Solid Queue のマスタリング:Ruby on Rails 向けの実証済みのバックグラウンド ジョブ ソリューション
このシリーズの前回の記事では、バックグラウンド ジョブを処理するシステムが必要な場合には、Solid Queue が優れた選択肢であることを証明しました。外部依存関係を最小限に抑えます。Redis は必要ありません。 — すべてのジョブをデータベースに保存することによって。それにもかかわらず、信じられないほどのパフォーマンスを発揮します。
しかし、実稼働対応のバックグラウンド ジョブ システムには、パフォーマンスが高いだけでは十分ではありません。 Rails 開発者は長年にわたって多くのことを期待するようになりました。単にジョブをキューに入れてバックグラウンドで実行するだけではありません。ジョブをスケジュールし、定期的なスケジュールで実行したいと考えています。また、同時に実行できるジョブの数を制限したい場合もあります。もっと機能が欲しいです!
驚くべきことに、Solid Queue はこれらの機能をすべてすぐに提供します。 Solid Queue をさらに深く掘り下げて、それがどのように可能なのかを学びましょう!
Ruby on Rails の Solid Queue を使用したジョブのスケジュール
まず、簡単な要約の時間です。 Solid Queue は、ジョブ データを保存するためにデータベース (データベースのみ) を使用します。それが行うことはすべて、1 つまたは別のデータベース テーブルによって裏付けられています。ジョブのスケジュール設定、つまり将来のある特定の時点で実行するジョブの指定も同様です。スケジュールされたジョブはすべて solid_queue_scheduled_executions に保存されます。 .
このテーブルは solid_queue_ready_executions とほぼ同じです。 テーブル。唯一の違いは、scheduled_at が追加されていることです。 この列は、スケジュールされたジョブがいつ実行されるかを示します。ジョブをスケジュールしたときに何が起こるかを見てそれを確認しましょう。
そこには何の驚きもありません。 Solid Queue は新しい行を solid_queue_scheduled_executions に追加します。 テーブルには、予想されるデータが含まれています。しかし、そのような記録が存在する状態から、適切なタイミングで実際にジョブを実行するにはどうすればよいでしょうか?
solid_queue_scheduled_executions を継続的にポーリングするプロセスが必要です。 テーブル。そのプロセスはディスパッチャーと呼ばれ、スケジュールされたジョブを時間どおりに実行する責任があります。 Solid Queue が起動すると開始されます。追加の構成は必要ありません。ただし、必要に応じて、特定の構成で Solid Queue を実行することにより、ディスパッチャー プロセスのみを開始できます。
Dispatcher プロセスがどのように監視されているか疑問に思われた方のために付け加えておきますが、それは適切な名前の Supervisor の責任です。 。ワーカー プロセスやディスパッチャーなど、Solid Queue 内で実行中のプロセスを追跡します。
では、Dispatcher は実際にどのように機能するのでしょうか? poll を定義します。 ループ内で呼び出されるメソッドを使用して、スケジュールされたジョブを継続的にチェックします。ポーリング コードは複数のクラスとモジュールにまたがっていますが、非常に単純化した形式では次のようになります。
「準備完了」のスケジュールされた実行を取得するクエリは簡単です。
したがって、scheduled_at を持つスケジュールされたジョブはすべて 過去に発送する準備ができています。このシリーズのパート 1 で説明したように、Solid Queue がジョブをディスパッチすると、ReadyExecution が作成されます。 を記録し、対応する ScheduledExecution を破棄します。 記録する。 ReadyExecution その後、レコードは通常のワーカー プロセスによって取得され、対応するジョブが実行されます。
これまでのところ、とても良いです。スケジュールされたジョブは実際にはそれほど複雑ではありません。もっと複雑なもの、つまり定期的なタスクを見てみましょう。
定期的なタスク
定期的なタスクは、バックグラウンド ジョブ プロセッサに対してよく要求される機能です。簡単に言えば、これらは定期的なスケジュールで実行する必要があるバックグラウンド ジョブです。これらは、作業を実行するスケジュール (5 分ごと、毎日正午など) を定義するという点で Cron ジョブに似ています。
Solid Queue では、config/recurring.yml を使用して定期的なジョブを設定します。 ファイル。たとえば、CleanupData を実行したい場合 毎日正午に仕事をするなら、これが私たちのやり方です。
Solid Queue は Fugit を使用してスケジュール式を解析します。そのため、「毎日正午」などの人間が判読できるスケジュールが許可されます。スケジュールされたタスクを使用する場合は、実行するジョブのクラスとジョブ引数を定義します。優れた SolidQueue 定期タスク ReadMe に詳細が記載されています。私たちはその仕組みを学ぶためにここに来たので、内部を見てみましょう。
定期的なタスクは RecurringTask で表されます。 対応する solid_queue_recurring_tasks によってサポートされるモデル テーブル。その中の列は、設定ファイルで使用可能なフィールドに対応しています。
SolidQueue を開始すると、定期タスク構成ファイルに従って定期タスク レコードが作成されます。適切なタイミングでジョブを作成するには、ここでも新しいプロセスが必要になります。今回はスケジューラと呼ばれます。スケジューラは、すでに知っているディスパッチャの兄弟です。これはほぼ同じように動作します。Solid Queue が開始されると新しいプロセスがスピンアップされ、このプロセスは無限ループを実行します。スケジューラとディスパッチャの違いは、そのループ内で何が起こるかです。ディスパッチャが solid_queue_scheduled_executions をクエリする場所 テーブルに対して、スケジューラは solid_queue_recurring_tasks をクエリします。 — 適切なタイミングでジョブをスケジュールします。それでは、スケジューラは、適切な時刻と適切なジョブをいつスケジュールするかをどのように正確に知るのでしょうか?
この質問に答えるには、実装を詳しく調べる必要があります。スケジューラ クラスは新しい RecurringSchedule を作成します。 schedule を定義するオブジェクト 方法。このメソッドは、スケジュールされたタスクごとに繰り返し呼び出されます。簡略版は次のとおりです。
このコードを解いてみましょう。 Solid Queue は Concurrent::ScheduledTask を使用します (concurrent-ruby ライブラリから) 新しいスレッドを生成します。そのスレッドは、定期的なタスクのスケジュールで指定された時刻に実行されるようにスケジュールされています。そのスレッドが実行されると、まず別のスレッドを再帰的に生成して、次の繰り返しタスクをスケジュールします。次に、「現在の」スケジュールされたジョブをキューに入れます。
物事を把握するために、単純な繰り返しタスクの例を見てみましょう。
Solid Queue を 8:30 に開始すると、スケジュール メソッド内の変数には次の値が割り当てられます。逐語的にではありません、念のため。ここでは大幅に簡略化しています。
したがって、バックグラウンド スレッドは、今から 30 分後の 9:00 に実行されるようにスケジュールされています。その時間が経過すると、バックグラウンド スレッドが実行されます。 thread_task.enqueue(at: 9:00) を実行します — つまり、CleanupData のインスタンスです。 実行のためにキューに入れられます。また、thread_schedule.schedule を介して自分自身を再帰的に呼び出します。 。現在 9:00 であるため、この呼び出しの変数は変更されています。
したがって、バックグラウンド スレッドは 10:00 に再度実行されるようにスケジュールされ、サイクルが継続します。たとえば、再デプロイ中やシステムクラッシュ中にスケジューリングスレッドが強制終了されたらどうなるのか疑問に思われるかもしれません。それはあなたのスケジュールを狂わせませんか?幸いなことに、答えはノーです。 Cron スケジュールは静的です。 「Every Hour」のような式は、Solid Queue がいつ開始されるかに関係なく、常に 10:00、11:00、12:00 などに解決されます。スケジューリング スレッドが中断されても、状況は変わりません。
ここでは、注意すべきその他の実装の詳細をいくつか示します。まず、定期的なタスクを実行する前にその次回の発生をスケジュールするこのパターンは、GoodJob からインスピレーションを得たものです。 2 番目、RecurringTask.enqueue 新しい Job は作成されません および ReadyExecution ご想像のとおり記録します。代わりに、さらに別のレコード、つまり RecurringExecution が作成されます。 .
このレコードは、繰り返しジョブが複数回実行されることを避けるためだけに使用されます。 task_key にインデックスがあります および run_at その目的を果たすために独自の制約を設けます。 RecurringTask 以前の RecurringExecution がない場合にのみキューに入れられます。 同じ時間、同じ仕事について。
注意深い読者は、このコード スニペットが Solid Queue の制限を示していることに気づくでしょう。つまり、cron スタイルのタスクを実行するバックエンドとして Solid Queue を使用していない場合、はい、使用できます。Solid Queue は、定期的なジョブが 1 回だけキューに入れられることを保証できません。そのような状況に陥った場合は、そのことに注意する必要があります。
また、スケジューラ プロセスが停止した場合、またはデプロイメント中に強制終了された場合に何が起こるのか疑問に思うかもしれません。繰り返しはスレッドによって管理されるため、スレッドを強制終了するとスケジュールが中断されませんか?幸いなことに、その答えはノーです。
同時実行制御
Solid Queue の最後の機能、つまり同時実行制御を見てみましょう。場合によっては、特定の種類のジョブを同時に実行できる数を制限したいことがあります。これは、Solid Queue と limits_concurrency を使用して行うことができます。 .
ここでは、SolidQueue に MyJob のインスタンスを最大 1 つ実行するように指示しています。 ユーザーごとに。構成をさらに詳しく調べてみましょう。
to:同時に実行するジョブの最大数。key:どのジョブを一緒に制限するかを指定するための必須の引数。この例では、同じユーザー ID を持つジョブは 1 つの同時実行に制限されています。任意のジョブ引数をkeyとして使用できます。 ただし、文字列や記号などの定数も使用できます。duration:ジョブがキューに入れられた後、Solid Queue が同時実行性を保証できる最大時間。ジョブがそれより長く実行される場合、同時実行制御は適用されず、ジョブが重複する可能性があります。その理由については後ほど説明します。group:このオプションを使用すると、さまざまなジョブ クラス間での同時実行を制限できます。
さらに詳しく知りたい場合は、同時実行制御のドキュメントを参照してください。同時実行制御は、Solid Queue の最も洗練された機能です。スケジュールされたタスクにまだ頭がくらくらしていない場合でも、この機能がどのように機能するかを学ぶことで、確かに頭がくらくらするでしょう。
基本から始めましょう。他の Solid Queue 機能と同様に、同時実行制御はさまざまなモデルとそれに対応するデータベース テーブルによってサポートされています。特に注意する必要がある 2 つは Semaphore です。 と BlockedExecution .
Semaphore を見てみましょう まず。名前が示すように、これはカウンティング セマフォ パターンの実装です。 Solid Queue が limits_concurrency でジョブをキューに入れるたびに 、まず同時実行キーに基づいてセマフォ ロックの取得を試みます。この同時実行キーは、limits_concurrency に渡される引数に基づいています。 、つまり、ジョブ クラス、キー、およびグループ名 (指定されている場合)。セマフォが使用可能な場合、ジョブはキューに入れられます。そうでない場合は、BlockedExecution 代わりにレコードが作成されます。
セマフォには value があります。 複数の同時ジョブをサポートします。これはセマフォの残り容量と考えることができます。セマフォの取得はその値をデクリメントすることを意味し、セマフォを解放することはその値をインクリメントすることを意味します。セマフォの値がゼロになると、セマフォは使用できないとみなされます。簡単なジョブでロック メカニズムがどのように機能するかの例を見てみましょう。
このジョブを連続して複数回キューに入れようとするとどうなるかを見てみましょう。
<オル>MyJob の最初のインスタンス キューに入れられています。まだセマフォがないため、セマフォが作成されます。初期値は limit - 1 です。 。制限は 3 であるため、セマフォの初期値は 2 です。MyJob の 2 番目のインスタンス キューに入れられています。 Solid Queue は、そのジョブのロックを取得しようとします。値が 2 (ゼロより大きい) であるため、ジョブをキューに入れることができます。セマフォの値は 1 に減らされます。MyJob の 4 番目のインスタンス キューに入れられています。セマフォの値がゼロになっているため、セマフォの取得は失敗します。 BlockedExecution レコードはジョブに対して作成されます。MyJob の 4 番目のインスタンス 解放され、再度ロックの取得を試みます。セマフォ値は 1 であるため、ロックを取得してブロックされたジョブをキューに入れることができます。セマフォ値はゼロになりました。ジョブの終了時にセマフォを解放するコードは簡単です。
まだ触れていない詳細がもう 1 つあります。セマフォに有効期限があるのはなぜですか。また、limits_concurrency を使用するときに期間を設定する必要があるのはなぜですか。 ?
セマフォを解放せずにジョブがクラッシュした場合、たとえば、そのジョブを処理しているワーカーが死亡した場合に何が起こるかを考えてみましょう。セマフォをクリーンアップする何らかのメカニズムを追加しない限り、そのジョブによって保持されているロックは永久に保持されることになります。最悪の場合、これにより他のジョブの処理が永久にブロックされてしまいます。
このような状況を回避するために、セマフォにはジョブ定義で指定された期間に対応する有効期限が設定されています。セマフォの有効期限が切れると (キューに入れられたジョブがない場合に発生します)、セマフォは破棄されます。私たちはその原因となっているプロセスをすでに知っています。それは私たちの友人であるディスパッチャーです。 。 ConcurrencyMaintenance をインスタンス化します。 このクラスは次の 2 つのことを行います。
- まず、期限切れのセマフォを削除します。
- 2 番目に、ブロックされているジョブがあるかどうかを確認し、それらを解放します。
ジョブは 1 つずつリリースされるため、同時実行制限は引き続き適用されます。ただし、ジョブが指定された期間よりも長く実行された場合に何が起こるかを考えてください。この場合、ジョブは引き続き実行されますが、セマフォはクリーンアップされます。別のジョブがキューに入れられると、それらのジョブは重複します。
AppSignal を使用した Rails の Solid Queue の監視
これまでに説明したように、Solid Queue では多くのことができます。ただし、これらすべての可動部分があるため、監視が重要になります。幸いなことに、AppSignal は Solid Queue のサポートを組み込み、ジョブの実行時間、スループット、失敗率を表示する既製のダッシュボードを提供します。 AppSignal を Rails アプリケーションにインストールするだけで準備完了です。
AppSignal は、Solid Queue の使用状況を自動的に検出し、エラー率やスループットなどの重要な指標のグラフを含むアクティブなジョブ ダッシュボードを作成します。
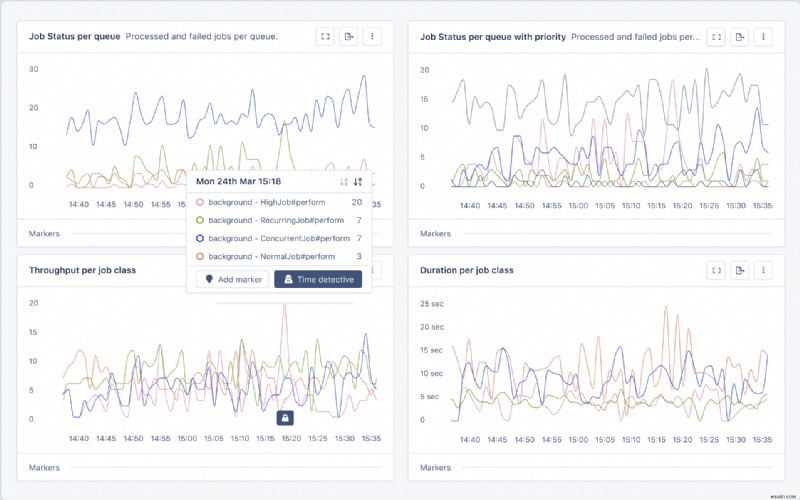
ジョブの動作が遅い、またはエラーが多すぎるなどの理由で不正な動作をしているジョブを見つけた場合は、問題を効果的に解決するためにステータスと担当者を割り当てます。
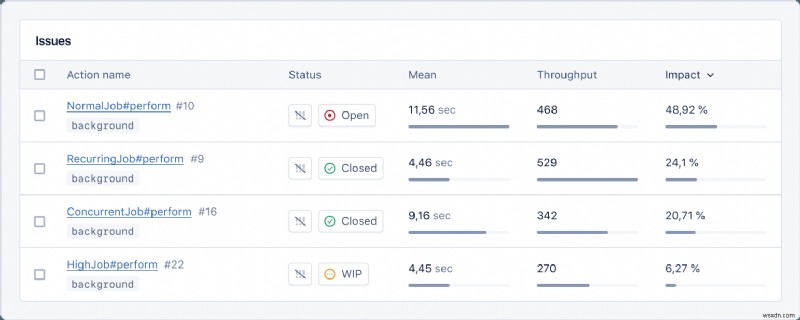
問題があるかどうかを確認するために、ダッシュボードを一日中見る必要はないのは明らかです。 AppSignal Alerts があなたをサポートします。失敗率やジョブ期間などのジョブ指標の新しいアラートを作成するだけで、準備は完了です。
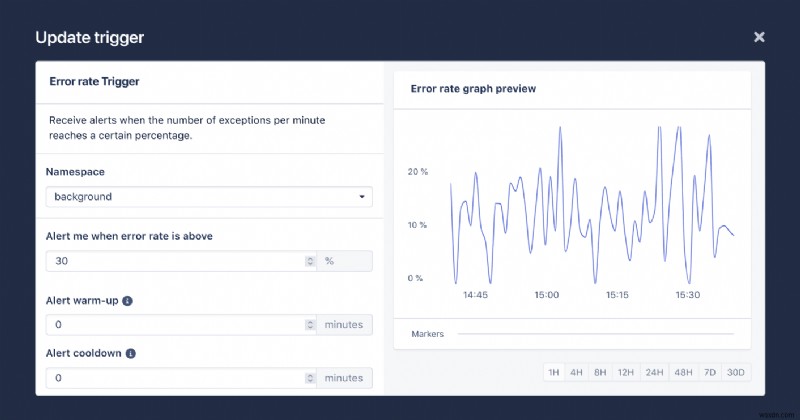
Solid Queue は、手間をかけずに強力なジョブ処理をアプリケーションに追加できる素晴らしい機能です。 AppSignal はモニタリングに関しても同様のことを行います。
まとめ
私たちは、Solid Queue の高度な機能の調査において多くの部分をカバーしてきました。スケジュールされたジョブから複雑な依存関係チェーンに至るまで、各機能は第 1 部で説明した強固な基盤の上に構築されています。これまで見てきたように、ジョブ処理バックエンドを構築するのは簡単ではありません。しかし、Solid Queue のソース コードとその仕組みを深く掘り下げることで、私たちはそれに伴う課題を理解し、ある程度の認識を得ることができました。
いずれにせよ、Solid Queue は、その優れたデータベース設計とプロセス調整により、Rails エコシステムへの素晴らしい追加となります。外部依存を必要とせず、シンプルさと信頼性というその核となる約束を維持しながら、必要なツールを提供します。
コーディングを楽しんでください!
-
Rubyでポートスキャナーを作成する方法
なぜポートスキャナーを作成したいのですか? ポートスキャナーを作成することは、トランスポート層であるTCPプロトコルの基本を学ぶための優れた方法です。 ほとんどのインターネットプロトコル(HTTPおよびSSHを含む)で使用されます。 Rubyネットワークプログラミングがどのように機能するかを学ぶのも良い練習です。 ポートについて話すことから始めましょう! ポートとは何ですか? ポートについて話すとき、私たちは本当に何について話しているのですか? O.S.の港(オペレーティングシステム)レベルは、プロセスに関連付けられた単なる「ファイル記述子」です。 ファイル記述子 stdoutのよう
-
ActionCableとTurboを使用してRailsでリアルタイムチャットアプリを構築する
Facebookにアクセスして、ページを更新せずに通知を受け取ったことはありますか?この種のリアルタイム機能は、状態管理を介したReactなどのJavaScriptフレームワークを使用するほとんどのアプリケーションで実現されます。これらのアプリケーションのほとんどは、データをリアルタイムで更新するために使用中にページをリロードする必要がないため、シングルページアプリケーションとして機能します。Railsアプリケーションは、通常、ページのリロードが必要であるという意味で、ステートレスでした。アプリケーションの現在の状態。たとえば、劇場で利用可能な映画のリストを表示するRailsアプリを使用してい