Redisを使用したリアルタイム取引プラットフォームの構築
ポートフォリオは、資産運用業界の基盤を形成します。ハリー・マコウィッツが現代ポートフォリオ理論を開拓して以来、資産およびウェルスマネジメントの専門家は、特定のレベルのリスクに対してポートフォリオの収益を最大化することに夢中になっています。今日、業界の専門家には何百万もの個人投資家が加わり、投資の状況は一変しました。これらの新規参入者は、小売仲介業者、取引所、手形交換所の取引インフラストラクチャを支えるテクノロジーに大きな影響を与えています。
たとえば、2021年1月のGameStop株マニアを例にとってみましょう。個人投資家はGameStop株を記録的なレベルで取引し始めました。これらの投資家はAMCエンターテインメントのような他のミーム株にも積み重なっており、VIXで測定した場合、市場全体のボラティリティは数取引日で76%以上上昇しました。このボラティリティは、何千もの証券に価格圧力をもたらしました。何百万もの投資家が同時にポートフォリオに必死にアクセスしようとしましたが、需要に追いつかないアプリに直面していました。投資家は、アプリが最も必要なときにうまく機能しない企業には親切ではありません。
これらの必死の時代に、ほとんどの投資家は、常にアクセスする必要があるポートフォリオに関する2つのデータポイントを探しています。
- その時点でのポートフォリオの合計値はいくらですか?
- ポートフォリオ内の特定の証券の利益または損失は何ですか?
これらの質問への回答は、投資家が特定の証券を購入、売却、または保有するように導く可能性があります。今日の動きの速い市場では、遅延は機会と利益の損失を意味する可能性があります。これらの質問に答えるには、価格にリアルタイムでアクセスする必要がありますが、2つの大きな課題があります。
- 数千の証券の価格を同時に更新する
- 一度に何百万もの顧客の要求に答えます。
証券の価格は、取引量、特定の証券のボラティリティ、および市場のボラティリティに基づいて急速に変化する可能性があります。一方、証券会社には数百万の顧客がいる可能性があり、各顧客のポートフォリオには数十の証券があります。顧客がログインしたらすぐに、ポートフォリオを最新の価格で更新する必要があります。また、証券会社が取引所から価格を受け取るときに、ポートフォリオを最新の状態に保つ必要があります。
基本的に、リアルタイムの株価チャートを作成しています。多くの証券会社のアプリは、これを大規模に実行しようとはしていません。代わりに、これらのアプリは、何百万ものクライアントに価格をプッシュするのではなく、最新の価格をプルします。たとえば、ポートフォリオページに更新ボタンがある場合があります。
これらの次世代の課題は簡単ではなく、1秒あたり数百万の操作を処理するように設計されていないディスクベースのデータベースでは簡単に解決できません。金融業界の要件には、簡単に拡張でき、毎秒数億の操作を処理できるデータベースが必要です。インメモリデータベースプラットフォームであるRedisEnterpriseには、これらの無数の課題に取り組む可能性があります。

これは、金融業界のさまざまなリアルタイムのユースケースをカバーする一連のブログの最初のものです。各ユースケースの詳細とビジネス上の課題、およびそれらの課題を解決するためにRedisEnterpriseが果たすことができる役割について説明します。ブログの一部として、サンプルデザイン、データモデル、およびコードサンプルを提供しています。また、各アプローチの長所と短所についても説明します。
このブログ投稿では、次のことについて説明します。
- RedisEnterpriseでの高性能でスケーラブルな証券ポートフォリオデータモデルのサンプル実装。
- 証券会社が取引所から最新の価格を受け取るので、ポートフォリオ内の証券の価格をリアルタイムで更新します。
クライアントアプリがポートフォリオを取得し、最新の価格を受け取ると、次のことが可能になります。
- ポートフォリオのポートフォリオの合計値を計算します。
- 保有する各ポートフォリオの利益または損失を計算します。
証券ポートフォリオデータモデル
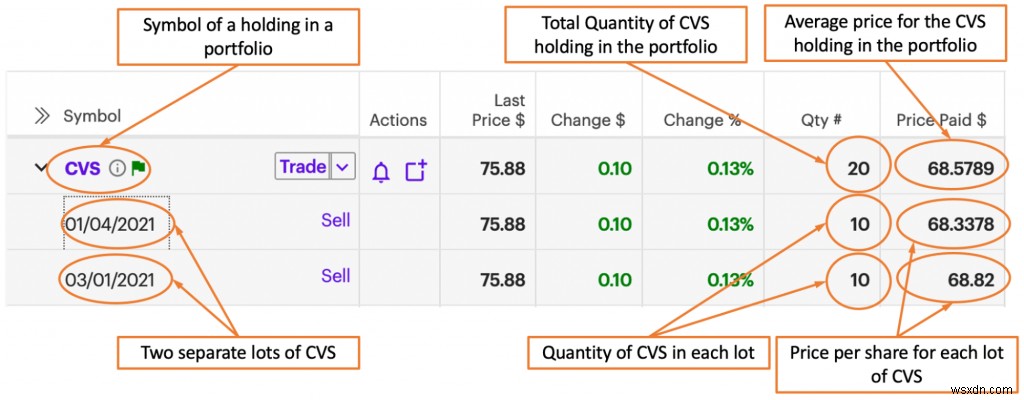
ポートフォリオの保有をモデル化することから始めましょう。下の図では、CVS Health Corp.(NYSE:CVS)が保有例の1つです。 CVSには2つの別々のロットがありました。1つ目は2021年1月4日に取得され、2つ目は2021年3月1日に取得されました。同じ数の株式が購入中に購入されました。 各ロットの取引。どちらの取引も10株でしたが、1株あたりの価格は異なります。 —最初のロットは68.3378ドル、2番目のロットは68.82ドル。ポートフォリオに保持されているCVSの総数は20で、平均コストは次のように計算されます:(($ 68.3378 * 10)+($ 68.82 * 10))/ 20=1株あたり$68.5789。
要件の実装
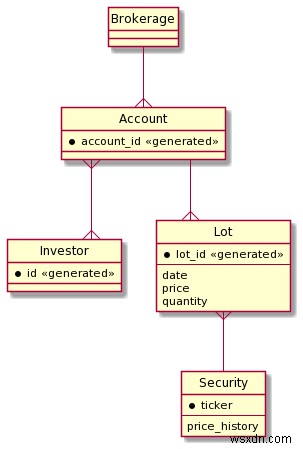
Redisのデータ表現はフラットです。たとえば、別のセット内にセットを埋め込むことはできません。したがって、ER図で記述されているデータモデルを必ずしも直接実装できるとは限りません。エンティティモデルを直接実装すると、望ましいパフォーマンス特性が得られない可能性があるため、実装に取り掛かるときは少し違った考え方をする必要があります。このセクションでは、Redisを使用して高性能でスケーリングの実装を設計する際に必要な基本的な設計原則のいくつかについて説明します。
ここでのデータモデルは、次のエンティティに言及しています。
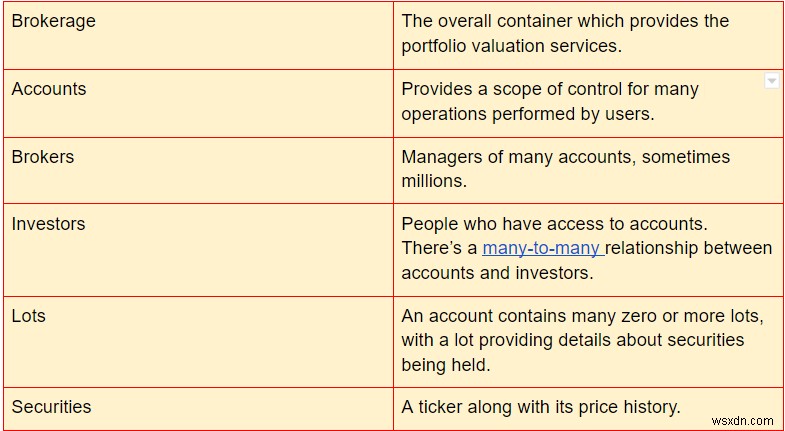
ERダイアグラムは、何が起こっているかを確認するのに役立つ視覚的な表現を提供します。
上の図に欠けているのは、証券の価格履歴に記録されているものの、入ってきた価格のセットと、瞬間的な価値と利益の計算です。 価格が変化するにつれて。したがって、ERダイアグラムは、ポートフォリオ評価が実行されるコンテキストである比較的静的なデータを表します。
全体的なアーキテクチャ
このシステムについて考慮する必要がある重要なポイントは次のとおりです。
- 適時性(つまり、待ち時間)は重要です。これが全体的な運転特性です。
- ポートフォリオの価値の計算では、アカウント固有のデータ(つまり、ロット情報)とアカウント間で共有されるデータ(つまり、証券価格)が組み合わされます。したがって、アカウント固有のデータは、共有データが使用されるコンテキストです。
- ポートフォリオの値は、投資家がオンラインになっているアカウント(アカウントの総数の一部)についてのみ計算する必要があります。
- データは、価格が生成される取引所からクライアントマシン(ブラウザ、携帯電話アプリケーション)に流れ、ポートフォリオの価値をオンライン投資家に提示します。
- ダイナミズムの高い特定の領域には、入力データフローの割合とオンライン投資家の数が含まれます。
これらの点を踏まえると、いくつかの一般的なアプローチは次のとおりです。
- 静的データと動的データの両方への低遅延アクセスについては、Redisのインメモリアーキテクチャに依存しています。
- Redisのデータ構造を使用してデータモデリングを最適化し、ゆっくりと変化するコンテキストデータへの迅速なアクセスを提供します。
- Redisの通信構造(ストリーム、コンシューマーグループ、Pub / Sub)を使用して、動的なデータ要件を処理します。
- システム全体のパフォーマンスに影響を与えることなく、データストレージを必要なものだけに削減します。
- クライアント自体にクライアント固有の計算を実装します。これは、オンライン投資家の数に応じて自然かつ自動的にスケーリングされ、スケールの負担を大幅に軽減します。
主な計算コンポーネントとデータフローは次のとおりです。

Redis Enterpriseは、オンプレミス、Kubernetes、ハイブリッドクラウド展開、マネージドサービス、ネイティブファーストパーティクラウドサービスなど、多くのマシンにまたがる1つ以上のノードで構成されており、クライアントとオンラインで数十万人の投資家がいることに注意してください。 )選択。
RedisEnterpriseコンポーネント
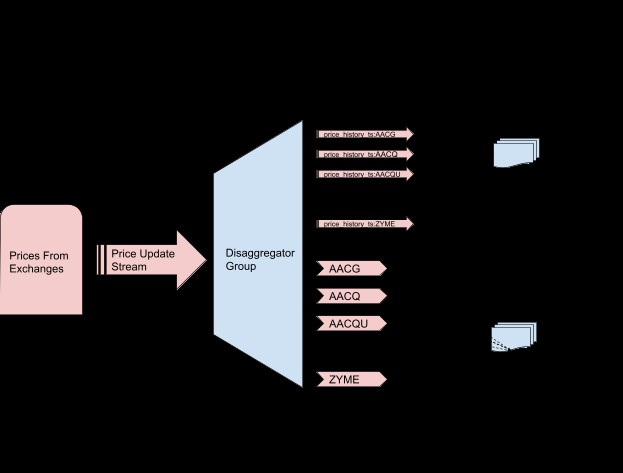
セキュリティ価格の更新は、RedisStreamsによって吸収されます。証券の更新はこのストリームで混合され、データを有用にするために分解する必要があります。コンシューマーグループは、その分解を実行し、セキュリティごとにデータを2つの構造に処理するために使用されます。
- RedisTimeSeriesデータベース。価格変更の履歴を追跡します(また、接続したばかりのクライアントの最新の価格を記録します)
- Pub / Subブローカーチャネル。そのチャネルにサブスクライブしているクライアント(つまり、ポートフォリオにそのセキュリティが含まれている投資家)に価格変更通知をプッシュします。
次の図は、アーキテクチャのこの部分の詳細を示しています。
モデルで最も重要な要素は、ロットと関連するセキュリティを表すアカウント固有のデータです。パフォーマンスに焦点を当てて、Redisでのデータのモデリングについて考える方法の例として2つの実装を比較します。他の実装も可能です。ここでの目標は、Redisでデータを実装する際の全体的な設計原則と思考プロセスを紹介することです。
具体的な例として、次の情報を使用します。
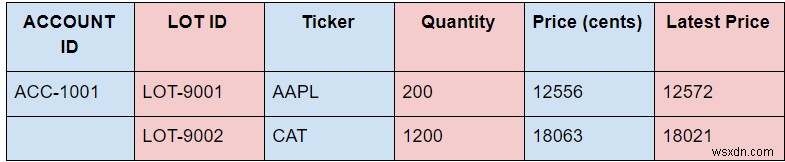
変動を避け、すべてを整数に保つために、可能な限り低い通貨単位で価格設定しています。クライアントがドルとセントへの変換を処理できるようにすることができます。この例では、小数点以下2桁の精度で価格を使用しています。
データモデルA
最初の実装では、アカウントIDで識別されるSETを使用してアカウント内のすべてのロットのIDを記録し、次に、ティッカー、数量、購入価格をフィールドとして、LOTIDで識別されるLOTごとに1つのRedisハッシュを使用します。つまり、HASHを使用して、各属性を持つLOTエンティティ構造をモデル化しています。 フィールドであるLOTエンティティの Redisハッシュで。
このデータモデルでは、各アカウントのキーと、RedisSETとして保存されたそのアカウントのすべてのLOTIDを含む値があります:
lotids:<ACCOUNT_ID> SET <LOTID>
さらに、ロットIDごとに、ティッカー、数量、購入価格のフィールドを持つハッシュがあります。
lot:<LOTID> HASH <ticker TICKER> <quantity INTEGER> <price INTEGER>
具体的には、次のようなキーを作成します。
127.0.0.1:6379> SADD lotids:ACC-1001 LOT-9001 LOT-9002 (integer) 2 127.0.0.1:6379> HMSET lot:LOT-9001 ticker AAPL quantity 200 price 12556 OK 127.0.0.1:6379> HMSET lot:LOT-9002 ticker CAT quantity 1200 price 18063 OK
RedisTimeSeriesモジュールを使用すると、関連する時間と値のペアを保存および取得できるほか、大量の挿入と低レイテンシの読み取りが可能になります。対応する時系列キーを使用するときにクライアントがアクセスする関心のあるティッカーの最新の価格を取得します:
price_history:<TICKER> TIMESERIES <price INTEGER>
127.0.0.1:6379> TS.GET price_history:APPL 1) (integer) 1619456853061 2) 12572 127.0.0.1:6379> TS.GET price_history:CAT 1) (integer) 1619456854120 2) 18021
更新のために価格設定チャネルにサブスクライブします:
<TICKER> SUBSCRIPTION_CHANNEL
すべてのデータを取得するために、クライアントは次の操作を実行します。
- lotidsでSMEMBERSを1回 キー-時間計算量O(N)、Nはロット数
- ロットでHGETALLをN回 キー-時間計算量N×O(1)
- price_historyでTS.GETをT回 キー–時間計算量T×O(1)、Tはティッカーの数
-
で1回サブスクライブする チャネル–時間計算量O(T)(SUBSCRIBEへの1回の呼び出しですべてのチャネルをサブスクライブできます)
全体的な時間計算量はO(N + T)です。
具体的には、操作1と2は次のようになります。
127.0.0.1:6379> SMEMBERS lotids:ACC1001 1) "LOT-9001" 2) "LOT-9002" 127.0.0.1:6379> HGETALL lot:LOT-9001 1) "ticker" 2) "AAPL" 3) "quantity" 4) "200" 5) "price" 6) "12556" 127.0.0.1:6379> HGETALL lot:LOT-9002 1) "ticker" 2) "CAT" 3) "quantity" 4) "1200" 5) "price" 6) "18063"
パイプライン(クライアント側でのバッチ処理の形式)を使用したり、LUAスクリプトを繰り返し使用したり(SCRIPT LOADとEVALSHAを使用)することで、ネットワークの遅延を最小限に抑えることができます。補足:トランザクションはパイプラインを使用して実装でき、ネットワークレイテンシを削減できますが、これはクライアント固有であり、その目標はサーバー上のアトミック性であるため、ネットワークレイテンシの問題を実際に解決することはできません。パイプラインは、入力と出力が互いに独立している必要があるコマンドで構成されます。 LUAスクリプトでは、すべてのキーを事前に提供する必要がありますおよび すべてのキーが同じスロットにハッシュされていること(詳細については、このトピックに関するRedis Enterpriseのドキュメントを参照してください)。
これらの制約を考えると、パイプラインへの操作の割り当ては次のようになります。
- パイプライン1:操作#1の単一コマンド
- パイプライン2:操作#2のすべてのNコマンド
- パイプライン3:操作#3および#4のすべてのNコマンド
また、LUAスクリプトを使用することはできません。これは、各操作で異なるキーが使用され、それらのキーには同じスロットにハッシュできる共通の部分がないためです。
このモデルを利用することで、O(N + T)の時間計算量と3つのネットワークホップがあります。
データモデルB
別のモデルは、LOTエンティティ構造をフラット化し、アカウントIDで識別されるキーを使用して各エンティティ属性を表すことです。これは、ロットの属性(数量、ティッカー、価格)ごとに1つのキーです。各ハッシュのフィールドは、LOT IDと、数量、ティッカー、または価格のいずれかに対応する値になります。したがって、キーがあります:
tickers_by_lot: <ACCOUNT_ID> HASH <LOTID TICKER>
quantities_by_lot:<ACCOUNT_ID> HASH <LOTID INTEGER>
prices_by_lot:<ACCOUNT_ID> HASH <LOTID INTEGER>
これらのハッシュは、データモデルAのLOTIDキーとLOTキーを置き換えますが、price_history および<TICKER> キーは同じままです。
キーの作成:
HSET tickers_by_lot:ACC-1001 LOT-9001 AAPL LOT-9002 CAT HSET quantities_by_lot:ACC-1001 LOT-9001 200 LOT-9002 1200 HSET prices_by_lot:ACC-1001 LOT-9001 125.56 LOT-9002 180.63
値の取得:
127.0.0.1:6379> HGETALL tickers_by_lot:ACC-1001 1) "LOT-9001" 2) "AAPL" 3) "LOT-9002" 4) "CAT" 127.0.0.1:6379> HGETALL quantities_by_lot:ACC-1001 1) "LOT-9001" 2) "200" 3) "LOT-9002" 4) "1200" 127.0.0.1:6379> HGETALL prices_by_lot:ACC-1001 1) "LOT-9001" 2) "12556" 3) "LOT-9002" 4) "18063"
クライアントが必要とする操作は次のようになります:
- lot_quantityでHGETALLを1回 キー-時間計算量NxO(1)
- lot_tickerで1回HGETALL キー-時間計算量NxO(1)
- lot_priceでHGETALLを1回 キー-時間計算量NxO(1)
- price_historyでTS.GETのT倍 キー-時間計算量TxO(1)、Tはティッカーの数
-
で1回サブスクライブする チャネル-時間計算量1xO(T)
これには、以前と同じO(N + T)の全体的な時間計算量があります。
パイプラインの観点から、これは次のようになります。
- パイプライン1—操作#1、#2、および#3のすべてのコマンド
- パイプライン2—操作#4および#5のすべてのTコマンド
そのため、ネットワークホップの数を1つ減らしました。絶対的にはそれほど多くはありませんが、相対的には33%です。
さらに、キーがわかっているのでLUAを簡単に使用でき、特定のアカウントのすべてのキーを同じスロットにマップできます。操作が簡単なため、LUAについてはこれ以上掘り下げませんが、この設計により少なくとも可能になることに注意してください。
単純なベンチマークでは、データモデルBは4.13ミリ秒速く実行されました(数千回の実行でベンチマークされました)。これは、クライアントがアカウントに対して初期化されるたびに1回だけ実行されることを考えると、全体的なパフォーマンスに影響を与えない可能性があります。
概要
このブログでは、Redisデータ型を使用したエンティティモデルの2つの可能な実装を示しました。また、Redisデータ型を選択するたびに実行する必要がある時間計算量分析を紹介し、ネットワークパフォーマンスの向上を考慮しました。これは、大規模で高性能が必要な場合の重要なステップです。以降のブログでは、データモデルが拡張されるにつれて、これらのアイデアをさらに拡張していきます。
証券ポートフォリオを大規模に管理する際のビジネス上の課題のいくつかを紹介し、次のことを示しました。
- リアルタイムでスケーラブルな証券ポートフォリオを実装するためのRedisデータモデル。
- ポートフォリオの合計値と各保有の利益または損失を計算するために使用できる、高性能のリアルタイム価格更新システム。
これらの2つの重要な機能を導入することで、証券会社のアプリクライアントは、数百万のアカウントを処理するように実行および拡張するリアルタイムのポートフォリオ更新を提供できます。この設計では、ポートフォリオの合計値と、各保有全体の利益または損失をリアルタイムで表示できます。このデータモデルとアーキテクチャは、暗号通貨や広告交換などをカバーする証券以外のユースケースにも適用できます。
-
CloudflareワーカーとのRedis@Edge
エッジでのコンピューティングは、近年最もエキサイティングな機能の1つです。 CDNを使用すると、ファイルをユーザーに近づけることができます。エッジコンピューティングを使用すると、アプリケーションをユーザーの近くで実行できます。これは、開発者がグローバルに分散されたパフォーマンスの高いアプリケーションを構築するのに役立ちます。 Cloudflare Workersは、現在この分野の主要製品です。コールドスタートのないサーバーレス処理環境を提供します。 Cloudflareのグローバルネットワークを活用して、アプリケーションのレイテンシーを最小限に抑えます。関数はJavascript、Rust、
-
例を含むRedisGEORADIUSBYMEMBERコマンド–Redisチュートリアル
このチュートリアルでは、特定の領域に該当するキーに格納されている地理空間値の要素を取得する方法について学習します。このために、Redis GEORADIUSBYMEMBERを使用します コマンド。 GEORADIUSBYMEMBERコマンド このコマンドは、キーに格納されている地理空間値(Sorted Set)の1つ以上のメンバーを返すために使用されます。これらのメンバーは、経度、指定されたメンバーの緯度値、および半径の引数を使用して計算された領域の境界内にあります。この面積は、指定されたメンバーの経度、緯度の値を円の中心位置として使用し、指定された単位の半径を円の半径として使用して計算