } from "react"
import {
MessageType,
validateMessage,
type ChunkMessage,
type MetadataMessage,
StreamStatus,
} from "@/lib/message-schema"
// precondition = stream is ready to read
class PreconditionFailedError extends Error {
constructor(message: string) {
super(message)
this.name = "PreconditionFailedError"
}
}
export default function Home() {
const { sessionId, regenerateSessionId, clearSessionId } = useLLMSession()
const [prompt, setPrompt] = useState("")
const [status, setStatus] = useState<
"idle" | "loading" | "streaming" | "completed" | "error"
>("idle")
const [response, setResponse] = useState("")
const [chunkCount, setChunkCount] = useState(0)
const controller = useRef<AbortController | null>(null)
const responseRef = useRef<HTMLDivElement>(null)
const isInitialRequest = useRef(true)
// keep generation in viewport
useEffect(() => {
if (responseRef.current) {
responseRef.current.scrollTop = responseRef.current.scrollHeight
}
}, [response])
// start generator
const { mutate, error, isIdle } = useMutation({
mutationFn: async (newSessionId: string) => {
controller.current?.abort()
isInitialRequest.current = false
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId: newSessionId }),
})
},
onSuccess: () => {
setStatus("streaming")
refetch()
},
})
// connect to running stream
const { refetch } = useQuery({
queryKey: ["stream", sessionId],
queryFn: async () => {
if (!sessionId) return null
setResponse("")
setChunkCount(0)
const abortController = new AbortController()
controller.current = abortController
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
signal: controller.current.signal,
})
if (res.status === 412) {
// stream is not yet ready, retry connection
throw new PreconditionFailedError("Stream not ready yet")
}
if (!res.body) return null
const reader = res.body.pipeThrough(new TextDecoderStream()).getReader()
let streamContent = ""
while (true) {
const { value, done } = await reader.read()
if (done) break
if (value) {
const messages = value.split("\n\n").filter(Boolean)
for (const message of messages) {
if (message.startsWith("data: ")) {
const data = message.slice(6)
try {
const parsedData = JSON.parse(data)
const validatedMessage = validateMessage(parsedData)
if (!validatedMessage) continue
switch (validatedMessage.type) {
case MessageType.CHUNK:
const chunkMessage = validatedMessage as ChunkMessage
streamContent += chunkMessage.content
setResponse((prev) => prev + chunkMessage.content)
setChunkCount((prev) => prev + 1)
break
case MessageType.METADATA:
const metadataMessage = validatedMessage as MetadataMessage
if (metadataMessage.status === StreamStatus.COMPLETED) {
setStatus("completed")
}
break
case MessageType.ERROR:
setStatus("error")
break
}
} catch (e) {
console.error("Failed to parse message:", e)
}
}
}
}
}
return streamContent
},
refetchOnWindowFocus: false,
refetchOnMount: false,
retry(failureCount, error) {
if (isInitialRequest.current === true) return false
if (error instanceof PreconditionFailedError) {
return failureCount < 10
}
return false
},
})
const handleSubmit = async (e: FormEvent) => {
e.preventDefault()
setStatus("loading")
const newSessionId = regenerateSessionId()
mutate(newSessionId)
}
const handleReset = () => {
controller.current?.abort()
clearSessionId()
setPrompt("")
setResponse("")
setChunkCount(0)
setStatus("idle")
}
return (
<main className="flex min-h-screen flex-col items-center justify-between p-12 sm:p-24">
<div className="z-10 max-w-5xl w-full items-center justify-between font-mono text-sm">
<h1 className="text-4xl tracking-tight font-bold mb-8 text-center">
Resumable LLM Stream
</h1>
<form onSubmit={handleSubmit} className="mb-8">
<div className="mb-4">
<label htmlFor="prompt" className="block text-sm font-medium mb-2">
Enter your prompt:
</label>
<textarea
autoFocus
id="prompt"
value={prompt}
onChange={(e) => setPrompt(e.target.value)}
className="w-full p-2 border border-zinc-700 rounded-md min-h-[100px] focus:outline-none focus:ring-2 focus:ring-blue-500 focus:border-transparent transition-all duration-200"
placeholder="Ask the AI something..."
disabled={status === "loading" || status === "streaming"}
/>
</div>
<div className="flex gap-4">
<button
type="submit"
disabled={status === "loading" || status === "streaming"}
className="px-4 py-2 bg-blue-600 text-white rounded-md hover:bg-blue-700 disabled:bg-gray-400"
>
{status === "loading"
? "Starting..."
: status === "streaming"
? "Streaming..."
: "Generate Response"}
</button>
<button
type="button"
onClick={handleReset}
className="px-4 py-2 bg-zinc-600 text-white rounded-md hover:bg-zinc-700"
>
Reset
</button>
</div>
</form>
<div className="mt-8">
<h2 className="text-xl tracking-tight font-semibold mb-2">
Response:
</h2>
{status === "error" ? (
<div className="p-4 bg-red-100 border border-red-300 rounded-md text-red-800">
<p className="font-bold">Error:</p>
<p>{error?.message}</p>
</div>
) : status === "idle" && !response ? (
<p className="text-gray-500">
Enter a prompt and click "Generate Response" to see the AI's
response.
</p>
) : (
<div
ref={responseRef}
className="flex flex-col h-96 overflow-y-auto p-4 bg-zinc-900 text-zinc-200 border border-zinc-800 rounded-md whitespace-pre-wrap [&::-webkit-scrollbar]:w-2 [&::-webkit-scrollbar-thumb]:bg-zinc-700 [&::-webkit-scrollbar-track]:bg-zinc-800"
>
<div>{response || "Loading..."}</div>
</div>
)}
{(status === "streaming" || status === "completed") && (
<div className="mt-2 text-sm text-gray-500">
<p>Session ID: {sessionId}</p>
<p>Status: {status}</p>
<p>Chunks received: {chunkCount}</p>
<p>
Connection: {status === "streaming" ? "Active SSE" : "Closed"}
</p>
</div>
)}
</div>
</div>
</main>
)
}ストリーム ジェネレーター
ストリーム ジェネレーターのコード全体は次のとおりです。 LLM の生成がどこかの時点で失敗した場合、信頼性を最大限に高めるために、Upstash ワークフローを使用して自動的に再試行されます。
api/llm-stream/route.tsimport {
MessageType,
StreamStatus,
type ChunkMessage,
type MetadataMessage,
} from "@/lib/message-schema";
import { redis } from "@/utils";
import { openai } from "@ai-sdk/openai";
import { serve } from "@upstash/workflow/nextjs";
import { streamText } from "ai";
interface LLMStreamResponse {
success: boolean;
sessionId: string;
totalChunks: number;
fullContent: string;
}
export const { POST } = serve(async (context) => {
const { prompt, sessionId } = context.requestPayload as {
prompt?: string;
sessionId?: string;
};
if (!prompt || !sessionId) {
throw new Error("Prompt and sessionId are required");
}
const streamKey = `llm:stream:${sessionId}`;
await context.run("mark-stream-start", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.STARTED,
completedAt: new Date().toISOString(),
totalChunks: 0,
fullContent: "",
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
const res = await context.run("generate-llm-response", async () => {
const result = await new Promise<LLMStreamResponse>(
async (resolve, reject) => {
let fullContent = "";
let chunkIndex = 0;
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
success: true,
sessionId,
totalChunks: chunkIndex,
fullContent,
});
},
});
for await (const chunk of textStream) {
if (chunk) {
fullContent += chunk;
chunkIndex++;
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
};
await redis.xadd(streamKey, "*", chunkMessage);
await redis.publish(streamKey, { type: MessageType.CHUNK });
}
}
},
);
return result;
});
await context.run("mark-stream-end", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.COMPLETED,
completedAt: new Date().toISOString(),
totalChunks: res.totalChunks,
fullContent: res.fullContent,
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
});完全な型安全性を確保するために、すべてのメッセージ スキーマも zod で記述しました。
message-schema.tsimport { z } from "zod";
export const MessageType = {
CHUNK: "chunk",
METADATA: "metadata",
EVENT: "event",
ERROR: "error",
} as const;
export const StreamStatus = {
STARTED: "started",
STREAMING: "streaming",
COMPLETED: "completed",
ERROR: "error",
} as const;
export const baseMessageSchema = z.object({
type: z.enum([
MessageType.CHUNK,
MessageType.METADATA,
MessageType.EVENT,
MessageType.ERROR,
]),
});
export const chunkMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.CHUNK),
content: z.string(),
});
export const metadataMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.METADATA),
status: z.enum([
StreamStatus.STARTED,
StreamStatus.STREAMING,
StreamStatus.COMPLETED,
StreamStatus.ERROR,
]),
completedAt: z.string().optional(),
totalChunks: z.number().optional(),
fullContent: z.string().optional(),
error: z.string().optional(),
});
export const eventMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.EVENT),
});
export const errorMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.ERROR),
error: z.string(),
});
export const messageSchema = z.discriminatedUnion("type", [
chunkMessageSchema,
metadataMessageSchema,
eventMessageSchema,
errorMessageSchema,
]);
export type Message = z.infer<typeof messageSchema>;
export type ChunkMessage = z.infer<typeof chunkMessageSchema>;
export type MetadataMessage = z.infer<typeof metadataMessageSchema>;
export type EventMessage = z.infer<typeof eventMessageSchema>;
export type ErrorMessage = z.infer<typeof errorMessageSchema>;
export const validateMessage = (data: unknown): Message | null => {
const result = messageSchema.safeParse(data);
return result.success ? result.data : null;
};ストリームコンシューマ
最後に、完全なストリーム コンシューマの実装を見てみましょう。これは、クライアントが接続するときに、すべての目に見えないチャンクを自動的に送信する置換可能な接続です。
api/check-stream/route.tsimport { redis } from "@/utils"
import { nanoid } from "nanoid"
import { NextRequest, NextResponse } from "next/server"
import {
validateMessage,
MessageType,
type ErrorMessage,
} from "@/lib/message-schema"
export const dynamic = "force-dynamic"
export const maxDuration = 60
export const runtime = "nodejs"
type StreamField = string
type StreamMessage = [string, StreamField[]]
type StreamData = [string, StreamMessage[]]
const arrToObj = (arr: StreamField[]) => {
const obj: Record<string, string> = {}
for (let i = 0; i < arr.length; i += 2) {
obj[arr[i]] = arr[i + 1]
}
return obj
}
const json = (data: Record<string, unknown>) => {
return new TextEncoder().encode(`data: ${JSON.stringify(data)}\n\n`)
}
export async function GET(req: NextRequest) {
const { searchParams } = new URL(req.url)
const sessionId = searchParams.get("sessionId")
if (!sessionId) {
return NextResponse.json(
{ error: "Stream key is required" },
{ status: 400 }
)
}
const streamKey = `llm:stream:${sessionId}`
const groupName = `sse-group-${nanoid()}`
const keyExists = await redis.exists(streamKey)
if (!keyExists) {
return NextResponse.json(
{ error: "Stream does not (yet) exist" },
{ status: 412 }
)
}
try {
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
})
} catch (_err) {}
const response = new Response(
new ReadableStream({
async start(controller) {
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
">"
)) as StreamData[]
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0]
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields)
const validatedMessage = validateMessage(rawObj)
if (validatedMessage) {
controller.enqueue(json(validatedMessage))
}
}
}
}
await readStreamMessages()
const subscription = redis.subscribe(streamKey)
subscription.on("message", async () => {
await readStreamMessages()
})
subscription.on("error", (error) => {
console.error(`SSE subscription error on ${streamKey}:`, error)
const errorMessage: ErrorMessage = {
type: MessageType.ERROR,
error: error.message,
}
controller.enqueue(json(errorMessage))
controller.close()
})
req.signal.addEventListener("abort", () => {
console.log("Client disconnected, cleaning up subscription")
subscription.unsubscribe()
controller.close()
})
},
}),
{
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
},
}
)
return response
}簡単なまとめと最後の言葉
ネットワークの中断、ページの更新、さらには完全な切断にも対応できる、非常に堅牢な LLM ストリームを構築しました。私たちがやったことは次のとおりです。
-
生成と配信の分離: LLM の生成をクライアント接続から分離することで、クライアントの問題に関係なくコンテンツの生成が続行されます。
-
Redis ストリームを使用した永続ストレージ: 私たちは Redis ストリームを永続メッセージ ブローカーとして使用し、生成された LLM レスポンスの各チャンクを保存しています。
-
Redis Pub/Sub によるリアルタイム更新: 新しいチャンクが利用可能になったときにストリーム コンシューマに通知するために、Redis Pub/Sub を使用して通知システムを構築しました。
-
自動再接続: クライアントはいつでも再接続でき、すべてのコンテンツを自動的に受信し、重複やチャンクの欠落がないことが保証されます。これには、切断中に生成されたコンテンツが含まれます。
-
セッション管理: ユーザーが複数のデバイスで同時にストリームを視聴できるようにするセッション システムを作成しました。
要するに、私たちは現在、ユーザーに優れたユーザー エクスペリエンス (UX) を提供しています。特に LLM チャット サービスのようなものを構築している場合は、このアプローチを強くお勧めします。
読んで乾杯!フィードバックがある場合、または Upstash のゲスト著者になりたい場合は、josh@upstash.com までご連絡ください。 🙌
-
Redis GEOADD –地理空間値で要素を作成および追加する方法
このチュートリアルでは、キーに格納されている地理空間値に要素を作成して追加する方法について学習します。このために、Redis GEOADDを使用します コマンド。 GEOADDコマンド このコマンドは、キーに格納されている地理空間値に1つ以上の指定された地理空間メンバーを追加するために使用されます。地理空間値は、このコマンドを使用して入力されるソートされたセットに他なりません。地理空間メンバーは、GEORADIUSコマンドとGEORADIUSBYMEMBERコマンドを使用して半径によるクエリを使用して後でメンバーを取得できるように、並べ替えられたセットに追加されます。 並べ替えられたセ
-
RedisLaunchpadの紹介
Redisコミュニティは、常にRedisの優れた点の中心にあります。このグループのおかげで、Redisは5回連続で、StackOverflowの開発者調査で最も愛されているデータベースとして選ばれました。 Redisの人気が高まるにつれ、開発者コミュニティ、業界、地域全体のユースケースも増えます。 コミュニティの愛情を込めて、単一のビジョンを通じてRedisのパワーを強化、成長、活用することが、RedisLaunchpadを夢見た理由です。本日、Redisで私たちとあなたが構築した75以上のサンプルアプリケーションのハブであるRedisLaunchpadをご紹介します。 Redis Laun